 摩尔定律、后摩尔时代以及Chiplet概念
摩尔定律、后摩尔时代以及Chiplet概念
Chiplet的概念一直都很火,国内外的各大公司各大专家,都发过各种各样的视频和长文。近段时间更是火热,一级火,二级也火,而且因为Chiplet技术有着2个14nm堆叠出7nm这样的说法,按照这个逻辑那4个14nm能不能堆叠5nm?
在普通人眼里,Chiplet像是国内弯道超车的技术和机会,一时间各种分析解读,层出不穷,但是看完这些之后是不是有一种感觉,越看越糊涂?后摩尔时代为什么和先进封装有关系?Chiplet到底是不是国内弯道超车的机会?
确实,太多专业概念需要科普,光靠自己去理解其中关系和概念其实挺困难的,简直头都大了。而且术业有专攻,不是专家自己擅长的领域不一定会覆盖到,因此哪怕产业专家也有讲的不够全面地方。
有没有一篇文章, 用最简单通俗的话术,用普通人最容易理解的方式去解释其中的前因后果以及各种概念?
经过走访众多大佬,刷过无数文章之后,笔者终于摸到一点门槛,今天就通过梳理发展历史脉络和概念,帮助大家更好的理解Chiplet和后摩尔时代半导体的发展方向。
01摩尔定律的历史
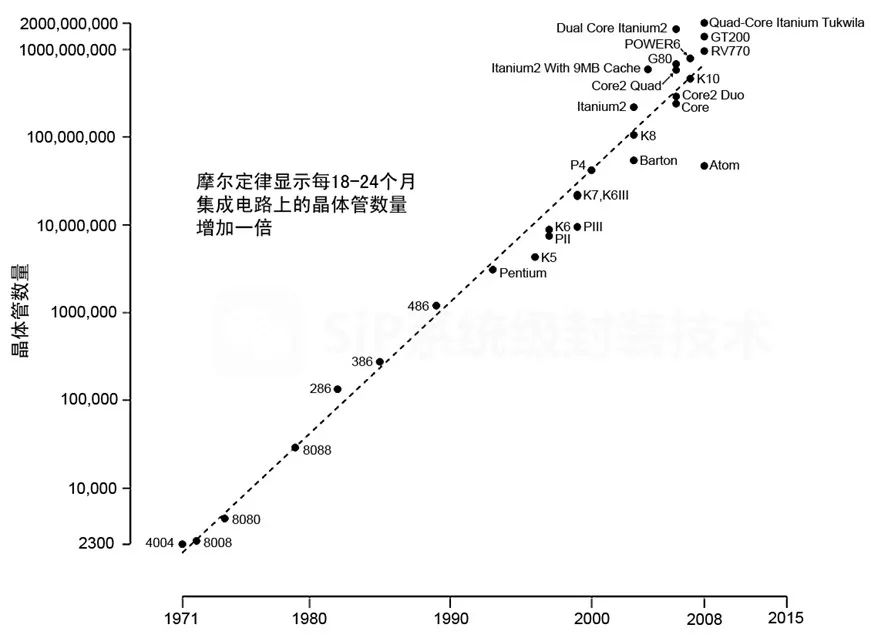
这个摩尔定律大家都很熟悉,一句话来概括:每隔18个月,单位面积内晶体管数量翻倍且价格不变。
这条被奉为行业圭臬的定律是由英特尔创始戈登·摩尔在60多年前提出的。
如果把它拆解后可得到两条衍生定律:1、成本减半定律,2、性能翻倍定律,且前置条件是更替节奏必须是每隔18个月。
成本减半很好理解,晶体管数量翻倍但是价格不变,等于每个晶体管的成本每个周期都在下降。
性能翻倍也很好理解,单位面积内晶体管数量翻倍,相当于每颗芯片的性能变得越来越强,毕竟晶体管数量的多少,很大程度上决定了这颗芯片的算力性能,越多基本等于越强。
当然这个是有前提的,仅适用于逻辑芯片领域,类似模拟,功率,传感器,射频之类不在这个讨论范围内,全世界最好的音频芯片还是4-6英寸的工艺在做,都是30,40年前的工艺,摩尔定律不太适用,但是你能说它落后吗?不,它已经是最好的了。
02摩尔定律的发展困境
假如,摩尔定律发展遇到困境了,那么从逻辑上来讲,必然是成本减半和性能翻倍两个结论,以及18个月这个周期,三者约定的条件中,有1-2个因素发展变化导致这个周期节奏被打破了,所以我们说摩尔定律发展遇到困境了。
换言之就是这个节奏玩不动了,或者不按这个节奏走了,所以结论就是摩尔定律被打破了,然后就开始提后摩尔时代这个概念了。这就是摩尔定律无法延续,我们要进入后摩尔时代的说法来源,确实先进工艺也确实快到极限了。
显然成本减半和性能翻倍是一件非常矛盾的事,相当于又要马儿少吃草,又要马儿跑得快,而且更替节奏只有短短的18个月。
从现实发展而言,两个定律都遇到两个无法回避的现实问题。
1、晶体管数量翻倍导致性能翻倍背后,有个巨大的隐患,就是急剧攀升的功耗。
道理也很简单,现在的集成电路技术,已经可以在指甲盖大小的面积内塞下上百亿个晶体管,如此狭小的面积内,任何电流经过都不可避免的带来发热,因此晶体管越多功耗越大,功耗越大意味着发热量就大,内部堪比一个大火炉,发热量一旦超过极限,芯片就直接烧穿了,那就是出大问题了。
可以说功耗和发热问题一直制约着晶体管数量的翻倍,业界一直在寻找各种方案与功耗做斗争。
2、成本减半,显然也很痛苦,毕竟投入越来越大,还要维持18个月内减半, 其中蕴含着巨大的矛盾和商业风险。新技术从研发投入到最终产出,必须有看得见降本提效,否则就变成往无底洞扔钱,太难了。
03传统思路是如何延续摩尔定律?
所以解决功耗和发热,是集成电路工艺一直为之战斗的目标,解决思路不外乎2个:1、改工艺;2、改基础材料。
无论是改工艺,还是改基础材料,目标都是继续维持性能翻倍定律和成本减半定律,综合下来就是怎么降本提效让摩尔定律能继续走下去。
先说改基础材料的问题,这就是现在炒的火热的概念,比如碳基芯片,硅光芯片/光电芯片,生物芯片等。
相当于把硅晶体管改成碳晶体管,或者硅光/光电子芯片,或者生物芯片。
分开聊聊这几个方向的优缺点。
碳管就是石墨烯材料的一种具体应用。相比硅管,石墨烯碳管有更高的载流子迁移率和稳定性,有更薄的导电通道和完美的结构,确实是一种比硅更好的材料。当然现在碳基芯片还处于比较早期的研究阶段,还有很多现实问题要解决,比如掺杂问题,晶体管制造的规模化等等,当然还有产业生态圈的问题,比如设计人员要如何设计电路才能完美发挥碳管的性能?晶圆工厂如何提供专业的工具包,标准晶体管单元库,仿真平台,以及制造工艺?
碳基芯片已经在实验室被制造出来,但是大规模商业化还早,还要很多年反复论证之后产业才能成熟。
也许有朝一日碳管的时代会到来,中国在这方面有所布局,让我们拭目以待。
硅光/光电子芯片,光电子芯片概念也很火,但是实际上也有两层不同概念。
第一,比较简单的方案是用光电互联结构替代硅晶体管的金属互联结构,因为光子速度极快,且传输过程中没有功耗,不会有额外的发热,因此是非常理想取代金属互联层材料的方案。毕竟目前的芯片中,大约有一半的功耗是在金属互联层上,如果用光传输信号,确实能解决这个问题,能极大降低芯片功耗,包括英特尔,英伟达,台积电等早就开始押注这个赛道了。
硅光芯片目前往这个方面在发展。

还有更高一层的梦想,就是用光子来替代硅晶体管进行0/1运算,这个有点类似量子计算,但是这个更早期,属于最前沿的科研项目。
生物芯片同理,因为仅需一点点加入一些酶就能变化,优点是几乎不需要什么能量,自然就不存在什么功耗和发热的问题,缺点是计算结论比较难得到,目前业内认为用于存储方面可能是一个比较可行的方案,当然现阶段只是一个研究方向,是非常前沿的技术,离商业化应用还很远。
改晶体管基础材料说完了,再说说改工艺的方案。
改工艺,解决思路也就是从晶体管结构入手,从金属互联材料和结构入手,加入各种新材料辅以先进制造技术,继续微缩晶体管尺寸,最终实现提高密度,降低功耗,提升性能这一目标。因此工艺进步依然是按着传统的思路在前进,这属于集成电路工程学的范畴。
以笔者在半导体工艺的知识储备,改工艺方面大概能科普到以下内容,如果有误望各位指正。
一、改进金属互联材料。
最早的集成电路工艺用的是铝互联工艺,这是英特尔另外一名创始人诺伊斯想出来的。
从6英寸工艺到8英寸再到12英寸工艺,看似是以硅片不同尺寸来命名的叫法,实际上每一代硅片变化的时候,工艺也在变化,不仅是改硅片尺寸,同时设备也做出更大改进,因此6英寸,8英寸,12英寸工艺设备,都有自己范围内的工艺节点。
比如6英寸大多数是0.5um-0.25um的线宽,8英寸多数是0.35-0.13um的线宽,12英寸是从90nm-28nm算成熟12英寸制程,小于20nm的16/14nm,7nm,5nm,3nm属于先进12英寸工艺范畴。
科普完了硅片和工艺节点的知识后,我们继续。
不同的工艺节点上,金属互联材料以及接触点材料就发生了巨大变化,6英寸用铝,但是8英寸工艺上就加入了钨塞工艺,钨作为接触点金属材料被运用在接触点上,而12英寸工艺上则加入了铜,用铜线替代了铝线。
进入10nm工艺更先进的制程里,英特尔折腾出钴互联,钴互联用于局部替代铜钨以及铜钌材料,用在衬底,导电,接触点,以及中间层上,特别是在M0和M1层的连线基线上。

科普一下M0和M1层,是指和最底下晶体管那一两层,直接和晶体管相连的,往上的M2到M十几层,都属于金属互联层。
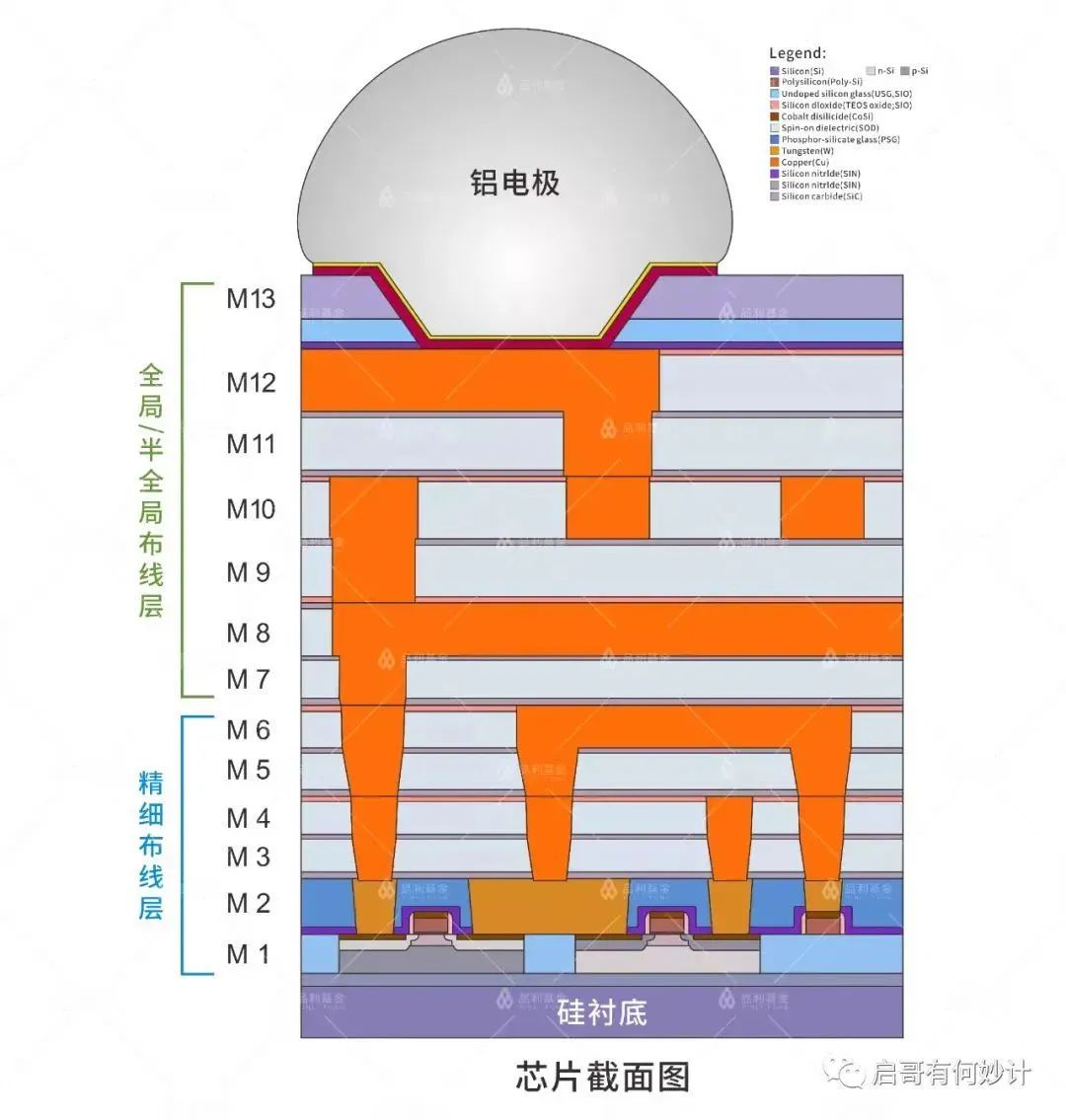
台积电在3nm以下工艺又折腾出铋互联,也是同一个思路。
同时,由于不同金属的导电率不同,隧穿率不同,我们需要在接触点/互联布线层外加入各种不同介电常数的材料作为阻挡层/缓冲层包裹起来,不让电子随便乱跑,不能漏出来,毕竟漏电了就代表有能量被带走,然后带来的就是大量发热,这是需要努力克服的问题。
阻挡层/缓冲层还有一个作用,就是让电子愉快的且不费力往前跑。
于是集成电路工艺大佬们在怎么弄阻挡层材料和沉积阻挡层工艺上也费了不少心血,目的就是为了就是让电子更顺畅通过,从而不漏电。
因此改金属互联工艺,就是改了接触点和互联层材料,以及包裹他们的阻挡层,缓冲层材料的一整套完整工艺。
这点上,应材去年推出了一款新设备叫 Endura Copper Barrier SeedIMSTM。
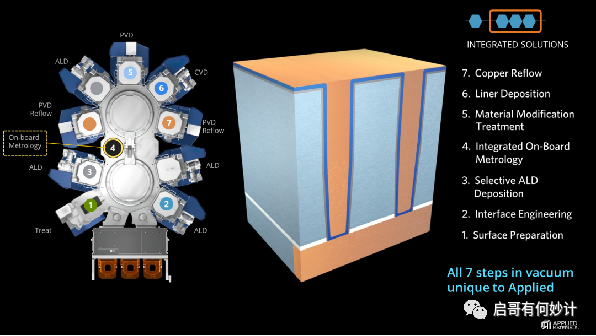
在这款新设备上,应材把ALD、PVD、CVD、铜回流、表面处理、界面工程和计量这七种不同的工艺技术集成到一个系统中,号称通过这一解决方案,通孔接触界面的电阻降低了50%,芯片性能和功率得以改善,逻辑微缩也得以继续至3nm及以下节点,当然这设备实际能有多大效果我不知道,但是价格一定很大。
二、改变栅极厚度,大小,结构和材料
深入钻研过集成电路工艺的小伙伴可能在28nm工艺上听说过一种叫HKMG的工艺,HKMG叫做High-K Metal Gate,翻译过来叫高介电常数金属栅极。
这个K就是介电常数的意思。
实际上就是用高K材料HfO2(二氧化铪)和HfSiON取代SiON(氮氧化硅)作为栅极氧化层。
到45nm工艺的时候,最先达到极限的就是这个栅极的介电质。
先来科普一下,栅极是啥。
MOSFET管,也就是金属氧化物金属场效应晶体管,简单理解成这是芯片内部的基础单位。比如一颗芯片集成了10亿个晶体管,你可以理解成集成了10亿个MOS管,但是实际上还有nMOS,pMOS,CMOS,Bicmos,电容之类的,比这个复杂多了,暂不做讲解,今天只讲科普原理。
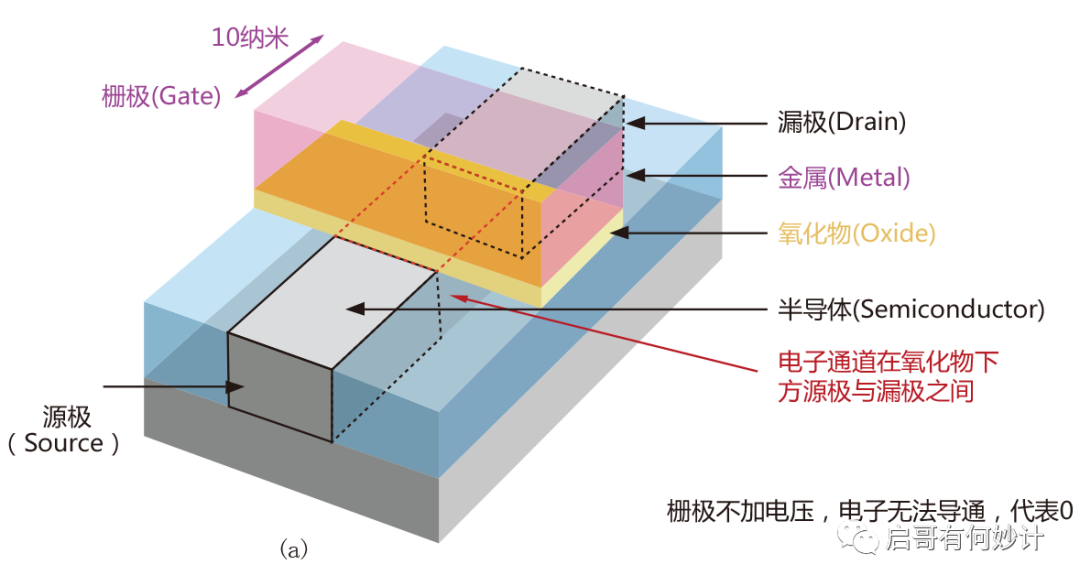
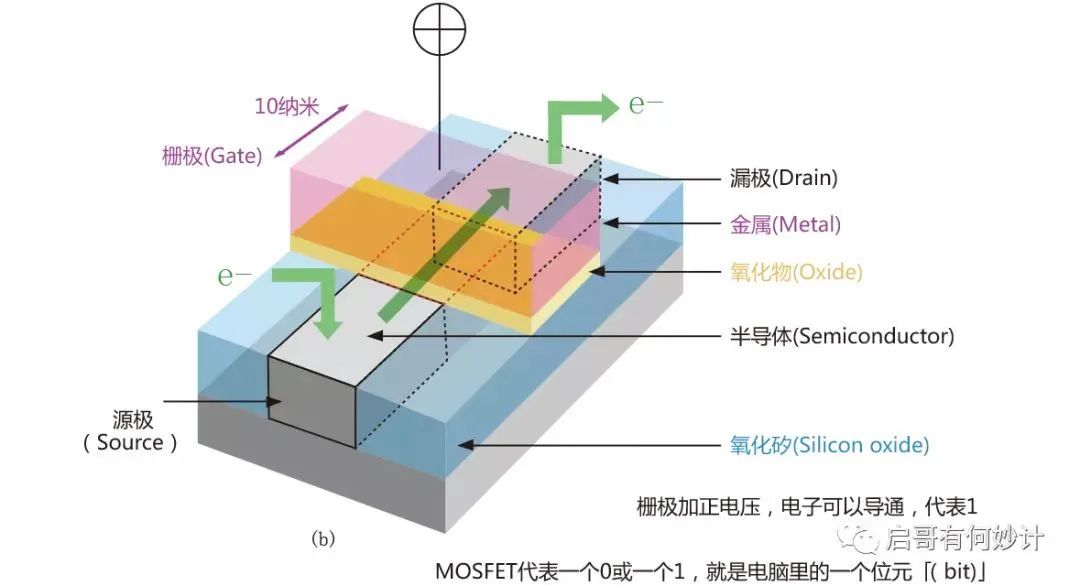
MOSFET结构有三个极,分别是源极(Source),漏极(Drain),栅极(Gate),可以理解成电流从源极进去,从漏极出来,而栅极相当于水龙头的作用,加电压就形成导通,没有电压就关断(这是常关型MOS特性,如果是常通型MOS则是加负电压关断)。形成导通和关断就能代表0和1,这就是计算机的基础工作原理,对,0和1,二进制,德国数学家莱布尼茨发明的,其还发明了微积分。
显然栅极的开关速度和开启/关断的阈值电压,决定了晶体管工作的频率,速度,栅极大小和功耗密切相关,栅极越小,沟道就越小,但是沟道越小就更容易漏电,因此得到更高频率更好性能的芯片,带来的副作用就是面临更大损耗,同时发热量也越大。
显然栅极厚度,大小,结构和材料,很大程度上决定了晶体管的极限工作状态下的开关速度,频率以及功耗大小,换栅极材料就能继续提高晶体管的性能和控制功耗。
因此45nm工艺最先遇到就是这个问题,传统用二氧化硅材料做的栅极,已经没办法满足晶体管性能提高,体积缩小的要求,容易产生漏电等问题,导致晶体管可靠性下降,因此提出了用高K金属栅极材料替代传统二氧化硅的工艺路线。
在28nm工艺上除了HKMG工艺,其他还有多达5-6个工艺版本,另外一个比较让人熟知的是28nm PolySiON工艺,叫多晶硅工艺,显然这是用多晶硅作为栅极的工艺。
PolySiON工艺水平接近40nm工艺性能,高性能HPC芯片用HKMG工艺的居多,到后面更是加入La2O3(氧化镧)等高K材料。
结论是在传统摩尔定律发展过程中,确实把克服栅极材料短板作为一项重要的工作内容,但是发展到后面,短板不在栅极上的时候,又一种解决摩尔定律的思路出现了。
三、改变晶体管结构
这里又要提一个耳熟能详的大神——胡正明。
胡正明教授在1999年至2000年,分别提出了用于20nm以下的两种新晶体管技术,FinFET和FD-SOI硅,并预言未来在20nm以下节点会用这两种技术。
当时预测20nm是摩尔定律的尽头,没想到硬是靠胡正明的FinFET强行续了一命。
15年后,在2015-2016年,台积电,三星,英特尔等前后研发出了基于FinFET晶体管技术的芯片,证明胡大神的设想是成立的。
FinFET的技术让胡正明就此封神了,这项技术足以冲击诺贝尔奖。
FinFET叫鳍式栅晶体管,顾名思义这东西像鱼鳍一样竖着的,和平面型的MOSFET不同,这是立体的晶体管结构。
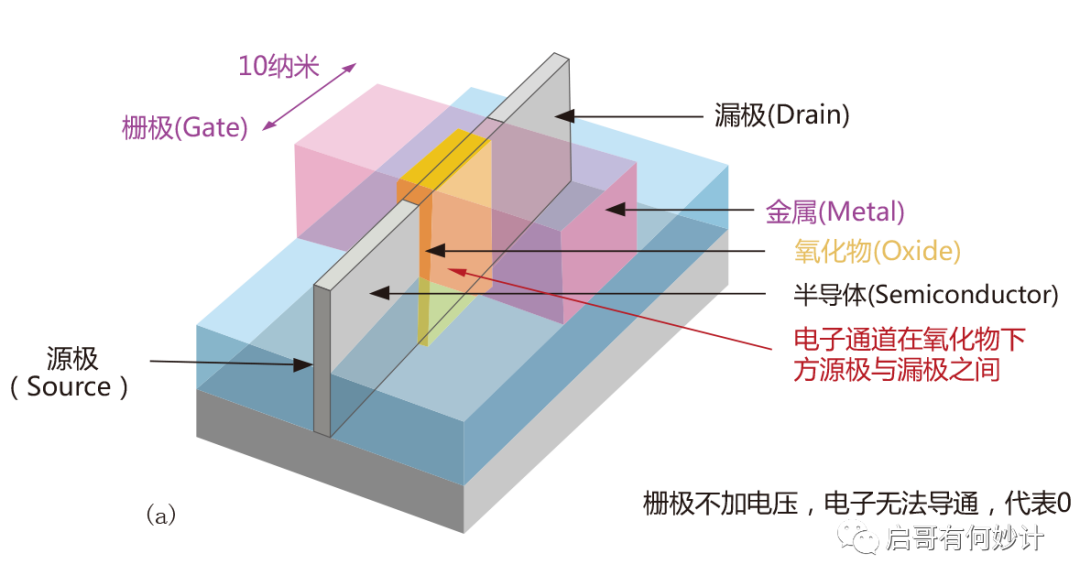
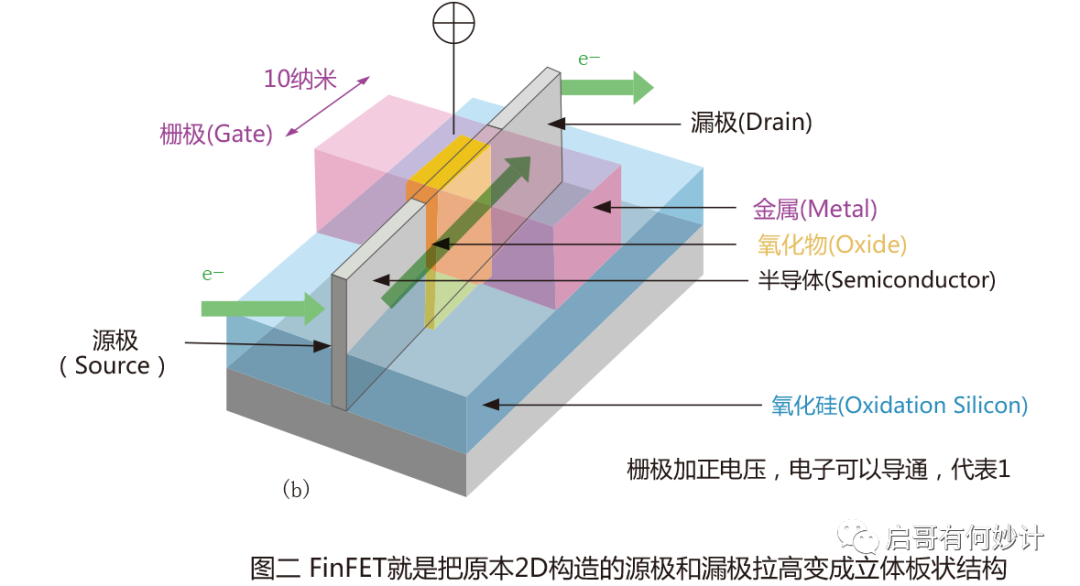
显然竖起来之后,不仅晶体管密度大大增加,同时也克服了MOSFET致命的“短沟道效应”,FinFET的出现继续给摩尔定律续命了。当然FinFET工艺也是配套一系列的工艺,为了解决FinFET特有比如电压阈值难以控制,更高的寄生电容效应,特殊三维轮廓也是上了一大堆新技术例如SADP(多重曝光)。
当然到3nm节点,可能唱主角的变成GAA技术(Gate-all-around环绕式栅极晶体管)。现在三星和台积电明争暗斗,三星5nm无法超越台积电,于是把资源都投在3nm节点上,相当于未来三星要和台积电在3nm节点上决战了。按照三星的说法,预计明年就能看到第一批使用GAA晶体管技术的芯片面世。
但是再往后呢?以人类无穷尽的智慧应该还有其他办法,1nm以下可能会用更新的堆叠技术,也许会过渡到碳晶体管时代,让我们拭目以待。
至于胡大神另外一个FD-SOI硅技术,也顺带科普下。
FD-SOI,叫全耗尽型绝缘硅,这种工艺需要使用一种特殊的硅片,一种类似三明治夹层结构的硅片,硅片中间有一层二氧化硅。

这种硅片中间有一层Oxide(氧化层),类似三明治夹层的结构
国内上海硅产业集团及法国子公司Soitec和沈阳硅基,都生产这种特殊的硅片。
这种特殊的硅片中间有一层二氧化硅,二氧化硅是非常良好的绝缘层,有绝缘层意味着不漏电,因此采用这种工艺制造的芯片有个绝对优点,就是功耗非常低。
而且不仅能实现低功耗,由于有二氧化硅夹层的存在,在制造过程中还能省光罩次数和层数,相当于降低了制造成本。
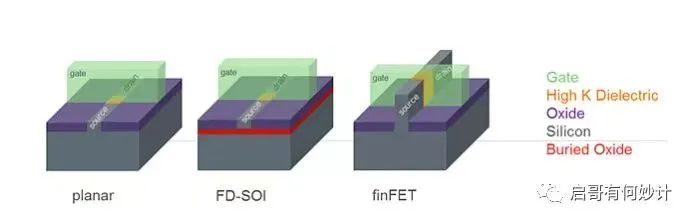
低功耗+省成本,是不是完美契合前文提到过的摩尔定律延伸出来的两大定律,成本减半定律和性能翻倍定律?因此胡大神说它是20nm以下集成电路制造技术的另外一个路线。
以前IBM擅长此道,后面被格罗方德(改名为格芯)继承,格罗方德还在桑杰·贾(Sanjay Jha)时代,2017年曾经宣布在成都要投资300亿美金,盖一个22nm FDX厂对标14nm FinFET,就是这个技术,22nm SOI技术竟然能对标14nm这个说法原因也在这里。
但是FD-SOI也有一大堆问题,首先是SOI硅片比较贵,是普通硅抛光片的8-10倍左右,然后最主要就是产业生态圈的问题,生态不成熟,没有清晰的替代路径,没有考虑长远的产品和技术迭代,仿真软件和设计平台也不成熟,目前国内除了在射频和物联网方面追求极致低功耗的领域有见过FD-SOI硅技术的身影之外,高性能计算领域几乎是零,全是FinFET的天下。
FD-SOI硅技术,有很多优点,但是产业生态圈不成熟也是其最大的短板,国内芯原微电子比较力推这个路线,推出了各种IP,希望国内以后能利用自身市场优点和特点,在射频和物联网等低功耗领域把FD-SOI技术发扬光大。
改进工艺和改基础材料,就科普到这里。
04如何延续后摩尔时代?
显然改工艺和改基础材料的各种方案都还是传统的摩尔定律思路,用更小的晶体管技术制造更强大的芯片,但是万事万物都有尽头,在当下各种成本高企的阶段,确实力不从心了。
新工艺研发投入,新设备的研发投入,新厂的建设加一起堪称天文数字,每年接近上千亿美金的研发投入和新厂资本支出。
那么灵魂拷问来了,这些投入后的回报怎么算?
以老大哥英特尔为例,今年3月宣布在亚利桑那州投入200亿美金的巨资,新建两座工厂,相当于一座厂100亿美金,你说这要卖多少颗CPU?一颗卖多少价格?一座工厂运营也需要天量资金,请问这些投入多少年才能回本???
当然英特尔盖厂背后有美国政府的全力支持,芯片法案里有巨额补贴,实际上英特尔不需要从自己口袋里掏这么多钱,成本能降低不少。
但不可否认的是,新工艺,新设备,新建厂越来越高的成本也催生了巨大的商业风险,搞不好就是巨亏,搁谁都受不了。
所以这投入加一起已经堪比天文数字,如果平摊到每个晶体管上,会造成当期成品的单个晶体管成本不降反升!几年以后会逐渐摊平研发投入,单个晶体管成本还是会下降,但是前几年成本依然非常高。
有机构统计过,2015年前后刚出14nm的FinFET那会儿,当时每个晶体管的成本已经不降反升了,初期FinFET所涉及的技术太复杂,良率不高,导致成本居高不下。换句话说7年前,摩尔定律其中之一的晶体管成本减半定律已经被打破,那会儿摩尔定律已然失效,当然由于后续技术提升,提高良率后,整体成本还是下降的,摩尔定律得以继续前进,但是以后呢?成本越来越高的问题已经没办法无视了,所以说业界到现在开始探讨摩尔定律还能不能维持,怎么维持的问题。
延续后摩尔时代,已然要从根本问题入手,成本减半,性能翻倍,降本提效。于是后摩尔时代以及Chiplet概念来了。
05后摩尔时代与Chiplet
在商业环境下,抛开成本谈性能是耍流氓,这是商业法则,因此必须兼顾性能和成本。
但是摩尔定律现在已经是百尺竿头,逼近极限了,再进一步是难上加难。
但是性能的需求一直在增加?如何平衡这两者关系?
因此后摩尔时代的概念被提出,后摩尔时代并不仅仅是提出新技术,新概念,延续摩尔定律, 而是从更高层面出发来定义新时代芯片如何设计,如何制造,如何平衡性能,功耗以及成本之间的关系。
在讲Chiplet概念之前,还是有必要再讲一段工艺制程的相关概念。
P.P.A,懂行的小伙伴都知道,它是衡量一道工艺,一颗芯片的关键指标,是性能(Performance),功耗(Power),以及面积尺寸(Area),是这三个英文字母的缩写。
换言之,任何芯片都被希望有着更好的性能,更低的功耗,以及更小的面积尺寸,工程师们都希望在PPA之间寻找平衡点,兼顾性能和成本,这是为之努力的方向(工程师的真正KPI)。
当然这个目标极难实现,以至于这些工程师在还在努力过程中。
从集成电路的工艺角度而言,从45nm以下工艺开始,晶体管的真实栅极(Gate length)长度和节点工艺的命名规则,并不是一一对应关系,比如现在说14nm,7nm其实真实栅极长度并不是14nm,7nm。之所以这么叫14nm是根据上一代28nm工艺指标等效出来。
举个例子,以上一代28nm工艺节点为标准,新一代工艺让晶体管小了30%,功耗降低了25%,晶体管密度提高了50%,性能提升了40%,要不我们就叫他14nm工艺吧,于是14nm就这么来的。(真实数据笔者没有认真考证,只是打个比方)
看起来似乎像文字游戏,这种等效叫法确实也造成一定的宣传口径不统一。例如台积电的N7工艺和英特尔10nm工艺各方面都差不多,但是一个就是叫7nm,一个就是叫10nm,相比之下用台积电N7工艺制造的AMD Zen系列CPU看起来就比英特尔10nm工艺制造的CPU更强些,英特尔在宣传方面吃了个亏,10nm和7nm,明显7nm在宣传上更有优势。
所以到现在这套工艺节点命名背后的逻辑,除了FAB厂里最资深的技术大佬会比较熟悉外,基本没几个人能说清。
不管如何,在后摩尔时代,对更高集成度,更强性能芯片追求并不会停下脚步,但是成本又非常高,如何解决问题?
继续从高性能芯片入手,我们发现了一个问题。
以CPU为例,我们会发现,一颗CPU内部只有30%左右的面积是高性能计算单元,而70%则是SRAM(缓存单元)。
为什么会出现这样的布局,CPU性能要强不应该是塞入更多的计算单元才变强的吗?为什么一大半面积是SRAM?
深入研究后发现,因为瓶颈在数据存取上!
SRAM的作用是计算单元和外部内存单元之间的缓存,相当于一个临时仓库,它的容量比内存容量小很多,但是速度很快,主要用途是解决CPU运算速度和内存读写速率不匹配的矛盾。
所以算力瓶颈在运算核心和存储器之间的矛盾,数据运算越快,就需要越大的存储空间来放数据,而这个任务就是由CPU内部的SRAM和外部存储来担任,保证整体效率最高。
我们用一个比较形象的比喻就是,都是吃饭的家伙,显然胃的容量要比口腔大很多,口腔作用就是处理数据(咀嚼食物),而胃则是存放处理过的数据(存储食物),这么一看是不是就好理解了?
SRAM虽然速度快,但是由于占地面积大,在寸土寸金的CPU内部就显得比较昂贵,而且SRAM的结构包括存储单元整列(core cell array),行列地址编译器(decode),灵敏放大器(sense amplifier),缓存驱动电路(FFIO),器件比较多,集成度对比运算单元也不高,功耗也大。
既然SRAM这么占地方,把大量宝贵的晶体管用来作为存储数据的SRAM是不是有点亏?有没有什么办法来解决这个问题呢?
工程师想到的办法是在CPU外面加上高性能的HBM高宽带内存,来解决数据存储和数据交互的问题。
所以大家看到现在的GPU,APU,以及AI芯片,各种xPU,各种高性能计算的芯片都是这个解决思路,在原来SoC核外面外挂一颗HBM高宽度内存,解决系统瓶颈问题。
如果这颗HBM内存颗粒放在PCB板上,显然是无法发挥其最大性能,因为PCB布线的传输速度仅仅只有几百M,显然是不够用的,那么只能尽可能在内部和SoC整合一起,并且用高速SerDes接口总线,把他们连起来,速度就能提升成百上千倍,系统瓶颈问题就解决一大半了!
这样做不仅能减少SRAM的面积,把资源都堆在高性能计算单元上,最大程度提高整体性能,好钢都用在刀刃上的思路!
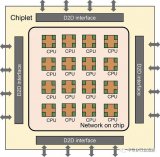
那么怎么整合到一起呢?PCB是肯定不行,SoC核内部已经定型了,也动不了,解决方案就是先进封装,直接把两颗裸芯粒(Die)集成到一起!
这种异构集成Chiplet的概念。
从字面上看Chiplet是小芯片的意思,但是我们从实际作用和思路可以拆解成三层概念,分别包含异构架,小芯粒和系统级集成。
1、异构架
异构架又包含两层概念,第一是把不同类型的芯片整合到一起,比如上文提到的GPU+HBM,显然GPU和HBEM是不同的芯片,一个是图形计算核心单元,一个是高宽带内存颗粒,它们设计不同,结构不同,类型不同,工艺也不同,是无法把他们在同一块chip上制造出来的,因此它们是分开制造,再用先进封装整合到一起。
在未来更广阔的范围里,我们还要整合不同材料的芯片,比如氮化镓光电芯片+硅的驱动芯片+数模混合芯片,氮化镓和硅属于不同材料,更加不可能直接制造,只能是分开制造再整合到一起。
2、小芯粒
小芯粒是相对SoC大核而言,它把大核SoC各个功能区IP拆分重排,拆分成一个个小芯粒重新组合,从面不同市场出发,不同客户的诉求出发,在成本,性能和特定功能之间找设计和制造的平衡点。
比较典型的案例如AMD的Zen 2,当时AMD就是把核心计算单元和I/O(输入输出单元)分开,一个用7nm,一个用14nm工艺制造,最后再封装到一起,英特尔现在也有这种玩法,叫EMIB混合封装,把不同的Die分开,再整合。
璧韧之前宣传自己超过英伟达同类产品,也是利用这个思路,用112G的高速SerDes直连HBM,最大程度发挥其性能。
3、系统级集成
系统级集成又包含软集成和硬集成两个概念。
软集成包含系统级软件和操作系统以及总线互联标准,它是把芯片设计从更高的系统角度去看,来重新定义一款芯片的诞生,软集成是指打通底层软件和系统。
硬集成是指的2D/2.5D/3D封装,用先进封装技术把他们整合一起,是先进封装技术的再升级。
其中2D理解成同一个基板上集成,2.5D在中间层通孔硅上集成,3D真正的chip on chip的堆叠,芯片与芯片的直连。
为了帮助大家更好理解Chiplet,笔者画了一个图,应该更容易看懂。

关于这个系统级集成,再扩大一点概念。
以英特尔2.0的的战略规划为例,英特尔表面上看要干代工,但是实质上我们剖析后认为,英特尔的棋是这么下的。
从现有手中的资源来看,英特尔拥有完整的x86构架的IP,这是它的底蕴,而且,英特尔又掌控了PCIe技术联盟标准的制定,而PCIe基础上发展起来的CXL联盟和UCle标准也是由英特尔主导,相当于英特尔既掌握了核心X86 IP,又掌握了非常关键的高速SerDes技术和标准。
有了高速SerDes的接口以及x86CPU构架,英特尔可利用它们更好地推出使用围绕CPU做Chiplet的定制化组合,更好更快的推出新的高性能,高算力的芯片。而且,英特尔的先进工艺,和先进混合封装技术的能力并不弱,是有希望通过商业模式创新,并打造出一个全新的英特尔2.0时代,继续保持其强大的江湖地位。
谷歌、亚马逊这种互联网巨头,这些年由于布局算力中心,数据中心,云存储中心,投入并不少,并且也开始自研各种芯片,如AI芯片,算力芯片,加速计算芯片诸如此类的东西。
笔者认为英特尔和他们是有双赢合作的可能性。
从商业逻辑上来讲,英特尔放开x86 CPU构架给亚马逊,让亚马逊围绕自己的CPU内核做定制化改进,增减各种功能模块,并且利用PCIe高速接口互联把亚马逊自研芯片的IP部分整合进来,同时英特尔又有代工能力和系统级整合能力,可以提供一站式服务。
比如wafer上切割下小芯粒后,可以利用英特尔的混合封装能力,把各个不同的小芯粒以及高性能内存颗粒直接封装到一起,再通过改进信号线路和供电线路的PowerVia技术,变相增加互联密度以及控制功耗,最终得到一个基于英特尔CPU为基础,亚马逊特制高阶定制版的HPC高性能芯片,用于他们自己的服务器和数据计算中心。
是不是看起来比给AMD代工靠谱一点?应该说算是一个比较完美的商业方案,这样做的好处有三条:
第一,英特尔通过授权X86构架的CPU IP和PCIe技术,有利于保持英特尔CPU领域的市场份额,联合亚马逊自研芯片体系,最快推出产品,顶住英伟达的蚕食。
第二、有利于UCle标准的推广,因为UCIe技术在自己手里,英特尔可以通过UCIe相关控制虚拟内存资源,将CPU内存资源开放,但是必须通过UCle来搞,这么一来,UCle标准也推出去了。
第三、英特尔提供完整平台来解决流片、封装的问题,提供一站式服务,形成最终英特尔深入参与的亚马逊版本Chiplet方案芯片。
前后可以更多的利润,还把自己主导的IP和标准推向了市场,一举多得。
从这个角度看,英特尔2.0战略还有点意思,至少逻辑上行得通,至于实际上怎么做,让我们拭目以待。
06结尾
所以Chiplet完整的概念是异构架小芯粒系统级集成,Chiplet是从整体系统效率出发,兼顾成本和工艺制造的一种新的解决思路,先进封装只是其中一部分,并不代表全部,用先进封装去套Chiplet概念是不完整的。
对于中国而言,发展Chiplet好处很多,至少笔者认为从底层逻辑来讲在性能,制造成本,时间成本之间找平衡,从未来发展角度而言,教会中国公司,如何从系统高度来看问题,来学习如何定义一款芯片,这其中会牵涉到很多新技术,新理念,正好是中国产业链一次自我学习,自我升级的机会。
2个14nm堆叠出7nm芯片,只是一个理想状态,只有众多前提条件约束,不能认为这个方案适用所有芯片。
最后再复习一遍下面这张图。
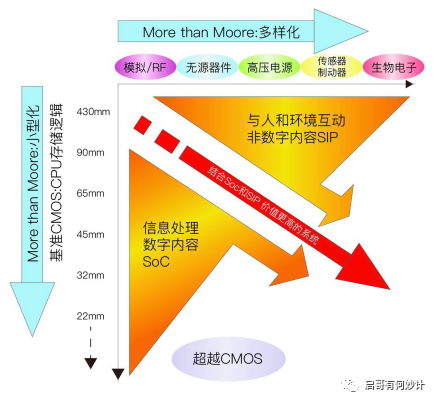
纵轴这条上依然按照传统摩尔定律走追求更小的晶体管尺寸和更高的密度,更强的性能。
横轴上是把不同的模拟,射频,高压,传感器等不同的芯片整合到一起,追求的是多功能,高效灵活设计,异构集成,平衡性能,功能和成本之间的关系,
两者共同组成了后摩尔时代。
审核编辑 :李倩
-
摩尔定律
+关注
关注
4文章
634浏览量
78982 -
晶体管
+关注
关注
77文章
9679浏览量
138050 -
chiplet
+关注
关注
6文章
430浏览量
12582
原文标题:深入浅出的聊聊摩尔定律、后摩尔时代以及Chiplet概念(万字长文)
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
击碎摩尔定律!英伟达和AMD将一年一款新品,均提及HBM和先进封装

对话郝沁汾:牵头制定中国与IEEE Chiplet技术标准,终极目标“让天下没有难设计的芯片”

后摩尔定律时代,提升集成芯片系统化能力的有效途径有哪些?
高算力AI芯片主张“超越摩尔”,Chiplet与先进封装技术迎百家争鸣时代

“自我实现的预言”摩尔定律,如何继续引领创新
封装技术会成为摩尔定律的未来吗?

功能密度定律是否能替代摩尔定律?摩尔定律和功能密度定律比较
摩尔定律的终结:芯片产业的下一个胜者法则是什么?

Chiplet技术对英特尔和台积电有哪些影响呢?

2023年Chiplet发展进入新阶段,半导体封测、IP企业多次融资
中国团队公开“Big Chip”架构能终结摩尔定律?
芯耀辉推动国内高速Chiplet接口IP不断破局





 工商网监
工商网监
评论