 如何借助TigerGraph机器学习工作台加速企业BI
如何借助TigerGraph机器学习工作台加速企业BI
什么是图数据库,为什么要关心图?
做出正确的商业决策需要了解任何一个行动或交易之间的关系,因为它们彼此相关。许多企业、数据分析公司和数据科学家正在寻找新的方法来探索连接和关系,看看我们的数据能给我们带来什么额外的见解。
借助图分析,我们认识到,所有的数据其实都代表了现实世界中的一些东西,而现实世界中的几乎所有东西都以某种方式联系在一起。从关系中找到这些新的模式,可以用来为电子商务网站打造更好的产品推荐,使银行在欺诈发生之前找到潜在欺诈者,或者让制造企业找到提高供应链效率的方法。
TigerGraph Cloud是业界首个也是唯一一个分布式原生图数据库即服务,使用户能够更容易地加速采用图,实时处理分析和事务性工作负载。通过最新的3.8版本,你还可以在TigerGraph Cloud上配置你的ML Workbench Jupyter notebook,为你的图数据库和图机器学习开发环境提供一站式体验。
案例:图增强的ML模型检测欺诈行为
世界各地的公司正在投资于图,将其作为一种竞争优势。图算法和机器学习领域的研究表明,通过将数据构建在一个固有的捕捉上下文和关系的图结构中,可以大大改善预测模型的质量。特别是在欺诈领域,图增强的机器学习模型可以学习欺诈交易和行为人之间的潜在关系模式,而传统的ML方法(如XGBoost模型)则无法捕捉。
在这篇博客中,我们将探讨如何应用图算法和图特征来解决欺诈检测问题。我们将展示如何用TigerGraph构建你的图数据集,然后我们将通过一个Jupyter notebook的例子,用GNN模型构建一个端到端的欺诈检测应用程序,使用Ethereum数据集,其中包含账户(有正面和负面标签)和它们之间的交易。下面是schema的样子:
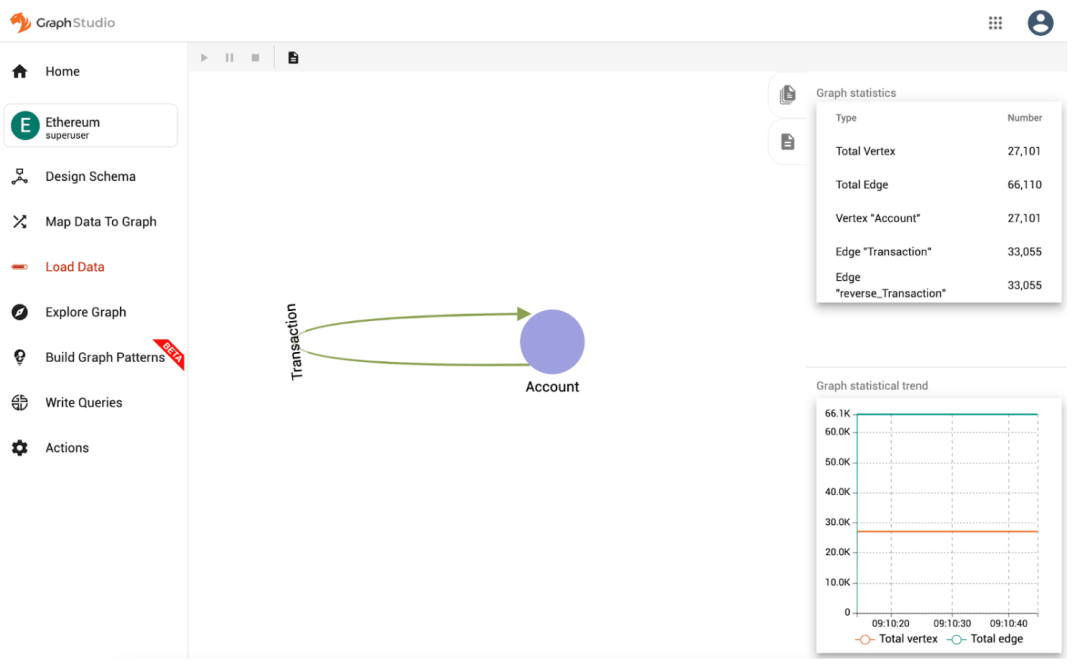
在TigerGraph Cloud上构建你的图
在任何模型开发之前,我们首先需要构建你的图。在这个例子中,我们将使用TigerGraph Cloud的免费版本,这是业界第一个也是唯一一个原生并行图数据库即服务。
要开始使用TigerGraph数据库集群,你只需要通过选择硬件配置来完成集群配置过程。
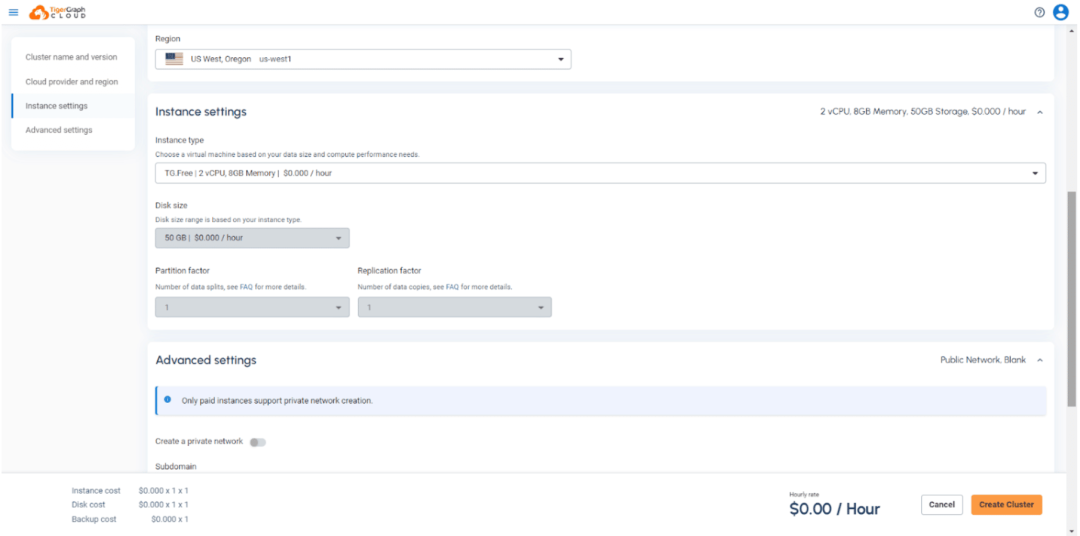
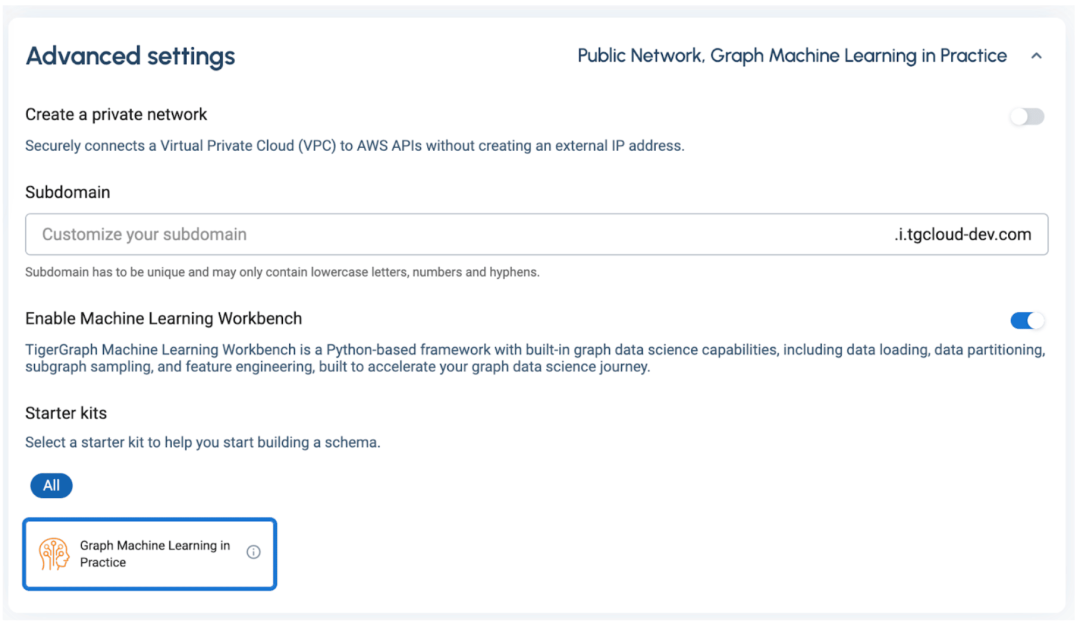
在高级设置部分,确保启用机器学习工作台,然后在入门套件中选择图机器学习,这样它就包括在你的配置集群中。(注意:对于这个版本,我们将只支持单服务器配置,即分区因子=1)
TigerGraph云上的机器学习工作台
TigerGraph云上的机器学习工作台
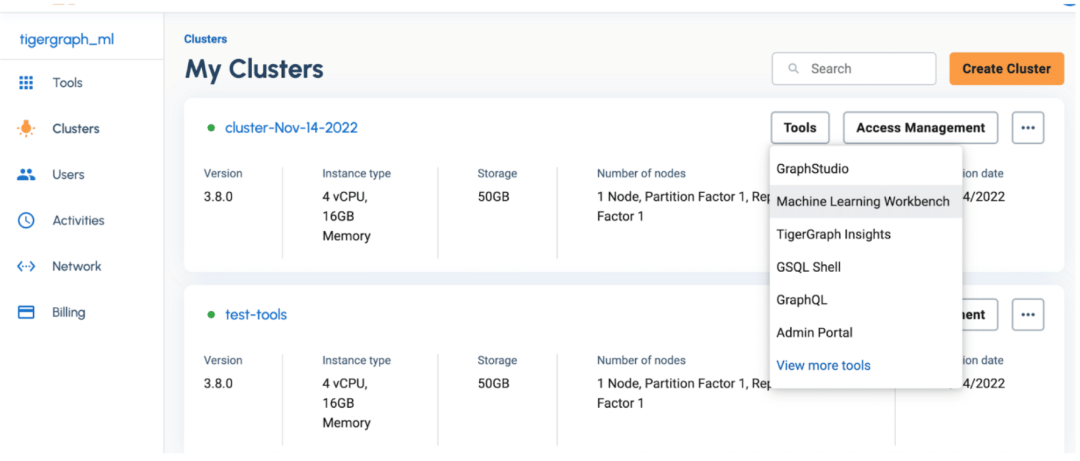
一旦你的图数据库被配置好了,你将需要添加一个用户和密码,以便用机器学习工作台连接到数据库。只需从左边的 “Clusters “选项卡上点击你刚刚配置的集群的 Access Management”,然后用你的凭证点击 “Add User”。
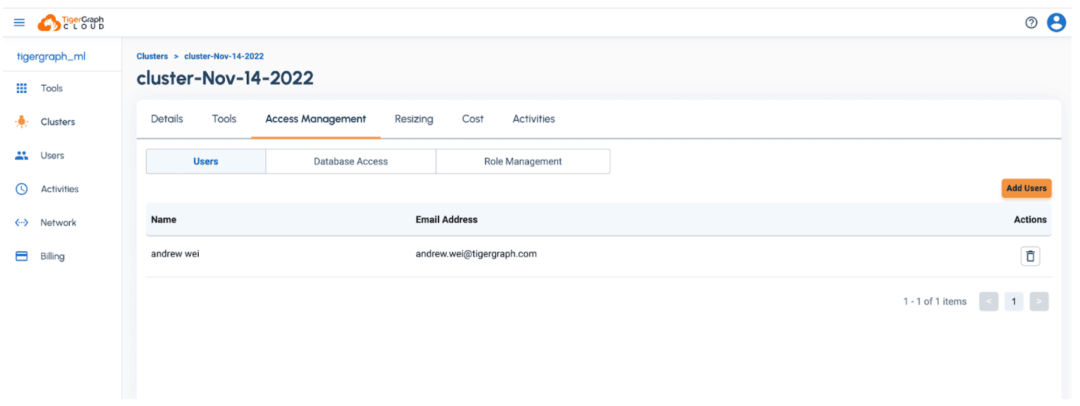
一旦你添加了一个用户,你现在可以直接利用机器学习工作台,点击左侧面板上的集群,然后点击”Tools” 》 “Machine Learning Workbench”。
一个新的浏览器窗口将被打开,你将登陆到机器学习工作台的Jupyter服务器。
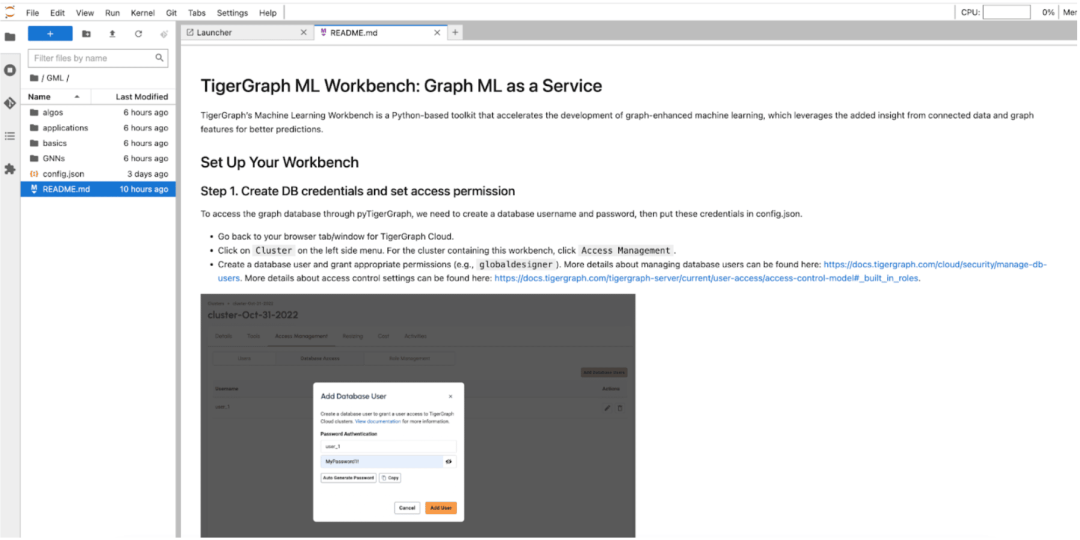
TigerGraph 机器学习工作台有很多很好的教程,包括如何使用pyTigerGraph使用我们的ML功能的例子,运行我们图数据科学库的算法,以及端到端的应用。
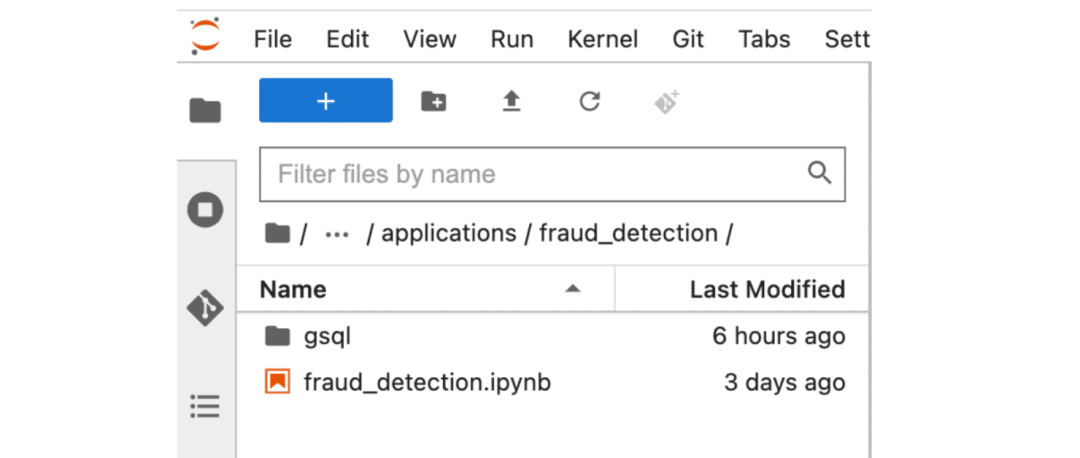
你可能已经听说了最近在人工智能/ML方面的图谱神经网络的突破。在这篇博客中,我们将展示利用我们内置的python功能(如图数据分区、数据导出/批处理和图特征工程)建立一个GNN模型是多么容易。该notebook 可以在下面路径找到:GML→ Applications → Fraud_Detection → Fraud_Detection.ipynb.
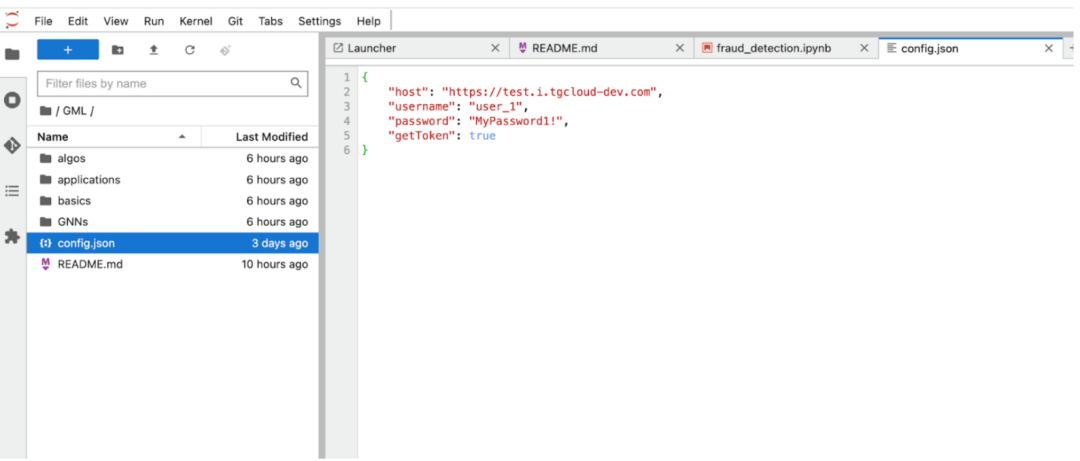
在运行任何代码之前,你首先需要确保config.json中的用户名和密码(在Jupyter服务器的root文件夹中)被相应地更新为你刚刚从tgcloud.io创建的新用户。
准备你的图数据集
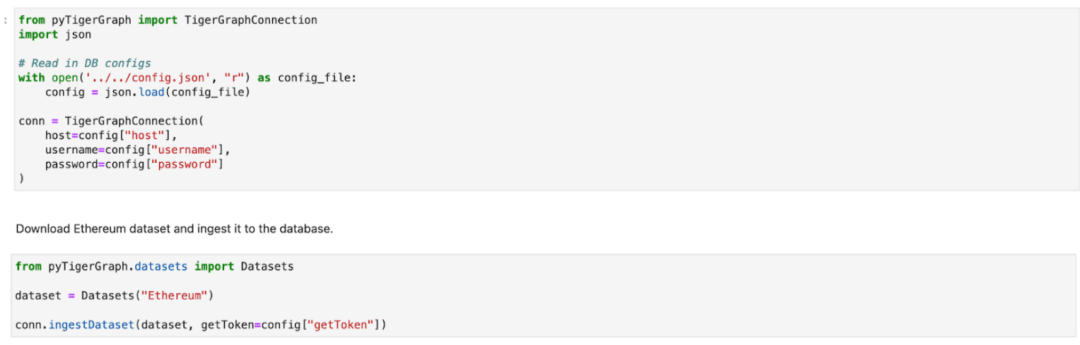
现在,我们已经准备好与TigerGraph云数据库实例建立连接,只需运行以下代码,并将Ethereum 数据集导入到你的实例。
图特征工程
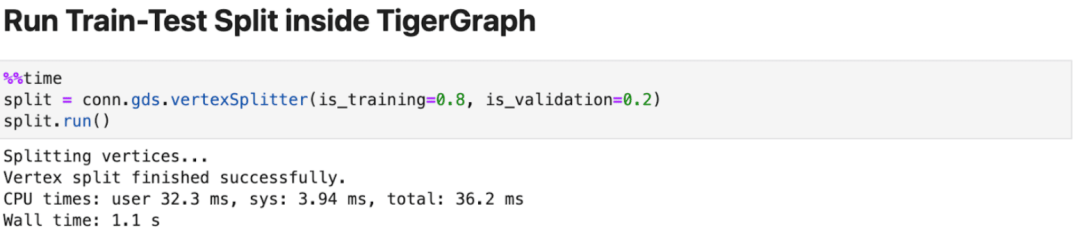
像任何其他监督下的机器学习模型一样,GNN需要训练、验证和测试集来开发模型。ML Workbench通过一个简单的命令使数据分区变得简单。我们将对你的图数据进行分区,同时保留你的数据集的关系。
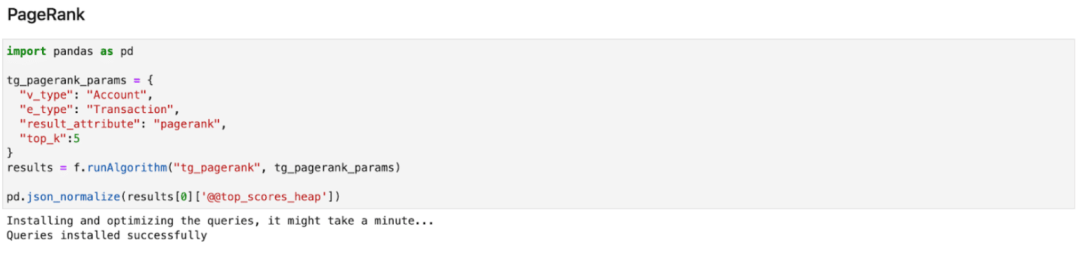
ML workbench 包括TIgerGraph的图数据科学库中的相当多的图算法来进行特征工程。这个notebook 所强调的关键功能是:
listAlgorithm():如果你输入算法的类别(如中心性),它将打印指定类别的可用算法;否则它将打印所有可用的算法类别。
installAlgorithm():获取算法的名称作为输入,如果该算法尚未安装,则安装该算法。
runAlgorithm():获取算法名称和参数以运行该算法。如果该算法尚未安装,并且存在于TigerGraph的图数据科学库中,该算法将自动安装查询语句,并在图中创建必要的schema属性。
下面的代码显示了如何使用Featurizer来获得PageRank作为一个特征。你也可以通过运行你自己的GSQL查询语句,并通过Featurizer运行它,来定义你自己的自定义特征。
现在我们已经完成了特征工程,下一步是使用我们的Neighbor Loader函数导出你的训练、验证和测试数据集。你可以用我们的Neighbor Loader函数定义你的采样策略,如批次大小、跳数和邻居数。

训练你的GNN模型
现在,我们已经完成了图特征工程,并将所有的数据导出到你的机器学习工作台环境,以训练机器学习模型。
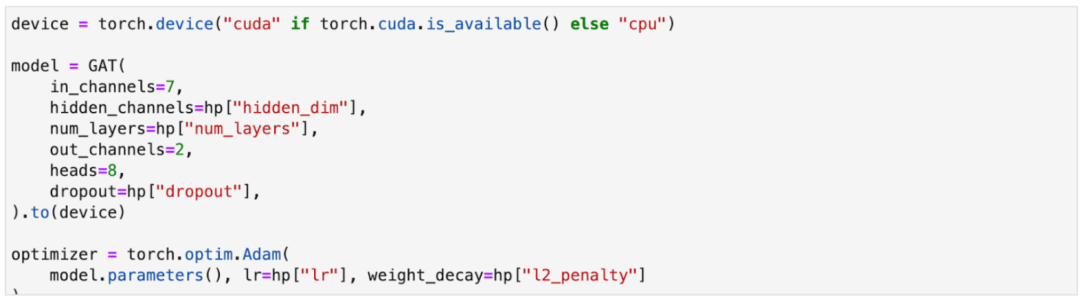
我们拥护开源社区,这就是为什么我们把TigerGraph ML Workbench与一些最流行的深度学习框架兼容,如PyTorch Geometric和Tensorflow。注意在上面的代码中,我们直接将你的关联数据以output_format参数中指定的PyG格式导出,你将能够直接利用PyG来训练一个GNN模型,比如Graph Attention Network( (GATs)算法。请看下面的例子:
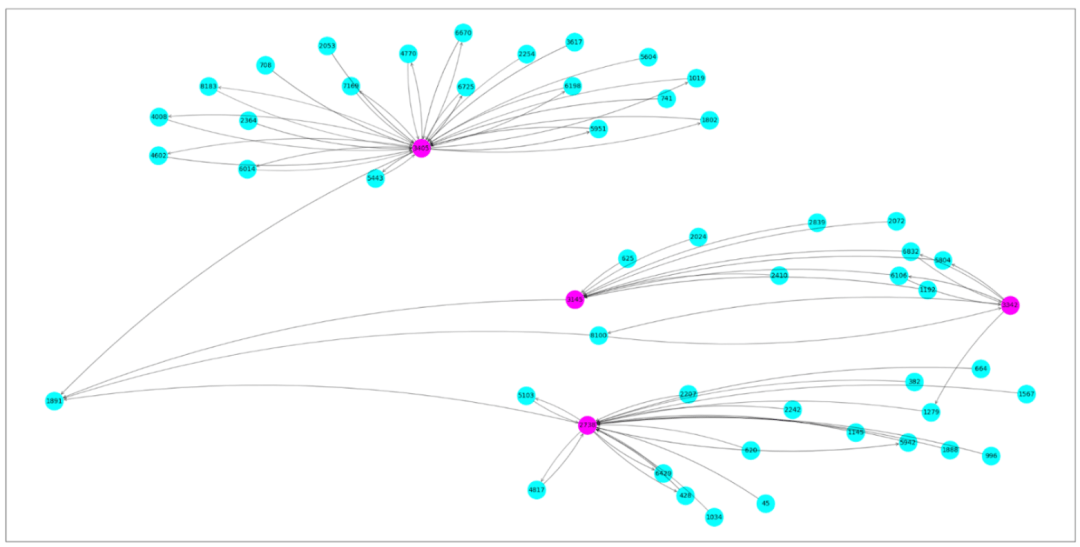
一旦你的模型训练完成,你就可以对你的模型进行推理,看看一个欺诈者是如何通过其网络移动交易的。为了更好地解释预测行为,我们可以将与预测顶点相关的子图可视化。
用子图可视化你的模型预测
在这个例子中,顶点#1891被预测为一个欺诈账户。粉红色的顶点是已知的欺诈账户,用蓝色标识的顶点是未知账户。看起来顶点1891是一个欺诈者网络的幕后策划者,一直在从无辜的用户那里拿钱!
下一步
如果你觉得这篇文章很有趣,并想建立自己的GNN应用程序,请免费试用我们的TigerGraph Cloud和TigerGraph ML Workbench。请从我们的Github(https://github.com/tigergraph/graph-ml-notebooks)上查看我们的教程。你也可以在这篇博文中找到我们所用到的notebook例子的链接。
审核编辑 :李倩
-
数据库
+关注
关注
7文章
3857浏览量
64810 -
机器学习
+关注
关注
66文章
8455浏览量
133186
原文标题:如何借助TigerGraph机器学习工作台加速企业BI
文章出处:【微信号:TigerGraph,微信公众号:TigerGraph】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何选择云原生机器学习平台
适用于MSP430 MCUs的IAR嵌入式工作台IDE版本7+

日本企业借助NVIDIA产品加速AI创新
NPU与机器学习算法的关系
FPGA加速深度学习模型的案例
AI引擎机器学习阵列指南

Cloudera推出机器学习项目加速器 (AMP) 的全新套件
名单公布!【书籍评测活动NO.35】如何用「时间序列与机器学习」解锁未来?
虹软PhotoStudio AI正式入驻阿里巴巴集团旗下的千牛商家工作台
工作台激光焊接机X, Y, Z,三轴功能的区别与作用

Domo与Tableau和Power BI?前Tableau工程师建议最大化BI工具潜能

三轴工作台激光焊接机:实现高精度、高效率焊接的新选择

NVIDIA Isaac机器人平台升级,加速AI机器人技术革新
数据中台:如何构建企业核心竞争力






 工商网监
工商网监
评论