 采用检测框架CoP通过控制偏好检测事实不一致
采用检测框架CoP通过控制偏好检测事实不一致
01、研究动机
在生成式摘要任务中,模型基于输入文档逐词生成摘要。随着深度学习的发展,生成式摘要取得了巨大进展。然而在现在的模型所生成的摘要中,超过70%含有事实不一致错误[1]。这些不一致错误严重限制了生成式摘要的实际应用。要解决这个问题的第一步就是评估摘要的一致性,检测出不一致错误。
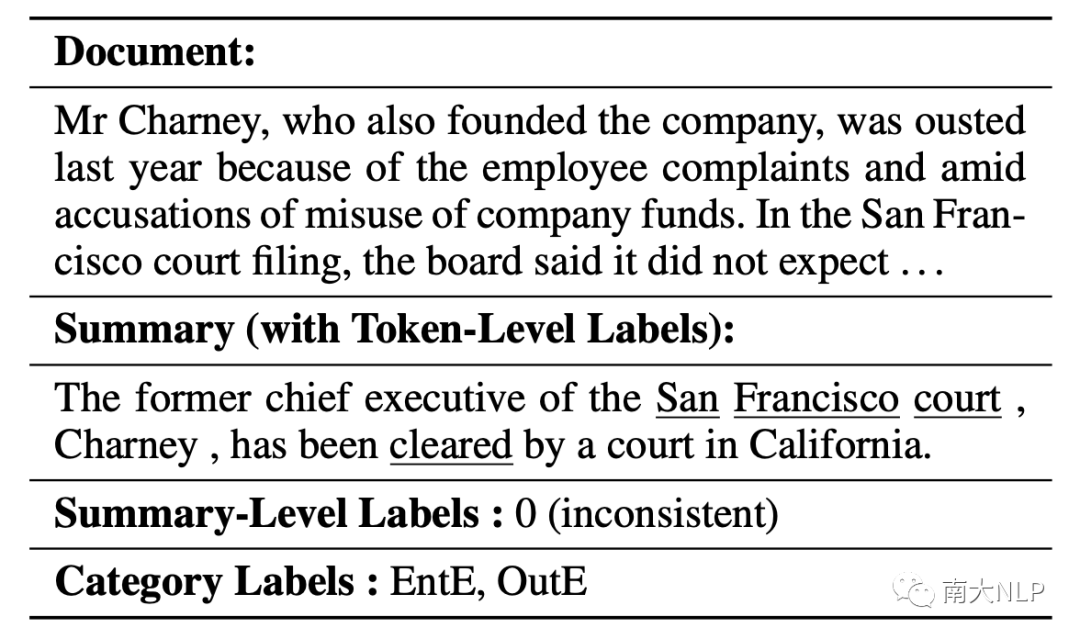
表1:一个多种粒度的事实不一致检测例子(下划线标记是词级别的不一致标注,EntE和OutE是具体不一致类别,对应实体错误以及不在原文错误)
摘要的生成过程中有两个因素:文档X提供重要的事实信息来支持生成一致的摘要内容。同时,在大规模语料上训练的模型M提供语言先验知识来保证生成摘要的流畅性。因此摘要中每个词的生成概率由文档X和模型M联合决定。而生成概率正反映了模型对摘要的偏好,对应存在模型对一致摘要的偏好以及对流畅摘要的偏好。这样的因果关系如图1(a)所示。
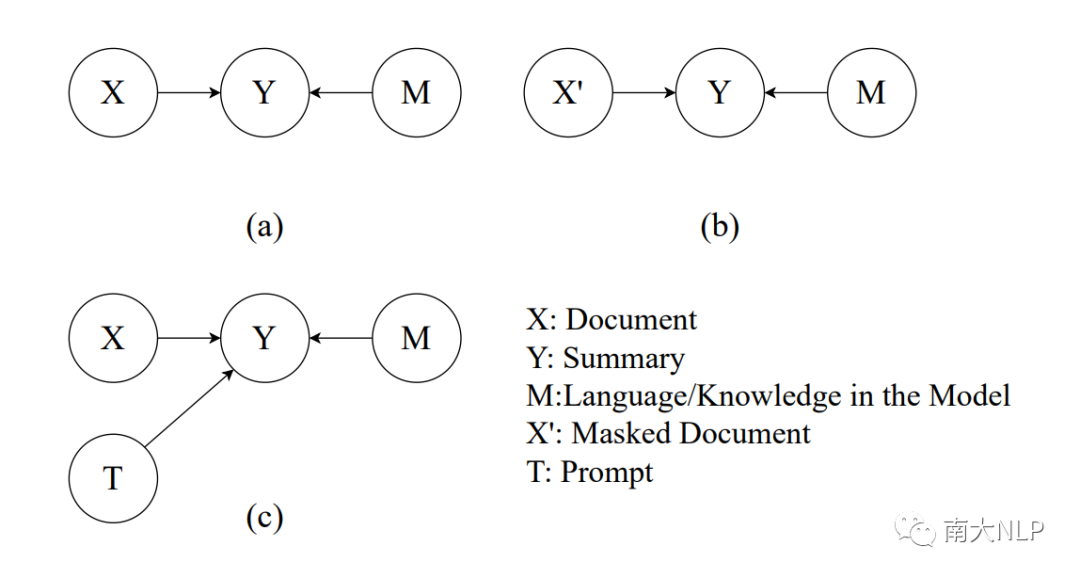
图1:不同推理过程的示意图:(a)常规的推理过程,Y的生成由文档和预训练模型共同决定;(b) CoCo[3]提出的使用部分Mask文档的推理过程;(c)我们提出的使用prompt的推理过程。
一致性评估的本质是衡量摘要Y受原文X支持的程度,也就是衡量X到Y的因果效应。直接使用常规推理过程的生成概率(如BARTScore[2])不能够区分X和M的因果效应,二者的偏好是混杂的。比如一些流畅性很差但是事实一致的摘要会获得一个较低的生成概率,被误判为不一致。概率差分方法使用一个额外推理过程来分离偏好。如图1(b)所示,CoCo[3]使用一个被部分遮盖(Mask)的文档作为额外推理的输入。然而,被遮盖的文档天然缺乏流畅性,违背语言先验知识,评估的过程依然受到和事实一致性无关的偏好影响。除此之外合理且精确的决定遮盖文档中哪些词语也很困难。
02、贡献
我们提出了一个事实不一致检测框架CoP,有三个优势:
在无监督的条件下,利用prompt更好的过滤模型的一致性无关偏好,专注于检测事实不一致。
可以和prompt tuning结合,高效利用少量标签数据训练,进一步提升性能。
通过灵活的设计prompt,不需要额外训练就可以控制特定的偏好来检测具体的不一致类别。
实验结果表明我们的框架CoP在三个事实不一致检测任务上获得了SOTA表现,进一步的实验分析验证了我们方法的有效性。
03、方法
3.1利用带prompt的额外推理来控制偏好
我们的框架包括两个推理过程(图2)。第一次推理和常见的生成过程是一样的:利用文档X作为输入,并将待测摘要Y输入解码器的进行forced-decoding,得到待测摘要Y中每一个词的生成概率。第二次推理我们将文档和一个prompt T一起作为输入,利用类似过程可以得到第二个概率。
我们可以根据实际的应用场景来设计prompt。考虑一个最简单的情况,我们用待测摘要作为prompt (我们称这种离散文本prompt为prompt text)。很直观的,假如待测摘要和输入文档事实一致,那么它是一种输入冗余,因此不会带来巨大的概率变化。相反的,摘要中的不一致部分会带来更大的概率变化。换而言之,差分概率更多的由模型对一致性的偏好引起,进而过滤了无关偏好,例如对流畅性的偏好。具体而言我们用第二次推理的概率减去第一次的概率,计算出差分概率。越大的差分概率意味着和原文的不一致程度越高。高于阈值的词语会被预测为不一致,我们可以根据具体的应用设置阈值来控制预测比例。例如,对于期望更高召回率的不一致改错任务,可以选择一个相对低的阈值。
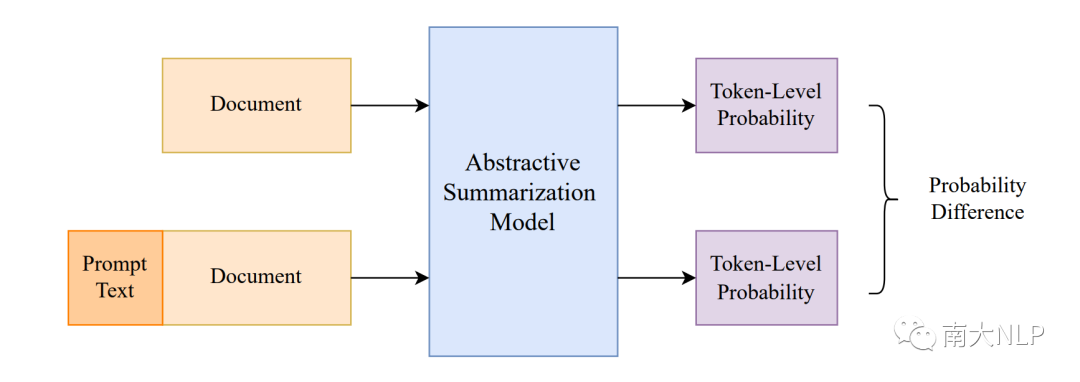
图2:我们的框架CoP示意图
3.2、对具体不一致类别设计prompt
先前的工作[4]详细定义了不一致类型,并统计了类型分布。现有的评估方法往往忽略了这些详细信息。我们认为能够检测不一致类型的评估工具有助于分析现有模型的错误倾向、指导未来的研究方向。其中EntE(实体相关不一致), CorefE(指代相关不一致),OutE(不在原文的不一致)相对高频,分别出现了36%, 10%和27%,我们以它们为例来说明我们框架的工作过程。
最基础的prompt是整个待测摘要,可以覆盖摘要里的所有不一致内容,对应的可以解决OutE。而对于检测其他类别的不一致,我们可以通过添加类别相关的事实信息来针对性控制偏好。对于实体错误,我们从摘要里抽取出实体,并把实体列表拼接到prompt text。对于指代错误,我们类似的对摘要进行指代消解,并将对应的指代信息插入到代词的后面。假如生成概率显著受这些额外的类别相关的事实信息影响,那么我们可以认定这个摘要包含和对应类别相关的不一致。
此时我们仍然获得的是词级别的不一致分数,而类别相关的标注往往是摘要级别的。最简单的方法就是在摘要上对词级别分数做平均(所有词语的权重均等)。然而我们的框架可以精细的检查每一个词的一致性,包含实体词和指代词。我们加倍对应类别词语的权重,让模型更专注于该类别的一致性评估。
3.3利用prompt tuning从有限数据中学习
事实一致性的标注数据相当稀缺。得益于我们框架的灵活性,我们可以集成prompt tuning[5],进一步的从有限的标注数据中学习。从离散的词汇空间中学习prompt text相当困难,因此我们提出了一个小规模的任务相关的连续向量prompt vector。我们希望prompt vector可以帮助模型更好的区分prompt text和输入文档,并引导模型在二者之间做精细的事实分析比对,强化对事实一致性的偏好。
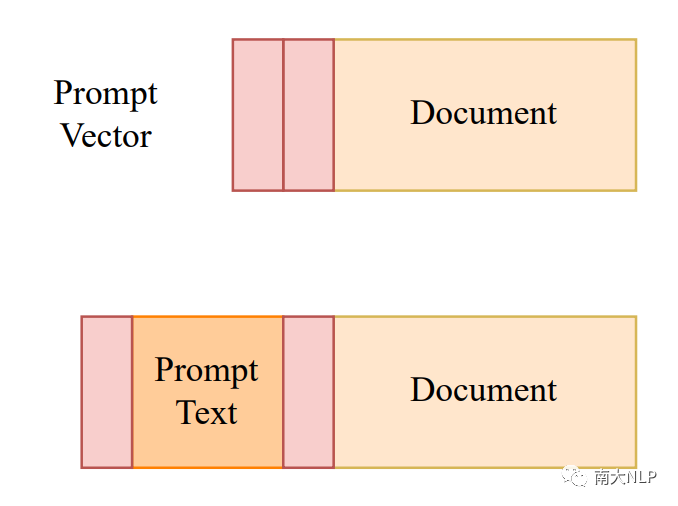
图3:prompt vector示意图(使用红色标出)
如图3所示,我们在第二次推理中的prompt text前后加上prompt vector。为了保证推理过程的一致性,我们在第一次推理中也保留prompt vector,区别在于第一次推理中没有prompt text。我们冻结了整个生成模型,仅学习小规模的prompt vector。使用如下的损失函数进行更新参数:
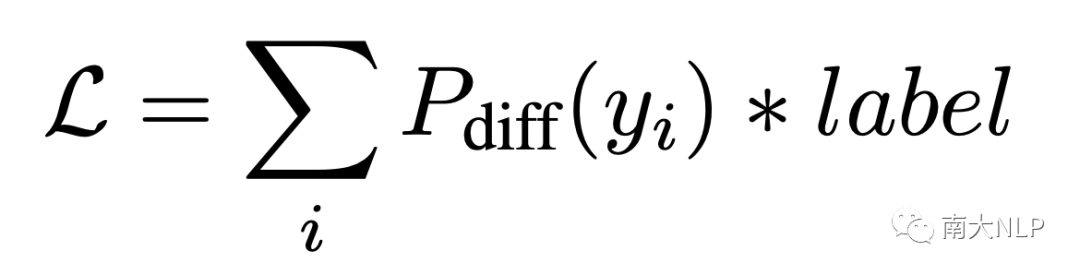
其中label是词级别的标记,用1和-1表示当前词是一致和不一致。损失函数将直接优化任务目标:最大化不一致词语的差分概率,最小化一致词语的差分概率。
04、实验
我们在XSum Hallucination Annotations[1],QAGS [6],FRANK [4]三个数据集上进行实验。XSum Hallucination Annotations数据集提供了词级别的不一致标签,0/1分别表示当前词是一致/不一致。QAGS和FRANK提供了摘要级别的分数来表示一致性,越高的分数代表了越高的一致性。FRANK数据集还提供了不一致类别标签,同样用分数表示。我们测试了三个设置下的CoP,分别是不需要训练的Ours Zero-Shot、使用300条数据训练的Ours Few-Shot,以及使用1200条数据训练的Ours Full-Shot。
4.1无监督下检测不一致
如表2,3所示,我们统计了XSum Hallucination Annotations数据集每一个子集和数据集整体的F1。Ours Zero-Shot效果的效果相当不错,比起之前表现最好的模型BARTScore[2]提升了4.64,直观的证明了利用prompt做额外推理去过滤无关偏好的有效性。即便是比起那些使用大量伪数据的方法,Ours Zero-Shot也相当有竞争力,比DAE-Weak[7]提升了4.62。此外,在每一个数据子集上的稳定提升证明了我们的模型有足够的泛化能力来处理不同模型生成的摘要。
表2:在每一个数据子集上的F1(×100),*代表这个方法不需要训练
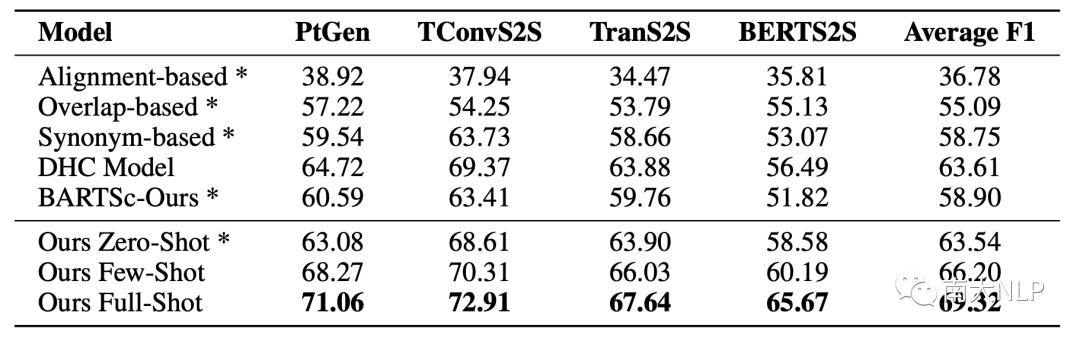
表3:数据集级别的F1(×100),*代表这个方法不需要训练
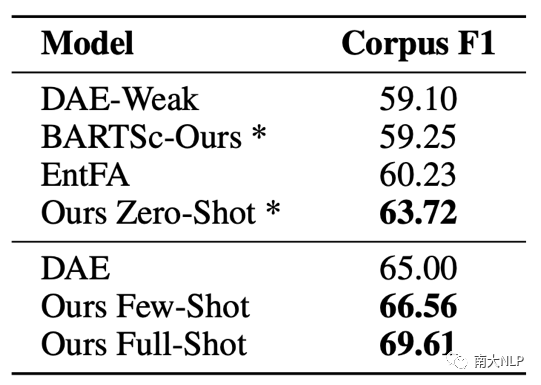
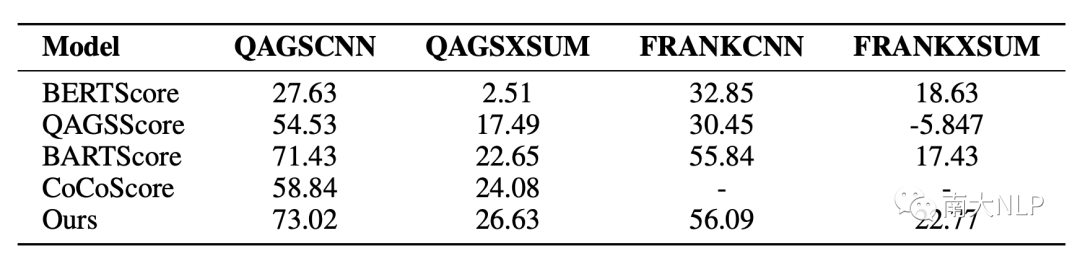
表4展示了在摘要级别上和人工标注分数的Pearson系数,我们的模型在4个数据集上都取得了SOTA。值得注意的是,我们的模型在QAGS-XSUM和FRANK-XSUM上取得了更加显著的提升,分别比BARTScore提升3.98和5.34。XSUM是一个更加抽象且含有更多噪音的数据集,在XSUM上取得显著优势表明CoP能够更好的分离语言知识偏好,专注于不一致的检测。
表4:指标评估和人工一致性分数的摘要级别Pearson系数(×100)
4.2结合prompt tuning高效改进性能
我们进一步的在词级别的不一致检测任务上验证prompt tuning的有效性,结果如表2和表3所示。CoP仅仅使用300条真实数据就超过了使用2000条真实数据的DAE以及使用960k伪数据的DHC,达到了SOTA水平。这表明了CoP能够更加有效的从少量数据中学习。当标记数据增多时,模型的性能也能进一步提升。当我们使用完整的1200条数据训练时,数据集级别的F1达到69.61,比表现很不错的Zero-Shot进一步提升9.24%。和使用2000条数据的DAE相比,CoP提升了4.61,展示了更高的学习效率。
4.3具体类别的事实不一致检测
表5和表6的结果表明Our Base已经超过了之前的工作,证明CoP不仅擅长检测细粒度的不一致,也能够很好的检测具体类别的不一致错误,而CoP还可以通过设计和使用多样的prompt进一步的提升多种不一致类别的检测结果。值得注意的是这个过程并不需要任何额外训练。
此外我们还注意到,当我们的模型改进特定不一致类别的检测结果时,还影响了整体和OutE这两种不一致类型。我们认为这可能因为(1)EntE是一个相当常见的错误,改进这个类别会加强模型对整体不一致程度的评估。(2)各种不一致类别之间也存在联系,比如EntE和OutE。当模型无法很好的理解原文的实体时,它也很容易产生不在原文的不一致。我们在附录里进一步讨论了不一致类别之间的关系。
表5:指标评估和人工CorefE标注分数的Pearson系数(×100)
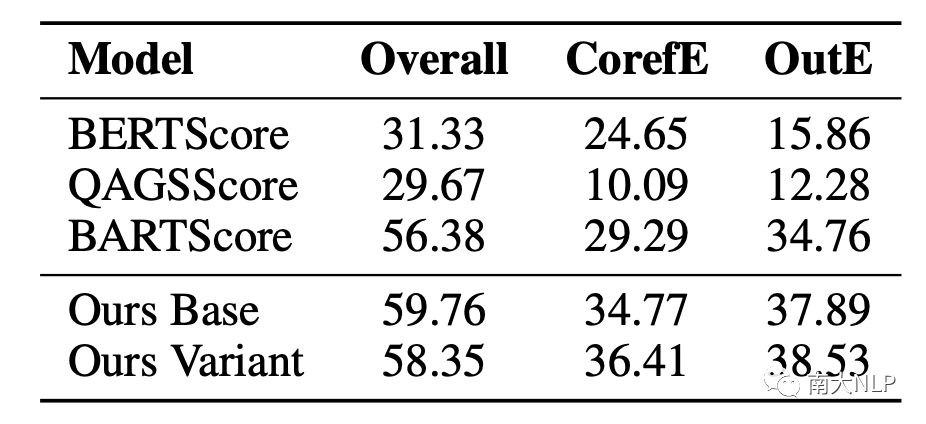
表6:指标评估和人工EntE标注分数的Pearson系数(×100)
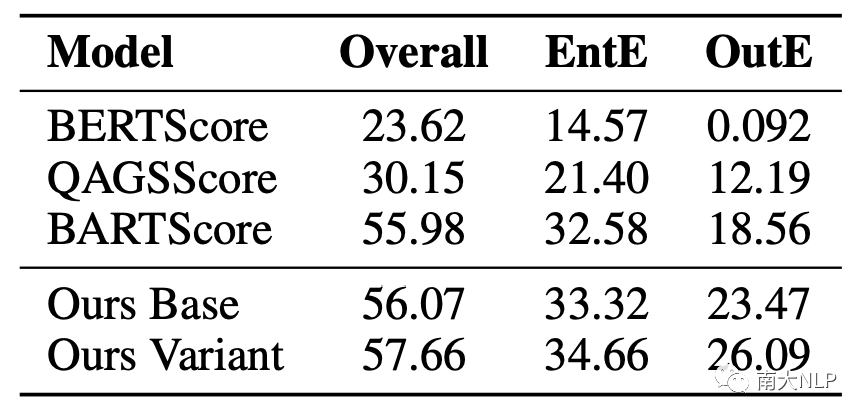
05、分析
5.1不同backbone上的鲁棒性
我们在QAGS-CNN上测试了基于不同的backbone的CoP和baseline,结果于表7。可以看到在不同backbone上CoP保持了稳定的优势,证明了其鲁棒性。
表7:在不同Backbone上的表现
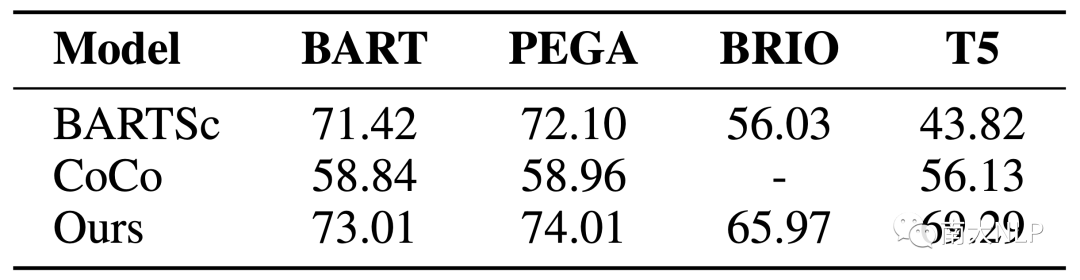
5.2灵活的prompt vector长度
作为第一篇在一致性领域结合prompt tuning的工作,我们也分析了prompt vector长度的影响。如图4所示,随着长度的增加,受益于更多可训练参数带来的更强表达能力,模型的效果会逐渐提升。但和prefix tuning[5]类似的,超过阈值之后效果出现了一些下降,这可能是因为更多参数带来的过拟合数据噪音的风险。比起先前的工作只能从一个固定大小的预训练模型开始训练,我们可以通过灵活调节参数量适应实际应用的不同数据规模。
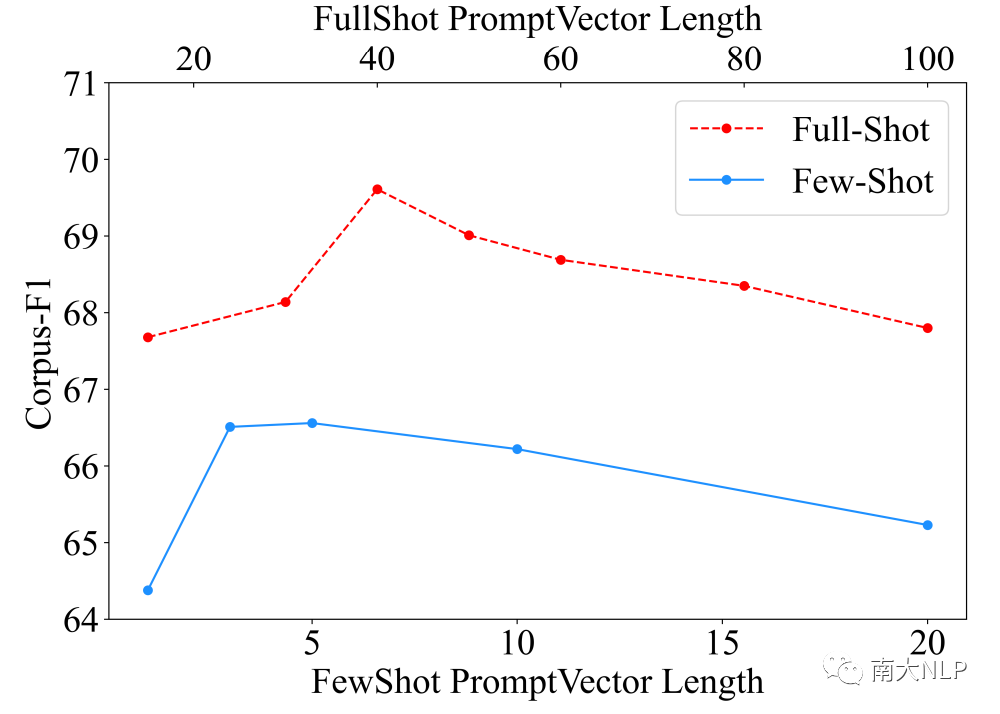
图4:prompt vector长度和数据集级别F1,两个X轴对应两个训练设定
5.3 prompt tuning带来更清晰的决策边界
我们可视化了CoP预测的评估分数于图5。可以观察到在Zero-Shot下,分数分布就存在区别,很直接的解释了为什么CoP可以在无监督环境下工作。而利用prompt tuning从微量数据中学习之后,分数的分布呈现了更加清晰的边界,极大的帮助CoP分辨出摘要的不一致。
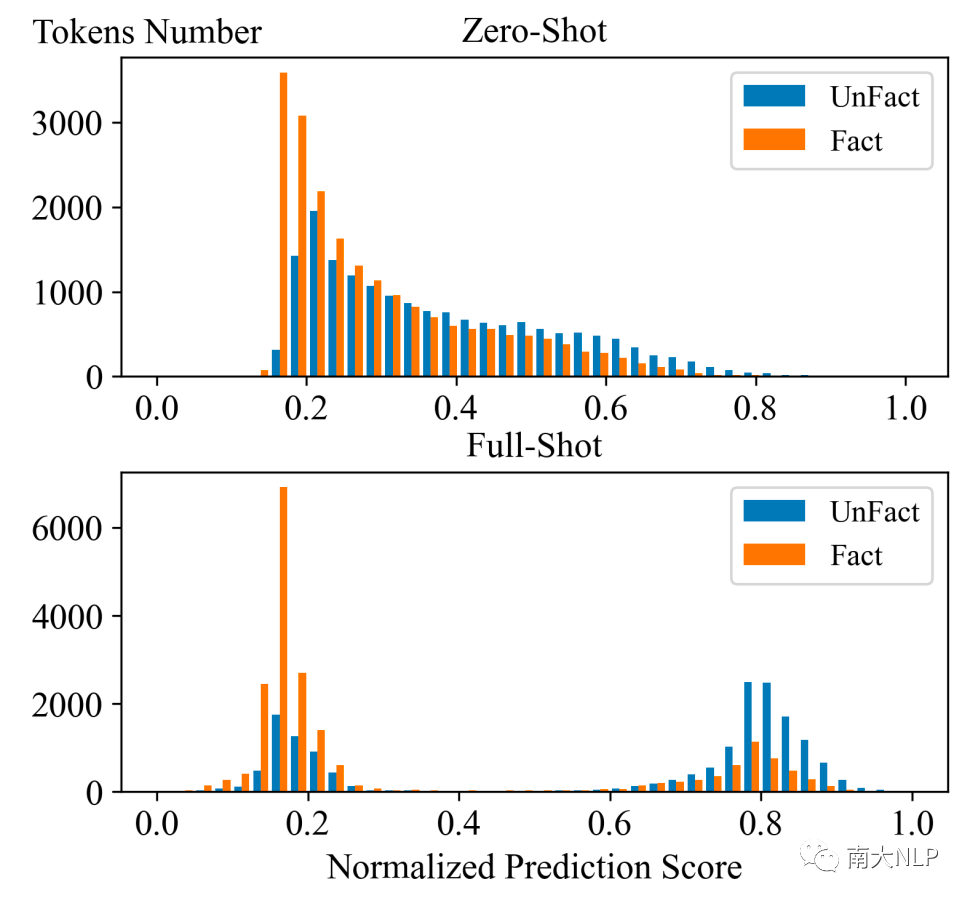
图5:标准化后的分数分布,更高的分数代表CoP认为这个词更可能是不一致
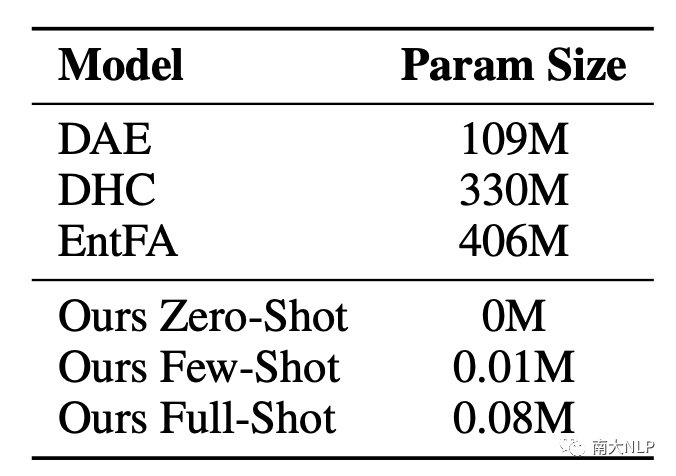
5.4高效的少量训练参数
可训练参数的规模极大影响训练效率以及所需显存。在这个低资源任务中,之前的工作为了训练大模型,往往需要构造大量伪数据,增加了训练代价。伪数据和真实数据分布的差异,也导致了天然性能差距。我们比较CoP和之前工作的参数规模,结果显示我们仅仅用了0.02%的参数就超过了之前的工作,展示了我们框架的高效性。
表8:不同方法的可训练参数规模
5.5样例分析
表9:越高的分数代表模型认为摘要更一致(下划线是词级别不一致标注)
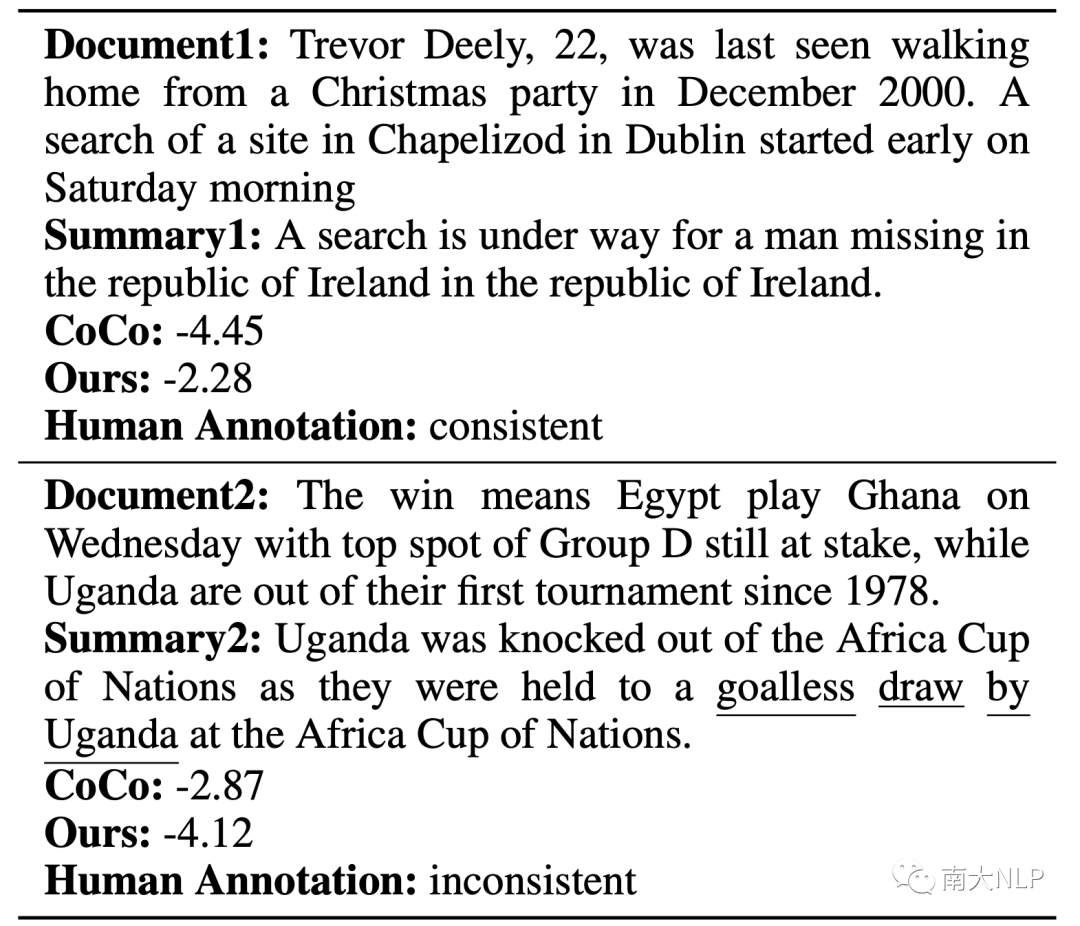
我们展示了两个测试集的例子。摘要1是事实一致的,但是存在生成冗余。对于那些不能很好过滤流畅性偏好的方法,生成冗余会误导模型去认为这个摘要不一致。显然我们的方法给出了一个更合理的分数。另一个例子则相反,相当流畅且仅仅在一些核心词语上出现了不一致错误。CoCo给了一个更高的分数,并不能发现不一致错误,CoP展现了更好检测事实不一致的能力。
06、总结
在本篇工作中,我们提出了CoP,利用prompt来控制模型偏好,检测事实不一致。通过分离无关偏好,CoP不需要训练就可以精确的检测出事实不一致。此外CoP可以衡量特定类型的偏好并检测出具体不一致类型。我们还探索了结合prompt tuning来高效的从少量真实数据中学习。CoP在三个不一致检测任务上取得了SOTA结果,证明了我们方法的有效性。
审核编辑:郭婷
-
深度学习
+关注
关注
73文章
5511浏览量
121355
原文标题:AAAI2023 | 通过控制偏好检测事实不一致
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ADS1293 DRDYB与读数据的关系为什么与手册描述的不一致?为什么?
HDJB-9000合并单元数模一体继电保护综合测试系统做三相不一致保护方法

光纤压板不一致怎么处理
为什么ADS1263 MOSI(DIN)每个命令周期对应的miso(DOUT)不一致?
PCM5102A左右声道THD不一致是哪里出了问题?
使用INA317这款仪表放大器时,增益和设置的Rg电阻不一致,为什么?
STM32H750DMA+SPi内存数据不一致的原因?
增量编码器计数值和实际角度不一致怎么办?






 工商网监
工商网监
评论