 【AI简报20221125】高通骁龙8Gen2 VS联发科天玑9200、瑞萨入局RISC-V
【AI简报20221125】高通骁龙8Gen2 VS联发科天玑9200、瑞萨入局RISC-V

嵌入式 AI
AI 简报 20221125 期
1. 能逆袭苹果A16芯片吗?高通骁龙8Gen2 VS联发科天玑9200,谁能成为2023年智能手机高端芯片霸主?
原文:
https://mp.weixin.qq.com/s/IWSolPkauAJEGYARg9Iheg
11月22日晚上7点,vivo召开vivo X90系列新品发布会,推出全新旗舰X90系列。其中,vivo X90 和vivo X90 Pro搭载联发科天玑9200系列,X90首发天玑9200处理器,搭载自研芯片V2,内置4810mAh大电池,支持120W双芯闪充,起始定价3699元,X90 Pro起始定价4999元。在3000元到5000元价位段智能手机领域,vivo选择了联发科的新品。
在高于800美元的高端旗舰手机当中,vivo选择了高通产品。vivo X90 Pro+搭载高通骁龙8 Gen2,首发LPDDR5x + UFS 4.0,4700mAh电池,80W有线快充,50W无线快充。12GB+256GB版本售价6499元。
11月16日,高通骁龙8Gen2正式官宣后,海外媒体报道,三星下一代旗舰Galaxy S23,S23 +和S23 Ultra将采用骁龙8Gen2,这个系列预计会在2023年1月份发布。在微博上,数码博主爆料,小米13系列将搭载满血版骁龙8 Gen2,其最高频率达到3.2GHz,同时在调校中会释放满血性能,在游戏表现上可能会更上一层。
高通、联发科是安卓手机芯片的主要供应商,他们如何看待2023年智能手机市场?作为高端旗舰芯片,两款芯片的极致性能对比,哪些优势显现?在智能手机和元宇宙生态圈的融合当中,谁又是最有潜力的选手?
2. IBM全新AIU芯片:5nm工艺,230亿晶体管!深度学习处理性能强劲!
原文:https://mp.weixin.qq.com/s/RR0ACES8j8bZvULjyy5MfA
IBM 研究院推出了一款AI处理器,名为人工智能单元(Artificial Intelligent Unit,AIU),这是IBM首个用于运行和训练深度学习模型的完整 SoC。IBM声称,其比通用CPU工作更快、更高效。

AIU:32个处理器核心、230亿个晶体管
这款AIU芯片是IBM研究院AI硬件中心投入五年开发出的结果,AI硬件中心于2019年启动,专注于开发下一代芯片与AI系统。该中心的目标是,计划未来每年将AI硬件效率提升2.5倍。到2029年,将AI模型的训练和运行速度拉高1000倍。
据IBM介绍,该芯片采用5nm制程工艺,共有32个处理器核心和230亿个晶体管,在设计易用性方面,与普通显卡相当,能够介入任何带有PCI插槽的计算机或服务器。AIU芯片,旨在支持多种格式并简化从图像识别到自然语言处理的人工智能工作流程。
AIU芯片与传统用于训练的GPU芯片有何不同?一直以来,深度学习模型依赖于CPU加GPU协处理器的组合进行训练与运行。GPU最初是为沉浸图形图像而开发,后来人们发现其在AI领域有着显著优势,因此GPU在AI训练领域占据了非常重要的位置。
IBM开发的AIU并非图形处理器,它是专为深度学习模型加速设计的,针对矩阵和矢量计算进行了优化。AIU能够解决高复杂计算问题,并以远超CPU的速度执行数据分析。
AIU芯片有何特点呢?过去这些年,AI与深度学习模型在各行各业中快速普及,同时深度学习的发展也给算力资源带来了巨大的压力。深度学习模型的体量越来越大,包含数十亿甚至数万亿个参数。而硬件效率的发展却似乎跟不上深度学习模型的增长速度。
过去,计算一般集中在高精度64位与32位浮点运算层面。IBM认为,有些计算任务并不需要这样的精度,于是提出了降低传统计算精度的新术语——近似计算。
如何理解呢?IBM认为对于常见的深度学习任务,其实并不需要那么高的计算精度,就比如说人类大脑,即使没有高分辨率,也能够分辨出家人或者小猫。也就是说各种任务,其实都可以通过近似计算来处理。
在AIU芯片的设计中,近似计算发挥着重要作用。IBM研究人员设计的AIU芯片精度低于CPU,而这种较低精度也让新型AIU硬件加速器获得了更高的计算密度。IBM使用混合8位浮点(HFP)计算,而非AI训练中常见的32位或16点浮点计算。由于精度较低,因此该芯片的运算执行速度可达到FP16的2倍,同时继续保持类似的训练效能。
IBM在AI芯片技术上的不断升级
在去2月的国际固态电路会议(ISSCC 2021)上,IBM也曾发布过一款性能优异的AI芯片,据IBM称它是当时全球首款高能效AI芯片,采用7nm制程工艺,可达到80%以上的训练利用率和60%以上的推理利用率,而通常情况下,GPU的利用率在30%以下。
有对比数据显示,IBM 7nm高能效AI芯片的性能和能效,不同程度地超过了IBM此前推出的14nm芯片、韩国科学院(KAIST)推出的65nm芯片、平头哥推出的12nm芯片含光800、NVIDIA推出的7nm芯片A100、联发科推出的7nm芯片。
IBM去年推出的这款7nm AI芯片支持fp8、fp16、fp32、int4、int2混合精度。在fp32和fp8精度下,这款芯片每秒浮点运算次数分别达到16TFLOPS和25.6TFLOPS,能效比为3.5TFLOPS/W和1.9TFLOPS。而被业界高度认可的NVIDIA A100 GPU在fp16精度下的能效比为0.78TFLOPS/W,低于IBM这款高能效AI芯片。
IBM在官网中称,这款AI芯片之所以能够兼顾能效和性能,是因为该芯片支持超低精度混合8位浮点格式((HFP8,hybrid FP8)。这是IBM于2019年发布的一种高度优化设计,允许AI芯片在低精度下完成训练任务和不同AI模型的推理任务,同时避免任何质量损失。
可以看到IBM此次发布的新款AIU与去年2月发布的7nm AI芯片,都采用了IBM此前提出的近似计算。从性能来看,去年推出的那款AI芯片一定程度上甚至超过了目前业界训练场景普遍使用的NVIDIA A100 GPU,而今年新推出的AIU无论是在制程工艺、晶体管数量上都有升级,可想而知性能水平将会更高。
3. 索尼、瑞萨入局,谈谈日本的RISC-V生态
原文:https://mp.weixin.qq.com/s/QX5ugMprlzoNQXQKeDsIvg
RISC-V作为一个尚在飞速成长中的ISA,如何辐射到更多的应用领域和地域是最为重要的,从我们过去的报道中可以看出,欧美、中国、印度乃至越南都已经开始了自己的RISC-V生态构建之路。除了这些地区之外,日本作为半导体大国之一,也是RISC-V开疆扩土的对象之一。那么RISC-V在如今半导体产业处于重振期的日本,究竟已经发展到何种程度了呢?
日本的RISC-V IP生态
对于打造一个基于RISC-V的芯片来说,第一步就是选择可用的RISC-V CPU核心IP。在RISC-V生态中,CPU IP的选择有很多种,你可以选择香山这样的开源IP,可以选择SiFive、晶心科技、平头哥、芯来科技等提供的商用IP,也可以基于RISC-V这一开源ISA内部自研IP,或是通过OpenHW这样的协作平台来选择验证过的IP。
日本本土的RISC-V IP供应商并不多,除了电装旗下的NSITEXE外,日本厂商用到的主要RISC-V IP多来自SiFive和晶心科技两家海外厂商,主要客户有瑞萨、ArchiTek等。纵观各大芯片原厂,瑞萨大概是与RISC-V厂商合作最多的公司之一了。
早在2020年,瑞萨就宣布与晶心科技合作,将其32为RISC-V CPU内核用于其专用标准产品中,也就是今年发布的R9A02G020电机控制MCU,2022年瑞萨又基于晶心科技的64位RISC-V CPU内核打造了全新的RZ/Five通用MPU。去年,瑞萨还宣布了与SiFive合作,利用其Intelligence系列处理器来打造下一代车用高端SoC和MCU。而瑞萨已经发布的汽车MCU RH850/U2B中,也用到了NSITEXE的DR1000C,一个RISC-V并行处理器IP。
另一家AI公司ArchiTek,也选择了SiFive的E3系列内核和自研的ArchiTek智能像素引擎(aIPE)来打造首个AI处理器AiOnlc。AiOnlc将作为一个边缘AI处理器,实时处理传感器数据的同时,减少AI推理的时延并提高安全性。从其融资公告来看,ArchiTek计划在明年开始出货AiOnlc芯片,并推出基于AiOnlc芯片的摄像头模组、SBC和配套软件。
索尼的入局
我们从RISC-V国际基金会的成员列表中可以看出,RISC-V已经在全球范围内开始普及,无论是IP厂商、芯片厂商、工具厂商还是终端厂商,都纷纷参与其中。不少知名厂商虽然动作不大,但均已经开始了布局,比如高通、谷歌和英特尔等等。其中日本厂商也不少,比如日立、自动驾驶厂商OTSL、超算厂商PEZY Computing等。
而在这些大厂中,还有一家日本厂商名列其中,也就是索尼半导体。索尼半导体的图像传感器业务自然无需多言,其市场地位几乎无人可以撼动。然而,索尼也是最先加入RISC-V国际基金会的厂商之一,早在2019年的RISC-V日本大会上,索尼半导体就曾分享过一篇《与RISC-V携手的未来图像传感》主题演讲。
其中提到,尽管索尼在设计制造传感器的过程中不需要用到RISC-V,但单靠图像传感器,还是很难解决一些遗留问题,比如色彩还原、摩尔纹消除等。然而在进入AI时代后,机器视觉开始发挥巨大的功效,尤其是在自动驾驶领域,决心进军汽车市场又想在图像市场更进一步的索尼,就打算将边缘AI与图像传感器结合起来。
以索尼最新发布的A7R5旗舰微单相机为例,微单相机最为关键的两大元件莫过于传感器和处理器,然而A7R5加入的AI识别功能是靠一块独立的AI处理器来实现的,从而完成自动对象识别、人体姿态识别等一系列复杂的智能对焦操作,未来也有机会继续注入新的识别模型来提升对焦体验。
虽然这一AI处理器是否基于RISC-V设计无从得知,但从上文举的几个例子就能看出,RISC-V在边缘AI市场存在着不小的优势,低功耗高算力的RISC-V AI芯片可以广泛用于汽车、摄像头中,哪怕只是作为一个协处理器来使用。除此之外,索尼还参与了印度的DIR-V计划,索尼印度会利用印度自研的SHAKTI RISC-V处理器来设计索尼的系统或产品,足见索尼已经开始在RISC-V上加大投入。
小结
除了以上这些商业公司外,日本的学研界也已经参与的RISC-V生态的构建中来,比如东京大学、立命馆大学和日本产业技术综合研究所等,相继发表了基于RISC-V芯片设计和软件开发移植的成果。日本作为一大半导体产业人才宝地,无疑能为RISC-V的发展提供更多的助力,而日本RISC-V生态的建立,或许也能为国内的一众RISC-V IP公司带来新的机遇。
4. 一句话生成3D模型:AI扩散模型的突破,让建模师慌了
原文:https://mp.weixin.qq.com/s/MhS6vjbc9iKjZiGDkFKjXQ
我们生活在三维的世界里,尽管目前大多数应用程序是 2D 的,但人们一直对 3D 数字内容有很高的需求,包括游戏、娱乐、建筑和机器人模拟等应用。
然而,创建专业的 3D 内容需要很高的艺术与审美素养和大量 3D 建模专业知识。人工完成这项工作需要花费大量时间和精力来培养这些技能。
需求大又是「劳动密集型行业」,那么有没有可能交给 AI 来做?上周五,英伟达提交到预印版论文平台 arXiv 的论文引起了人们的关注。
和现在流行的 NovelAI 差不多,人们只需要输入一段文字比如「一只坐在睡莲上的蓝色箭毒蛙」,AI 就能给你生成个纹理造型俱全的 3D 模型出来。

Magic3D 还可以执行基于提示的 3D 网格编辑:给定低分辨率 3D 模型和基本提示,可以更改文本从而修改生成的模型内容。此外,作者还展示了保持画风,以及将 2D 图像样式应用于 3D 模型的能力。

Stable Diffusion 的论文在 2022 年 8 月才首次提交,几个月就已经进化到这样的程度,不禁让人感叹科技发展的速度。
英伟达表示,你只需要在这个基础上稍作修改,生成的模型就可以当做游戏或 CGI 艺术场景的素材了。
3D 生成模型的方向并不神秘,其实在 9 月 29 日,谷歌曾经发布过一款文本到 3D 的生成模型 DreamFusion,英伟达在 Magic3D 的研究中直接对标该方法。
英伟达的方法首先使用低分辨率扩散先验获得粗糙模型,并使用稀疏 3D 哈希网格结构进行加速。用粗略表示作为初始,再进一步优化了带纹理的 3D 网格模型,该模型具有与高分辨率潜在扩散模型交互的高效可微分渲染器。
Magic3D 可以在 40 分钟内创建高质量的 3D 网格模型,比 DreamFusion 快 2 倍(后者平均需要 1.5 小时),同时还实现了更高的分辨率。统计表明相比 DreamFusion,61.7% 的人更喜欢英伟达的新方法。
连同图像调节生成功能,新技术为各种创意应用开辟了新途径。

论文链接:https://arxiv.org/abs/2211.10440
如果感兴趣,可以进一步的去看看相关论文。
5. 如何让AI具有通用能力?新研究:让它睡觉
原文:https://mp.weixin.qq.com/s/ZqiZHVSeqX2oiJITTELZfA
神经网络可以在很多任务上有超越人类的表现,但如果你要求一个 AI 系统吸收新的记忆,它们可能会瞬间忘记之前所学的内容。现在,一项新的研究揭示了神经网络经历睡眠阶段并帮助预防这种健忘症的新方法。
人工神经网络面临的一个主要挑战是「灾难性遗忘」(catastrophic forgetting)。当它们去学习一项新任务时,就有一种不幸的倾向,即突然完全忘记他们以前学到的东西。
本质上,神经网络对数据的表示是对原始数据的一种面向任务的数据「压缩」,新学到的知识会覆盖过去的数据。
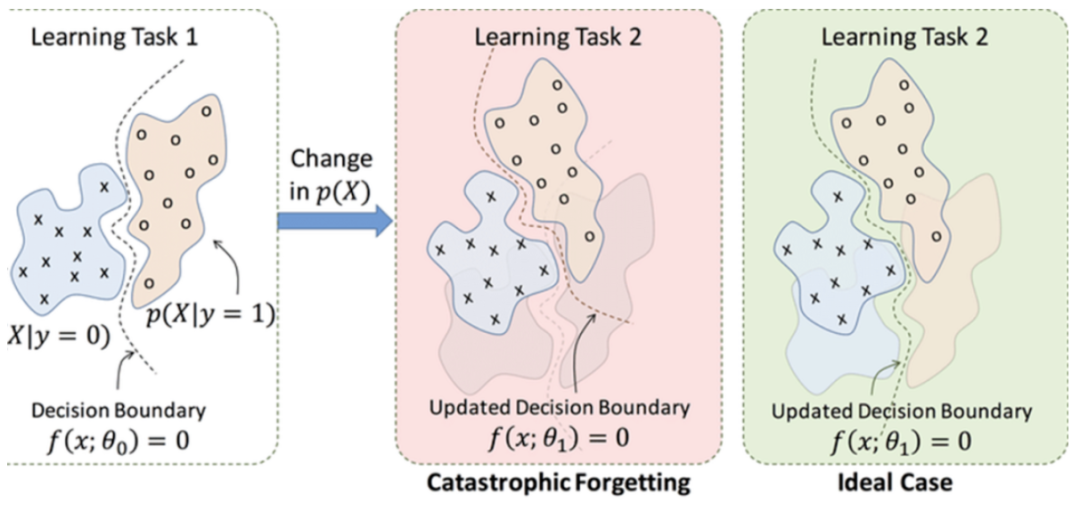
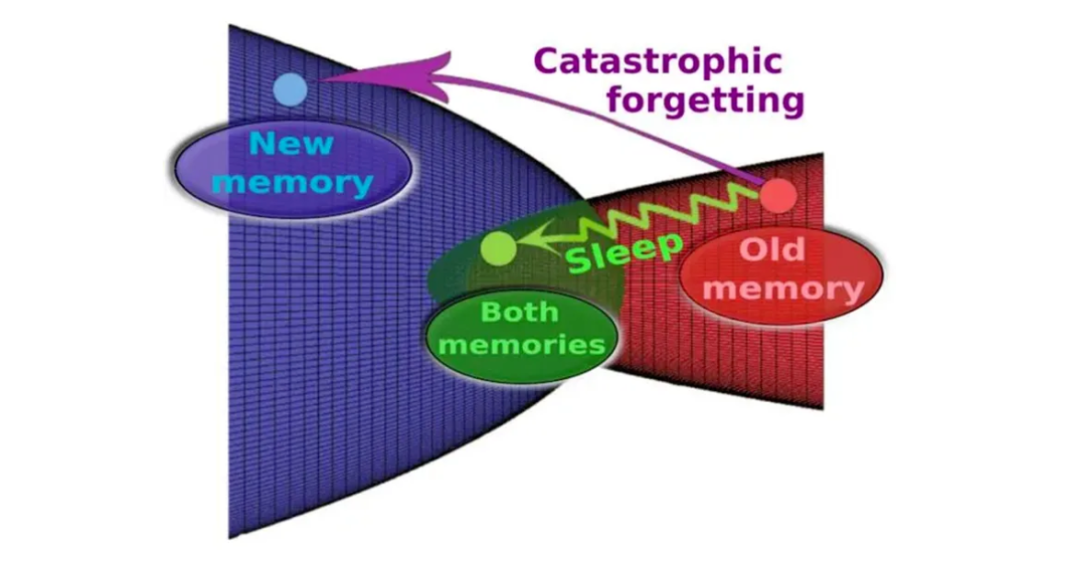
这是当前技术相比人类神经网络的最大缺陷之一:相比之下,人脑能够终身学习新任务,而不会影响其执行先前记忆的任务的能力。我们并不完全知晓其中原因,但早有研究表明,当学习轮次穿插在睡眠期间时,人脑的学习效果最好。睡眠显然有助于将最近的经历纳入长期记忆库。
「重组记忆实际上可能是生物体需要经历睡眠阶段的主要原因之一,」加州大学圣地亚哥分校计算神经科学家 Erik Delanois 说道。
AI 能不能也学会去睡觉?此前的一些研究试图通过让 AI 模拟睡眠来解决灾难性遗忘。例如,当神经网络学习一项新任务时,一种称为交错训练(interleaved training)的策略会同时向机器提供它们之前学习过的旧数据,以帮助它们保留过去的知识。这种方法以前被认为是模仿大脑在睡眠期间的工作方式——不断重播旧的记忆。
然而,科学家们曾假设交错训练需要在神经网络每次想要学习新事物时,为其提供最初用于学习旧技能的所有数据。这不仅需要大量的时间和数据,而且看起来也不是生物大脑在真正的睡眠中所做的事情——生物既没有能力保留学习旧任务所需的所有数据,睡觉时也没有时间重播所有这些内容。
在一项新研究中,研究人员分析了灾难性遗忘背后的机制以及睡眠对于预防问题的效果。研究人员没有使用传统的神经网络,而是使用了一种更接近人类大脑的「脉冲神经网络」。
在人工神经网络中,被称为神经元的组件被填喂数据并共同解决一个问题,例如识别人脸。神经网络反复调整突触——它的神经元之间的联系——并查看由此产生的行为模式是否能更好地找到解决方案。随着时间的推移(不断训练),网络会发现哪些模式最适合计算正确结果。最后它采用这些模式作为默认模式,这被认为是部分模仿了人脑的学习过程。
在人工神经网络中,神经元的输出随着输入的变化而不断变化。相比之下,在脉冲神经网络(SNN)中,一个神经元只有在给定数量的输入信号后,才会产生输出信号,这一过程是对真正生物神经元行为的真实再现。由于脉冲神经网络很少发射脉冲,因此它们比典型的人工神经网络传输的数据更少,原则上也需要更少的电力和通信带宽。
正如预期的那样,脉冲神经网络具有这样一个特点:在初始学习过程中会出现灾难性遗忘,然而,在之后的几轮学习后,经过一段时间间隔,参与学习第一个任务的神经元集合被重新激活。这更接近神经科学家目前认为的睡眠过程。
简单来说就是:SNN 使得之前学习过的记忆痕迹能够在离线处理睡眠期间自动重新激活,并在不受干扰的情况下修改突触权重。
该研究使用带有强化学习的多层 SNN 来探索将新任务训练周期与类睡眠自主活动周期交错,是否可以避免灾难性遗忘。值得注意的是,该研究表明,可以通过周期性地中断新任务中的强化学习(类似睡眠阶段的新任务)来预防灾难性遗忘。
图 1A 显示了一个前馈脉冲神经网络,用于模拟信号从输入到输出。位于输入层 (I) 和隐藏层 (H) 之间的神经元接受无监督学习 (使用非奖励 STDP),H 层和输出(O) 层之间的神经元则接受强化学习(使用奖励 STDP 实现)。
无监督学习允许隐藏层神经元学习来自输入层不同空间位置的不同粒子(particle)模式,而奖励 STDP 使输出层神经元学习基于输入层检测到的粒子模式类型的运动决策。
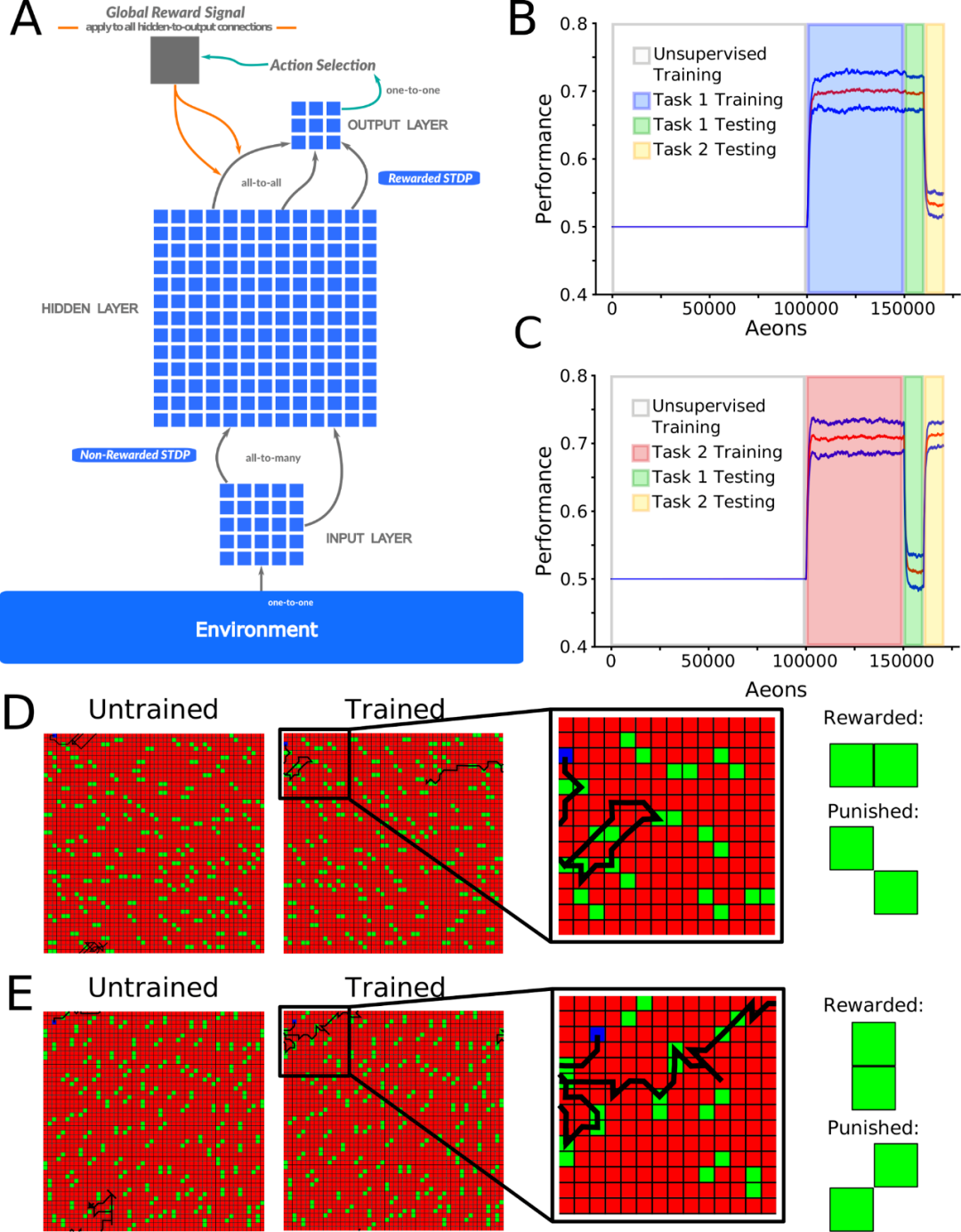
研究人员对网络进行了两项互补的训练。在任一任务中,网络都学会了区分奖励和惩罚的粒子模式,目标是获得尽可能多的奖励。任务将模式可辨性(消耗的奖励与惩罚粒子的比率)视为性能的衡量标准,机会为 0.5。所有报告的结果都基于至少 10 次具有不同随机网络初始化的试验。
为了揭示训练和睡眠期间的突触权重动态,研究人员接下来追踪「任务相关」的突触,即在特定任务训练后在分布的前 10% 中识别的突触。首先训练任务 1,然后训练任务 2,在每次任务训练后识别任务相关突触。接下来再次继续训练任务 1,但将其与睡眠时间交织在一起(交错训练):T1→T2→InterleavedS,T1。任务 1 - 任务 2 的顺序训练导致忘记了任务 1,但是在 InterleavedS 之后,任务 1 被重新学习,而任务 2 也被保留(图 4A 和 4B)。
重要的是,该策略允许我们比较 InterleavedS,T1 训练后的突触权重与单独任务 1 和任务 2 训练后被识别为任务相关的突触权重(图 4C)。任务 1 训练后形成的任务 1 相关突触的分布结构(图 4C;左上)在任务 2 训练(中上)后被破坏,但在 InterleavedS、T1 训练(右上)后部分恢复。任务 2 训练(中下)后任务 2 相关突触的分布结构在任务 1 训练(左下)后不存在,并且在 InterleavedS、T1 训练(右下)后部分保留。
应该注意的是,这种定性模式可以在单个试验中清楚地观察到(图 4C;蓝色条),也可以在试验中推广(图 4C;橙线)。因此,睡眠可以在合并新突触的同时保留重要的突触。
研究人员指出,他们的发现不仅限于脉冲神经网络。Sanda 表示,即将开展的工作表明,类似睡眠的阶段可以帮助「克服标准人工神经网络中的灾难性遗忘」。
该研究于 11 月 18 日发表在《PLOS Computational Biology》杂志上。

论文地址:
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1010628
6. 如何用单个GPU在不到24小时的时间内从零开始训练ViT模型?
原文:https://mp.weixin.qq.com/s/woAWs9l_7Opt63-vJfmhzQ
Transformers已成为计算机视觉最新进展的核心。然而,从头开始训练ViT模型可能会耗费大量资源和时间。在本文中旨在探索降低ViT模型训练成本的方法。引入了一些算法改进,以便能够在有限的硬件(1 GPU)和时间(24小时)资源下从头开始训练ViT模型。
首先,提出了一种向ViT架构添加局部性的有效方法。其次,开发了一种新的图像大小课程学习策略,该策略允许在训练开始时减少从每个图像中提取的patch的数量。最后,我们通过添加硬件和时间限制,提出了流行的ImageNet1k基准的新变体。根据这一基准评估了本文的贡献,并表明在拟定的训练预算下可以显著提高性能。
代码:https://github.com/BorealisAI/efficient-vit-training
1、简介
最近,Transformer架构已成为大量计算机视觉模型的关键组成部分。然而,训练大型变压器模型通常需要付出巨大的成本。例如,在4个GPU上训练像DeiT-S这样的小型ViT大约需要3天时间。
为了降低成本,作者建议探索以下问题:如何用单个GPU在不到24小时的时间内从零开始训练ViT模型。作者认为,由于多种原因,这一方向的进展可能会对计算机视觉研究和应用的未来产生重大影响。
-
加快模型开发。ML中的新模型通常通过运行和分析其上的实验来评估性能,当每次实验的训练成本过高时,这不是一种可扩展的方法。通过降低训练成本,缩短了开发周期。
-
更容易接近。大多数ViT模型都是通过使用多个GPU或TPU从头开始训练的,不幸的是,这将无法获得此类资源的研究人员排除在这一研究领域之外。通过仅使用1个GPU作为基准,显著降低了ViT的训练成本,这使得更多的研究人员能够推动这一研究方向。
-
降低环境成本。降低训练成本的一种方法是开发更高效的专用硬件或更高效的数据表示,如半精度。另一种正交方法是开发更有效的算法。
在本文中,重点讨论第二种方法。已经开发了许多方法(例如剪枝)来降低推理成本,但数量有限的工作正在探索降低训练成本的想法。有工作探索了如何在小型数据集上从头开始训练ViT。也有工作在探索如何在24小时内对文本数据训练BERT模型,但它使用8个GPU的服务器,而作者将自己限制在单个GPU。Primer建议寻找Transformer的更有效的替代品,但它侧重于NLP。作者试图将这项工作的发现应用于ViT,但没有看到任何改进。因此,仍然不清楚为NLP领域开发的改进是否也可以推广到计算机视觉应用中。
作者将目标定义为在固定预算内获得最高绩效指标。为了降低训练成本,提出了两种算法贡献。首先,作者表明,在Transformer编码器架构的每个前馈网络中添加局部机制可以显著提高给定固定资源预算的性能。其次,提出了一种基于图像大小的课程学习策略,以减少训练开始时每个时期的训练时间。训练从小图像开始,然后逐渐将大图像添加到训练中。除了为降低训练成本而引入的算法更改之外,还通过包括资源限制(1 GPU和24小时时间预算)正式定义了在ImageNet1k上的新基准,并在其上评估了模型。
2、本文方法
2.1、Locality in vision Transformer architecture
在本节中,首先解释了ViT架构,然后描述了对架构的更改,以加快训练。
(1)ViT architecture
Vanilla Transformer接收token嵌入的1D序列作为输入。为了处理2D图像,ViT模型将每个输入图像分割成一系列不重叠的reshape 2D块。用可训练的线性投影将面片映射到D维。该投影的输出通常称为patch嵌入。然后,将可学习的位置嵌入添加到块嵌入以编码图像中每个块的位置信息。嵌入向量z'的输出序列用作Transformer编码器的输入。
Transformer编码器由多头自注意力(MSA)和前馈网络(FFN)的交替层组成。在每个块之前应用LayerNorm(LN),在每个块之后应用残差连接。对于具有L个块的Transformer编码器,输出表示按照以下公式计算:
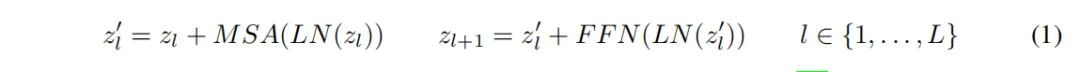
FFN由两个由GELU激活分离的线性层组成。第一个线性层将尺寸从D扩展到4D,第二个线性层则将尺寸从4D减小回D。
(2)Locality in ViT architecture
ViT的自注意力层捕获所有patch之间的全局依赖性,但它缺乏局部诱导偏差,特别是允许在局部区域内进行信息交换的机制。为了将局部性引入到vit中,这里只调整了FFN,而其他部分,如自注意力和位置编码,没有改变。作者建议通过在每个FFN中添加深度卷积层来为ViT架构添加局部性。在FFN中的两个FC层之间添加3×3深度卷积(图1)。在每个3×3深度卷积之前,使用序列到图像(Seq2Im)层将每个reshape的块表示转换为2D块表示。类似地,图像到序列(Im2Seq)层用于将每个2D面片表示转换为reshape patch表示。作者还将GELU激活层替换为h-swish。
(3)Connection with existing works
其他工作探索在ViT架构中添加局部性。他们中的大多数人分析局部机制对最终准确性的影响,没有人研究局部机制对训练速度的影响。最接近架构的工作可能是LocalViT,它也在FFN中使用卷积。LocalViT和本文的模型之间有3个主要区别。
-
首先,本文的体系结构使用LayerNorm作为标准化层,而LocalViT使用2D BatchNorm。
-
其次,在本文的架构中,扩展层和压缩层被实现为完全连接层,而LocalViT使用卷积层。
-
最后,本文的体系结构使用h-swish作为激活层,而LocalViT使用h-swish和SE模块的组合。
作者认为,本文的贡献是重要的,并带来了更高效的架构。
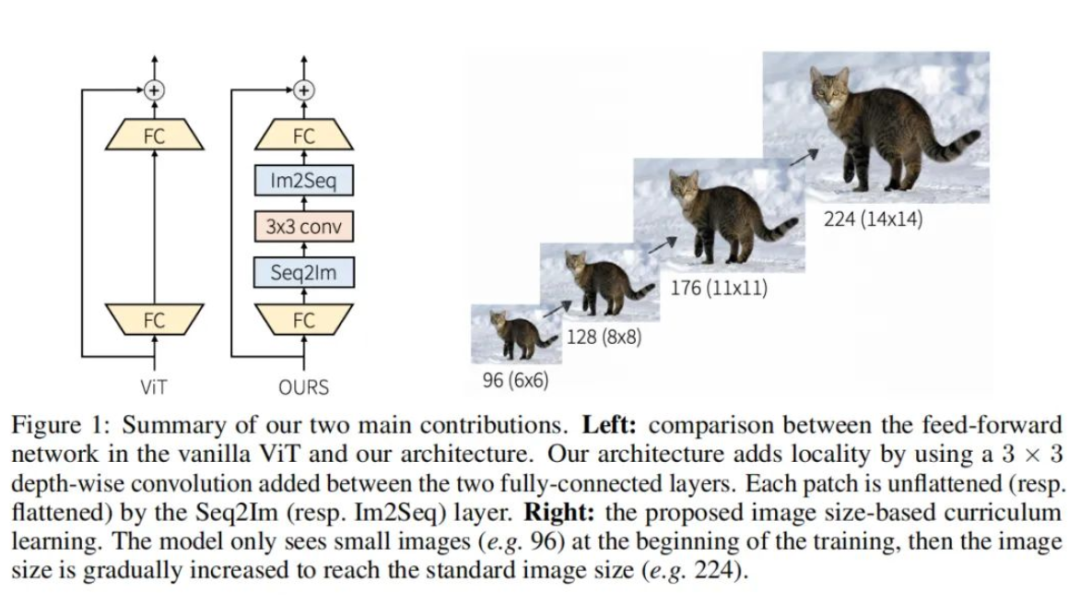
2.2、Image size-based curriculum learning
传统上,训练ViT是通过使用从训练数据中均匀采样的224×224 RGB图像的小批量来完成的。每个图像通常被分解为非重叠的16×16块,因此ViT的输入通常是196个扁平Patch的序列。由于注意力机制,普通ViT架构的复杂性与序列长度(即patch数)成二次关系。在本节中探索了一种减少序列长度(即patch数)以加速训练的方法。作者开发了一种基于小到大图像尺寸的课程学习策略,其中在训练开始时使用较短的patch序列。
课程学习的关键思想是从小处开始,学习任务中更容易的方面,然后逐渐提高难度。使用课程学习有不同的方法,但一种流行的方法是从简单的例子开始训练,然后逐渐添加更难的例子。
作者使用图像大小作为图像难度的代表。在训练开始时,使用低分辨率图像对ViT模型进行训练,然后每隔几个Epoch逐渐提高图像分辨率。通过调整输入图像的大小来实现这一点。图1显示了给定图像的不同图像大小(即课程学习步骤)。在每个Epoch中,所有图像都具有相同的大小,但图像大小可以在Epoch之间增加。然后,一个关键问题是如何设计一个好的策略来增加图像大小。首先,重要的是定义初始图像大小,即第一个Epoch的图像大小。然后,重要的是控制图像大小何时增大。这里使用线性规则,每N个时期将图像大小增加M个像素。在实验部分,分析了这些超参数的影响。
通过构造,vision Transformer架构中的所有层(位置嵌入除外)都可以自动适应多个序列长度。在每次图像尺寸增加之后,通过插值来更新位置嵌入。为了避免处理局部块,只使用可以分解为16×16块的图像大小。在训练期间使用多个图像大小也有助于学习更好的比例不变表示。
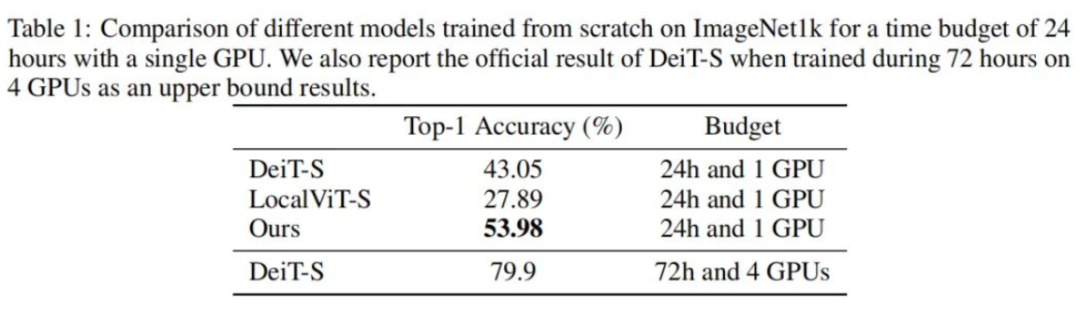
3、实验
你可以添加微信17775983565为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!

爱我就给我点在看
点击阅读原文进入官网
-
RT-Thread
+关注
关注
32文章
1657浏览量
45435
原文标题:【AI简报20221125】高通骁龙8Gen2 VS联发科天玑9200、瑞萨入局RISC-V
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
正面对决A19 Pro,骁龙8 Elite Gen5杀疯了,谁是2025手机真旗舰SoC?

直播预告|玄铁 x Canonical:从本地推理到 AI 工厂,基于 RISC-V 的 AI 基础设施创新路径探讨
RT-Thread 邀您参与“开放・连接”2026玄铁 RISC-V 生态大会,携手共铸 RISC-V“芯”纪元

OrangePi RV2 深度技术评测:RISC-V AI融合架构的先行者
重磅合作!Quintauris 联手 SiFive,加速 RISC-V 在嵌入式与 AI 领域落地
探索RISC-V在机器人领域的潜力
瑞芯微RISC-V芯片已量产,性能、功耗平衡更佳

首发端侧4K生图!单核性能追平苹果A19,联发科重磅发布天玑9500

进迭时空与青少年共赴RISC-V AI科技未来!

联发科野心不小,天玑9500 AI算力直接翻倍

【微五科技CF5010RBT60开发板试用体验】串口输出测试
RISC-V如何盈利?本土企业率先破局

旗舰芯片性能升级关键要看“IPC”,联发科天玑9500初露锋芒

高通放大招!骁龙AR1+Gen1发布,10亿端侧小型语言模型塞进眼镜




评论