 机器学习领域将算法按照学习方式分类进行问题解决
机器学习领域将算法按照学习方式分类进行问题解决

根据数据类型的不同,对一个问题的建模有不同的方式。在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。
1. 监督式学习:
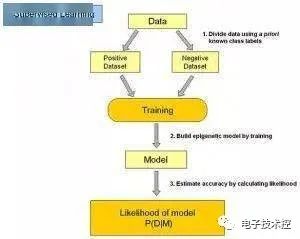
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network) 2. 非监督式学习:
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。 3. 半监督式学习:
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。 4. 强化学习:
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning) 在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。而强化学习更多的应用在机器人控制及其他需要进行系统控制的领域。 5. 算法类似性 根据算法的功能和形式的类似性,我们可以把算法分类,比如说基于树的算法,基于神经网络的算法等等。当然,机器学习的范围非常庞大,有些算法很难明确归类到某一类。而对于有些分类来说,同一分类的算法可以针对不同类型的问题。这里,我们尽量把常用的算法按照最容易理解的方式进行分类。 6. 回归算法:
回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。在机器学习领域,人们说起回归,有时候是指一类问题,有时候是指一类算法,这一点常常会使初学者有所困惑。常见的回归算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing) 7. 基于实例的算法
基于实例的算法常常用来对决策问题建立模型,这样的模型常常先选取一批样本数据,然后根据某些近似性把新数据与样本数据进行比较。通过这种方式来寻找最佳的匹配。因此,基于实例的算法常常也被称为“赢家通吃”学习或者“基于记忆的学习”。常见的算法包括 k-Nearest Neighbor(KNN), 学习矢量量化(Learning Vector Quantization, LVQ),以及自组织映射算法(Self-Organizing Map , SOM) 8. 正则化方法
正则化方法是其他算法(通常是回归算法)的延伸,根据算法的复杂度对算法进行调整。正则化方法通常对简单模型予以奖励而对复杂算法予以惩罚。常见的算法包括:Ridge Regression,Least Absolute Shrinkage and Selection Operator(LASSO),以及弹性网络(Elastic Net)。 9. 决策树学习
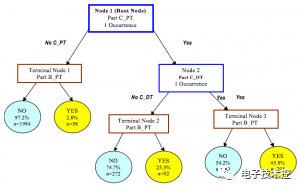
决策树算法根据数据的属性采用树状结构建立决策模型, 决策树模型常常用来解决分类和回归问题。常见的算法包括:分类及回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest), 多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine, GBM) 10. 贝叶斯方法
贝叶斯方法算法是基于贝叶斯定理的一类算法,主要用来解决分类和回归问题。常见算法包括:朴素贝叶斯算法,平均单依赖估计(Averaged One-Dependence Estimators, AODE),以及Bayesian Belief Network(BBN)。 11. 基于核的算法
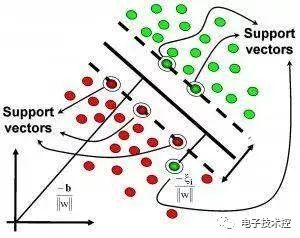
基于核的算法中最著名的莫过于支持向量机(SVM)了。基于核的算法把输入数据映射到一个高阶的向量空间, 在这些高阶向量空间里, 有些分类或者回归问题能够更容易的解决。常见的基于核的算法包括:支持向量机(Support Vector Machine, SVM), 径向基函数(Radial Basis Function ,RBF), 以及线性判别分析(Linear Discriminate Analysis ,LDA)等 12.聚类算法
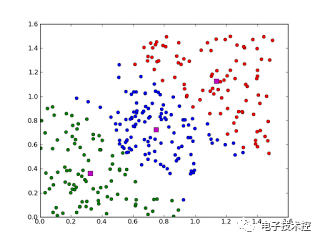
聚类,就像回归一样,有时候人们描述的是一类问题,有时候描述的是一类算法。聚类算法通常按照中心点或者分层的方式对输入数据进行归并。所以的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类。常见的聚类算法包括 k-Means算法以及期望最大化算法(Expectation Maximization, EM)。 13. 关联规则学习
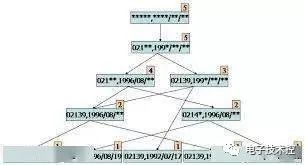
关联规则学习通过寻找最能够解释数据变量之间关系的规则,来找出大量多元数据集中有用的关联规则。常见算法包括 Apriori算法和Eclat算法等。 14. 人工神经网络
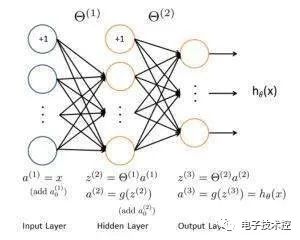
人工神经网络算法模拟生物神经网络,是一类模式匹配算法。通常用于解决分类和回归问题。人工神经网络是机器学习的一个庞大的分支,有几百种不同的算法。(其中深度学习就是其中的一类算法,我们会单独讨论),重要的人工神经网络算法包括:感知器神经网络(Perceptron Neural Network), 反向传递(Back Propagation), Hopfield网络,自组织映射(Self-Organizing Map, SOM)。学习矢量量化(Learning Vector Quantization, LVQ) 15. 深度学习
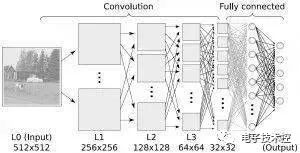
深度学习算法是对人工神经网络的发展。在近期赢得了很多关注, 特别是百度也开始发力深度学习后, 更是在国内引起了很多关注。在计算能力变得日益廉价的今天,深度学习试图建立大得多也复杂得多的神经网络。很多深度学习的算法是半监督式学习算法,用来处理存在少量未标识数据的大数据集。常见的深度学习算法包括:受限波尔兹曼机(Restricted Boltzmann Machine, RBN), Deep Belief Networks(DBN),卷积网络(Convolutional Network), 堆栈式自动编码器(Stacked Auto-encoders)。 16. 降低维度算法
像聚类算法一样,降低维度算法试图分析数据的内在结构,不过降低维度算法是以非监督学习的方式试图利用较少的信息来归纳或者解释数据。这类算法可以用于高维数据的可视化或者用来简化数据以便监督式学习使用。 常见的算法包括:主成份分析(Principle Component Analysis, PCA),偏最小二乘回归(Partial Least Square Regression,PLS), Sammon映射,多维尺度(Multi-Dimensional Scaling, MDS), 投影追踪(Projection Pursuit)等。 17. 集成算法:
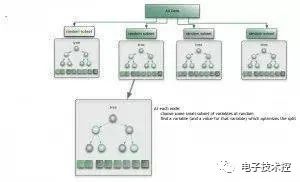
集成算法用一些相对较弱的学习模型独立地就同样的样本进行训练,然后把结果整合起来进行整体预测。集成算法的主要难点在于究竟集成哪些独立的较弱的学习模型以及如何把学习结果整合起来。 这是一类非常强大的算法,同时也非常流行。常见的算法包括:Boosting, Bootstrapped Aggregation(Bagging), AdaBoost,堆叠泛化(Stacked Generalization, Blending),梯度推进机(Gradient Boosting Machine, GBM),随机森林(Random Forest)。 常见机器学习算法优缺点: 朴素贝叶斯: 1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。 2. 计算公式如下:
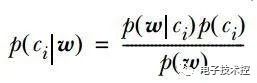
其中一项条件概率可以通过朴素贝叶斯条件独立展开。要注意一点就是的计算方法,而由朴素贝叶斯的前提假设可知,=,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。 3. 如果中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式)。 朴素贝叶斯的优点:对小规模的数据表现很好,适合多分类任务,适合增量式训练。 缺点:对输入数据的表达形式很敏感。 决策树:决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。 信息熵的计算公式如下: 其中的n代表有n个分类类别(比如假设是2类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。 现在选中一个属性xi用来进行分枝,此时分枝规则是:如果xi=vx的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’=p1*H1+p2*H2.,则此时的信息增益ΔH=H-H’。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。 决策树的优点:计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征; 缺点:容易过拟合(后续出现了随机森林,减小了过拟合现象)。 Logistic回归:Logistic是用来分类的,是一种线性分类器,需要注意的地方有: 1. logistic函数表达式为: 其导数形式为:
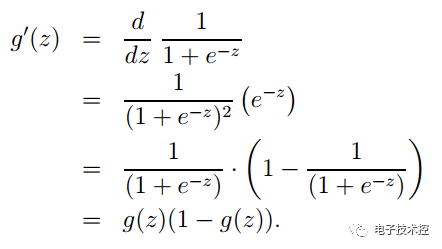
2. logsitc回归方法主要是用最大似然估计来学习的,所以单个样本的后验概率为: 到整个样本的后验概率:
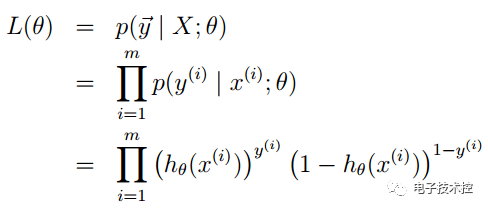
其中: 通过对数进一步化简为: 3. 其实它的loss function为-l(θ),因此我们需使loss function最小,可采用梯度下降法得到。梯度下降法公式为: Logistic回归优点: 1. 实现简单 2. 分类时计算量非常小,速度很快,存储资源低; 缺点: 1. 容易欠拟合,一般准确度不太高 2. 只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分; 线性回归: 线性回归才是真正用于回归的,而不像logistic回归是用于分类,其基本思想是用梯度下降法对最小二乘法形式的误差函数进行优化,当然也可以用normal equation直接求得参数的解,结果为: 而在LWLR(局部加权线性回归)中,参数的计算表达式为: 因为此时优化的是: 由此可见LWLR与LR不同,LWLR是一个非参数模型,因为每次进行回归计算都要遍历训练样本至少一次。 线性回归优点:实现简单,计算简单; 缺点:不能拟合非线性数据; KNN算法:KNN即最近邻算法,其主要过程为: 1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等); 2. 对上面所有的距离值进行排序; 3. 选前k个最小距离的样本; 4. 根据这k个样本的标签进行投票,得到最后的分类类别; 如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响。但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式技术来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。 近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。 注:马氏距离一定要先给出样本集的统计性质,比如均值向量,协方差矩阵等。关于马氏距离的介绍如下: KNN算法的优点: 1. 思想简单,理论成熟,既可以用来做分类也可以用来做回归; 2. 可用于非线性分类; 3. 训练时间复杂度为O(n); 4. 准确度高,对数据没有假设,对outlier不敏感; 缺点: 1. 计算量大; 2. 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少); 3. 需要大量的内存; SVM: 要学会如何使用libsvm以及一些参数的调节经验,另外需要理清楚svm算法的一些思路: 1. svm中的最优分类面是对所有样本的几何裕量最大(为什么要选择最大间隔分类器,请从数学角度上说明?网易深度学习岗位面试过程中有被问到。答案就是几何间隔与样本的误分次数间存在关系:
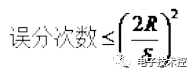
,其中的分母就是样本到分类间隔距离,分子中的R是所有样本中的最长向量值),即: 经过一系列推导可得为优化下面原始目标: 2. 下面来看看拉格朗日理论:
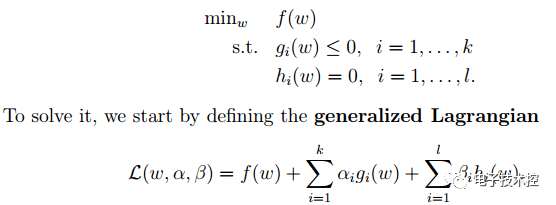
可以将1中的优化目标转换为拉格朗日的形式(通过各种对偶优化,KKD条件),最后目标函数为: 我们只需要最小化上述目标函数,其中的α为原始优化问题中的不等式约束拉格朗日系数。 3. 对2中最后的式子分别w和b求导可得:
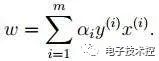
由上面第1式子可以知道,如果我们优化出了α,则直接可以求出w了,即模型的参数搞定。而上面第2个式子可以作为后续优化的一个约束条件。 4. 对2中最后一个目标函数用对偶优化理论可以转换为优化下面的目标函数:
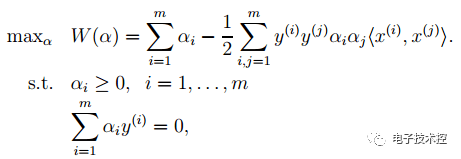
而这个函数可以用常用的优化方法求得α,进而求得w和b。 5. 按照道理,svm简单理论应该到此结束。不过还是要补充一点,即在预测时有:
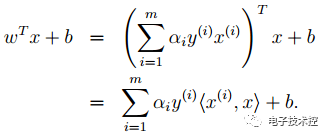
那个尖括号我们可以用核函数代替,这也是svm经常和核函数扯在一起的原因。 6. 最后是关于松弛变量的引入,因此原始的目标优化公式为: 此时对应的对偶优化公式为:
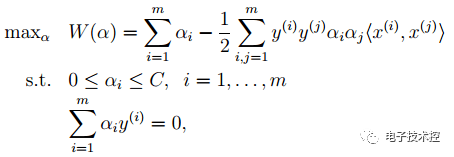
与前面的相比只是α多了个上界。 SVM算法优点: 1. 可用于线性/非线性分类,也可以用于回归; 2. 低泛化误差; 3. 容易解释; 4. 计算复杂度较低; 缺点: 1. 对参数和核函数的选择比较敏感; 2. 原始的SVM只比较擅长处理二分类问题; Boosting: 主要以Adaboost为例,首先来看看Adaboost的流程图,如下:
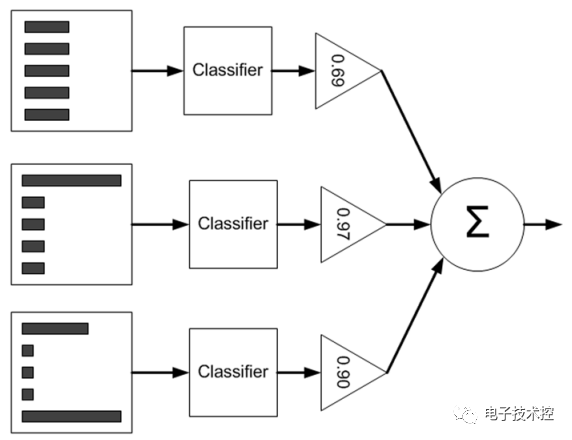
从图中可以看到,在训练过程中我们需要训练出多个弱分类器(图中为3个),每个弱分类器是由不同权重的样本(图中为5个训练样本)训练得到(其中第一个弱分类器对应输入样本的权值是一样的),而每个弱分类器对最终分类结果的作用也不同,是通过加权平均输出的,权值见上图中三角形里面的数值。那么这些弱分类器和其对应的权值是怎样训练出来的呢? 下面通过一个例子来简单说明,假设的是5个训练样本,每个训练样本的维度为2,在训练第一个分类器时5个样本的权重各为0.2. 注意这里样本的权值和最终训练的弱分类器组对应的权值α是不同的,样本的权重只在训练过程中用到,而α在训练过程和测试过程都有用到。 现在假设弱分类器是带一个节点的简单决策树,该决策树会选择2个属性(假设只有2个属性)的一个,然后计算出这个属性中的最佳值用来分类。 Adaboost的简单版本训练过程如下: 1. 训练第一个分类器,样本的权值D为相同的均值。通过一个弱分类器,得到这5个样本(请对应书中的例子来看,依旧是machine learning in action)的分类预测标签。与给出的样本真实标签对比,就可能出现误差(即错误)。如果某个样本预测错误,则它对应的错误值为该样本的权重,如果分类正确,则错误值为0. 最后累加5个样本的错误率之和,记为ε。 2. 通过ε来计算该弱分类器的权重α,公式如下:
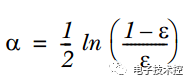
3. 通过α来计算训练下一个弱分类器样本的权重D,如果对应样本分类正确,则减小该样本的权重,公式为:
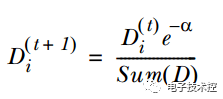
如果样本分类错误,则增加该样本的权重,公式为:
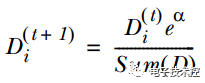
4. 循环步骤1,2,3来继续训练多个分类器,只是其D值不同而已。 测试过程如下: 输入一个样本到训练好的每个弱分类中,则每个弱分类都对应一个输出标签,然后该标签乘以对应的α,最后求和得到值的符号即为预测标签值。 Boosting算法的优点: 1. 低泛化误差; 2. 容易实现,分类准确率较高,没有太多参数可以调; 3. 缺点: 4. 对outlier比较敏感; 聚类: 根据聚类思想划分: 1. 基于划分的聚类: K-means, k-medoids(每一个类别中找一个样本点来代表),CLARANS. k-means是使下面的表达式值最小:
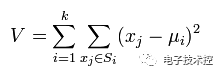
k-means算法的优点: (1)k-means算法是解决聚类问题的一种经典算法,算法简单、快速。 (2)对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度大约是O(nkt),其中n是所有对象的数目,k是簇的数目,t是迭代的次数。通常k<
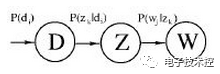
其中更深的颜色代表去掉小特征值重构时的三个矩阵。 果m代表商品的个数,n代表用户的个数,则U矩阵的每一行代表商品的属性,现在通过降维U矩阵(取深色部分)后,每一个商品的属性可以用更低的维度表示(假设为k维)。这样当新来一个用户的商品推荐向量X,则可以根据公式X'*U1*inv(S1)得到一个k维的向量,然后在V’中寻找最相似的那一个用户(相似度测量可用余弦公式等),根据这个用户的评分来推荐(主要是推荐新用户未打分的那些商品)。 pLSA:由LSA发展过来,而早期LSA的实现主要是通过SVD分解。pLSA的模型图如下
公式中的意义如下:
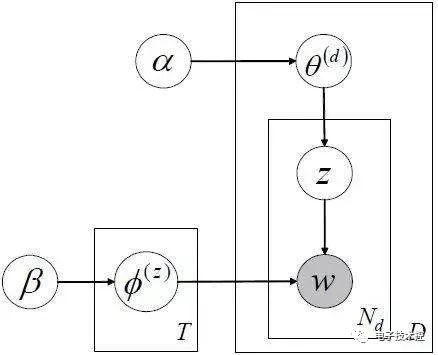
LDA主题模型,概率图如下:
和pLSA不同的是LDA中假设了很多先验分布,且一般参数的先验分布都假设为Dirichlet分布,其原因是共轭分布时先验概率和后验概率的形式相同。 GDBT:GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),好像在阿里内部用得比较多(所以阿里算法岗位面试时可能会问到),它是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的输出结果累加起来就是最终答案。 它在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。近些年更因为被用于搜索排序的机器学习模型而引起大家关注。 GBDT是回归树,不是分类树。其核心就在于,每一棵树是从之前所有树的残差中来学习的。为了防止过拟合,和Adaboosting一样,也加入了boosting这一项。 Regularization作用是 1. 数值上更容易求解; 2. 特征数目太大时更稳定; 3. 控制模型的复杂度,光滑性。复杂性越小且越光滑的目标函数泛化能力越强。而加入规则项能使目标函数复杂度减小,且更光滑。 4. 减小参数空间;参数空间越小,复杂度越低。 5. 系数越小,模型越简单,而模型越简单则泛化能力越强(Ng宏观上给出的解释)。 6. 可以看成是权值的高斯先验。 异常检测:可以估计样本的密度函数,对于新样本直接计算其密度,如果密度值小于某一阈值,则表示该样本异常。而密度函数一般采用多维的高斯分布。 如果样本有n维,则每一维的特征都可以看作是符合高斯分布的,即使这些特征可视化出来不太符合高斯分布,也可以对该特征进行数学转换让其看起来像高斯分布,比如说x=log(x+c), x=x^(1/c)等。异常检测的算法流程如下:
其中的ε也是通过交叉验证得到的,也就是说在进行异常检测时,前面的p(x)的学习是用的无监督,后面的参数ε学习是用的有监督。那么为什么不全部使用普通有监督的方法来学习呢(即把它看做是一个普通的二分类问题)? 主要是因为在异常检测中,异常的样本数量非常少而正常样本数量非常多,因此不足以学习到好的异常行为模型的参数,因为后面新来的异常样本可能完全是与训练样本中的模式不同。 EM算法:有时候因为样本的产生和隐含变量有关(隐含变量是不能观察的),而求模型的参数时一般采用最大似然估计,由于含有了隐含变量,所以对似然函数参数求导是求不出来的,这时可以采用EM算法来求模型的参数的(对应模型参数个数可能有多个), EM算法一般分为2步: E步:选取一组参数,求出在该参数下隐含变量的条件概率值; M步:结合E步求出的隐含变量条件概率,求出似然函数下界函数(本质上是某个期望函数)的最大值。 重复上面2步直至收敛,公式如下所示:
M步公式中下界函数的推导过程:
EM算法一个常见的例子就是GMM模型,每个样本都有可能由k个高斯产生,只不过由每个高斯产生的概率不同而已,因此每个样本都有对应的高斯分布(k个中的某一个),此时的隐含变量就是每个样本对应的某个高斯分布。 GMM的E步公式如下(计算每个样本对应每个高斯的概率): 更具体的计算公式为: M步公式如下(计算每个高斯的比重,均值,方差这3个参数):
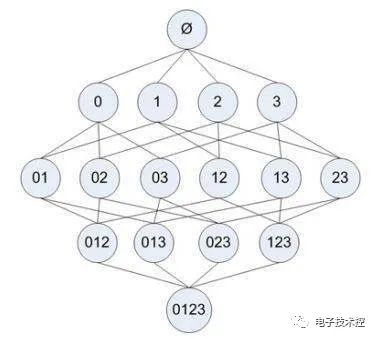
Apriori是关联分析中比较早的一种方法,主要用来挖掘那些频繁项集合。其思想是: 1. 如果一个项目集合不是频繁集合,那么任何包含它的项目集合也一定不是频繁集合; 2. 如果一个项目集合是频繁集合,那么它的任何非空子集也是频繁集合; Aprioir需要扫描项目表多遍,从一个项目开始扫描,舍去掉那些不是频繁的项目,得到的集合称为L,然后对L中的每个元素进行自组合,生成比上次扫描多一个项目的集合,该集合称为C,接着又扫描去掉那些非频繁的项目,重复… 看下面这个例子,元素项目表格: 如果每个步骤不去掉非频繁项目集,则其扫描过程的树形结构如下:
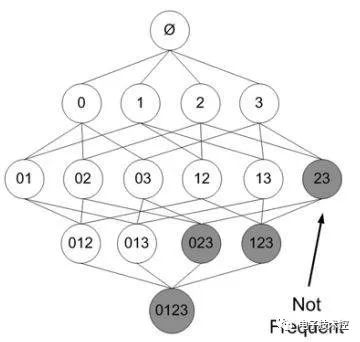
在其中某个过程中,可能出现非频繁的项目集,将其去掉(用阴影表示)为:
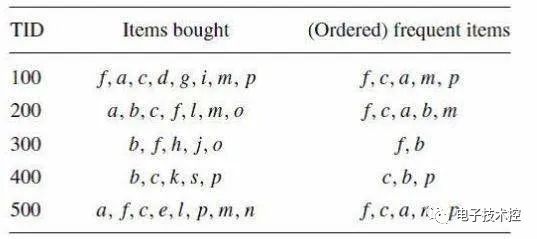
FP Growth是一种比Apriori更高效的频繁项挖掘方法,它只需要扫描项目表2次。其中第1次扫描获得当个项目的频率,去掉不符合支持度要求的项,并对剩下的项排序。第2遍扫描是建立一颗FP-Tree(frequent-patten tree)。 接下来的工作就是在FP-Tree上进行挖掘,比如说有下表:
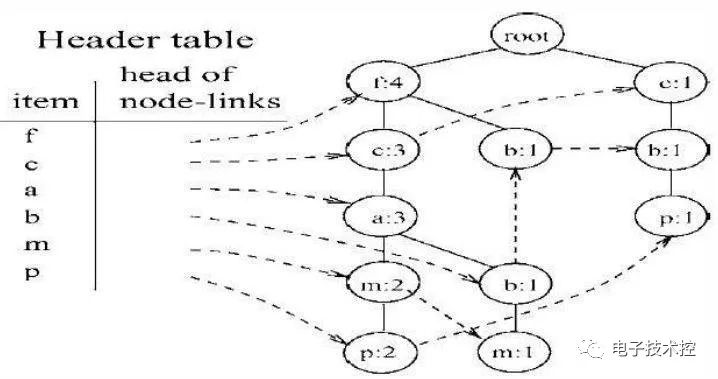
它所对应的FP_Tree如下:
然后从频率最小的单项P开始,找出P的条件模式基,用构造FP_Tree同样的方法来构造P的条件模式基的FP_Tree,在这棵树上找出包含P的频繁项集。 依次从m,b,a,c,f的条件模式基上挖掘频繁项集,有些项需要递归的去挖掘,比较麻烦,比如m节点。 来源:图灵人工智能
审核编辑:郭婷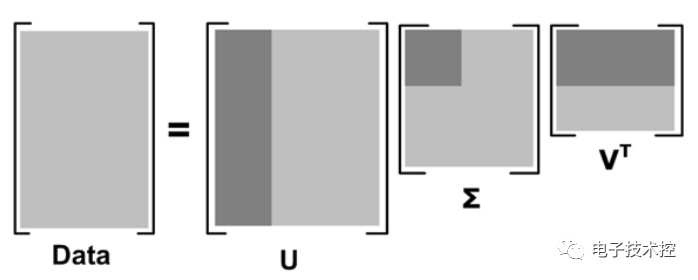


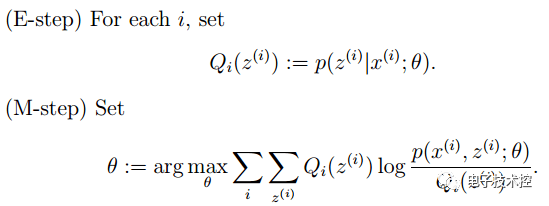
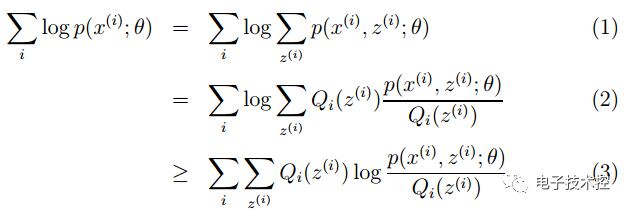

-
人工智能
+关注
关注
1821文章
50471浏览量
267610 -
机器学习
+关注
关注
67文章
8570浏览量
137381
原文标题:17个机器学习的常用算法
文章出处:【微信号:电子技术控,微信公众号:电子技术控】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
机器学习特征工程:分类变量的数值化处理方法

人工智能与机器学习在这些行业的深度应用
强化学习会让自动驾驶模型学习更快吗?

学习单片机快速方法
机器学习和深度学习中需避免的 7 个常见错误与局限性
基于ETAS嵌入式AI工具链将机器学习模型部署到量产ECU
分享一个嵌入式开发学习路线
探索RISC-V在机器人领域的潜力
如何深度学习机器视觉的应用场景
AI 驱动三维逆向:点云降噪算法工具与机器学习建模能力的前沿应用

任正非说 AI已经确定是第四次工业革命 那么如何从容地加入进来呢?
机器学习异常检测实战:用Isolation Forest快速构建无标签异常检测系统




评论