 SC-Depth系列的网络都解决了什么问题以及实现了什么效果
SC-Depth系列的网络都解决了什么问题以及实现了什么效果
0. 笔者个人体会
因为项目原因需要用到无监督单目深度估计网络,目前SC-Depth系列是非常经典的框架,因此写下这篇文章记录自己的学习经历。 深度估计其实是一个非常早的问题,早期方法主要是Structure from Motion (SfM)和Multi View Stereo (MVS)这两种。
SfM算法输入是一系列无序照片,两两照片通过特征点建立匹配关系,利用三角化方法获得稀疏点云,之后使用BA进行联合优化,输出是整个模型是三维点云和相机位姿。但此类方法获得的是稀疏点云,就是说深度图也是稀疏的。MVS与SfM原理类似,但它是对每个像素都去提取特征并进行匹配,最终可以获得稠密的深度图。
相较双目/多目深度估计而言,单目深度估计更具挑战性,这是因为单目视觉天生就存在致命缺陷:尺度模糊。近年来深度学习技术的发展,引发了一系列单目深度估计网络的问世。近期SC-DepthV3发表在了新一期的TPAMI上,对单目深度估计问题又提出了一个新的解决思路。本文将分别介绍牛津大学提出的SC-Depth系列的三个网络,探讨它们都解决了什么问题,以及实现了什么效果。
1. 为什么是无监督?
先说答案:
因为有监督太贵了!
目前单目深度估计网络在KITTI、NYU等数据集上的性能其实已经非常好了,各项定量指标也好,定性估计深度图也好,看起来已经非常完美。但任何网络、任何模型归根结底都是要落地的,只在数据集上跑一跑没办法创造实际的产能。可是深度学习本身就是依赖数据集的,如果想把一个训练好的模型拓展到实际场景中,往往需要在实际场景进行finetune。
如果是有监督网络的话,实际场景的微调就需要激光雷达、高精相机等昂贵传感器提供的ground truth。这在很大程度上就限制了有监督单目深度估计网络的实际落地。我们更想实现的目标是拿着一个相机(甚至手机)拍一组视频,就可获得每帧的深度!
那么怎么办呢?
无监督单目深度估计网络就可以很好得解决这一问题!无监督单目深度估计网络不需要提供深度真值就可以进行训练,可以在任何场景通过一组单目视频进行finetune,这就意味着网络具备极强的泛化能力! 最早的无监督单目深度估计网络来源于2016年ECCV论文“Unsupervised CNN for single view depth estimation: Geometry to the rescue.”。
网络输入是双目相机中的左右目图像,但是只估计左目图像的深度。由于左右目位姿是已知的,那么我们就可以通过左目深度图和左右目位姿去重建左图,之后去计算重建左图和真实左图之间的差异,回传损失进行训练。除这个损失外,这个网络还提出了深度值的平滑损失。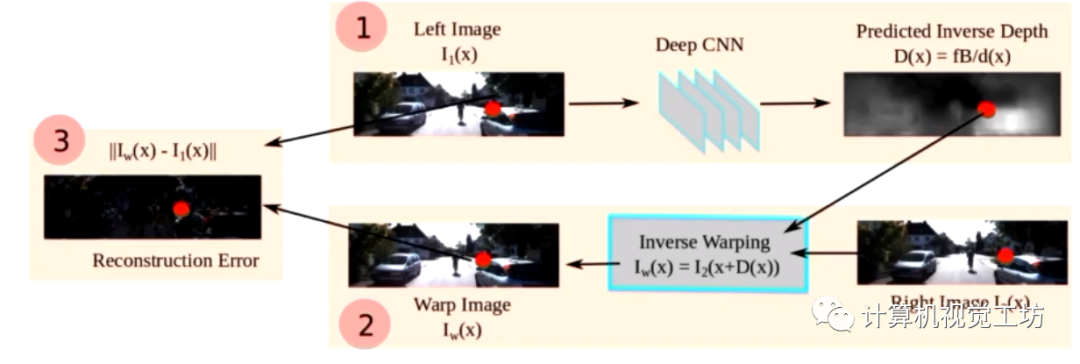
这个网络名义上确实是单目深度估计网络,因为只估计了左图的深度。但我们更希望的是网络输入是真正的单目图像。 最早的真正只使用单目图像的无监督单目深度估计网络是2017年CVPR论文“Unsupervised Learning of Depth and Ego-Motion from Video”。
这个网络与上一篇论文的原理类似,它的输入是单目视频序列中的前后两帧。首先给第一帧图像估计深度图,同时估计两帧图像中的位姿,之后利用深度图和位姿重建第一帧图像,同样去计算与真实图像之间的差异。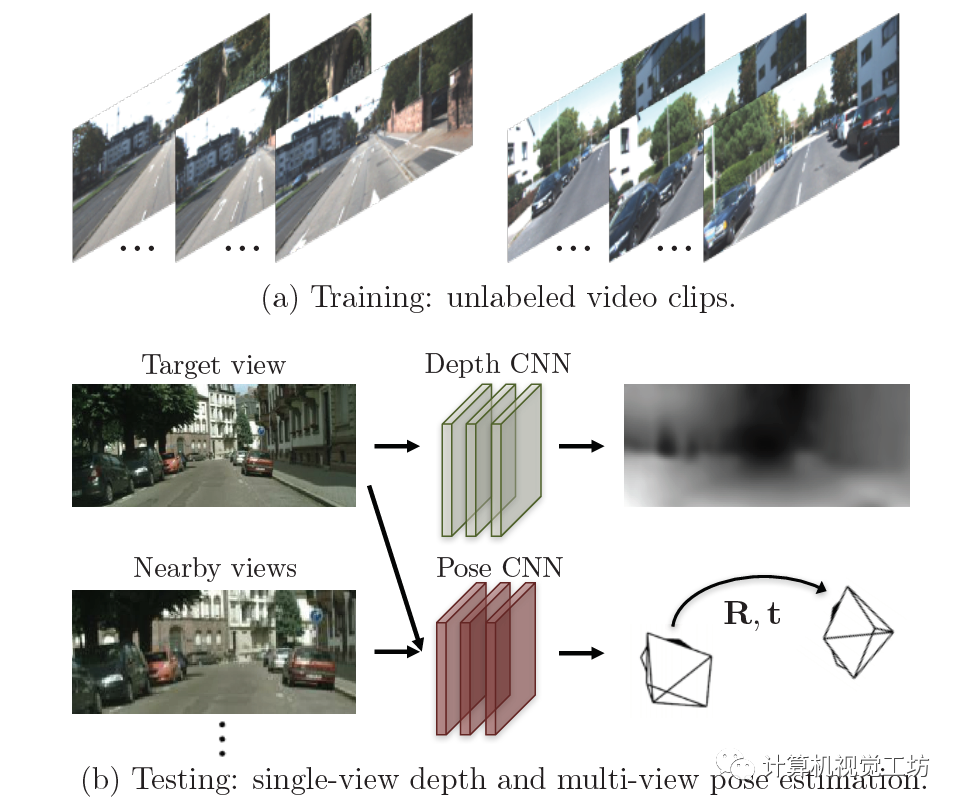
之后的SOTA方法就是大家所熟知的Monodepth2,来源于2019年ICCV论文“Digging Into Self-Supervised Monocular Depth Estimation”。其原理还是利用SfM同时估计深度网络和位姿网络。网络输入为单目视频的连续多帧图片,根据深度网络和位姿网络构建重投影图像,计算重投影误差并引入至损失函数。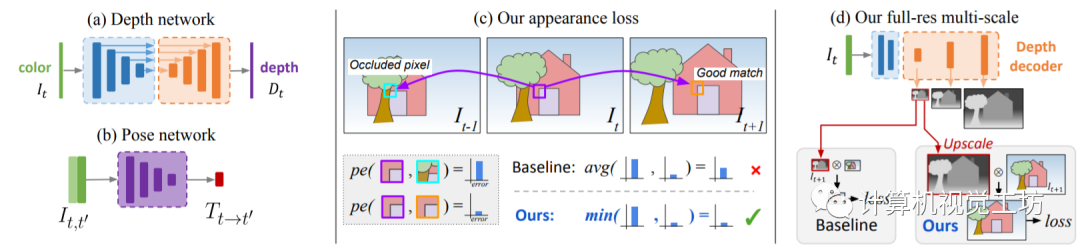
虽然近些年也出现了非常多的单目深度估计网络,但大多都是基于Monodepth2和SC-Depth框架进行的。因此,本文对其他网络结构不再赘述。
2. SC-DepthV1做了什么?
至此,开始引入本文真正的主角:SC-Depth系列。
之前的单目深度估计网络的重投影损失,更多的是利用前后帧的颜色误差进行约束,得到了比较精确的结果。但它们基本上都有一个共性问题:深度值不连续!连续几张图像之间的深度值不连续!也就是说,在不同的帧上产生尺度不一致的预测,因为它们承受了每帧图像的尺度不确定性。
这种问题这不会影响基于单个图像的任务,但对于基于视频的应用至关重要,例如不能用于VSLAM系统中的初始化。 因此,SC-DepthV1为解决此问题提出了尺度一致性约束。具体来说,就是给前后两帧图像都预测深度,利用两张图像的深度和位姿投影到3D空间中,进而去计算尺度一致性损失。
这种方法确保了相邻帧之间尺度的一致性,如果每连续两帧图像的尺度都是一致的,那么整个视频序列的深度序列也就是连续的。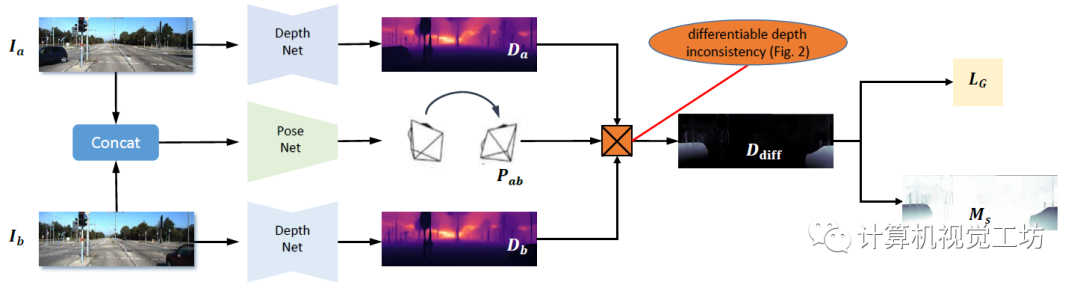
此外,SC-DepthV1还使用了一种Mask,对应视频上出现不连续的区域。作者认为这就是动态物体,通过去除这种Mask可以使得网络具备一定的动态环境鲁棒性。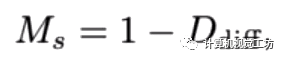
定量结果显示,SC-DepthV1取得了与Monodepth2相持平的结果。但SC-DepthV1估计出的深度图具有连续性,因此还是SC-DepthV1更胜一筹。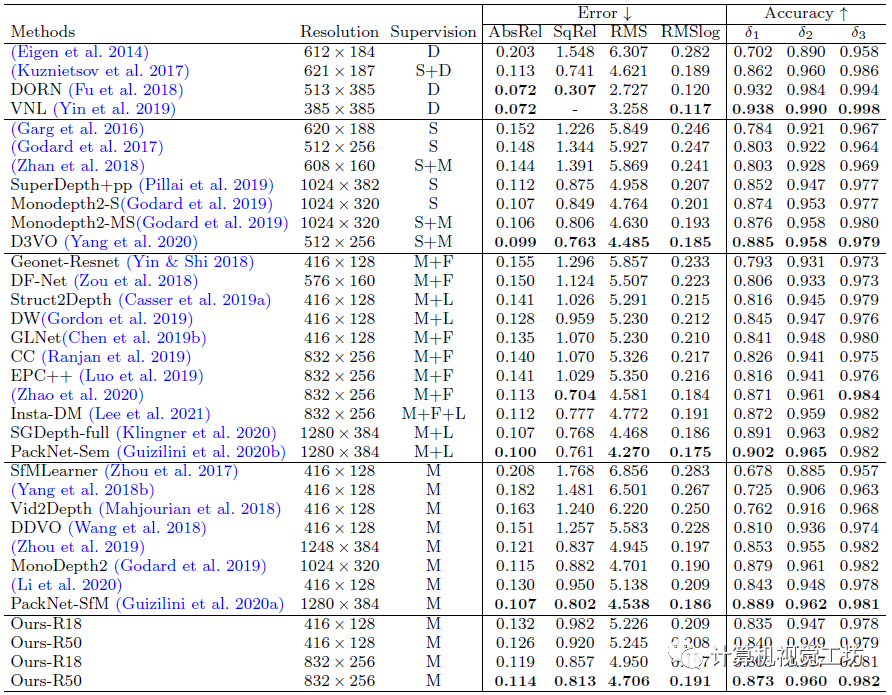
值得一提的是,SC-DepthV1在论文里除了介绍自己的定量结果外,还将单目深度估计结果引入到了ORB-SLAM2中,构建了一个伪RGB-D SLAM系统。在一些序列中,Monodepth2+ORB-SLAM2的系统由于深度不连续问题,很快跟丢。而SC-DepthV1+ORB-SLAM2的组合可以获得较好的跟踪结果。
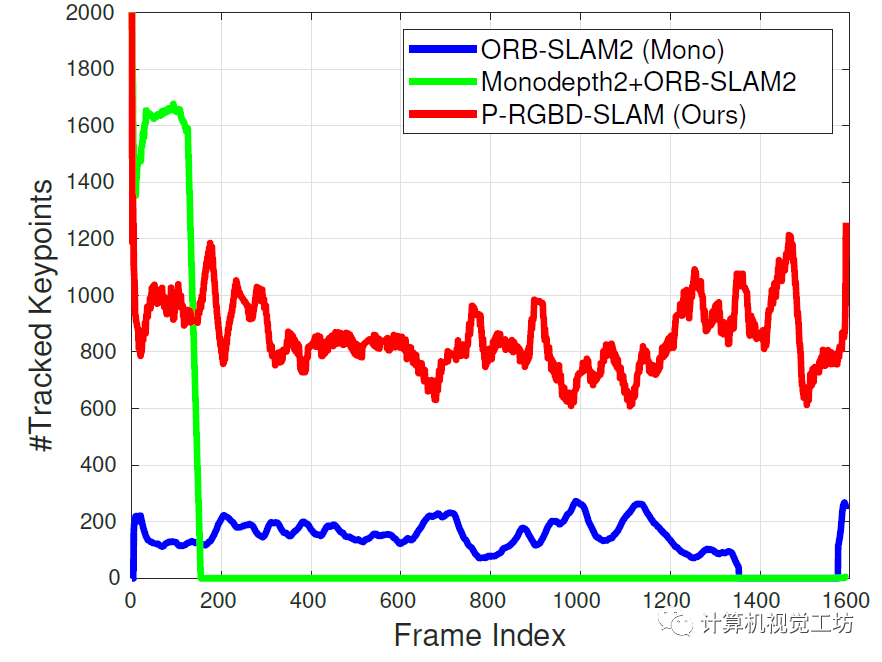
一句话总结:SC-DepthV1解决了深度连续性问题。
3. SC-DepthV2做了什么?
之前的SC-DepthV1和MonoDepth2等网络主要针对KITTI等室外场景,取得了非常不错的效果。但SC-Depth系列的作者发现,这些网络很难泛化到室内场景中,室内估计出的深度图很差。这就很奇怪了,按理说只要经过足够的训练,室内和室外场景应该是可以取得相似的精度的。
这是为什么呢?
有一些学者认为,这是因为室内场景中有大量的弱纹理区域,比如白墙。这些区域很难去提取特征,就更不用说去做特征匹配,是这些弱纹理区域导致深度估计不准。看似有一定道理,但要知道室外场景中的天空也是弱纹理区域啊,并且也占了图像中的很大一部分。
为什么同样是存在大量弱纹理场景,性能却差了那么多呢? SC-Depth系列的作者认为,室外场景中的相机运动主要是平移,旋转所占的比重很小,而室内场景正好相反。那么是不是室内场景中的旋转分量,对单目深度估计结果造成了影响呢? SC-Depth系列的作者对此进行了严密的数学推导:

这个数学推导很有意思。SC-Depth系列作者发现旋转运动和深度估计结果完全无关!但平移运动和深度估计结果却是相关的!
这个结论是什么意思呢?
也就是说,对于旋转运动来说,就算估计的很准也不会帮助单目深度估计结果,但如果估计的不准就会给深度估计带来大量噪声。而对于平移运动来说,如果估计的位姿准确是可以辅助单目深度估计结果的。 因此,SC-depthV2提出了位姿自修正网络,这个网络只估计旋转运动,并借此剔除场景中的旋转运动。
之后将第二帧图像旋转到第一张图,这样两帧图像之间的位姿就只剩下的平移运动。自此,自监督深度估计网络就可以得到很好的训练。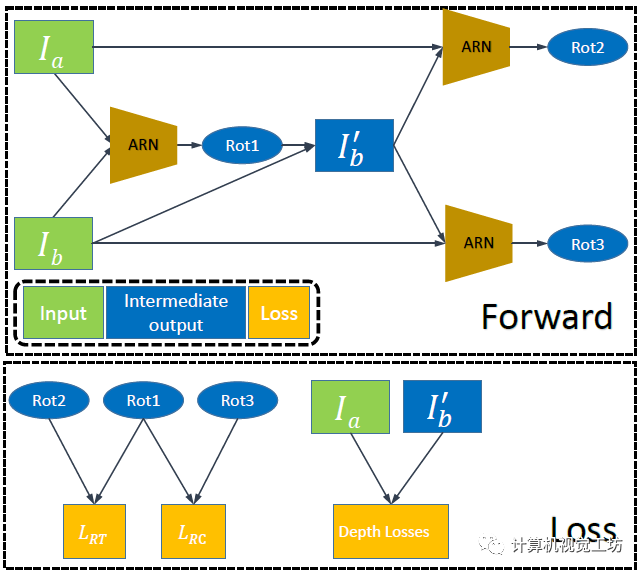
此外,SC-depthV2还提出了两个新的损失约束。这里具体解释一下:前面我们知道,Ia和Ib通过ARN生成了去除旋转运动的图像,理论上此时Ia和Ib’之间应该是不包含任何旋转的。
也就是说Ia和Ib’再进行一次ARN得到的Rot2应该为0。此外,Ib’和Ib再进行一次ARN得到的Rot3应该和第一次得到的Rot1是相等的。通过这两个约束可以完全剔除两帧之间的旋转运动,得到更好的位姿估计结果。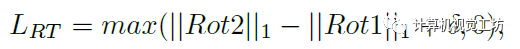
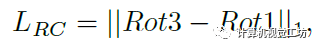
至于定量结果,由于作者主要思路就是针对室内场景中的旋转运动,因此主要评估的数据集是室内NYU。
结果显示,SC-depthV2相较于之前的方法实现了大幅提升,这也验证了作者的想法。
一句话总结:SC-DepthV2解决了旋转位姿对深度估计的影响问题。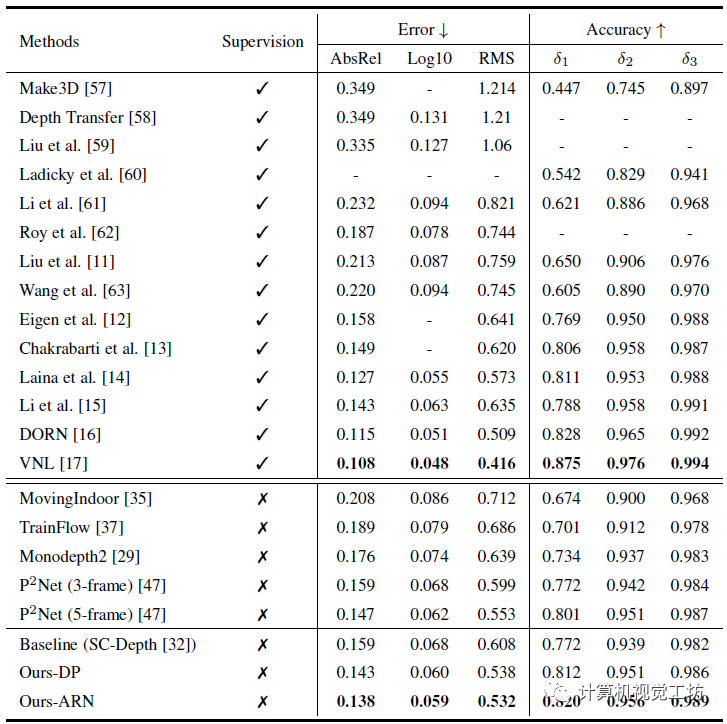
4. SC-DepthV3做了什么?
至此,其实SC-Depth系列已经做的很好了。SC-DepthV1面向室外场景,SC-DepthV2面向室内场景,可以说实现了很好的通用性和泛化能力。但SC-DepthV1和SC-DepthV2都是基于静态环境假设的,虽然作者也利用Mask剔除了一些动态物体的影响,但当应用场景是高动态环境时,算法很容易崩溃。
为了解决动态物体和遮挡问题,现有网络通常是检测动态物体,然后在训练时剔除这些区域。这些方法在训练时效果比较好,但是在推理时往往很难得到高精度。也有一些方法对每个动态对象进行建模,但网络会变得非常笨重。 因此,SC-Depth系列作者又在近日提出了SC-DepthV3,面向高动态场景的单目深度估计网络!
在各种动态场景中都可以鲁棒的运行! 具体来说,SC-DepthV3首先引入了一个在大规模数据集上有监督预训练的单目深度估计模型LeReS,并通过零样本泛化提供单图像深度先验,也就是伪深度,同时引入了一个新损失来约束网络的训练。
注意,LeReS只需要训练一次,在新场景中不需要进行finetune,因此这一网络的引入并不会加入额外的成本。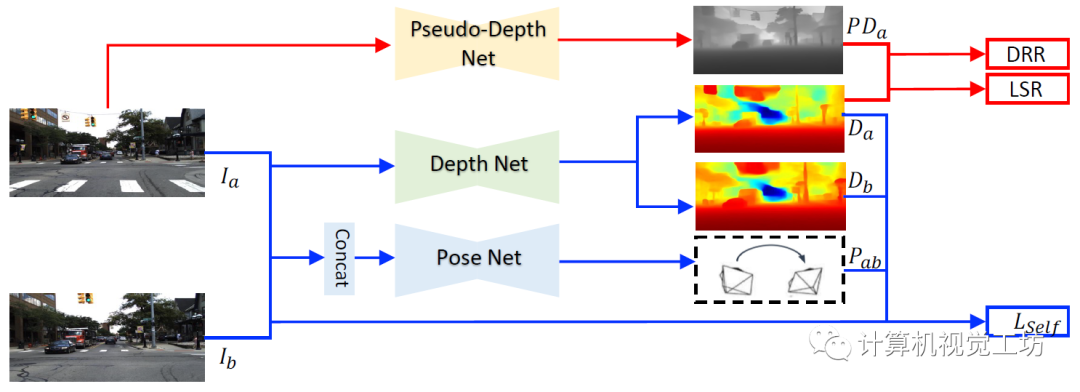
LeReS显示了很好的定性结果,但伪深度的精度很低,伪深度的误差图也说明了这一问题。不过SC-DepthV3认为经过合适的模块设计,伪深度可以很好得促进无监督单目深度估计的结果。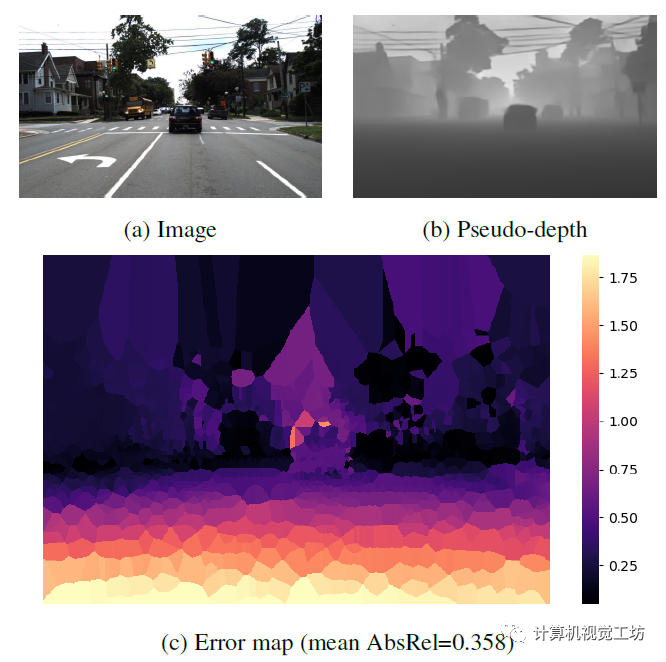
解决动态区域问题的关键是作者提出的动态区域细化(DRR)模块,该方法的来源是,作者发现伪深度在任意两个物体或像素之间保持极好的深度有序度。
因此,SC-DepthV3提取动态和静态区域之间的真值深度序信息,并使用它来规范动态区域的自监督深度估计。
为了从静态背景中分割动态区域,SC-DepthV3使用了SC-DepthV1中提出的Mask,并通过计算自监督训练中的前后向深度不一致性来生成,因此不需要外部分割网络。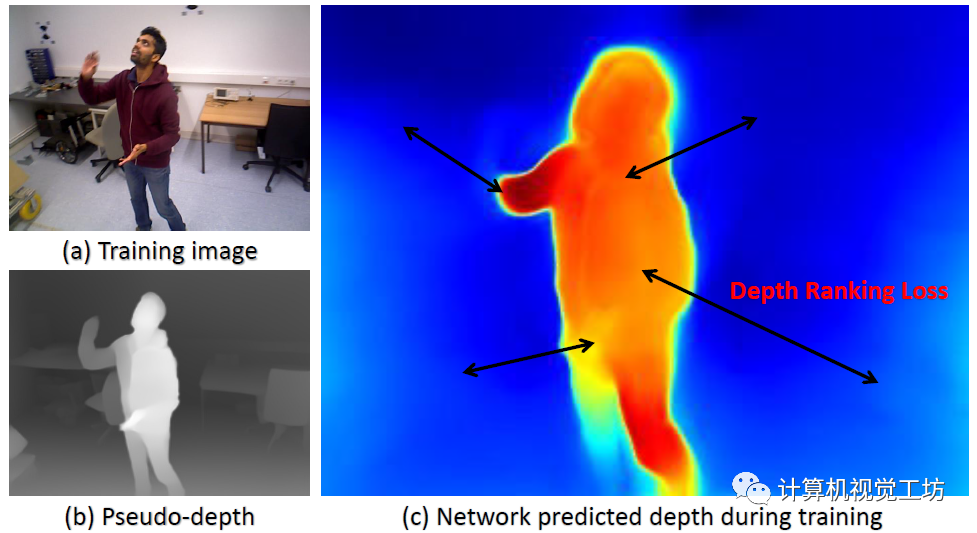
此外,伪深度显示了光滑的局部结构和物体边界。因此SC-DepthV3提出一个局部结构优化(LSR)模块来改进深度细节的自监督深度估计。该模块包含两个部分:一方面从伪深度和网络预测深度中提取表面法线,并通过应用法线匹配损失来约束;另一方面应用相对法向角度损失来约束物体边界区域的深度估计。
在损失函数的设置上,除了之前的几何一致性损失、光度损失外,SC-DepthV3还提出了边缘感知平滑损失来正则化预测的深度图。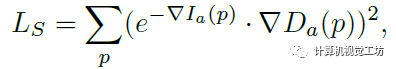
在具体的评估上,SC-DepthV3在DDAD、BONN、TUM、KITTI、NYUv2和IBims-1这六个数据集进行了大量实验,定性结果显示SC-DepthV3在动态环境中具有极强的鲁棒性。
定量结果也说明了SC-DepthV3在动态环境中的性能远超Monodepth2和SC-Depth。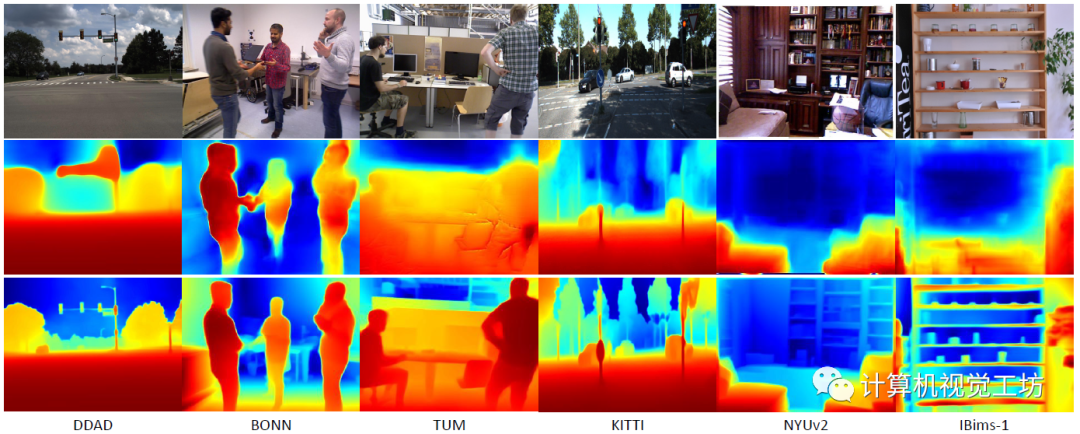
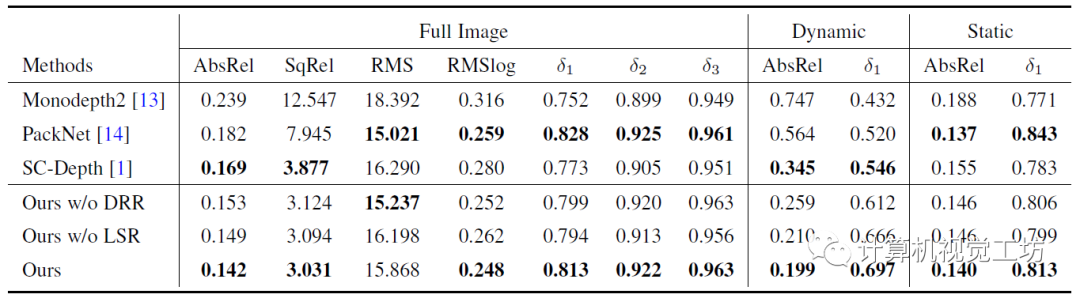
一句话总结:SC-DepthV3解决了动态环境问题。
5. 总结
SC-Depth系列是非常经典且先进的无监督单目深度估计网络,现在已经有了V1、V2、V3三个版本。其中SC-DepthV1主要解决深度图不连续的问题,SC-DepthV2主要解决室内环境中旋转位姿对深度估计产生噪声的问题,SC-DepthV3主要解决动态环境中的单目深度估计问题。可以说这三个网络已经可以应用于大多数的场景,这样在一个方向不断深耕的团队并不多见。研究单目深度估计网络的读者一定不要错过。
审核编辑:刘清
-
传感器
+关注
关注
2557文章
51761浏览量
759082 -
激光雷达
+关注
关注
970文章
4072浏览量
190978 -
VSLAM
+关注
关注
0文章
24浏览量
4379
原文标题:SC-DepthV3来了!深度解析无监督单目深度估计V1到V3的主要变化
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人脸识别、语音翻译、无人驾驶...这些高科技都离不开深度神经网络了!
在STM32F407上实现了直播声卡
TEE解决了什么问题?
WS2811 led strip添加了analogWrite来控制板载LED的亮度,效果都失真了怎么解决?
SK电讯成功实现了1.2Gbps的LTE网络服务
使用Matlab实现了一个通用无源网络仿真引擎
CDN解决了什么问题





 工商网监
工商网监
评论