 介绍一个为数据中心租户提供高度可预测的VF服务的框架FAB
介绍一个为数据中心租户提供高度可预测的VF服务的框架FAB

它提出了一种可预测的虚拟结构解决方案——FAB,能够实现为所有流明确选择适当的路径并且在亚毫秒时间尺度内收敛到理想的带宽分配。
背景
在多租户数据中心中,即使所有租户共享相同的物理网络,租户的虚拟机(VMs)也应通过虚拟网络结构(VF)进行逻辑互连。虽然已经提出了许多解决方案来提高多租户数据中心网络的性能,但它们仍然无法提供高度可预测的VF服务——带宽保证、有限的尾延迟。
因此本文提出FAB,这是一个为数据中心租户提供高度可预测的VF服务的框架。它利用可编程数据平面来构建活动边缘(如NIC)和信息核心(如交换机)的融合。在核心中,每个交换机通过网络遥测(INT)将关键信息(如链路利用率和活动带宽订阅)发送给活动边缘。借助核心的实时反馈,边缘可以对路径选择和流量准入做出及时准确的决策来实现预期的网络性能。
设计
FAB整体系统架构如图所示: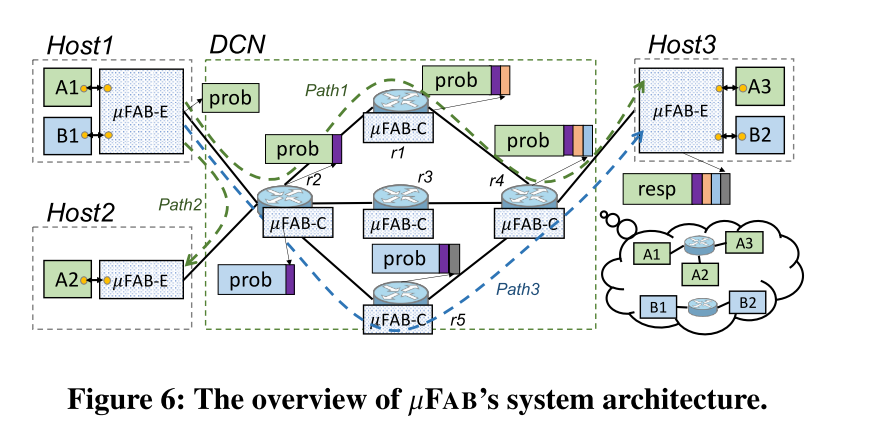
图中显示了FAB将边缘代理(FAB-E)和核心代理(FAB-C)分别安装到DCN边缘和DCN核心中,两种类型的代理通过周期性探测和相应的响应协同工作。在边缘,FAB-E通过隧道或源路由将一个租户的应用程序流从一个VM汇聚到一定数量的底层网络(定向)路径中再发送到另一个VM。
源FAB-E将本地的VF信息,即最小带宽和发送窗口插入到探针中。沿着转发路径,FAB-C将聚合的VF信息,即总带宽订阅和总发送窗口以及网络信息,即链路容量、队列大小、TX速率通过INT插入到探针中。目标FAB-E返回所有在探测器中搭载的信息和响应以及它的本地最小带宽。源FAB-E将目标带宽与其本地带宽进行比较以确定VM对的最小带宽保证。
FAB整体工作流程如图所示: 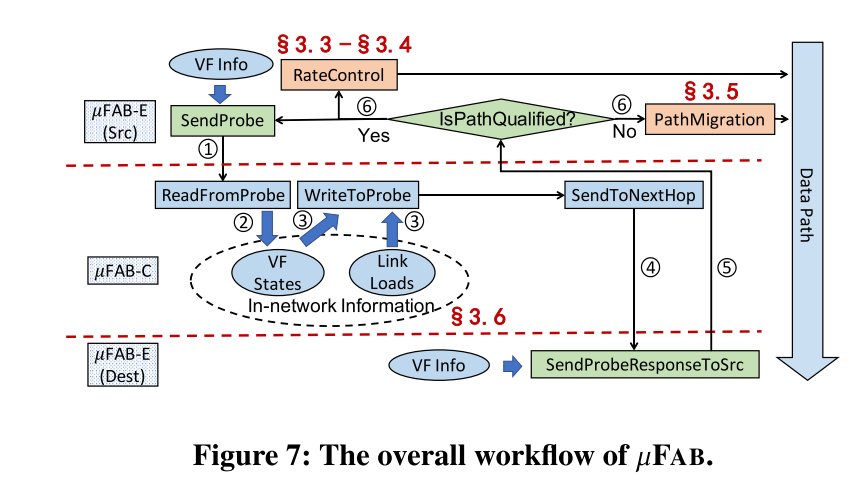
图中显示了FAB的整体工作流程。首先,每个FAB-E沿着活动底层路径发送探针(步骤1)。探针到达FAB-C后,FAB-C读取搭载的VF信息并将其与内部VF信息聚合(步骤2),然后将更新的结果插入到探针(步骤3)。
接下来,探针沿着路径转发到目的地(步骤4)。当目标FAB-E发送的相应返回时(步骤5),源FAB-E将根据相应中提供的信息决定是继续使用经过速率调整的路径还是如果当前路径不再合格就迁移到其他的路径(步骤6)。
性能实验
本文通过使用商品SmartNIC和可编程交换机全面实施FAB。评估表明,在探测带宽开销有限的各种网络情况下,FAB可以保持最小带宽保证、高带宽利用率和接近最优的出传输延迟。
对于如计算和存储场景的应用级实验,FAB相比于替代方案可以将QPS提高2.5倍,并将尾部延迟减少21倍以上。
总结
新推出的可编程数据平面是解决在多租户DCN中提供可预测虚拟结构所面临特殊挑战的关键。FAB就是利用可编程数据平面来融合信息核心和活动边缘来构建可预测的虚拟结构服务。它的创新在于简单有效的机制,使整个网络收敛到可预测的租户级性能(例如保证带宽和有效延迟)和亚毫秒级时间尺度的高利用率。
个人观点
在传统的网络架构中,网络核心(交换机)通常与边缘(终端主机)独立工作,导致核心几乎被视为没有直接反馈的管道,对于这个问题,传统的方式是要么假设一个理想的核心,要么利用启发式推断网络状态。从根本上来说,如果网络核心能够提供明确的信息,这个问题就可以得到解决。利用商品可编程交换机,以前无法访问的网络信息现在都可以被方便的计算、存储和传输。
这类信息允许网络边缘对数据传输做出及时的决策,从而无需经过耗时且不准确的启发式方法。因此,本文的创新点即是利用可编程数据平面来探索如何建立网络核心与边缘之间的协作关系从而在根本上提高VF的可预测性。
Using Trio -- Juniper Networks’ Programmable Chipset -- for Emerging In-Network Applications
Mingran Yang (Massachusetts Institute of Technology), Alex Baban (Juniper Networks), Valery Kugel (Juniper Networks), Jeff Libby (Juniper Networks), Scott Mackie (Juniper Networks), Swamy Sadashivaiah Renu Kananda (Juniper Networks), Chang-Hong Wu (Juniper Networks), Manya Ghobadi (Massachusetts Institute of Technology)
这篇文章来自麻省理工学院和瞻博网络团队的研究者。它介绍了一种用于瞻博网络MX系列路由器和交换机的可编程芯片组——Trio。
背景
可编程交换机的出现,为设计新的数据包处理协议和编译器创造了机会,Tofino交换机还为使用网络内计算来加速应用程序(如缓存、数据库查询处理、机器学习)铺平了道路。尽管可编程交换机一直是这种新范式的关键推动力,但协议独立交换机架构(PISA)通常不适合新兴的网络内应用,因此限制了进一步的增长并阻碍了广泛采用网络内计算的应用程序。
因此,本文介绍了一种用于瞻博网络MX系列路由器和交换机的可编程芯片组——Trio,它的架构基于多线程可编程数据包处理引擎和高容量内存系统的层次结构,使其与基于流水线的架构有根本的不同,此外,Trio还能够处理不同的数据包处理速率,使其成为新兴网络应用程序的理想平台。
设计
1、非流水线架构:基于 Trio 的路由器/交换机和基于 PISA 的交换机的高级比较如下图所示: 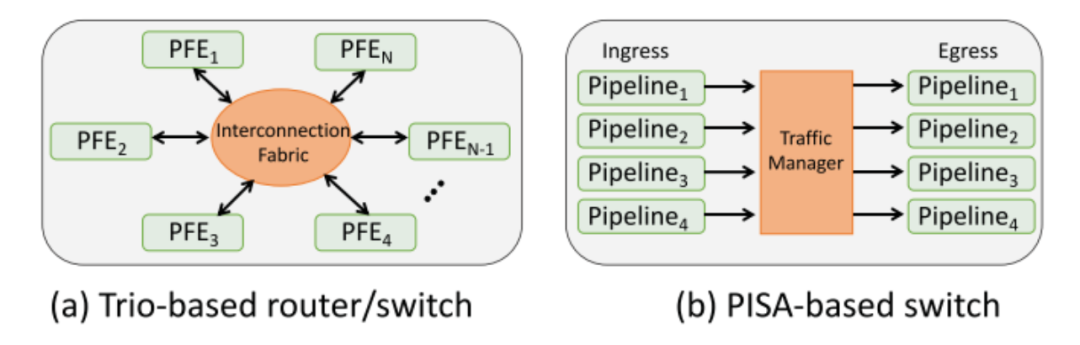
Trio 的架构与 Tofino 的架构有着根本的不同。Trio 具有非流水线架构,因此不同的数据包不会必然流经芯片上相同的物理路径。Trio 中的传入数据包使用数以千计的并行线程独立处理。
这些线程使用 run-tocompletion 模型,其中线程将执行所需的指令,以完成对当前正在处理的数据包的处理。Trio 有专门的逻辑来确保相同流的数据包按顺序传递,但不同流的数据包可以乱序处理,从而使其能够有效地处理并发应用程序的混合。
2、中央处理元件:Trio中央处理元件如下图所示: 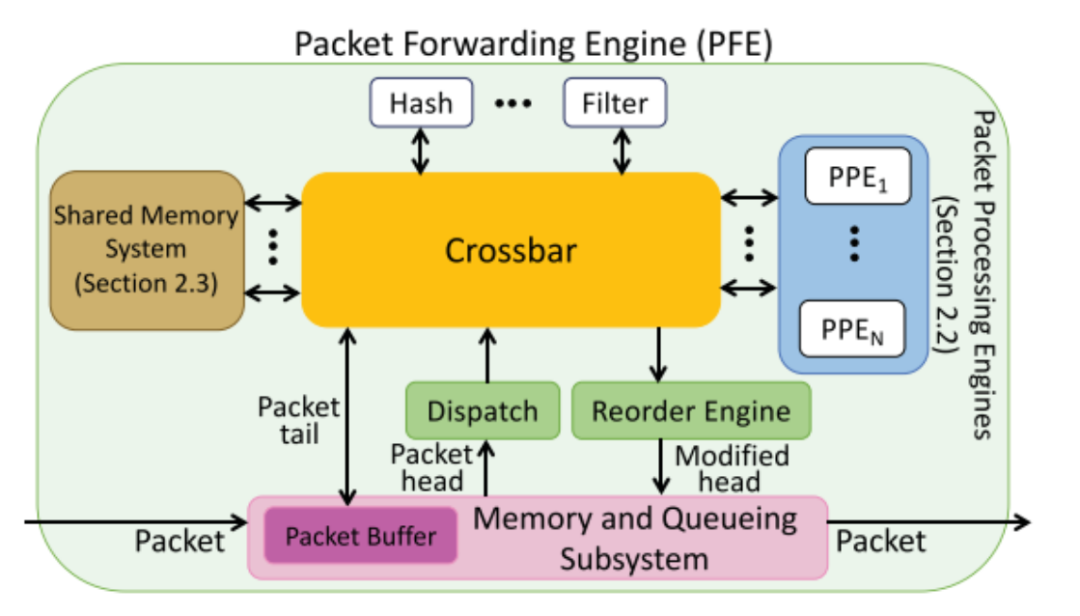
PFE 是 Trio 转发平面的中央处理元件,用于系统地将数据包移入和移出设备。基于 Trio 的设备由一个或多个 PFE 组成。每个 PPE 都在入口和出口方向处理数据包。
每个 PFE 都有数百个多线程数据包处理引擎 (PPE)。当一个新的数据包到达时,PFE 内部的一个硬件模块,称为 Dispatch 模块,根据可用性将数据包头发送到 PPE 进行处理,PPE 为这个数据包头生成一个新线程。数据包尾部保存在内存和排队子系统的 PFE 数据包缓冲区中,以避免在 PPE 线程中存储大量字节。默认情况下,每个线程处理一个数据包。许多 PPE 线程并行工作以提供所需的处理带宽。
当数据包处理完成时,修改后的数据包头被发送到重新排序引擎。重新排序引擎保持更新的数据包头,直到同一流中所有较早到达的数据包都已被处理以确保按顺序交付。然后,重新排序引擎将修改后的数据包头发送到内存和排队子系统,以便排队进行传输。
3、共享内存系统:Trio的共享存储系统如下图所示: 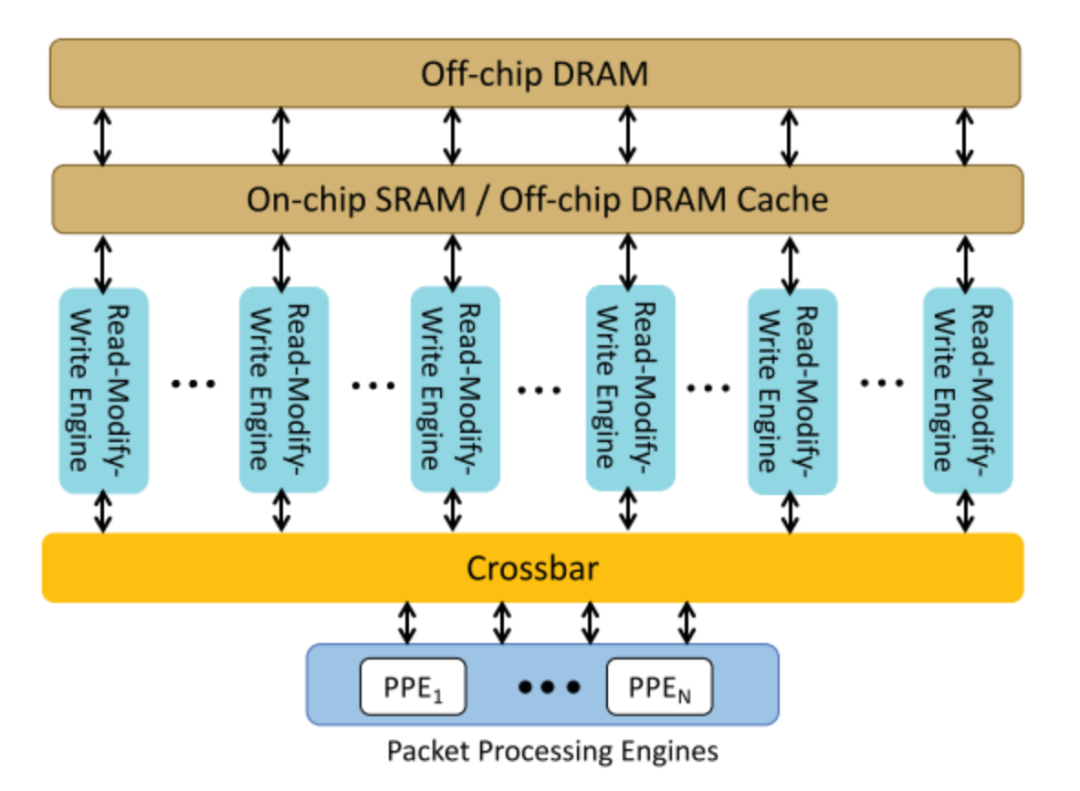
对于交换机和路由器,一些数据结构,例如计数器和监管器,需要高速修改。为了支持数百个 PPE 线程对这些数据结构的高效访问,Trio 的共享内存系统充当所有线程访问和修改数据的地方。数据修改发生在读-修改-写引擎内部,这允许在内存附近进行高速数据更新,很好地满足了数据包处理应用程序的需求。
相比之下,传统处理器使用的基于缓存行的一致性模型需要在访问期间将数据移动到线程,当多个线程尝试修改相同的内存位置时,这会产生更长的延迟。
4、编程语言Microcode:程序员使用一种名为 Microcode 的类 C 语言来编写新应用程序并配置目标 Trio 路由器 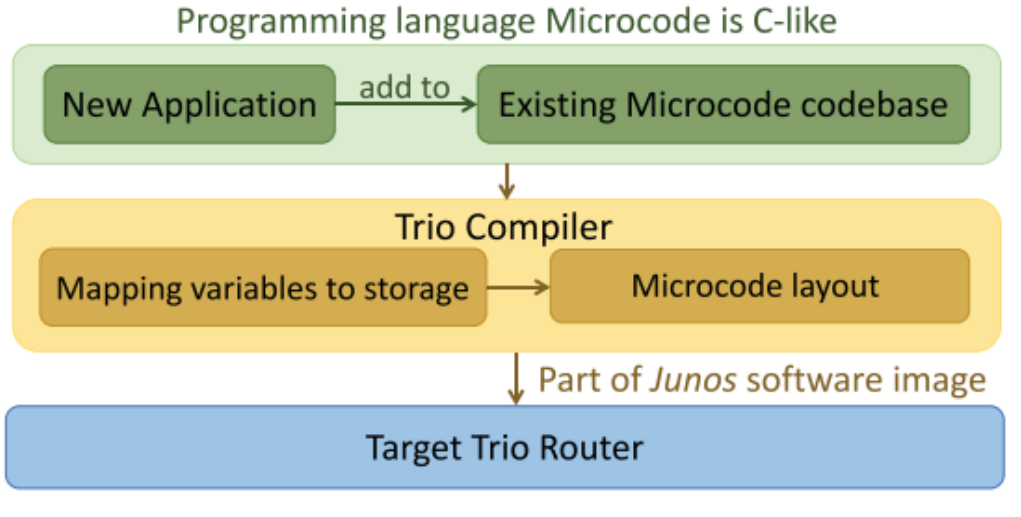
Trio 的设备的编程语言是一种类似于 C 的语言,称为 Microcode。程序员在 Microcode 中实现所有数据包处理操作,包括数据包解析、路由查找、数据包重写和网络内计算(如果有)。
为了在 Trio 上编写新应用程序,程序员使用 Microcode 语言编写新应用程序并将新的 Microcode 程序添加到现有代码库中。然后程序员使用 Trio 的编译器生成软件映像并配置目标器件。
性能实验
本文使用三个真实的 DNN 模型(ResNet50、DenseNet161 和 VGG11)在测试平台上对使用网络内聚合进行分布式机器学习训练和网络内落后者缓解两个用例进行了原型设计,以展示 Trio 在执行网络内聚合时缓解落后者的能力。评估表明,当集群中出现落后者时,Trio 的性能比当今基于管道的解决方案高出 1.8 倍。
总结
本文介绍了瞻博网络的可编程芯片组Trio及其在新兴密集数据型网络应用程序中的用途。本文通过描述Trio的多线程和可编程数据包转发和数据包处理引擎对Trio的设计进行了介绍。然后,使用网络内聚合进行分布式机器学习训练和网络内落后者缓解两个用例来进行了原型设计以展示 Trio 在执行网络内聚合时缓解落后者的能力。
个人观点
本文的创新点在于Trio芯片组的设计使其不仅具有传统ASIC的性能, 而且它能够完全利用可编程处理器的灵活性。它的灵活架构能够使其支持在芯片组发布很久之后开发的功能和协议。它的内存系统也对于具有大内存占用的新兴应用程序的可扩展性至关重要。
Thanos:Programmable Multi-Dimensional Table Filters for Line Rate Network Functions
Vishal Shrivastav (Purdue University)
这篇文章来自普渡大学的Vishal Shrivastav。它主要介绍了Thanos,可以增强现有的可编程交换机pipeline,支持对一组资源进行可编程的多维过滤。
背景
对于性能感知路由、资源感知负载平衡、网络诊断、安全和防火墙等几个关键网络功能来说,基于多维策略在有状态资源特定指标上从一组资源中过滤数据平面中的条目的能力是至关重要的。然而,当前的可编程交换机不支持行率的表级状态过滤。
本文提出了Thanos,它增强了现有的可编程开关管道交换机pipeline,并且Thanos无缝集成多太比特可编程开关管道在名义芯片面积的开销。此外,在交换数据平面表达丰富的过滤策略的能力不仅为网络运营商提供了更多的灵活性,而且它还大大提高了网络性能。然而,不幸的是,由于内存和计算语义的限制,当前一代的可编程交换机无法以线速度表达这样的过滤策略。
Thanos 交换机整体架构: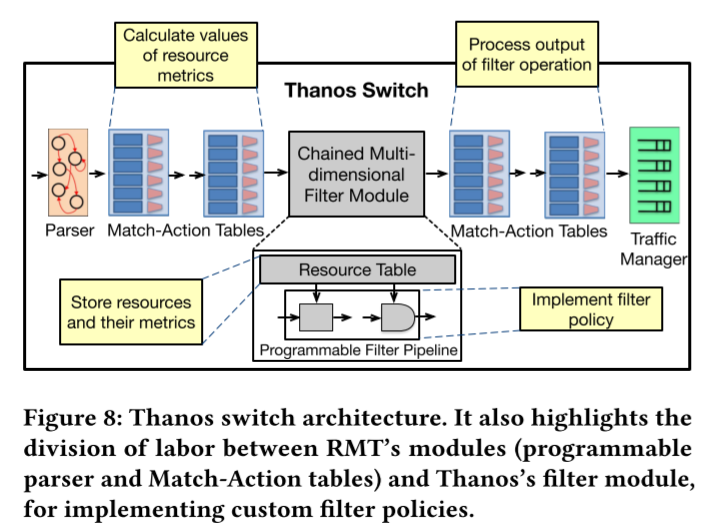
上图显示了Thanos的高级架构,其中过滤器模块与RMT管道的Match-Action阶段内联集成。通常,可以有多个这样的筛选器模块与RMT管道集成,其中每个模块将表示不同资源集上的筛选器策略。每当有数据包到达过滤模块时,该模块就会被触发。
信息包将不加修改地通过过滤器模块,同时,编程的过滤策略将应用于资源集。过滤操作的输出被写入包的元数据,以便在过滤模块之后的RMT阶段进行进一步处理。过滤器模块是完全流水线的,因此可以在每个时钟周期为一个新的包服务。此外,它不希望应用过滤策略的包可以完全跳过过滤模块。
硬件设计
1、资源表: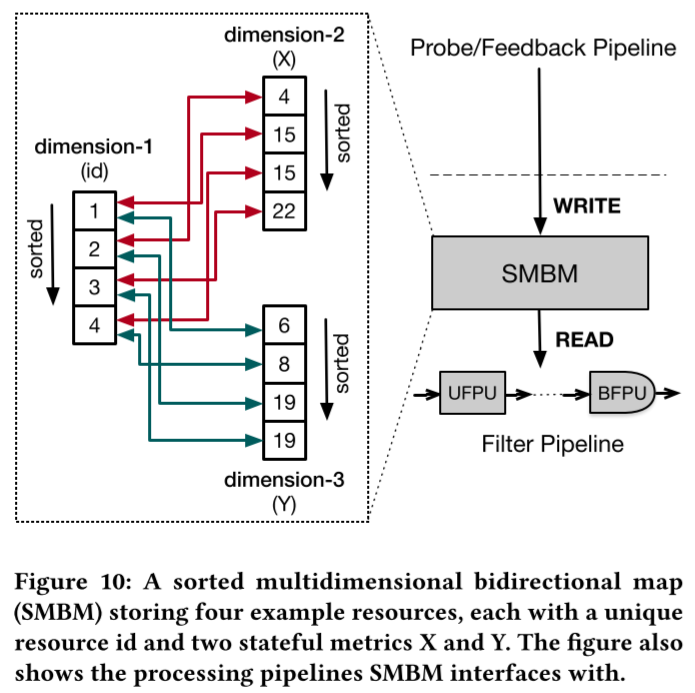
Thanos使用名为Sorted多维双向映射(SMBM)的新硬件数据结构将资源表存储为关系表,具体结构如上图所示。
2、可编程过滤单元: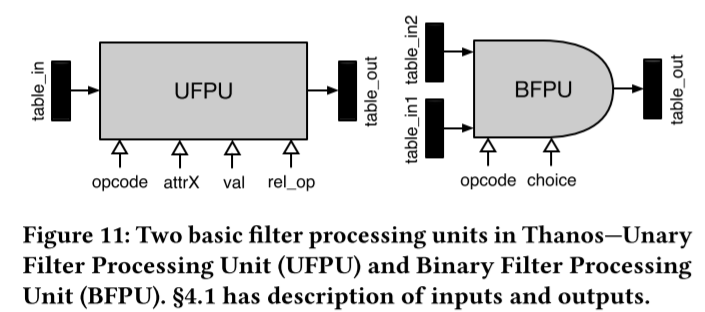
UFPU的输入和输出如图上所示。
3、可编程过滤器链管道: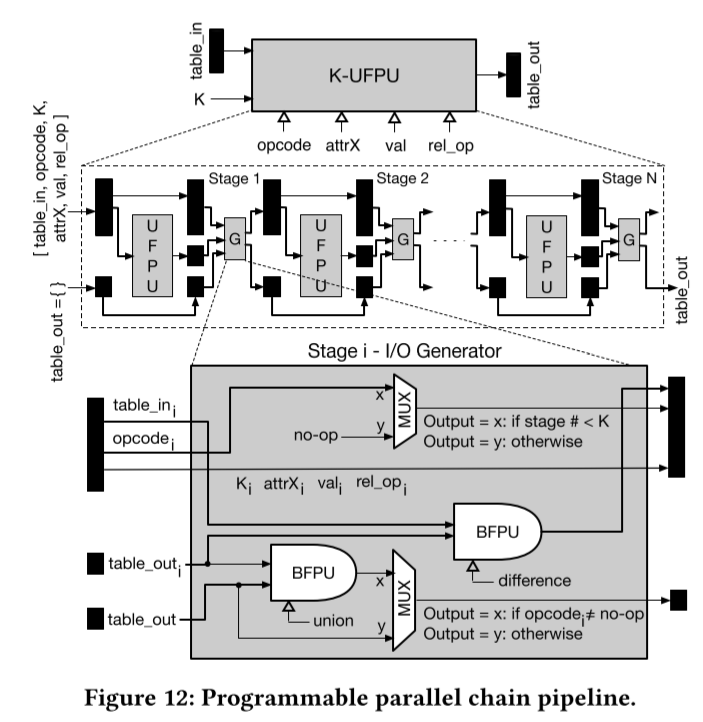
该管道是由N个uppu组成的线性链。我们称之为K-UFPU。K-UFPU的接口与UFPU相同,除了一个名为K的额外输入外,它指定了用操作码中指定的操作来编程的upu的数量(从N开始)。编程后的K个ufpu总是流水线中最接近输入的第一个K个ufpu,而最后剩下的N-K个ufpu使用操作码no-op编程,只是作为一个对最终输出没有影响的旁路电路。
链中每个UFPU的输入根据公式1生成,使用上图所示的一系列I/O生成器实现。注意,通过设置K=1, K-UFPU在功能上等价于UFPU。最后,我们的设计是完全流水线的,假设它的构建块ufpu和bfpu的实现是完全流水线的。
性能测试
本文基于FPGA原型和模拟器进行的评估表明,与最先进的技术相比,Thanos中表达的策略可以将关键网络功能的性能提高1.7倍。
个人观点
Thanos可以使得RTM交换机架构支持多维过滤一系列资源,相比于前代有了很大的性能提升。并且,对于支持Thanos的内网,在一些常见的分布式应用问题上都有很大的性能提升。
Stateful Multi-Pipelined Programmable Switches
Vishal Shrivastav (Purdue University)
这篇文章来自普渡大学的Vishal Shrivastav。它主要介绍了MP5的设计和实现。
背景
由于晶体管扩展速度放缓,单个包处理管道的时钟速率已经饱和,今天的可编程交换机采用多个并行管道来满足高包处理速率。然而,并行处理对有状态包处理提出了挑战,在保持线速率处理的同时,很难保证功能的正确性。本文介绍了MP5的设计和实现,MP5是一种新的多流水线可编程交换机的结构、编译器和运行时,它在功能上相当于逻辑上的单流水线交换机,同时处理数据包的速度也接近理想的所有数据包处理程序。
交换机架构
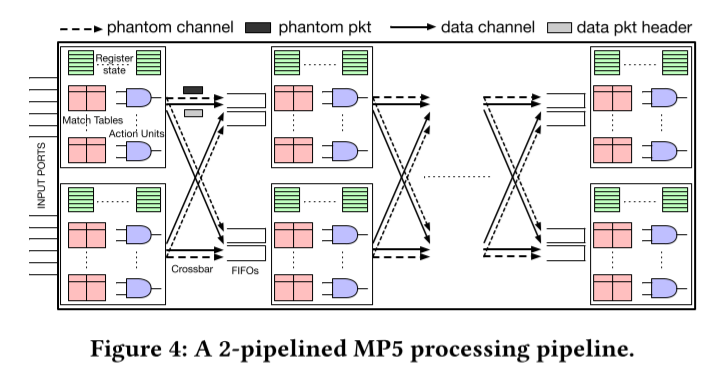
MP5的架构如上图所示。MP5中的k个管道在架构上是相同的。此外,每个管道阶段都与Banzai的管道阶段相同,并包含匹配表、作为操作单元的Banzai原子和有状态寄存器。然而,与Banzai不同的是,MP5中连续管道阶段之间的互连不是线性的,而是由一个交叉杆组成,遵循D3的设计原则。此外,MP5有两个物理上独立且并行的互连通道,一个用于传输数据包(“数据”通道),另一个用于传输幻像数据包(“幻像”通道),遵循D4的设计原则。
此外,MP5的每个阶段也有k个fifo,每个管道一个,在它的输入,缓冲数据包(数据或幻影)等待访问该阶段的寄存器状态。当来自多个管道的数据包可能希望进入相同时钟周期的给定阶段时,需要fifo来处理争用场景。每个管道都有一个单独的FIFO, MP5可以解决这样的争用。物理上,每个FIFO实现为一个独立的环形缓冲区,但逻辑上,k个FIFO作为一个单独的FIFO运行。
语言和编译器

MP5可以使用Domino编程,Domino是一种用于编写Banzai管道的领域特定语言。与P4相比,Domino是一种类似c语言的语言,它提供了编写包处理程序(尤其是有状态程序)的高级抽象。上图展示了一个Domino示例程序。
实现和原型
本文在System Verilog中实现了MP5的设计。本文从单个RMT管道的开源硬件实现开始,并复制它来实现多个管道。本文还使用Banzai模型引入的有状态动作单元来扩充管道。最后,本文加入了互联的crossbar和每个阶段的fifo,以及包转向和动态分片逻辑。
接下来,本文在FPGA和ASIC模拟器上综合了本文的实现。本文使用FPGA原型来运行和评估真正的有状态数据包处理程序,而本文使用ASIC模拟器来估计我们设计的时钟速度和芯片面积开销。最后,由于本文的FPGA原型只有4个端口,每个端口的带宽为10 Gbps,本文还在Python中实现了一个MP5模拟器,以评估MP5在更真实的交换机配置下的性能。
个人观点
MP5既是一种新型的交换机架构,也是一种新型的交换机编译器和并行包处理管线,它和逻辑单数据包处理管线有着同等的效果,也能达到理想的包处理速率。
FAst In-Network GraY Failure Detection for ISPs
Edgar Costa Molero (ETH Zurich), Stefano Vissicchio (University College London), Laurent Vanbever (ETH Zurich)
这篇文章来自 ETH Zurich 和 University College London 的研究者们。主要描述了FANcY的设计和实现。
背景
避免丢包对isp来说至关重要。不幸的是,isp的硬件故障可能会导致长期的数据包丢失,也被称为灰色故障,这是现有的监控工具无法检测到的。本文描述了FANcY的设计和实现,这是一个以isp为目标的系统,可以快速准确地检测和定位灰色故障。FANcY是对以前监控方法的补充,以前的监控方法主要针对低延迟网络,如数据中心网络,不适用于ISP规模。
FANCY整体设计描述
FANcY工作在每个链路的粒度上,为每个交换机端口分别报告丢失。为了检测和定位影响输入表项的灰色故障,每个向下游发送报文的上游FANcY交换机都与下游建立计数会话,一旦上一个会话关闭,就会打开新的会话。在每个计数会话中,上游对下游计数的报文进行标记,标记为待增加的计数器,使两台交换机一致地对同一子集的报文进行相同的计数。
在每个会话结束时,下游将其计数器发回上游,上游将比较计数器,然后立即开始一个新的会话。当它检测到计数器与下游计数器之间的差异时,上游开关通过填充本地寄存器来标记不匹配的计数器。
FANcY计数器被小心地放置,以避免记录由于拥塞而造成的包丢失。在任何交换机中,拥塞通常发生在流量管理器(TM),它实现了实际的交换逻辑,即将数据包从入口管道重定向到配置的出口管道。在FANcY模式中,报文的计数顺序为上游交换机的TM之后,下游交换机的TM之前。
本文设计了FANcY的计数协议,使其对包丢失具有弹性,同时在交换机上使用最小的内存。为了为最佳努力条目提供良好的准确性,本文依赖于一种缩放算法,该算法允许交换机的数据平面在运行时动态地探索基于哈希的树。这减少了FANcY在交换机上的内存消耗,从而允许每个交换机与所有下游交换机保持计数会话。
性能测试
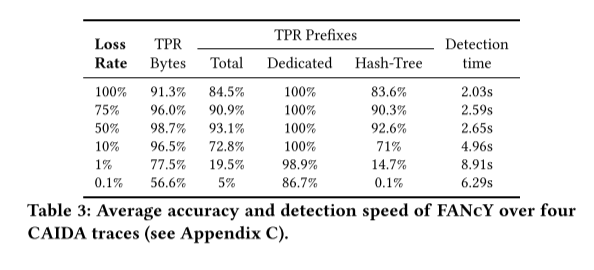
本文通过实验证实了FANcY的能力,可以在数秒内准确检测出灰色故障,只要交通损失的比例很小。本文还在Intel Tofino交换机中实现了FANcY,演示了它如何实现细粒度的快速重路由。本文的评估表明,FANcY可以在ISP设置中快速、准确地检测和定位灰色故障,除了那些导致每个条目很少、零星数据包丢失的故障——正如预期的那样,因为FANcY是一个数据驱动的系统。
个人观点
FANcY是一种数据平面系统,它可以在ISPs中检测内网潜在错误。虽然FANcY主要用来检测和报告错误,但是它的接口仍然能支持未来的一些可选择的快速重路由应用。此外,这篇文章还做了一系列测试,FANcY都能快速检测并定位错误。
审核编辑:刘清
-
虚拟机
+关注
关注
1文章
975浏览量
30753 -
QPS
+关注
关注
0文章
24浏览量
9103 -
FAB
+关注
关注
2文章
35浏览量
10353
原文标题:SIGCOMM 2022 阅读评述——可编程数据平面
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论