 5种方式初始化String成员怎样选择?
5种方式初始化String成员怎样选择?
C++初始化成员的方式有许多,尤其是随着C++11值类别的重新定义,各种方式之间的差异更是细微。
本文将以String成员初始化为例,探讨以下5种方式之间的优劣:输入不同,它们的开销也完全不同,我们将以4种不同的输入分别讨论。本篇结束,下方的表格也将填满。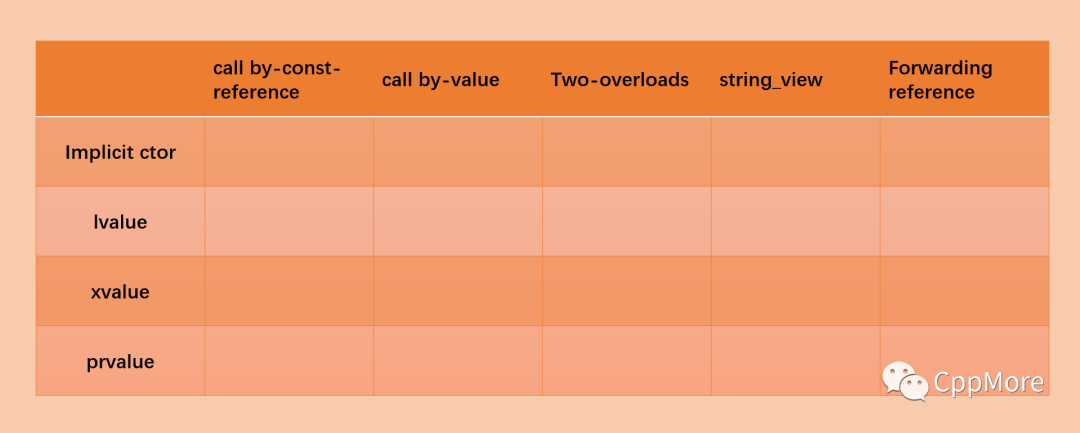 实际要讨论的情况远超1种,因此这张表格在不同的情境下,填入的开销也不尽相同。多种情况,多个概念,交叉讨论,错综复杂,这也是本篇文章难度能入四星的原因。下面正式进入讨论。
实际要讨论的情况远超1种,因此这张表格在不同的情境下,填入的开销也不尽相同。多种情况,多个概念,交叉讨论,错综复杂,这也是本篇文章难度能入四星的原因。下面正式进入讨论。1call by-const-reference
这种方式最是广为流传,C++11之前亦可使用,是早期的推荐方式。
比如:
structS{
std::stringmem;
S(conststd::string&s):mem{s}{}
};
即便现在,使用这种方式也是大有人在。根据4种不同的输入分析其开销,代码如下:
std::stringstr{"dummy"};
Ss1("dummy");//1.Implicitctor
Ss2(str);//2.lvalue
Ss3(std::move(str));//3.xvalue
Ss4(std::string{"dummy"});//4.prvalue
第一,Implicit ctor。当传入一个字符串字面量时,会先通过隐式构造创建一个临时的string对象,将它绑定到形参之上,再通过拷贝构造复制到成员变量。共2次分配。第二,lvalue。对于左值,将直接绑定到形参上,再通过拷贝构造复制到成员变量。共1次分配。
第三,xvalue。对于消亡值,操作同上。共1次分配。
第四,prvalue。对于纯右值,操作同上。共1次分配。
由此可知,使用const-reference string时,至少存在1次分配。对于左值来说,这本无可厚非;但对于右值来说,这将徒增一次没必要的拷贝;对于字符串字面量,还会由隐式构造创建一个临时对象,增加一次开销。
因此,这种方式只有针对左值时,效果才不错,其他情况都会增加一次开销。
2call by-value
这是从C++11开始也广为流传的一种方式,使用的人也不少。4种调用不变,实现变为了:
structS{
std::stringmem;
S(std::strings):mem{std::move(s)}{}
};
这种方式采用值传递参数,在许多人的印象中,这种开销很大,实际情况到底如何呢?第一,Implicit ctor。同样,先通过隐式构造创建一个临时对象,然后将其值偷取到成员变量。共1次分配+1次移动。第二,lvalue。拷贝对象,然后将其值偷取到成员变量。共1次分配+1次移动。第三,xvalue。值经过两次偷取到成员变量。共0次分配+2次移动。第四,prvalue。值直接原地构造,然后偷取到成员变量。共0次分配+1次移动。可以看到,call by-const-reference的缺点,这种方式全部避免。只在接受左值时,多了一次移动。因此,很多情况下,这种方式往往是一种更好的选择,它可以避免无效的拷贝。3Two-overloads
这种方式通过多提供一个移动构造来消除call by-const-reference的缺点,由于存在两个重载函数,所以称为two-overloads。此时实现变为了:
structS{
std::stringmem;
S(conststd::string&s):mem{s}{}
S(std::string&&s):mem{std::move(s)}{}
};
相信你已经猜到了现在的开销。第一,Implicit ctor。同样,先创建一个临时对象,然后调用移动构造。共1次分配+1次移动。第二,lvalue。调用拷贝构造。共1次分配。第三,xvalue。调用移动构造。共0次分配+2次移动。第四,prvalue。调用移动构造。共0次分配+1次移动。通过多增加一个重载函数,得到了不少好处,因此这也是一种可行的方式,但多写一个重载函数总是颇显琐碎。4C++17 string_view
C++17 std::string_view也是一种可行的方案,所谓是又轻又快。采用这种方式,实现变为:
structS{
std::stringmem;
S(std::string_views):mem{s}{}
};
此时的开销情况如何?第一,Implicit ctor。除了mem创建,没有多余开销。共1次分配。第二,lvalue。通过隐式转换创建string_view,然后拷贝到成员变量。共1次分配。第三,xvalue。同上。共1次分配。第四,prvalue。同上。共1次分配。对于右值,这种方式也会产生没必要的开销。最重要的是,std::string_view隐藏有许多潜在的危险,就像操作裸指针一样,需要程序员来确保它的有效性。稍不留神,就有可能产生悬垂引用,指向一个已经删除的string对象。因此,若是对其没有一定的研究,极有可能使用错误的用法。5Fowarding references
Forwarding references可以自动匹配左值或是右值版本,也是一种不错的方式。
实现变为:
structS{
std::stringmem;
template<classT>
S(T&&s):mem{std::forward(s)}{}
};
此时的开销又如何?第一,Implicit ctor。除了mem构造,无额外开销。共1次分配。第二,lvalue。直接绑定到实例化的模板函数参数上,然后拷贝一份。共1次分配。第三,xvalue。调用移动构造。共0次分配+2次移动。第四,prvalue。调用移动构造。共0次分配+1次移动。这种方式借助了模板,参数的实际类型根据TAD推导,所以它的开销也都很小。很多时候,这种方式就是最佳选择,它可以避免非必要的移动或是拷贝,也适用于非String成员的初始化。但有些时候,你可能想明确指定参数类型,此时这种方式就多有不便了。下节有相应例子。6曲未尽
分析至此,已然可以初步得出一张开销对比图。
 因此,若是要问哪种方式初始化String成员比较好,如何回答?
因此,若是要问哪种方式初始化String成员比较好,如何回答?看情况。
没有哪种方式是完全占优的,可以依据使用次数最多的操作计算消耗,从而正确决策。
举个例子:
structS{
usingvalue_type=std::vector<std::string>;
usingassoc_type=std::map<std::string,value_type>;
voidpush_data(std::string_viewkey,value_typedata){
datasets.emplace(std::make_pair(key,std::move(data)));
}
assoc_typedatasets;
};
功能很简单,就是往一个map中添加数据。此时,如何让浪费最小?假设我们后面使用次数最多的操作为:
Ss;
s.push_data("key1",{"Dear","Friend"});
s.push_data("key2",{"Apple"});
s.push_data("key3",{"Jack","Tom","Jerry"});
s.push_data("key4",{"20","22","11","20"});
那么上述实现就是一种较好的方式。对于键,如果使用call by-const-reference,将会创建一个没必要的临时对象,而使用string_view可以避免此开销。对于值,实际上也使用隐式构造创建了一个临时vector对象,此时call by-value也是一种开销较小的方式。你可能觉得Forwarding reference也是一种不错的方式。
voidpush_data(auto&&key,auto&&data){
datasets.emplace(std::make_pair(
std::forward<decltype(key)>(key),
std::forward<decltype(data)>(data)
));
}
对于键来说的确不错,但对于值来说就存在问题了。因为模板参数推导为initializer_list,而参数传递需要的是vector,使用这种方式还得手动创建一个临时的vector。所以,具体问题具体分析,才能选择最恰当的方式,有时甚至可以组合使用。大家也许注意到,开销对比图标题为"初始化Long String成员开销图",那么还有短String吗?6.1SSO短字符串优化
各家编译器在实现std::string时,基本都会采取一种SSO(Small String Optimization)策略。
此时,对于短字符串,将不会在堆上额外分配内存,而是直接存储在栈上。比如,有些实现会在size的最低标志位上用1代表长字符串,0代表短字符串,根据这个标志位来决定操作形式。
可以通过重载operator new和operator delete来捕获堆分配情况,一个例子如下:
std::size_tallocated=0;
void*operatornew(size_tsz){
void*p=std::malloc(sz);
allocated+=sz;
returnp;
}
voidoperatordelete(void*p)noexcept{
returnstd::free(p);
}
intmain(){
allocated=0;
std::strings("hi");
std::printf("stackspace=%zu,heapspace=%zu,capacity=%zu
",
sizeof(s),allocated,s.capacity());
}
例子来源:https://stackoverflow.com/a/28003328
在clang 14.0.0上得出的结果为:
stackspace=32,heapspace=0,capacity=15
可以看到,对于短字符串,将不会在堆上分配额外的内存,内容实际存在在栈上。
早期版本的编译器可能没有这种优化,但如今的版本基本都有。
也就是说,这时的移动操作实际就相当于复制操作。于是开销就可以如下图表示。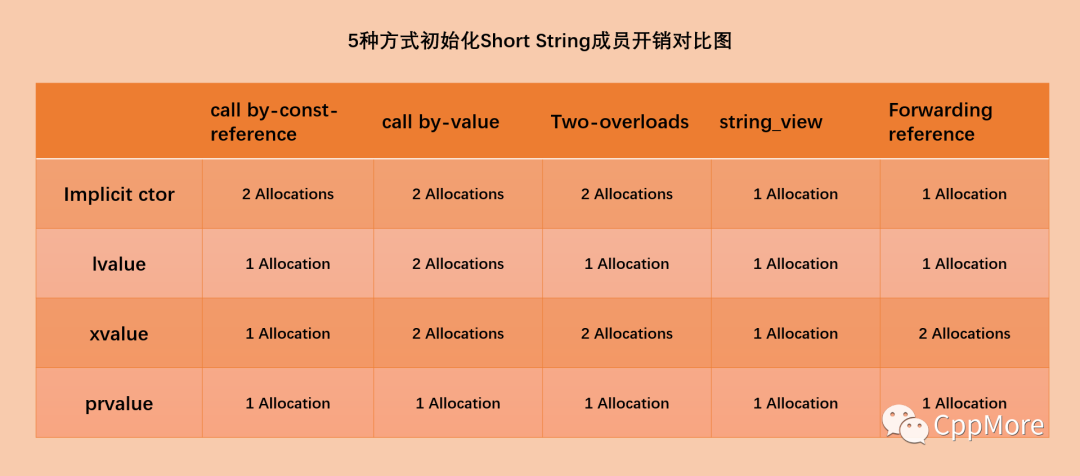
于是可以得出结论:尽管小对象的拷贝操作很快,call by-value还是要慢于其他方式,string_view则是一种较好的方式。
但是,string_view使用起来要格外当心,若你不想为此操心,使用call by-const-reference则是一种不错的方式。
6.2无拷贝,无移动
当仅需要接受参数,之后即不拷贝,也无移动的情境下,情况又不一样。
此时的开销如下图。
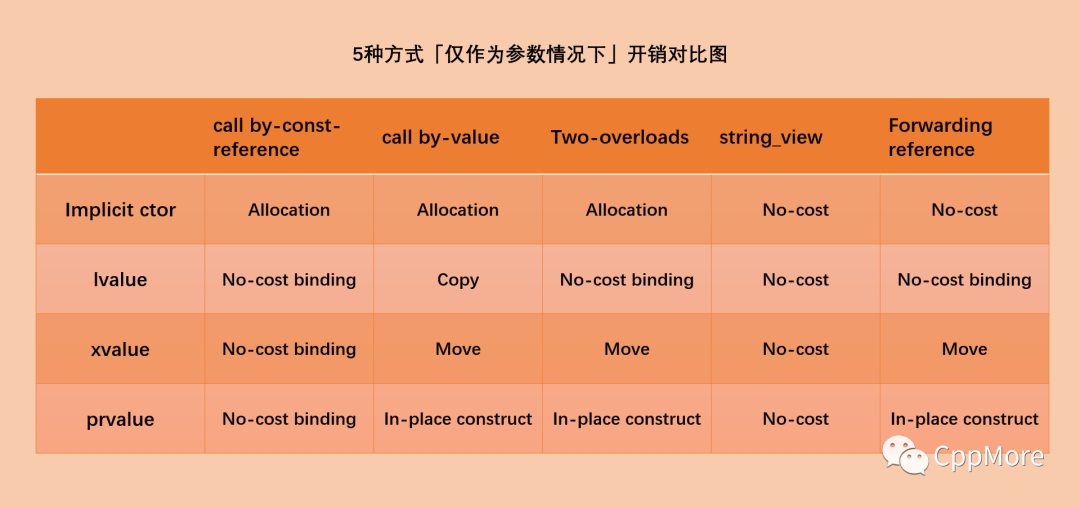 前三种方式对于隐式构造,都会产生一个临时对象,故皆含一次分配。后两种方式没有这次额外分配。Views的创建非常之轻,可忽略不计;Forwarding references经过TAD推导的参数为常量串,也无消耗。总的来说,我们能得出,通常情况下,后两种方式在这种情境下是一种开销更小的方式。若不考虑隐式构造,则除了call by-value,其他方式是一种开销更小的方式。
前三种方式对于隐式构造,都会产生一个临时对象,故皆含一次分配。后两种方式没有这次额外分配。Views的创建非常之轻,可忽略不计;Forwarding references经过TAD推导的参数为常量串,也无消耗。总的来说,我们能得出,通常情况下,后两种方式在这种情境下是一种开销更小的方式。若不考虑隐式构造,则除了call by-value,其他方式是一种开销更小的方式。6.3优化限制:Aliasing situations
Aliasing situations指的是多个变量实际指向的是同一块内存,这些变量之间互为别名。这种情况会导致编译器束手束脚,不敢优化。
以引用的方式传递参数便会产生许多额外的Aliasing situations。
举个例子:
intfoo_by_ref(constS&s){
intm=s.value;
bar();
intn=s.value;
returnm+n;
}
intfoo_by_value(Ss){
intm=s.value;
bar();
intn=s.value;
returnm+n;
}
例子来源:https://reductor.dev/cpp/2022/06/27/pass-by-value-vs-pass-by-reference.html
引用传递版本,编译器无法判定bar()中是否修改了s.value,比如s引用的是一个全局变量,bar()中就可以修改它。因此,m和n的值可能并不相同,编译器必须加载两次s.value。
而值传递版本,由于参数进行了拷贝,不存在外部修改,m和n的值肯定相同,于是编译器可以优化为只加载一次s.value。
这是call by-const-reference的另一处缺点,它可能会限制编译器的优化,而这又恰恰成了call by-value的一个优点。
7总结
本篇文章介绍了5种初始化String成员的方式,详细分析对比了它们的开销。
没有哪种方式是最优解,如何选择需要依具体情况而论。
Two-overloads这种方式一般不会考虑,因为总有其他方式比它的开销更小,还只需编写一个函数。
string_view在很多情况下的开销可观,但是需要格外注意潜在的悬垂引用问题。
其他三种方式亦是有利有弊,可根据文中提及的各种情况进行分析。
总而言之,各方式之间存在着细微而本质的差别,且还有许多特殊情况需要单独分析,开销在不同情境下也不尽相同。
一句话,看情况。
审核编辑 :李倩
-
C++
+关注
关注
22文章
2114浏览量
73819 -
变量
+关注
关注
0文章
613浏览量
28457 -
string
+关注
关注
0文章
40浏览量
4739
原文标题:5 种方式初始化 String 成员,怎样选择?
文章出处:【微信号:CPP开发者,微信公众号:CPP开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
EE-359:ADSP-CM40x启动时间优化和器件初始化

STM32F407 MCU使用SD NAND 不断电初始化失效解决方案

segger编译器初始化问题
SpringBean初始化顺序


瀚海微SD NAND应用之SD协议存储功能描述2 初始化命令
esp32调试MQTT的程序,如何对.host初始化?
在初始化IO口为外部中断线的时候,最先初始化的会被后初始化的覆盖掉为什么?
使用STM32CubeIDE初始化STM32407的SPI1(PB3)初始化失败的原因?怎么解决?
什么是异步?异步的八种实现方式
MCU单片机GPIO初始化该按什么顺序配置?为什么初始化时有电平跳变?






 工商网监
工商网监
评论