 字节跳动基于Iceberg的海量特征存储实践
字节跳动基于Iceberg的海量特征存储实践
01背景
字节跳动特征存储痛点
当前行业内的特征存储整体流程主要分为以下四步:
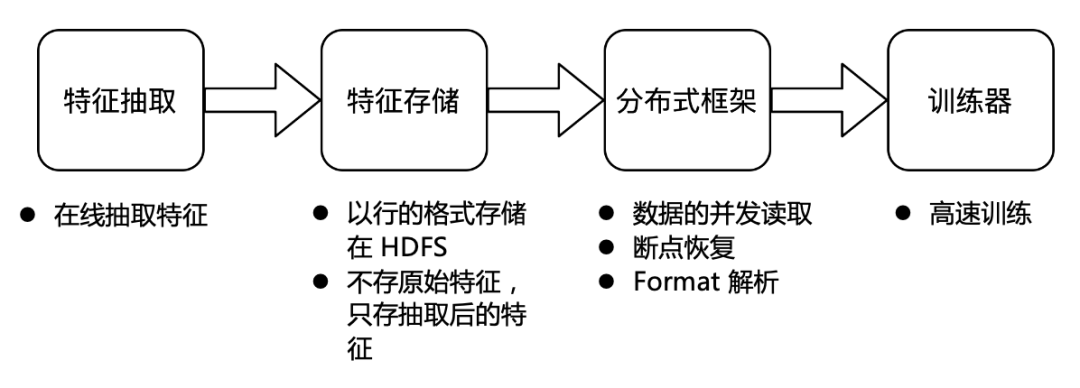
特征存储的整体流程
业务在线进行特征模块抽取;
抽取后的特征以行的格式存储在 HDFS,考虑到成本,此时不存储原始特征,只存抽取后的特征;
字节跳动自研的分布式框架会将存储的特征并发读取并解码发送给训练器;
训练器负责高速训练。
字节跳动特征存储总量为 EB 级别,每天的增量达到 PB 级别,并且每天用于训练的资源也达到了百万核心,所以整体上字节的存储和计算的体量都是非常大的。在如此的体量之下,我们遇到了以下三大痛点:
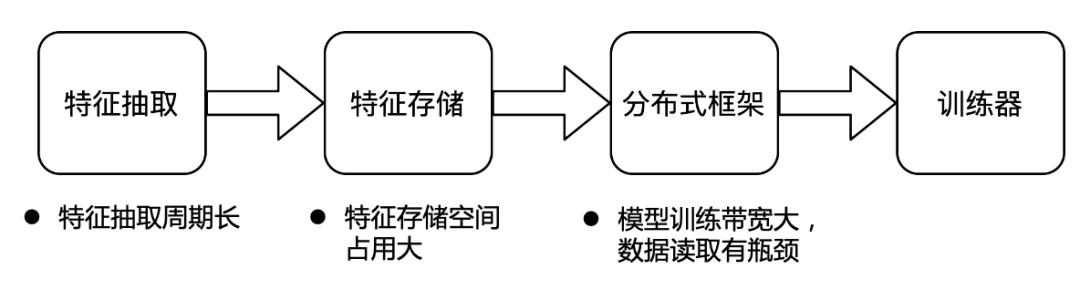
特征抽取周期长。在特征抽取上,当前采用的是在线抽取的方式。大量的算法工程师,每天都在进行大量的特征相关的试验。在当前的在线抽取模式下,如果有算法工程师想要调研一个新的特征,那么他首先需要定义特征的计算方式,等待在线模块的统一上线,然后需要等在线抽取的特征积累到一定的量级后才可以进行训练,从而判断这个特征是否有效果。这个过程通常需要2周甚至更长的时间。并且,如果发现特征的计算逻辑写错或想要更改计算逻辑,则需重复上述过程。在线特征抽取导致当前字节特征调研的效率非常低。基于当前的架构,离线特征调研的成本又非常高。
特征存储空间占用大。字节的特征存储当前是以行存的形式进行存储。如果基于当前的行存做特征调研,则需要基于原来的路径额外生成新的数据集。一方面需要额外的空间对新的数据集进行存储,另一方面还需要额外的计算资源去读取原来的全量数据生成新的数据,且很难做数据的管理和复用。行存对于特征存储来说,也很难进行优化,占用空间较大。
模型训练带宽大,数据读取有瓶颈。字节当前将每个业务线的绝大部分特征都存储在一个路径下,训练的时候会直接基于这个路径进行训练。对于每个模型,训练所需的特征是不一样的,每个业务线可能存有上万个特征,而大部分模型训练往往只需要几百个特征,但因为特征是以行存格式进行存储,所以训练时需要将上万特征全部读取后,再在内存中进行过滤,这就使得模型训练的带宽需求非常大,数据的读取成为了整个训练的瓶颈。
基于痛点的需求梳理
基于上述问题,我们与业务方一同总结了若干需求:
存储原始特征:由于在线特征抽取在特征调研上的低效率,我们期望能够存储原始特征;
离线调研能力:在原始特征的基础上,可以进行离线调研,从而提升特征调研效率;
支持特征回填:支持特征回填,在调研完成后,可以将历史数据全部刷上调研好的特征;
降低存储成本:充分利用数据分布的特殊性,降低存储成本,腾出资源来存储原始特征;
降低训练成本:训练时只读需要的特征,而非全量特征,降低训练成本;
提升训练速度:训练时尽量降低数据的拷贝和序列化反序列化开销。
02字节跳动海量特征存储解决方案
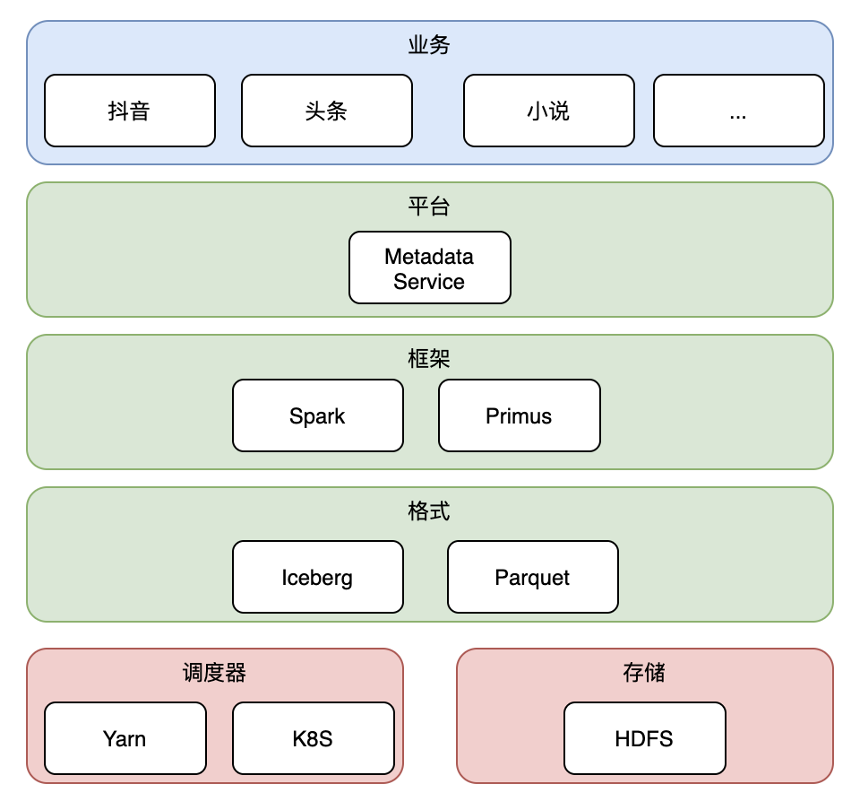
在字节的整体架构中,最上层是业务层,包括抖音、头条、小说等字节绝大部分业务线;
其下我们通过平台层,给业务同学提供简单易用的 UI 和访问控制等功能;
在框架层,我们使用 Spark 作为特征处理框架(包括预处理和离线特征调研等),字节自研的 Primus 作为训练框架;
在格式层,我们选用 Parquet 作为文件格式,Iceberg 作为表格式;
最下层是调度器 Yarn & K8s 以及存储 HDFS。
下面我们重点针对格式层进行详细介绍。
技术选型

为了满足业务方提到的6个需求,我们首先想到的是通过 Parquet 列存的格式,降低行存的存储成本,节省的空间可用来存储原始特征。同时由于 Parquet 选列可以下推到存储层的特性,在训练时可以只读需要的特征,从而降低训练时反序列化的成本,提升训练的速度。
但是使用 Parquet 引入了额外的问题,原来的行存是基于 Protobuf 定义的半结构化数据,不需要预先定义 Schema,而使用 Parquet 以后,我们需要先知道 Schema,然后才能进行数据的存取,那么在特征新增和淘汰时,Schema 的更新就是一个很难解决的问题。Parquet 并不支持数据回填,如果要回填历史几年的数据,就需要将数据全量读取,增加新列,再全量写回,这一方面会浪费大量的计算资源,另一方面做特征回填时的 overwrite 操作,会导致当前正在进行训练的任务由于文件被替换而失败。
为了解决这几个问题,我们引入了 Iceberg 来支持模式演进、特征回填和并发读写。
Iceberg 是适用于大型数据集的一个开源表格式,具备模式演进、隐藏分区&分区演进、事务、MVCC、计算存储引擎解耦等特性,这些特性匹配了我们所有的需求。因此,我们选择了 Iceberg 作为我们的数据湖。
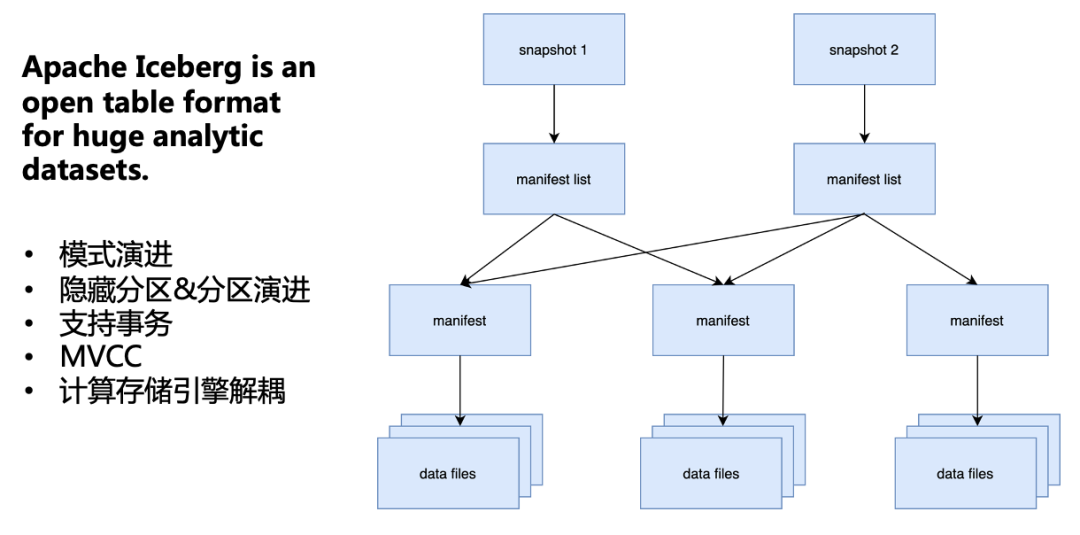
整体上 Iceberg 是一个分层的结构,snapshot 层存储了当前表的所有快照;manifest list 层存储了每个快照包含的 manifest 云数据,这一层的用途主要是为了多个 snapshot 可以复用下一层的 manifest;manifest 层,存储了下层 Data Files 元数据;最下面的 Data File 是就是实际的数据文件。通过这样的多层结构,Iceberg 可以支持上述包括模式演进等几个特性。
下面我们来一一介绍 Iceberg 如何支持这些功能。
字节跳动海量特征存储解决方案
并发读写
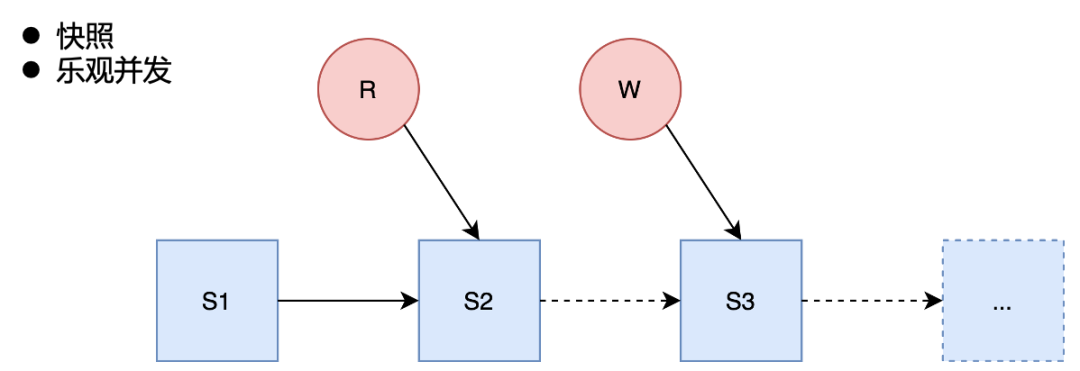
在并发读取方面,Iceberg 是基于快照的读取,对 Iceberg 的每个操作都会生成新的快照,不影响正在读取的快照,从而保证读写互不影响。
在并发写入方面,Iceberg 是采用乐观并发的方式,利用HDFS mv 的原子性语义保证只有一个能写入成功,而其他的并发写入会被检查是否有冲突,若没有冲突,则写入下一个 snapshot。
模式演进
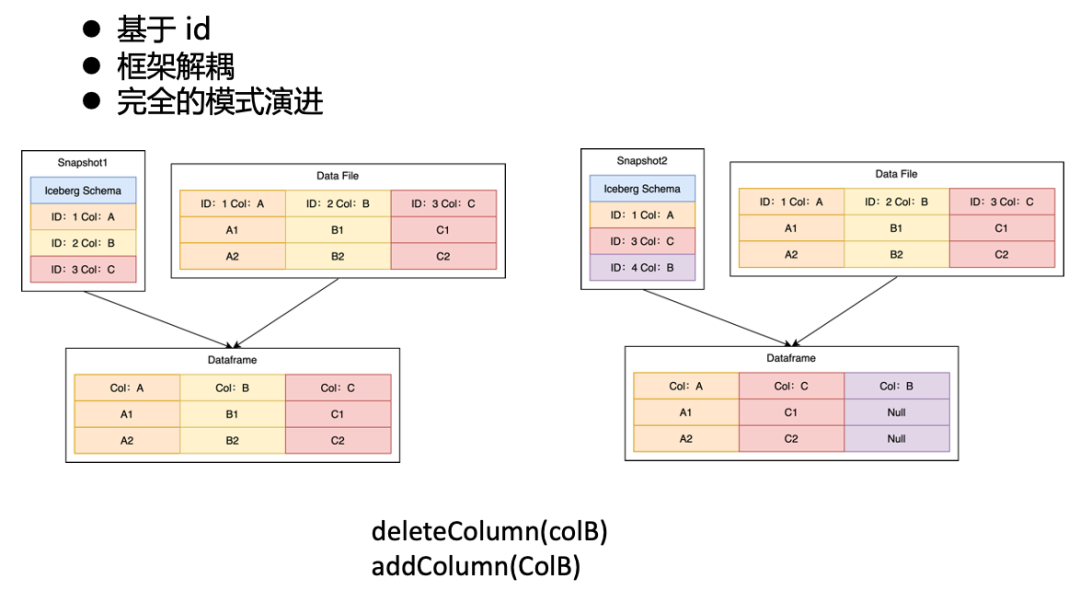
Iceberg 的模式演进原理
我们知道,Iceberg 元数据和 Parquet 元数据都有 Column,而中间的映射关系,是通过 ID 字段来进行一对一映射。
例如上面左图中,Iceberg 和 Parquet 分别有 ABC 三列,对应 ID 1、2、3。那最终读取出的 Dataframe 就是 和 Parquet 中一致包含 ID 为1、2、3的 ABC 三列。而当我们对左图进行两个操作,删除旧的 B 列,写入新的 B 列后, Iceberg 对应的三列 ID 会变成1、3、4,所以右图中读出来的 Dataframe,虽然也是 ABC 三列,但是这个 B 列的 ID 并非 Parquet 中 B 列的 ID,因此最终实际的数据中,B 列为空值。
特征回填
写时复制
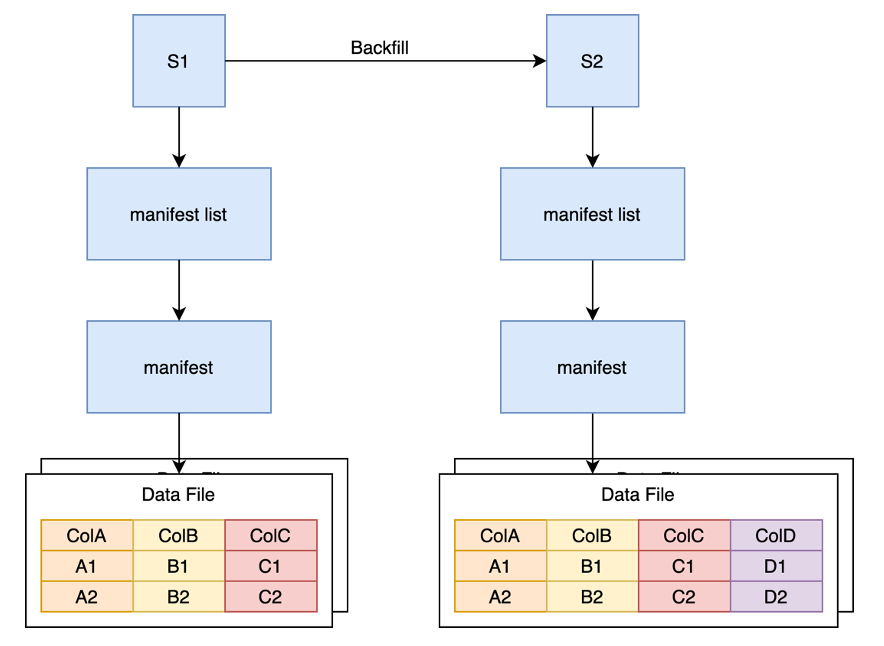
如上图所示,COW 方式的特征回填通过一个 Backfill 任务将原快照中的数据全部读出,然后写入新列,再写出到新的 Data File 中,并生成新的快照。
这种方式的缺点在于虽然我们只需要写一列数据,但是需要将整体数据全部读出,再全部写回,不仅浪费了大量的计算资源用来对整个 Parquet 文件进行编码解码,还浪费了大量的 IO 来读取全量数据,且浪费了大量的存储资源来存储重复的 ABC 列。
因此我们基于开源 Iceberg 自研了 MOR 的 Backfill 方案。
读时合并
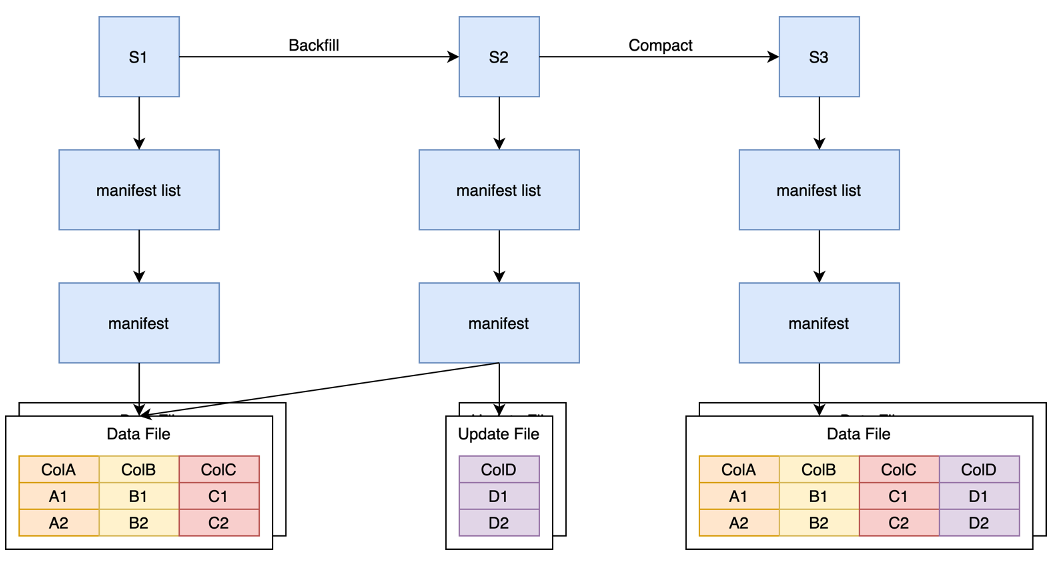
如上图所示,在 MOR 方案中,我们仍然需要一个 Backfill 任务来读取原始的 Data File 文件,但是这里我们只读取需要的字段。比如我们只需要 A 列通过某些计算逻辑生成 D 列,那么 Backfill 任务则只读取 A 的数据,并且 Snapshot2 中只需要写包含 D 列的 update 文件。随着新增列的增多,我们也需要将 Update 文件合并回 Data File 文件中。
为此,我们又提供了 Compaction 逻辑,即读取旧的 Data File 和 Update File,并合并成一个单独的 Data File。
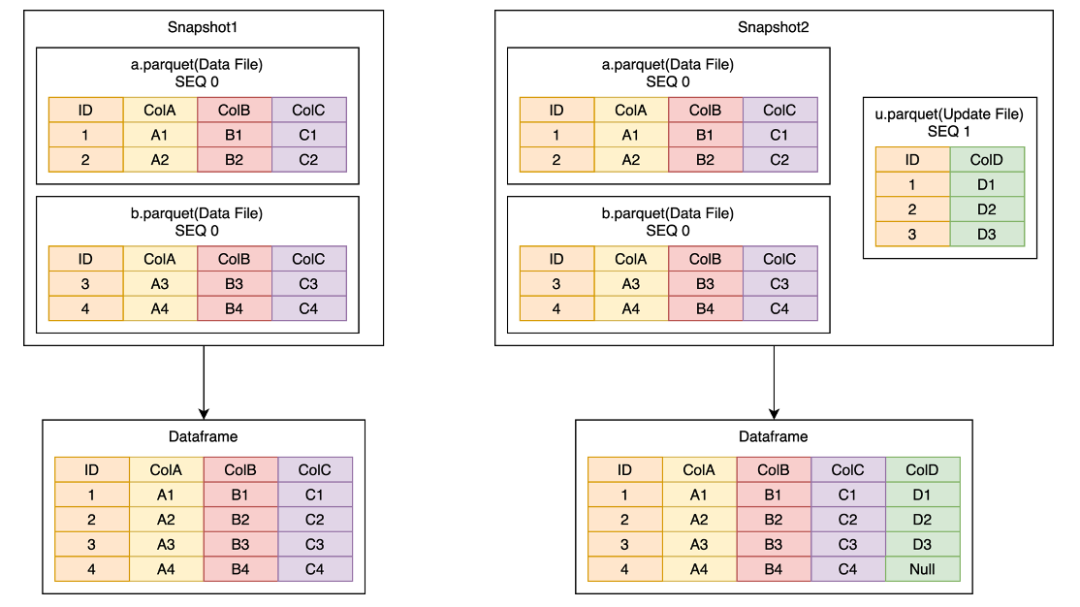
MOR原理如上图,假设原来有一个逻辑 Dataframe 是由两个 Data File 构成, 现在需要回填一个 ColD 的内容。我们会写入一个包含 ColD 的 Update File,这样 Snapshot2 中的逻辑 Dataframe 就会包含ABCD 四列。
实现细节:
Data File 和 Update File 都需要一个主键,并且每个文件都需要按照主键排序,在这个例子中是 ID;
读取时,会根据用户选择的列,分析具体需要哪些 Update File 和 Data File;
根据 Data File 中主键的 min-max 值去选择与该 Data File 相对应的 Update File;
MOR 整个过程是多个 Data File 和 Update File 多路归并的过程;
归并的顺序由 SEQ 来决定,SEQ 大的数据会覆盖 SEQ 小的数据。
COW 与 MOR 特性比较
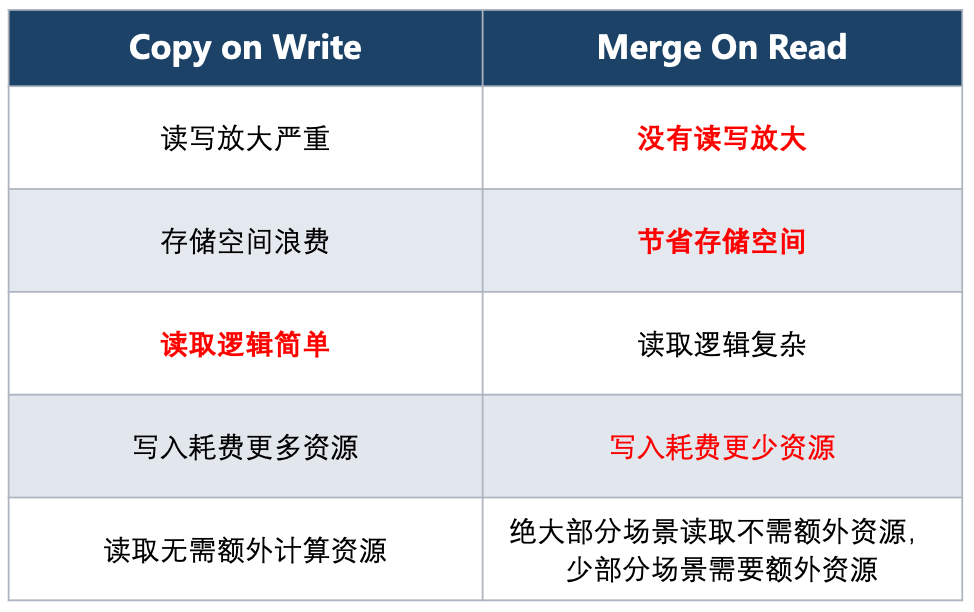
相比于 COW 方式全量读取和写入所有列,MOR 的优势是只读取需要的列,也只写入更新的列,没有读写放大问题。在计算上节省了大量的资源,读写的 IO 也大大降低,相比 COW 方式每次 COW 都翻倍的情况, MOR 只需要存储新增列,也大大避免了存储资源浪费。
考虑到性能的开销,我们需要定期 Compaction,Compaction 是一个比较重的操作,和 COW 相当。但是 Compaction 是一个异步的过程,可以在多次 MOR 后进行一次 Compaction。那么一次 Compaction 的开销就可以摊销到多次 MOR 上,例如10次 COW 和10次 MOR + 1次 Compaction 相比,存储和读写成本都从原来的 10x 降到当前的 2x 。
MOR 的实现成本较高,但这可以通过良好的设计和大量的测试来解决。
而对于模型训练来说,由于大多数模型训练只需要自己的列,所以大量的线上模型都不需要走 MOR 的逻辑,可以说基本没有开销。而少数的调研模型,往往只需读自己的 Update File 而不用读其他的 Update File ,所以整体上读取的额外资源也并未增加太多。
训练优化
从行存改为 Iceberg 后,我们也在训练上也做了大量的优化。
在我们的原始架构中,分布式训练框架并不解析实际的数据内容,而是直接以行的形式把数据透传给训练器,训练器在内部进行反序列化、选列等操作。
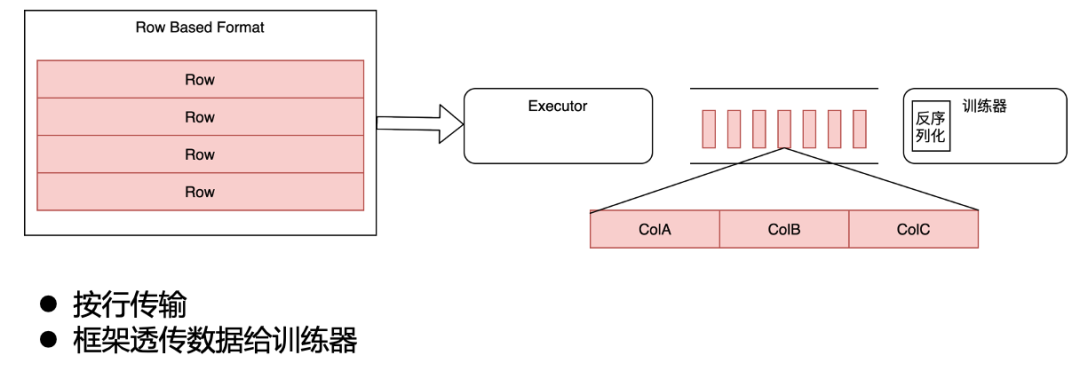
原始架构
引入 Iceberg 后,我们要拿到选列带来的 CPU 和 IO 收益就需要将选列下推到存储层。最初为了保证下游训练器感知不到,我们在训练框架层面,将选列反序列化后,构造成原来的 ROW 格式,发送给下游训练器。相比原来,多了一层序列化反序列化的开销。
这就导致迁移到 Iceberg 后,整体训练速度反而变慢,资源也增加了。
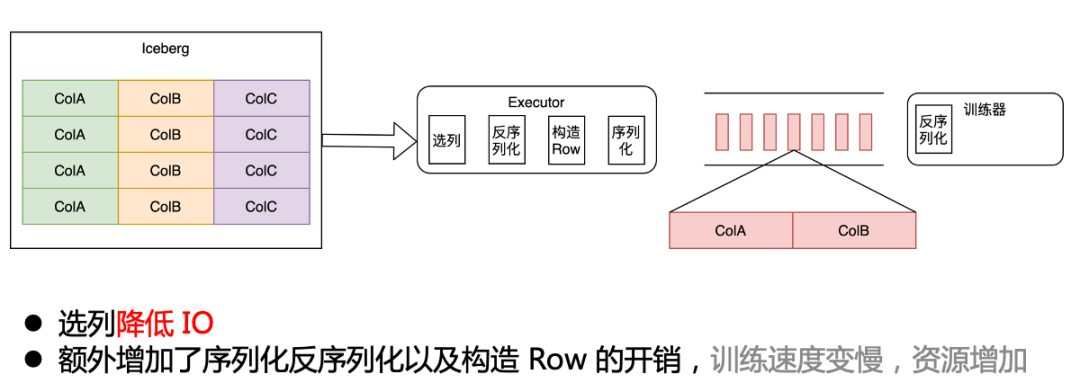
列式改造为了提升训练速度,我们通过向量化读取的方式,将 Iceberg 数据直接读成 Batch 数据,发送给训练器,这一步提升了训练速度,并降低了部分资源消耗。
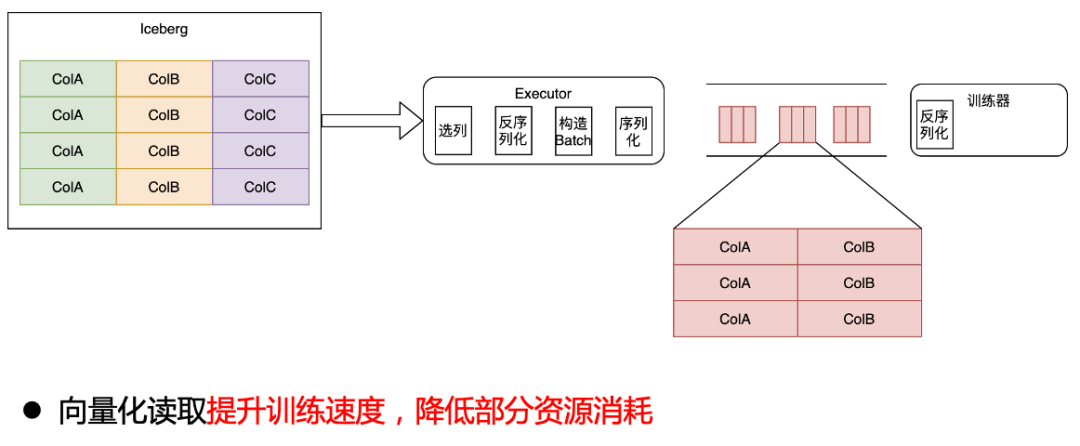
向量化读取
为了达到最优效果,我们与训练器团队合作,直接修改了训练器内部,使训练器可以直接识别 Arrow 数据,这样我们就实现了从 Iceberg 到训练器端到端的 Arrow 格式打通,这样只需要在最开始反序列化为 Arrow ,后续的操作就完全基于 Arrow 进行,从而降低了序列化和反序列化开销,进一步提升训练速度,降低资源消耗。
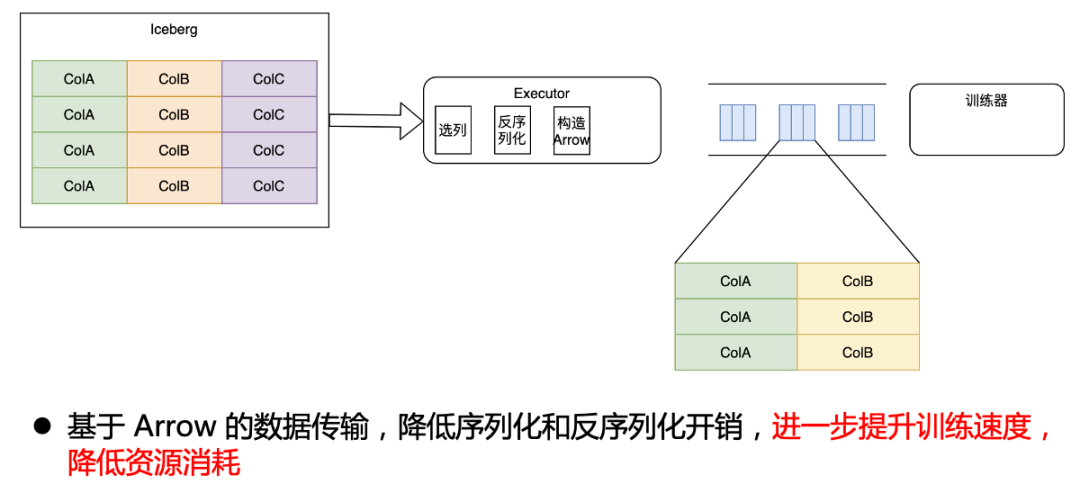
Arrow
优化收益
最终,我们达到了最初的目标,取得了离线特征工程的能力。在存储成本上,普遍降低了40%以上;在同样的训练速度下,CPU 降低了13%,网络IO 降低40%。
03未来规划
未来,我们规划支持以下4种能力:
Upsert 的能力,支持用户的部分数据回流;
物化视图的能力,支持用户在常用的数据集上建立物化视图,提高读取效率;
Data Skipping 能力,进一步优化数据排布,下推更多逻辑,进一步优化 IO 和计算资源;
基于 Arrow 的数据预处理能力,向用户提供良好的数据处理接口,同时将预处理提前预期,进一步加速后续的训练。
审核编辑:汤梓红
-
存储
+关注
关注
13文章
4396浏览量
86393 -
训练器
+关注
关注
0文章
4浏览量
6430 -
字节跳动
+关注
关注
0文章
342浏览量
9099
原文标题:字节跳动基于Iceberg的海量特征存储实践
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
字节跳动全面屏电子设备专利曝光 有望应用于字节跳动旗下坚果手机





 工商网监
工商网监
评论