 如何打造BEV + Transformer的技术架构?
如何打造BEV + Transformer的技术架构?

Nullmax感知部总监兼计算机视觉首席科学家成二康博士,前段时间做客汽车之心·行家说栏目,就行泊一体的感知能力话题进行了分享。
当中,成二康博士就自动驾驶的数据闭环以及虚拟样本生成等数据话题进行了概括性的介绍,并对当前备受关注的BEV感知,尤其是BEV + Transformer技术架构,从总结和实践两方面进行了简明易懂的阐述。
我们将成二康博士分享的主体内容进行了整理,本篇是关于BEV + Transformer的精简介绍。目前,Nullmax已经完成了BEV感知的一系列工作,并在量产项目开始了相关技术的运用。
行泊一体是一个很热的话题,简单来讲就是用一个域控或者嵌入式平台同时实现行车、泊车两大功能。因此,行泊一体的方案对于整个系统的感知架构也有着极高的要求。
比如,需要处理包括相机、毫米波雷达等多个传感器的输入,需要支持行泊一体中的融合、定位、规划和感知等多个任务。尤其是视觉感知方面,需要支持360度覆盖的相机配置,为下游的规划、控制任务输出目标检测、车道线检测等感知结果。
为此,Nullmax开发了一套强大的感知架构,它最大的优势就在于可以同时融合时间、空间信息,很好地支持多传感器、多任务的协同工作。
在整个感知架构的设计中,Nullmax对BEV + Transformer的技术架构进行了充分的考虑,在技术研发和项目落地两方面同步进行了大量工作,取得了不错进展。
在自动驾驶中,BEV(鸟瞰图)视角下的感知输出,能够更好地为规划、控制等下游任务服务,因此设计一个BEV-AI的技术架构,对于行泊一体方案来说很有意义。
这个架构的输入,是多个相机拍摄的图像,输出则是自动驾驶的一系列任务,当中包含了动态障碍物的检测和预测,静态场景的理解,以及这两个基础之上的一系列下游规控任务。
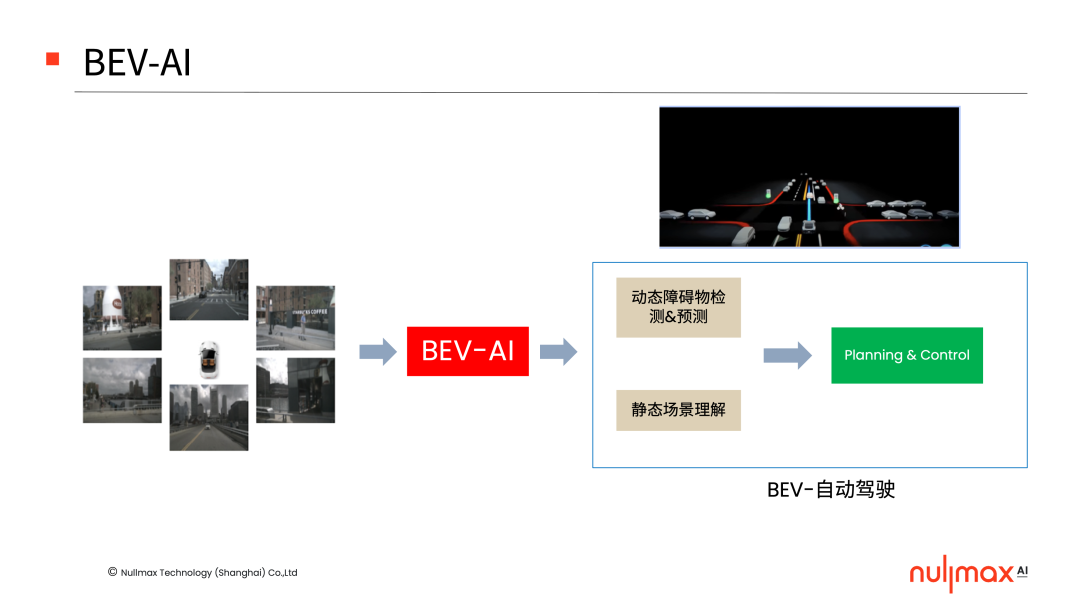
当中的挑战就在于:图像是二维的平面空间,但是BEV空间以及自动驾驶的车体坐标系是三维的立体空间,如何才能去实现图像空间和三维空间的影射?

1、BEV-CNN架构
在传统的CNN(卷积神经网络)层面,天然的想法就是去做纯粹的端到端方法。输入一张图片,直接输出三维结果,不利用相机参数。
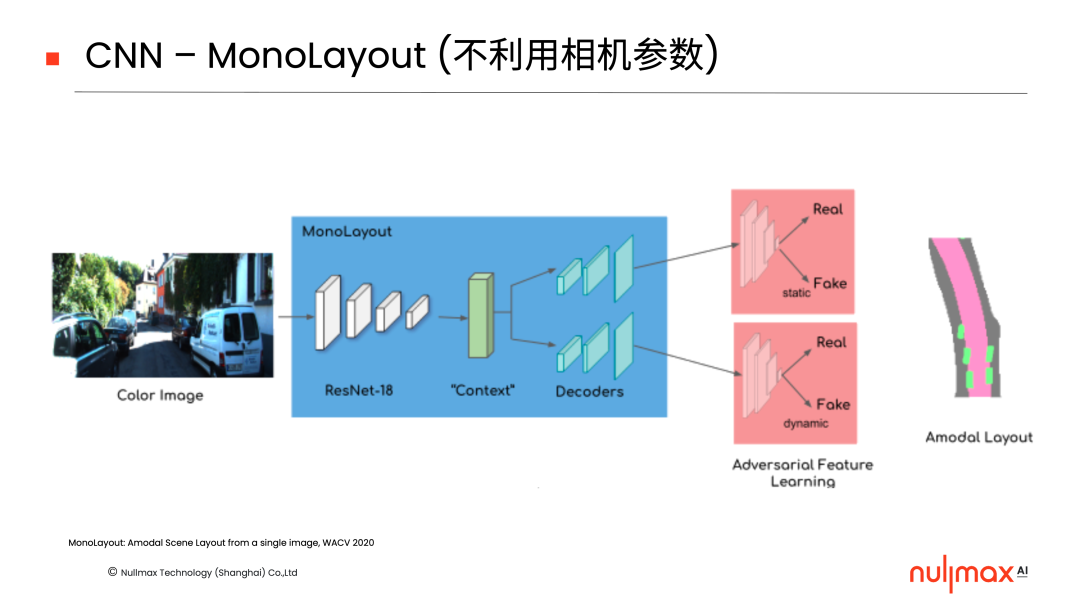
但是,相机对三维世界的成像遵循着一些原理,相机参数其实也能派上用场。比如,三维世界中的一个点,它可以通过相机的外参投到相机的三维坐标系中,然后再通过透视变换投到图像平面,完成3D到2D的转换。
在CNN当中,利用相机参数和成像原理,实现3D和2D信息关联的方法可以总结为两种。一种是在后端,利用3D到2D的投影,即一个光心射线上面所有的3D点都会投影到一个2D像素上,完成3D和2D信息的关联。知名的OFT算法,就是这一类方法的代表性工作。
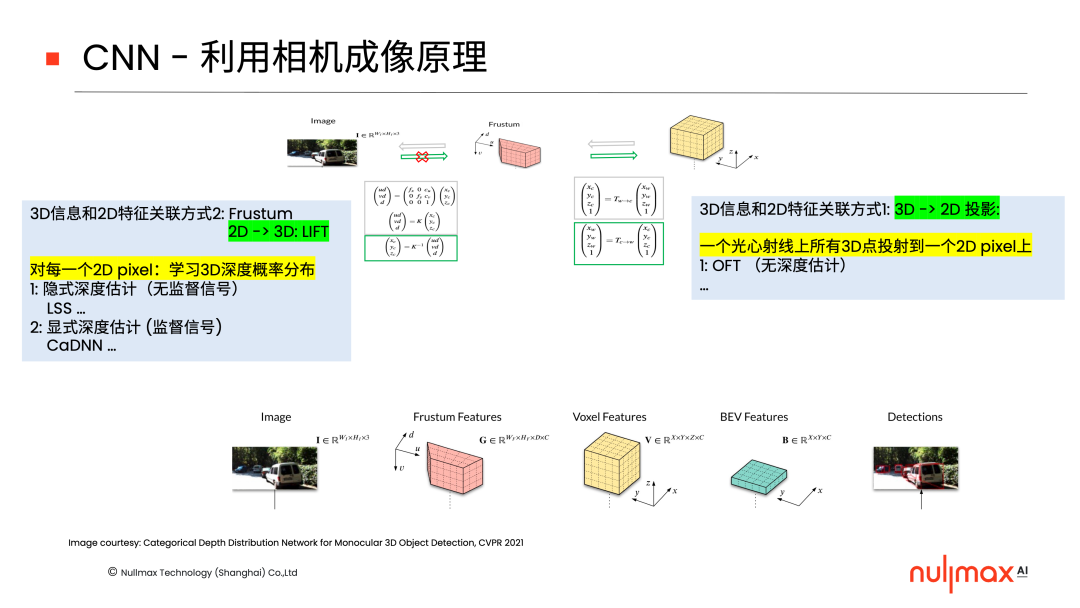
另外一种是在前端,让每一个像素学习三维深度的分布,把2D空间lift成3D空间。这当中又可以细分为两种方式,一种是隐式的学习,典型的算法有LSS,对每个点都要学一个特征,同时隐式地学习该点深度的概率分布;另一种则是显式估计每个像素的深度,比如CaDNN。
2、BEV-Transformer架构
在有了Transformer之后,它天然提供了一种机制,可以利用decoder中的cross-attention(交叉注意力)机制,架接3D空间和2D图像空间的关系。
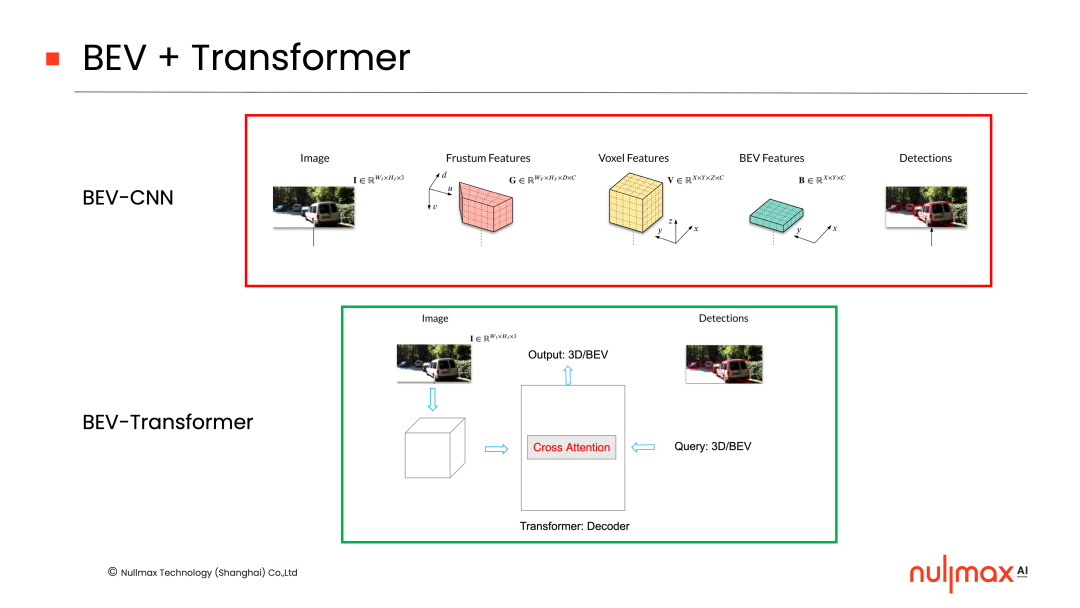
BEV-Transformer的实现方式也可分为两类,一类是通过cross-attention机制,在后端加入3D信息和2D特征的关联,它可以进一步细分为利用相机参数、不利用相机参数两种方式,比如Nullmax提出的BEVSegFormer,就是不利用相机参数的形式。
另一类是在前端,通过Frustum(视锥)的方式,2D特征上面直接加入3D信息,PETR的一系列工作就是这方面的研究。
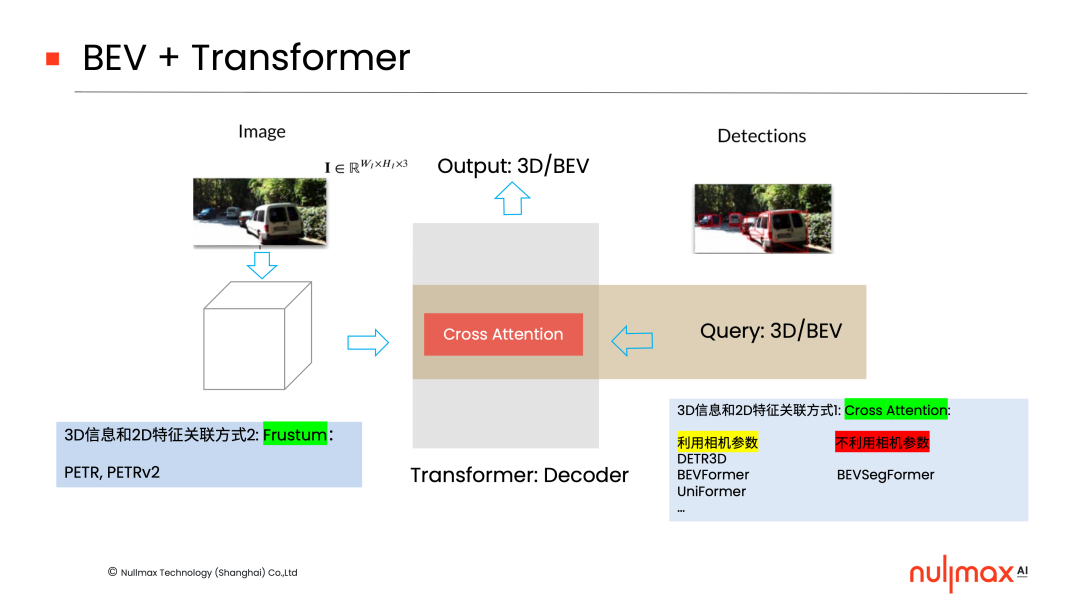
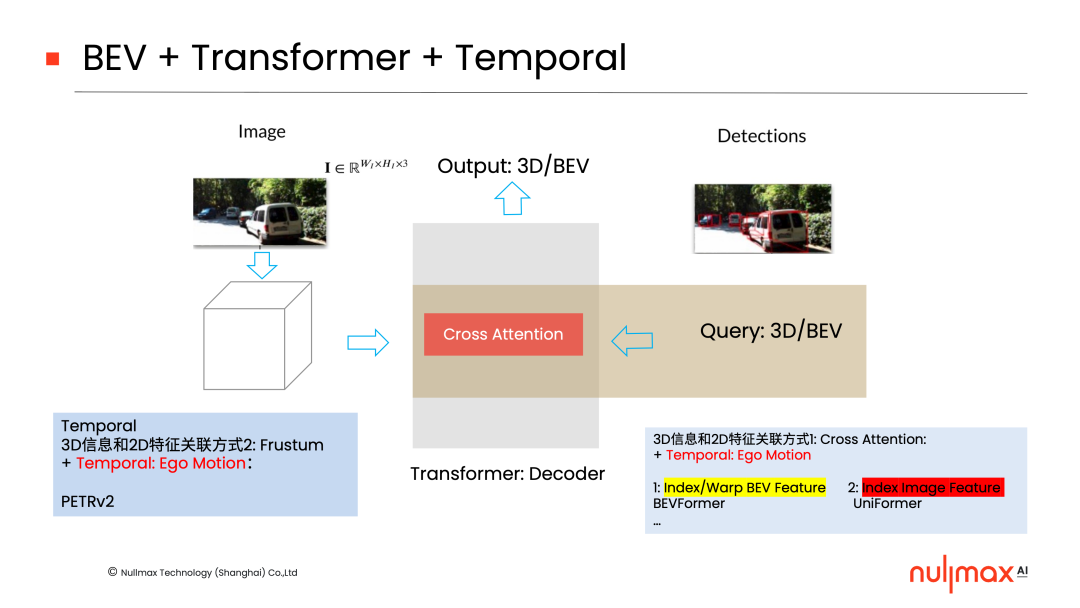
此外,在BEV + Transformer的基础上,也可以加入temporal(时间)的信息。
具体来说,就是利用temporal当中的ego motion(自运动)信息。比如,三维世界通过ego motion在后端去关联;或者在前端,通过两个相机坐标系之间的ego motion将3D信息叠加进去,然后在2D特征上面去做任务。
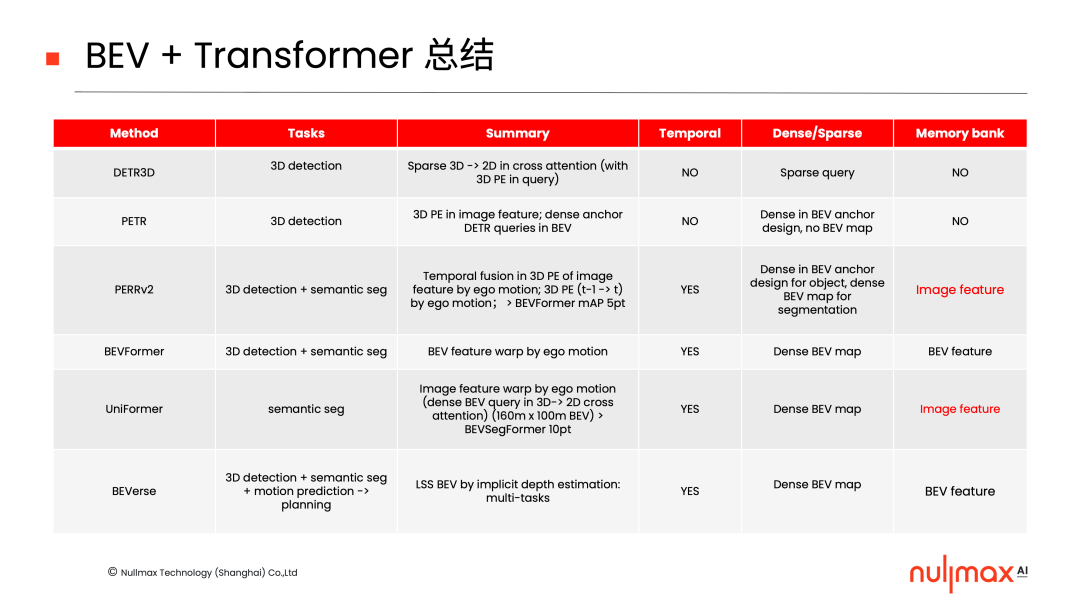
目前BEV + Transformer的方法比较多,我们对比较主流的几种方式做了一个简单的总结。
3、Nullmax的多相机BEV方案
Nullmax正在开发多相机BEV方案,这些工作与前述的工作有所不同,面临一些独特的挑战。

当中有两个非常关键的问题:一是支持任意多个相机,二是不依赖相机参数。
此前,Nullmax提出的BEVSegFormer就是当中的一项工作(现已被WACV 2023录用),面向任意数量相机的BEV语义分割,为自动驾驶在线实时构建局部地图。它在不利用相机参数的情况下,可以完成二维图像和三维感知的关联。「点击查看详尽解读」
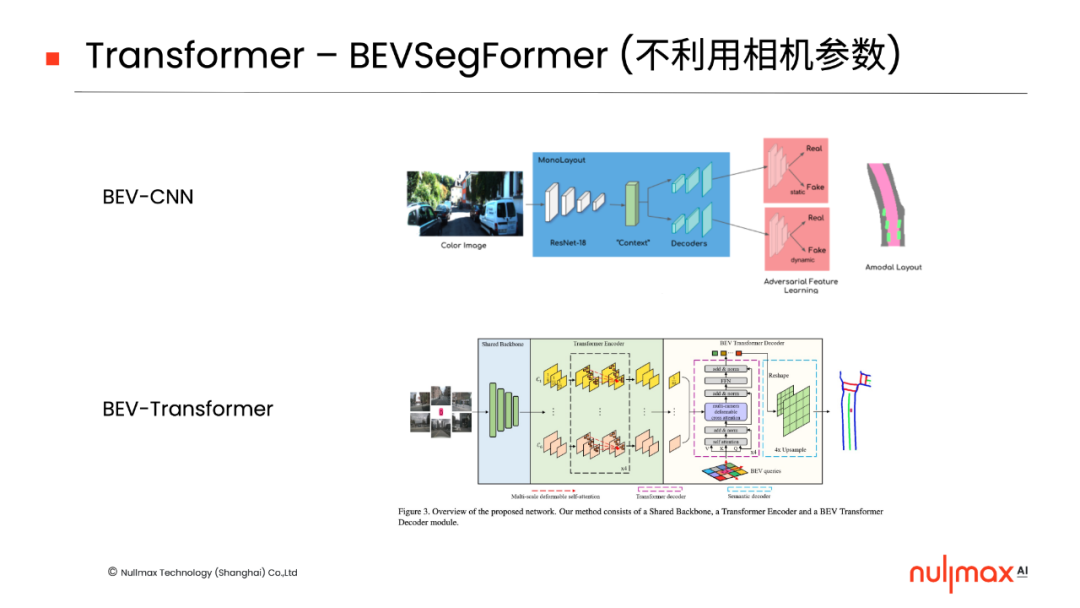
在nuScenes数据集上,BEVSegFormer相比于HDMapNet,效果提升了10个百分点。
除此之外,显式构建BEV是一个难点,对于空间中只有少数几个目标的任务,例如车道线,Nullmax提出了不显式构建BEV的方法,直接计算三维车道线的新范式。
这是Nullmax近期在3D车道线检测方面的工作之一,通过设计sparse的curve query来完成车道线检测。在Apollo数据集上,Nullmax的3D车道线检测方法对比PersFormer,效果进一步提升。「点击查看详尽解读」
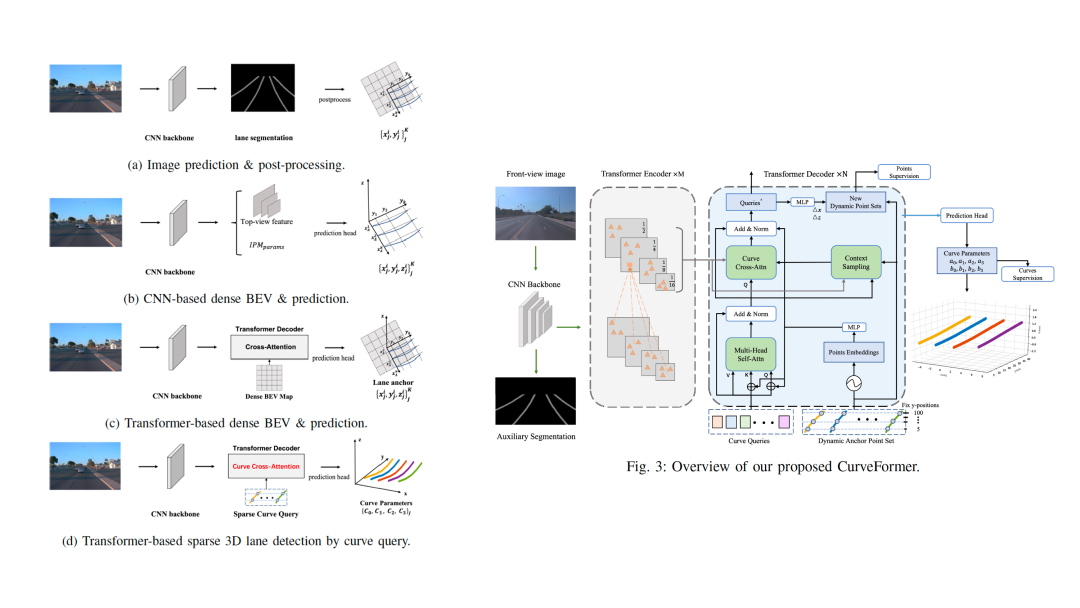
同样的,Nullmax也将3D目标检测的一些工作扩展到了量产应用中,特别是在低算力平台上进行BEV视角的检测。比如近期交付的一个量产方案,就是用8 TOPS算力实现4个周视相机的3D障碍物检测,当中的优化工作,非常具有挑战。

在3D障碍物检测方面,BEV + Transformer架构融合多个相机信息,可以带来一些明显的优势。
在多相机的感知系统中,如果进行障碍物检测,比较传统的方案是每个相机单独工作。这会导致系统的工作量比较大,每个相机都要完成目标检测、跟踪、测距,还要完成不同相机的ReID(重识别)。同时,这也给跨相机的融合带来很大挑战,比如截断车辆的检测或者融合。

如果技术架构的输出是BEV视角,或者车体坐标下的三维感知结果的话,那么这个工作就可以简化,准确率也能提升。
总体而言,Nullmax目前已经在基于BEV的多相机感知方面完成了系列工作,包括BEV + Transformer的局部地图、3D车道线检测、3D目标检测,以及在高、中、低算力嵌入式平台的上线。
Nullmax希望做出的BEV + Transformer架构能够适配多个相机、不同相机,以及不同相机的选型、内参、外参等等因素,提供一个真正平台化的产品。

同时,我们还在进行一些这里没有介绍的工作,包括BEV视角下的规划控制,以及支撑BEV + Transformer技术架构的关键任务,比如离线的4D Auto-GT(自动化4D标注真值)。
最终,我们希望完成一套可在车端实时运行BEV + Transformer基础架构的整体方案,同时支持感知、预测、规划任务,并在高、中、低算力平台上完成落地。
审核编辑 :李倩
-
嵌入式
+关注
关注
5212文章
20762浏览量
338623 -
自动驾驶
+关注
关注
795文章
15054浏览量
181976 -
Transformer
+关注
关注
0文章
156浏览量
6973 -
LLM
+关注
关注
1文章
351浏览量
1407
原文标题:Nullmax研习社 | 面向行泊一体,如何打造BEV + Transformer的技术架构?
文章出处:【微信号:Nullmax,微信公众号:Nullmax纽劢】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Transformer如何让自动驾驶大模型获得思考能力?
为具身智能打造“中国底座”:灵境智源德沃夏克架构荣获高工金球奖

自动驾驶BEV Camera数据采集系统:高精度时间同步解决方案

自动驾驶BEV Camera数据采集:时间同步技术解析与康谋解决方案

Transformer如何让自动驾驶变得更聪明?
赋能 BEV 感知课题!高校科研多传感器时间同步方案

图解AI核心技术:大模型、RAG、智能体、MCP
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
自动驾驶中Transformer大模型会取代深度学习吗?

Transformer在端到端自动驾驶架构中是何定位?
【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
浅析4D-bev标注技术在自动驾驶领域的重要性
Transformer架构中编码器的工作流程

Transformer架构概述




评论