 介绍3种实现Nested-Loop Join算法的方法
介绍3种实现Nested-Loop Join算法的方法
在MySQL的实现中,Nested-Loop Join有3种实现的算法:
一、原理篇
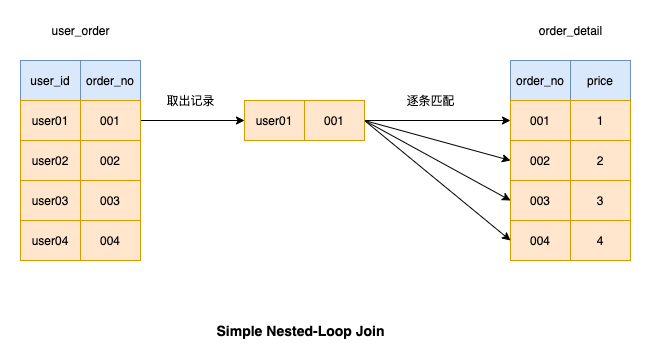
1、Simple Nested-Loop Join
比如:
SELECT *
FROM user u
LEFT JOIN class c ON u.id = c.user_id
我们来看一下当进行 join 操作时,mysql是如何工作的:

当我们进行left join连接操作时,左边的表是 「驱动表」 ,右边的表是**「被驱动表」**
特点:
Simple Nested-Loop Join 简单粗暴容易理解,就是通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有1万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。
「这个全是磁盘扫描!」
❝因为每次从驱动表取数据比较耗时,所以MySQL即使在没有索引命中的情况下也并没有采用这种算法来进行连接操作,而是下面这种!
❞
2、Block Nested-Loop Join
同样以上面的sql为例,我们看下mysql是如何工作的
SELECT *
FROM user u
LEFT JOIN class c ON u.id = c.user_id

因为每次从驱动表取一条数据都是磁盘扫描所有比较耗时。
这里就做了优化就是 「每次从驱动表取一批数据放到内存中,然后对这一批数据进行匹配操作」 。
这批数据匹配完毕,再从驱动表中取一批数据放到内存中,直到驱动表的数据全都匹配完毕。
这块内存在MySQL中有一个专有的名词,叫做 join buffer,我们可以执行如下语句查看 join buffer 的大小
show variables like '%join_buffer%'

另外,Join Buffer缓存的对象是什么,这个问题相当关键和重要。
❝Join Buffer存储的并不是驱动表的整行记录,具体指所有参与查询的列都会保存到Join Buffer,而不是只有Join的列。
❞
比如下面sql
SELECT a.col3
FROM a JOIN b ON a.col1 = b.col2
WHERE a.col2 > 0 AND b.col2 = 0
上述SQL语句的驱动表是a,被驱动表是b,那么存放在Join Buffer中的列是所有参与查询的列,在这里就是(a.col1,a.col2,a.col3)。
也就是说查询的字段越少,Join Buffer可以存的记录也就越多!
变量join_buffer_size的默认值是256K,显然对于稍复杂的SQL是不够用的。好在这个是会话级别的变量,可以在执行前进行扩展。
建议在会话级别进行设置,而不是全局设置,因为很难给一个通用值去衡量。另外,这个内存是会话级别分配的,如果设置不好容易导致因无法分配内存而导致的宕机问题。
-- 调整到1M
set session join_buffer_size = 1024 * 1024 * 1024;
-- 再执行查询
SELECT a.col3
FROM a JOIN b ON a.col1 = b.col2
WHERE a.col2 > 0 AND b.col2 = 0
3、Index Nested-Loop Join
当我们了解**「Block Nested-Loop Join」** 算法,我们发现虽然可以将驱动表的数据放入 「Join Buffer」 中,但是缓存中的每条记录都要和被驱动表的所有记录都匹配一遍,也会非常耗时,所以我们应该如何提高被驱动表匹配的效率呢?
其实很简单 就是给被驱动表连接的列加上索引,这样匹配的过程就非常快,如图所示

上面图中就是先匹配索引看有没有命中的数据,有命中数据再回表查询这条记录,获取其它所需要的数据,但列的数据在索引中都能获取那都不需要回表查询,效率更高!
二、SQL示例
1、新增表和填充数据
-- 表1 a字段加索引 b字段没加
CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`a` int DEFAULT NULL COMMENT '字段a',
`b` int DEFAULT NULL COMMENT '字段b',
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 表2
create table t2 like t1;
-- t1插入10000条数据 t2插入100条数据
drop procedure if exists insert_data;
delimiter ;;
create procedure insert_data()
begin
declare i int;
set i = 1;
while ( i <= 10000 ) do
insert into t1(a,b) values(i,i);
set i = i + 1;
end while;
set i = 1;
while ( i <= 100) do
insert into t2(a,b) values(i,i);
set i = i + 1;
end while;
end;;
delimiter ;
call insert_data();
2、Block Nested-Loop Join算法示例
-- b字段没有索引
explain select t2.* from t1 inner join t2 on t1.b= t2.b;
-- 执行结果
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10337 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
从执行计划我们可以得出一些结论:
驱动表是t2,被驱动表是t1。所以使用 inner join 时,排在前面的表并不一定就是驱动表。- Extra 中 的 「Using join buffer (Block Nested Loop)」 说明该关联查询使用的是 BNLJ 算法。
上面的sql大致流程是:
- 将 t2 的所有数据放入到
join_buffer中 - 将 join_buffer 中的每一条数据,跟表t1中所有数据进行比较
- 返回满足join 条件的数据
3、Index Nested-Loop Join 算法
-- a字段有索引
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
-- 执行结果
+----+-------------+-------+------------+------+---------------+-------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | t2 | NULL | ALL | idx_a | NULL | NULL | NULL | 100 | 100.00 | Using where |
| 1 | SIMPLE | t1 | NULL | ref | idx_a | idx_a | 5 | mall_order.t2.a | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------+---------+-----------------+------+----------+-------------+
从执行计划我们可以得出一些结论:
- 我们可以看出 t1的type不在是all而是ref,说明不在是全表扫描,而是走了idx_a的索引。
- 这里并没有出现 「Using join buffer (Block Nested Loop)」 ,说明走的是Index Nested-Loop Join。
上面的sql大致流程是:
- 从表 t2 中读取一行数据
- 从第 1 步的数据中,取出关联字段 a,到表 t1 idx_a 索引中查找;
- 从idx_a 索引上找到满足条件的数据,如果查询数据在索引树都能找到,那就可以直接返回,否则回表查询剩余字段属性再返回。
- 返回满足join 条件的数据
我们发现这里效率最大的提升在于,t1表中rows=1,也就是说因为idx_a 索引的存在,不需要把t1每条数据都遍历一遍,而是通过索引1次扫描可以认为最终只扫描 t1 表一行完整数据。
三、join优化总结
根据上面的知识点我们可以总结以下有关join优化经验:
在关联查询的时候,尽量在被驱动表的关联字段上加索引,让MySQL做join操作时尽量选择INLJ算法。
2)小表做驱动表!
当使用left join时,左表是驱动表,右表是被驱动表,当使用right join时,右表是驱动表,左表是被驱动表,当使用join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表,如果说我们在 join的时候 明确知道哪张表是小表的时候,可以用 「straight_join」 写法固定连接驱动方式,省去mysql优化器自己判断的时间。
「对于小表定义的明确」 :
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
3)在适当的情况下增大 join buffer 的大小,当然这个最好是在会话级别的增大,而不是全局级别。
4)不要用 * 作为查询列表,只返回需要的列!
这样做的好处可以让在相同大小的join buffer可以存更多的数据,也可以在存在索引的情况下尽可能避免回表查询数据。
审核编辑:刘清
-
MySQL
+关注
关注
1文章
777浏览量
26137
发布评论请先 登录
相关推荐
FFT 算法的一种 FPGA 实现
两种典型的ADRC算法介绍
Apriori算法的一种优化方法
3DES算法的FPGA高速实现

Join在Spark中是如何组织运行的
SQL子查询优化是怎么回事

LOOP指令——汇编语言学习笔记3

一文终结SQL子查询优化
大模型+多模态的3种实现方法






 工商网监
工商网监
评论