 使用LIME解释CNN
使用LIME解释CNN
作者:Mehul Gupta
来源:DeepHub IMBA
图像与表格数据集有很大不同(显然)。如果你还记得,在之前我们讨论过的任何解释方法中,我们都是根据特征重要性,度量或可视化来解释模型的。比如特征“A”在预测中比特征“B”有更大的影响力。但在图像中没有任何可以命名的特定特征,那么怎么进行解释呢?
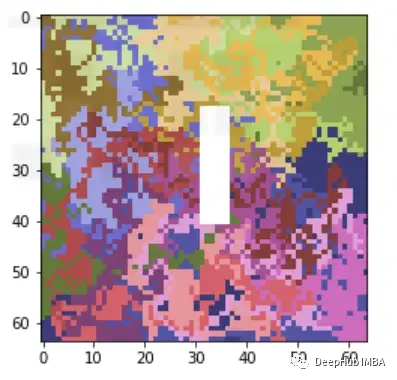
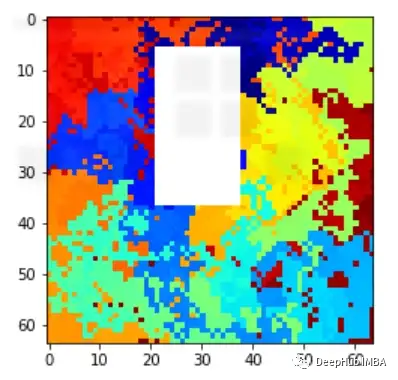
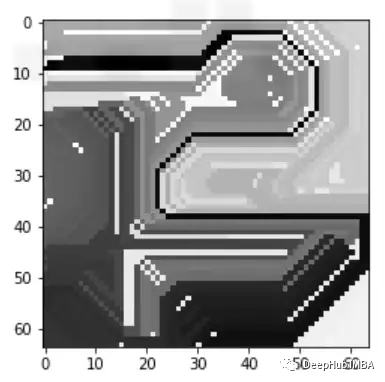
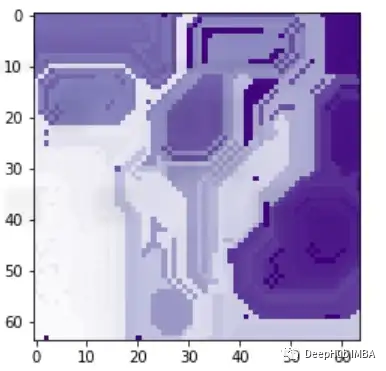
一般情况下我们都是用突出显示图像中模型预测的重要区域的方法观察可解释性,这就要求了解如何调整LIME方法来合并图像,我们先简单了解一下LIME是怎么工作的。

LIME在处理表格数据时为训练数据集生成摘要统计:
使用汇总统计生成一个新的人造数据集
从原始数据集中随机提取样本
根据与随机样本的接近程度为生成人造数据集中的样本分配权重
用这些加权样本训练一个白盒模型
解释白盒模型
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.layers import Input, Dense, Embedding, Flatten
from keras.layers import SpatialDropout1D
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.models import Sequential
from randimage import get_random_image, show_array
import random
import pandas as pd
import numpy as np
import lime
from lime import lime_image
from skimage.segmentation import mark_boundaries
#preparing above dataset artificially
training_dataset = []
training_label = []
for x in range(200):
img_size = (64,64)
img = get_random_image(img_size)
a,b = random.randrange(0,img_size[0]/2),random.randrange(0,img_size[0]/2)
c,d = random.randrange(img_size[0]/2,img_size[0]),random.randrange(img_size[0]/2,img_size[0])
value = random.sample([True,False],1)[0]
if value==False:
img[a:c,b:d,0] = 100
img[a:c,b:d,1] = 100
img[a:c,b:d,2] = 100
training_dataset.append(img)
training_label.append(value)
#training baseline CNN model
training_label = [1-x for x in training_label]
X_train, X_val, Y_train, Y_val = train_test_split(np.array(training_dataset).reshape(-1,64,64,3),np.array(training_label).reshape(-1,1), test_size=0.1, random_state=42)
epochs = 10
batch_size = 32
model = Sequential()
model.add(Conv2D(32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
# Output layer
model.add(Dense(32,activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, validation_data=(X_val, Y_val), epochs=epochs, batch_size=batch_size, verbose=1)
x=10
explainer = lime_image.LimeImageExplainer(random_state=42)
explanation = explainer.explain_instance(
X_val[x],
model.predict,top_labels=2)
)
image, mask = explanation.get_image_and_mask(0, positives_only=True,
hide_rest=True)
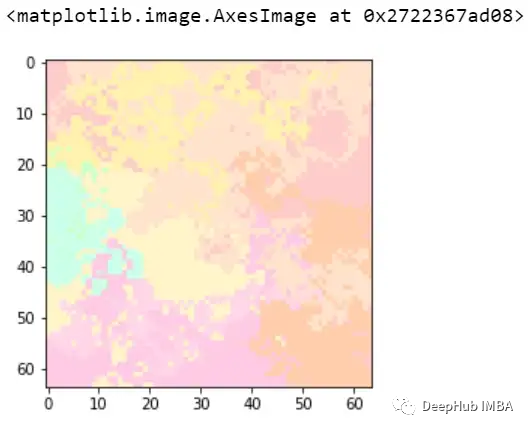
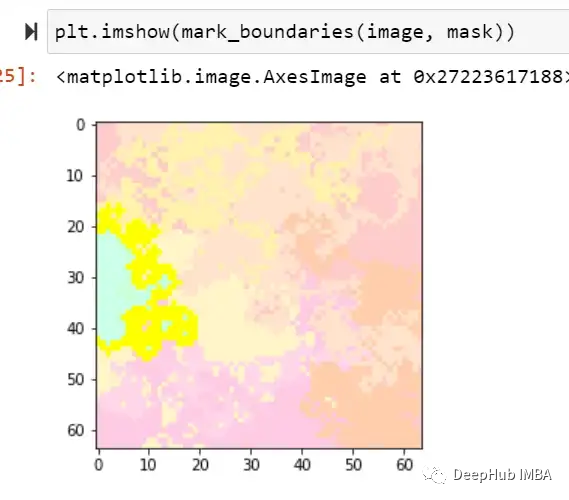
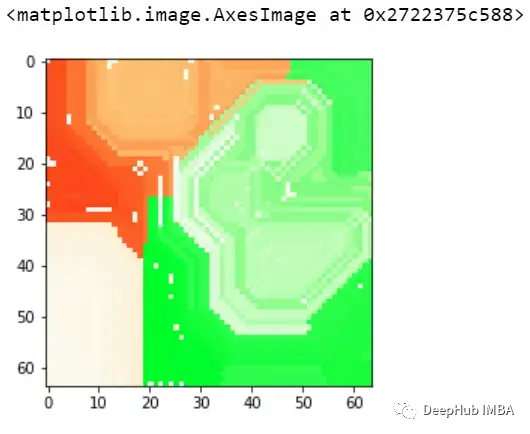
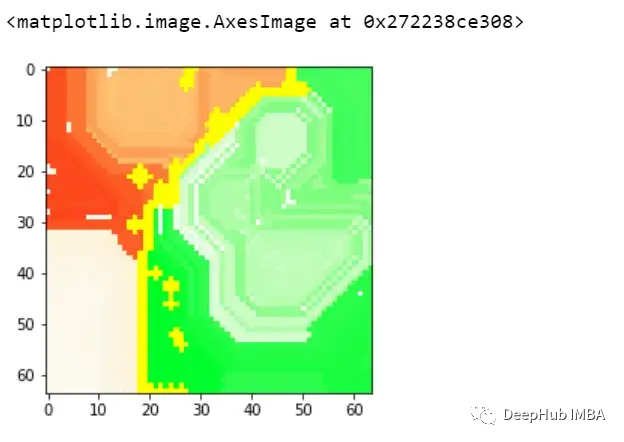
这样我们就可以理解模型导致错误分类的实际问题是什么,这就是为什么可解释和可解释的人工智能如此重要。
END

(添加请备注公司名和职称)
Imagination 基于 O3DE 引擎的光线追踪 Demo 详解

Imagination Technologies是一家总部位于英国的公司,致力于研发芯片和软件知识产权(IP),基于Imagination IP的产品已在全球数十亿人的电话、汽车、家庭和工作场所中使用。获取更多物联网、智能穿戴、通信、汽车电子、图形图像开发等前沿技术信息,欢迎关注 Imagination Tech!
原文标题:使用LIME解释CNN
文章出处:【微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
imagination
+关注
关注
1文章
570浏览量
61272
原文标题:使用LIME解释CNN
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
cnn常用的几个模型有哪些
CNN(卷积神经网络)是一种深度学习模型,广泛应用于图像识别、自然语言处理等领域。以下是一些常用的CNN模型: LeNet-5:LeNet-5是最早的卷积神经网络之一,由Yann LeCun等人于
图像分割与语义分割中的CNN模型综述
图像分割与语义分割是计算机视觉领域的重要任务,旨在将图像划分为多个具有特定语义含义的区域或对象。卷积神经网络(CNN)作为深度学习的一种核心模型,在图像分割与语义分割中发挥着至关重要的作用。本文将从CNN模型的基本原理、在图像分割与语义分割中的应用、以及具体的模型架构和调
CNN与RNN的关系
在深度学习的广阔领域中,卷积神经网络(CNN)和循环神经网络(RNN)是两种极为重要且各具特色的神经网络模型。它们各自在图像处理、自然语言处理等领域展现出卓越的性能。本文将从概念、原理、应用场景及代码示例等方面详细探讨CNN与RNN的关系,旨在深入理解这两种网络模型及其在
CNN在多个领域中的应用
,通过多层次的非线性变换,能够捕捉到数据中的隐藏特征;而卷积神经网络(CNN),作为神经网络的一种特殊形式,更是在图像识别、视频处理等领域展现出了卓越的性能。本文旨在深入探究深度学习、神经网络与卷积神经网络的基本原理、结构特点及其在多个领域中的广泛应用。
CNN的定义和优势
卷积神经网络(Convolutional Neural Networks, CNN)作为深度学习领域的核心成员,不仅在学术界引起了广泛关注,更在工业界尤其是计算机视觉领域展现出了巨大的应用价值。关于
基于CNN的网络入侵检测系统设计
入侵检测提供了新的思路和方法。卷积神经网络(Convolutional Neural Network, CNN)作为深度学习的一种重要模型,以其强大的特征提取能力和模式识别能力,在网络入侵检测领域展现出巨大的潜力。
如何在TensorFlow中构建并训练CNN模型
在TensorFlow中构建并训练一个卷积神经网络(CNN)模型是一个涉及多个步骤的过程,包括数据预处理、模型设计、编译、训练以及评估。下面,我将详细阐述这些步骤,并附上一个完整的代码示例。
如何利用CNN实现图像识别
卷积神经网络(CNN)是深度学习领域中一种特别适用于图像识别任务的神经网络结构。它通过模拟人类视觉系统的处理方式,利用卷积、池化等操作,自动提取图像中的特征,进而实现高效的图像识别。本文将从CNN的基本原理、构建过程、训练策略以及应用场景等方面,详细阐述如何利用
NLP模型中RNN与CNN的选择
在自然语言处理(NLP)领域,循环神经网络(RNN)与卷积神经网络(CNN)是两种极为重要且广泛应用的网络结构。它们各自具有独特的优势,适用于处理不同类型的NLP任务。本文旨在深入探讨RNN与CNN
cnn卷积神经网络分类有哪些
卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像分类、目标检测、语义分割等领域。本文将详细介绍CNN在分类任务中的应用,包括基本结构、关键技术、常见网络架构以及实际应用案例。 引言 1.1
cnn卷积神经网络三大特点是什么
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种深度学习模型,广泛应用于图像识别、视频分析、自然语言处理等领域。CNN具有以下三大特点: 局部连接
CNN模型的基本原理、结构、训练过程及应用领域
卷积神经网络(Convolutional Neural Network,简称CNN)是一种深度学习模型,广泛应用于图像识别、视频分析、自然语言处理等领域。CNN模型的核心是卷积层
卷积神经网络cnn模型有哪些
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种深度学习模型,广泛应用于图像识别、视频分析、自然语言处理等领域。 CNN的基本概念 1.1 卷积层
深度神经网络模型cnn的基本概念、结构及原理
深度神经网络模型CNN(Convolutional Neural Network)是一种广泛应用于图像识别、视频分析和自然语言处理等领域的深度学习模型。 引言 深度学习是近年来人工智能领域的研究热点
基于Python和深度学习的CNN原理详解
卷积神经网络 (CNN) 由各种类型的层组成,这些层协同工作以从输入数据中学习分层表示。每个层在整体架构中都发挥着独特的作用。





 工商网监
工商网监
评论