 关于视觉SLAM直接法的介绍
关于视觉SLAM直接法的介绍
本次内容包括三个部分,分别是三维几何学的基础和特征点法和直接法的对比,直接法的代表工作以及对于未来发展的展望。
三维几何学基础知识
关于基础知识,首先要了解的是刚体运动的基本属性。三维空间的刚体运动通常包括六个自由度,对应的转换矩阵的表达方式在不同的文献中有不同的方式,而在学术写作的时候,不管用哪一种,重要的是一定要保持格式的统一和连贯。此外,转换矩阵所描述的不是某种运动,而是点在不同坐标系的转换。第二个比较重要的基础知识是本质矩阵和对极几何。
考虑下列场景:我们用两个摄像头可以同时观测到一个特征点,利用匹配的特征点,我们将可以建立对极约束,当匹配的特征点足够多时,我们将可以求解本质矩阵,比如使用常用的八点法,当求解完成后,我们就可以从本质矩阵中分解得到两个相机位置相对的位移和旋转。值得注意的是本质矩阵的自由度是5,因为在位移上,我们丢失了一个自由度的尺度信息。
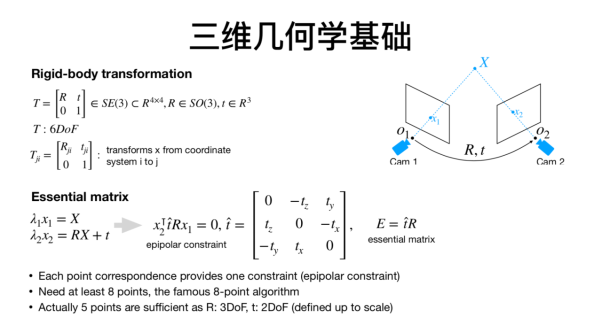
图1:多视觉几何基础
而关于SLAM,它是英文“同时定位与建图”的缩写。而有时候,我们还会听到VO,SfM等概念,而因此容易混淆。对于这些概念,我的理解是,sfm用于基于图像的三维重建,过程可以是在线或者离线,图像的顺序可以是连续的,也可以是乱序的;视觉slam一般处理的图像是连续的,并且过程也是在线的;视觉里程计中有局部地图生成的模式其实就是slam,而没有地图的模式就是单独的里程计。虽然我们接触到的大部分视觉里程计都是有对应的地图,但是,也有些情况,比如现在的一些深度网络可以通过两张图片直接训练输出相对位姿,这就是单独的里程计信息。
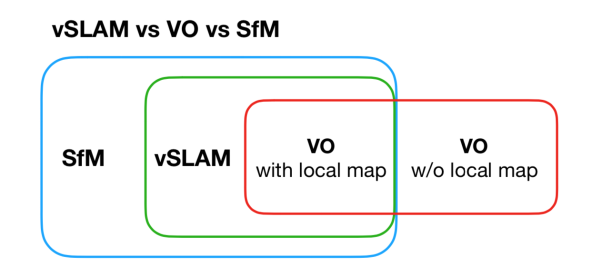
图2:SLAM相关概念的关系图
接下来我们来看看特征点法和直接法直接的对比。关于特征点法,通常我们在两张图片上找到特征点以及对应的匹配特征点,从而求两帧图像之间的相对位姿以及特征点的三维位置。当有一个初始的相对位姿估计时,我们可以计算特征投影到另一帧图像的位置,从而可以建立重投影误差。
相比于使用两张图片,当使用多张图片时,重投影误差则包括所有特征点在所有可被观测到的帧上的误差。而针对直接法,我们所关注的误差称为光度误差。如果说特征点法关注的是像素的位置差,那么,直接法关注的则是像素的颜色差。
总结一下,特征点法通常会把图像抽象成特征点的集合,然后去缩小特征点之间的重投影误差;而直接法则通过warp function直接计算像素点在另一张图像上的颜色差,这样就省去了特征提取的步骤。
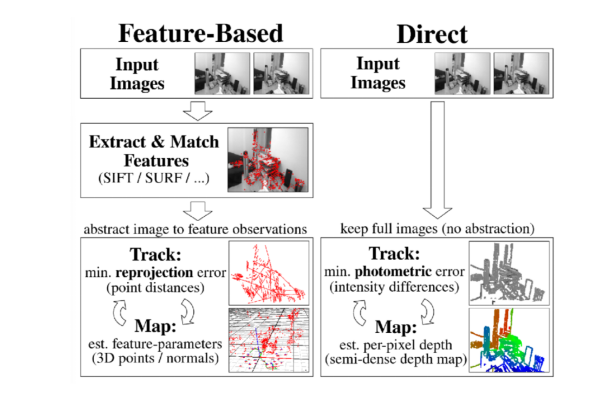
图3:直接法和特征点法流程对比
直接法的应用
关于直接法的应用,主要介绍的是DSO和大范围DSO。首先关于直接图像对齐(direct image alignment),针对每一个图像的每一个点,我们需要计算像素点颜色的变化,对应点的寻找需要利用warp function,就是将一个点通过相机的内外参数转换到另一个相机的坐标系中,更周全的考虑还需要将两张图的亮度进行一致化处理。然而单目相机还是需要面对一个很棘手的问题,那就是无法恢复尺度信息,并且往往会出现尺度漂移的现象。
为了解决这个问题,一种方式是采用双目摄像头,对此我们需要使用新的能量函数,添加的优化量就是双目相机另一个摄像头投影到它上面的误差,值得注意的是,双目摄像头的相对位置需要已知,并且,通过双目项的添加,会自然的得到尺度的约束。
而实际上,随着双目相机和对尺度约束的引入,相比于ORB-SLAM2和深度LSD,大范围DSO在KITTI等室外场景具备了更好的里程计效果,而经过反思,我们认为通过将双目相机用“聪明”的方式加以利用,我们确实可以得到正确的尺度信息。除了支持里程计信息的获取,双目DSO还能很好的支持三维重建。

图4:双目DSO三维重建效果
在实现了比较好的三维重建后,接下来值得继续研究的方向之一就是语义重建。基于视觉SLAM的语义重建的流程包括实现定位和地图后,通过点云信息来进行语义分割,基于分割好的点云,我们将进一步参数化,抽象化。
总之,我们希望实现对于点云比较简洁的参数化描述。
我们接下来的一个工作是试图从输入的图像直接得到想要的语义信息。对应的输入包括双目相机获取的左右图像,初始的位姿和形状估计,以及物体的语义分割结果。而误差的计算则包括两张图片光度投影的误差,和将物体估计的形状投影到图像上的误差,以及关于车的形状和位置的先验知识。利用构建的误差,我们可以通过高斯牛顿法进行优化。
而这里,涉及到的问题包括构建车辆的模型来进行参数化表达,一种方式是利用有效距离场对于形状以高维度向量的形式进行描述,然后采用PCA模型进行降维压缩。而在利用能量函数建立优化问题后,我们需要计算雅可比进行二阶优化,由于待优化的变量较多,所以雅可比推导很复杂,不过在我们的论文 DirectShape: Direct Photometric Alignment of Shape Priors for Visual Vehicle Pose and Shape Estimation中,对于所有优化变量的雅可比的求解都进行了推导,从而提供了优化问题的闭环解,感兴趣的同学可以自行阅读。而实验效果也实现了很好的场景描述效果,包括在物体被部分遮挡的情况下。

图5:语义重建的输入信息
接下来一个主题是关于特征点法和直接法的结合,第一个工作是结合特征点实现的相机的在线光度标定。要理解光度标定,就要理解数码摄像机的成像过程,首先光源发射到物体上的光会反射到镜片上,经过镜头后,光亮会发生变化,然后打到传感器上,一定时间内形成能量积累,经过响应函数的处理从而得到对应的光照强度。
从物体表面反射的光通常称为辐射亮度(radiance),而发射到传感器上的光通常称为辐射照度(irradiance)。这一过程涉及到三个参数,包括是镜头的暗角V,曝光时间E,镜头的响应函数f。
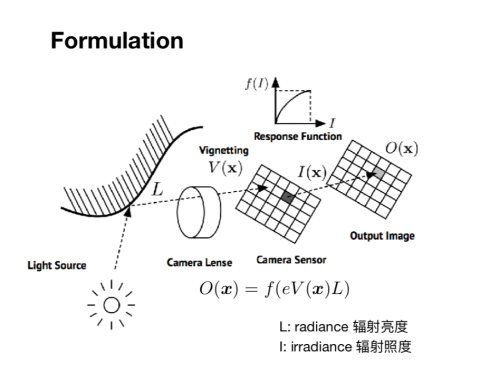
图6:数码相机的成像过程
而相机的光度标定的目标就是求得相机的三个参数,并利用这三个参数对于图像进行矫正,从而确保输出图像的光度一致性。
为什么我们要进行光度标定呢?因为直接法SLAM的假设就是光度的一致性,即对应的点在不同的图像中颜色要一致。已有的方法在进行光度标定时,我们需要至少10分钟的时间完成全部的复杂操作。而当相机安装在无人机上,或者曝光时间无法控制时,操作将更加复杂。我们所提出的在线光度标定的方法是基于特征点在不同图片中对应的观察,能量函数是所有的点在所有图像中的实际颜色与模型估计出的颜色的误差和。在定义了能量函数后,我们需要怎样进行建模呢?
首先对于响应函数的建模还是利用主成分分析,我们收集一百个相机的响应函数进行PCA,任意一个相机的响应函数都可以用四个主成分的线性组合来进行描述。对于暗角的建模是基于暗角是完全对称的假设,并用四阶多项式来描述。在对能量函数进行参数化后,我们就可以进行优化求解。而实际的效果也证明优化参数可以很快收敛成真值。在进行光度标定后,DSO在Euroc等数据集上也实现了更好的定位和建图效果。
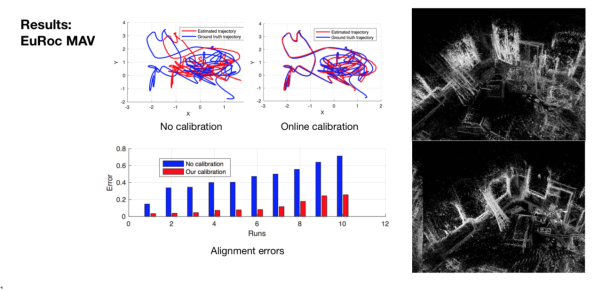
图7:光度标定后的成像效果
最后一个分享的课题是:如何在采用直接法的同时进行回环检测?直接法中因为没有描述子,所以很难利用进行数据关联和回环检测,一种思路就是对部分采样的点添加描述子,在高翔博士的工作LDSO:Direct sparse odmetry with loop closure中,我们把采样的点一部分换成角点,对于角点我们会建立描述子,从而得到整个图像的描述子,然后就可以检测回环,进行全局的位姿图优化。
而实际效果说明,特征的替换并不会影响DSO的效果,并且还增加了新的回环检测的功能。此外,还有一种思路是通过直接法得到的点云进行三维特征点的检测,并且抽取局部特征点的描述子,从而合并成全局特征点的描述子。
未来的工作方向
而关于直接法的局限性,我认为直接法做全局的优化是很有挑战性的,因为没有描述子,做回环检测和地图的重定位不是很直观。而且在极端的光照条件下,它的鲁棒性没有保证,还有一点就是目前的直接法采样点都是随机采样,这就意味着采样没有决定性,这就会为之后的重定位引入误差。
此外,直接法得到的点云如何得到更具备实际意义的表述形式?因为目前得到的点云还是无法直接使用的。直接法需不需要存储历史图像?特征点法只需要保留特征点和描述子,而直接法如果需要全局优化,那么就需要存储图像与历史信息进行对照,而一旦存储图像,就会导致存储数据的增加,那么这个问题该如何解决?
关于直接法未来的研究方向,一个可行的工作是增加点的描述性,如果能将之前不具备描述性的图像的颜色信息,换成具备描述性的描述子信息,那么将可以开展很多新工作。有了这些东西,我们就可以进行跨季节,跨时间,跨天气的回环检测。
此外,直接法获取的点云质量通常较高,但现在依旧没有充分挖掘这些点云信息的潜力,所以未来如果能够提取这些点云的描述子,并且和图像的描述子结合,那么就可以对场景实现更好的描述性,点云还有可能的潜在用途就是提供简洁的场景描述。此外,目前点的采样具有随机性,而未来,是否可以实现具有确定性的点的采样?从而实现更准确的重定位?还有就是直接法的全局地图该如何更新和维护,现在还没有解决。
审核编辑:刘清
-
DSO
+关注
关注
0文章
28浏览量
23363 -
SLAM
+关注
关注
23文章
423浏览量
31822 -
orb
+关注
关注
0文章
21浏览量
9893
原文标题:视觉SLAM直接法及未来发展
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
利用VLM和MLLMs实现SLAM语义增强

激光雷达在SLAM算法中的应用综述
MG-SLAM:融合结构化线特征优化高斯SLAM算法

电动机的△接法和Y接法有什么区别?简单介绍
电机角形接法和星形接法介绍
深度解析深度学习下的语义SLAM

工程实践中VINS与ORB-SLAM的优劣分析

什么是SLAM?SLAM算法涉及的4要素
从基本原理到应用的SLAM技术深度解析





 工商网监
工商网监
评论