 谷歌提出Flan-T5,一个模型解决所有NLP任务
谷歌提出Flan-T5,一个模型解决所有NLP任务
「论文」: Scaling Instruction-Finetuned Language Models
「地址」: https://arxiv.org/abs/2210.11416
「模型」: https://huggingface.co/google/flan-t5-xxl
1. Flan-T5是什么
「Flan-T5」是Google最新的一篇工作,通过在超大规模的任务上进行微调,让语言模型具备了极强的泛化性能,做到单个模型就可以在1800多个NLP任务上都能有很好的表现。这意味着模型一旦训练完毕,可以直接在几乎全部的NLP任务上直接使用,实现「One model for ALL tasks」,这就非常有诱惑力!
这里的Flan指的是(Instruction finetuning),即"基于指令的微调";T5是2019年Google发布的一个语言模型了。注意这里的语言模型可以进行任意的替换(需要有Decoder部分,所以「不包括BERT这类纯Encoder语言模型」),论文的核心贡献是提出一套多任务的微调方案(Flan),来极大提升语言模型的泛化性。
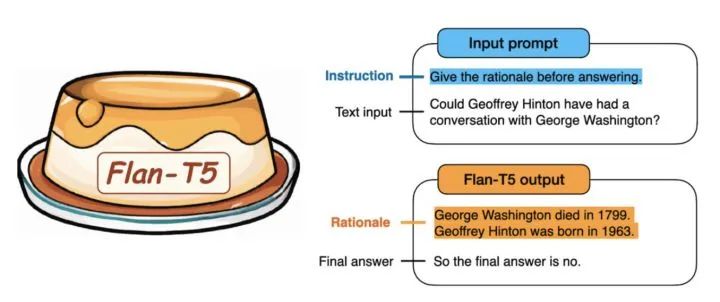
例如下面文章中的例子,模型训练好之后,可直接让模型做问答:
「模型输入」是:"Geoffrey Hinton和George Washington这两个人有没有交谈过?在回答之前想一想原因。“
「模型返回」是:Geoffrey Hinton是一个计算机科学家,出生在1947年;而George Washington在1799年去世。所以这两个不可能有过交谈。所以答案时“没有”。
2. 怎么做的
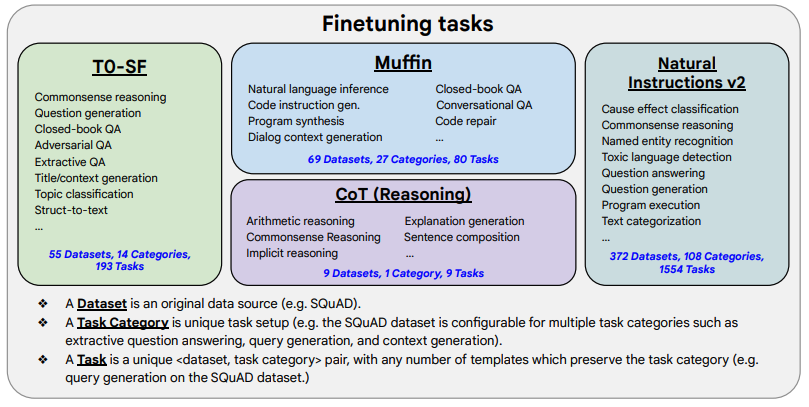
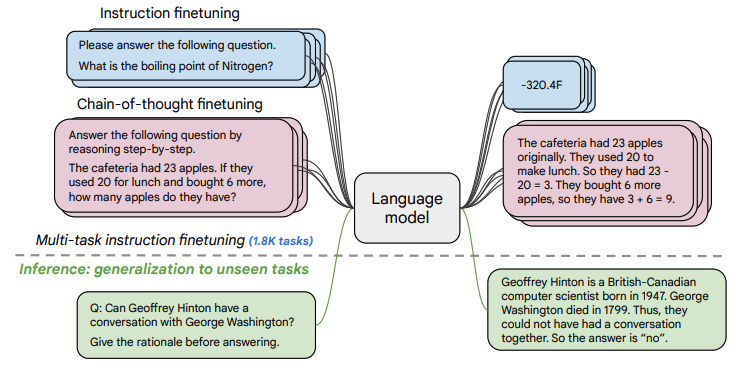
(1) 「任务收集」:工作的第一步是收集一系列监督的数据,这里一个任务可以被定义成<数据集,任务类型的形式>,比如“基于SQuAD数据集的问题生成任务”。需要注意的是这里有9个任务是需要进行推理的任务,即Chain-of-thought (CoT)任务。
(2) 「形式改写」:因为需要用单个语言模型来完成超过1800+种不同的任务,所以需要将任务都转换成相同的“输入格式”喂给模型训练,同时这些任务的输出也需要是统一的“输出格式”。
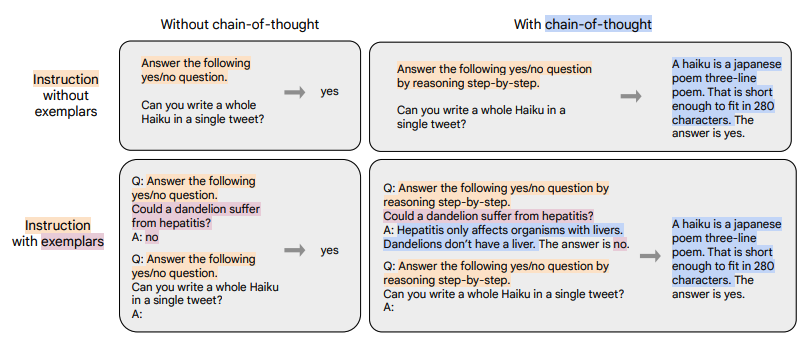
如上图所示,根据 “是否需要进行推理 (CoT)” 以及 “是否需要提供示例(Few-shot)” 可将输入输出划分成四种类型:
-
chain-of-thought : and few-shot: (图中左上)
- 输入:指令 + 问题
- 输出:答案
-
chain-of-thought : and few-shot: (图中右上)
- 输入:指令 + CoT引导(by reasoning step by step) + 问题
- 输出:理由 + 答案
-
chain-of-thought: and few-shot: (图中左下)
- 输入:指令 + 示例问题 + 示例问题回答 + 指令 + 问题
- 输出:答案
-
chain-of-thought: and few-shot: (图中右下)
- 输入:指令 + CoT引导 + 示例问题 + 示例问题理由 + 示例问题回答 + 指令 + CoT引导 + 问题
- 输出:理由 + 答案
(3) 「训练过程」:采用恒定的学习率以及Adafactor优化器进行训练;同时会将多个训练样本“打包”成一个训练样本,这些训练样本直接会通过一个特殊的“结束token”进行分割。训练时候在每个指定的步数会在“保留任务”上进行模型评估,保存最佳的checkpoint。

尽管微调的任务数量很多,但是相比于语言模型本身的预训练过程,计算量小了非常多,只有0.2%。所以通过这个方案,大公司训练好的语言模型可以被再次有效的利用,我们只需要做好“微调”即可,不用重复耗费大量计算资源再去训一个语言模型。

3. 一些结论
(1) 微调很重要
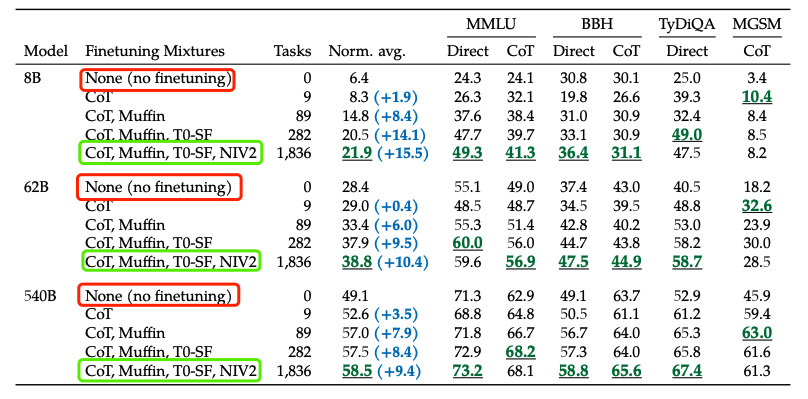
与不微调相比,通过基于指令的微调(flan)可以大幅度提高语言模型的效果。
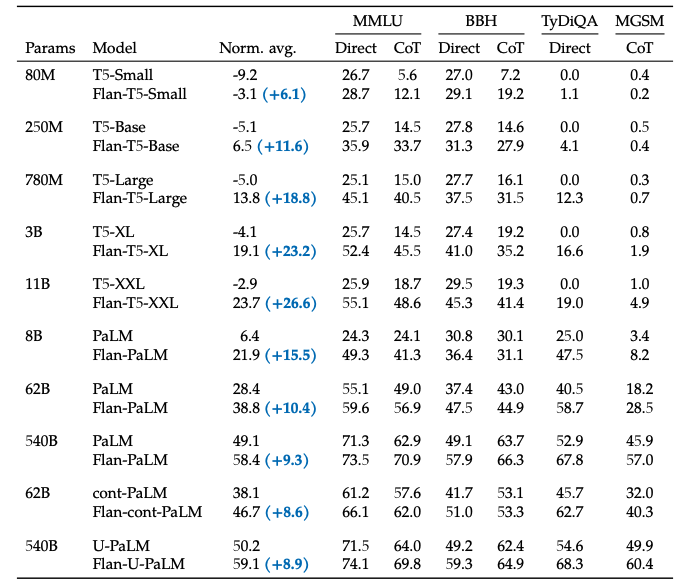
(2) 模型越大效果越好
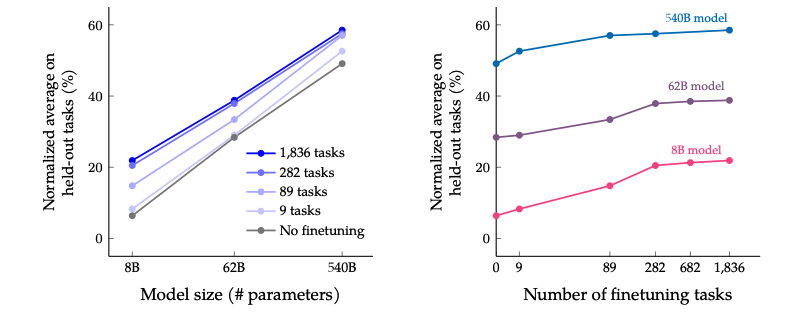
伴随模型体积的增加(上图左), 尤其是指数级的增加,比如从8B->62B,再从62B->540B,不论是否微调,效果都有非常显著的提升,而且还没有看到收敛的信号,可能如果有了 “万亿”参数的模型,效果还能继续提升。
(3) 任务越多效果越好
伴随任务数量的增加(上图右),模型的性能也会跟着增加,但是当任务数量超过282个之后,提升就不是很明显了。因为继续增加新的任务,尤其任务形式跟之前一样,不会给模型带来新的知识;多任务微调的本质是模型能够更好的把从预训练学到的知识进行表达,超过一定任务之后,继续新增相似的任务,知识的表达能力不会继续有很大的收益。进一步统计全部微调数据集的token数,发现只占到了预训练数据token数的0.2%,这表明还是有很多的知识没有在微调阶段重新被激发。
(4) 混杂CoT相关的任务很重要
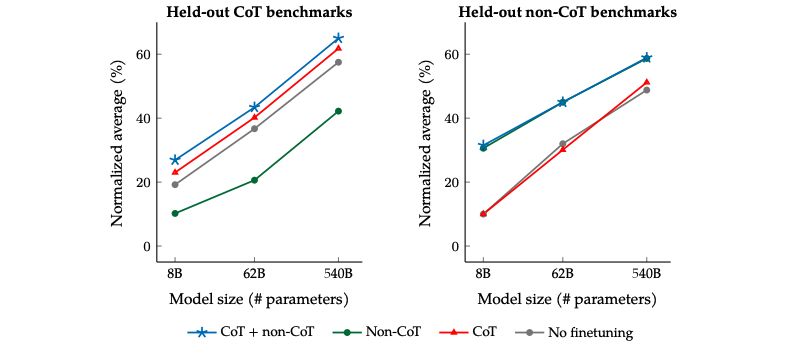
尽管在1800多个任务中只有9个需要推理再给出回答的任务(CoT任务),但是混杂了这9个任务之后对整个模型的提升很大。在针对CoT相关任务的预测上,如果在微调中混淆CoT任务能带来明显的提升(左图中蓝色和绿色线);在针对非CoT相关任务的预测上,如果在微调中混淆了CoT任务也不会对模型带来伤害(右图中蓝色和绿色线)。
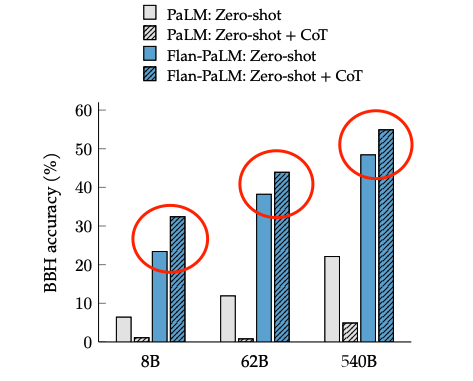
(5) 整合起来
最终在多个不同尺寸的模型上进行实验,都可以获得一致性的结论:引入Flan微调方案,可以很好提高语言模型在超大规模任务上的整体效果。
总结一下,这篇工作提出了Flan的微调框架,核心有四点:统一的输入输出格式(4种类型),引入chain-of-thought,大幅提高任务数量,大幅提高模型体积;实现了用一个模型来解决超过1800种几乎全部的NLP任务,通过较低的成本,极大发掘了现有语言模型的泛化性能,让大家看到了通用模型的希望,即「One Model for ALL Tasks」。
审核编辑 :李倩
-
Google
+关注
关注
5文章
1765浏览量
57528 -
模型
+关注
关注
1文章
3243浏览量
48836 -
nlp
+关注
关注
1文章
488浏览量
22035
原文标题:谷歌提出Flan-T5,一个模型解决所有NLP任务
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Transformer语言模型简介与实现过程
nlp逻辑层次模型的特点
nlp自然语言处理的主要任务及技术方法
llm模型有哪些格式
nlp自然语言处理模型怎么做
nlp自然语言处理模型有哪些
【大语言模型:原理与工程实践】大语言模型的基础技术
谷歌模型框架是什么软件?谷歌模型框架怎么用?
谷歌模型怎么用手机打开

谷歌大型模型终于开放源代码,迟到但重要的开源战略






 工商网监
工商网监
评论