 图解B+树的生成过程!
图解B+树的生成过程!
本文大概字数三千多,预计观看时长十分钟,练习时长两个半小时。希望大家都能学到知识。
前提
不少网友看 B+ 树,看不懂树结构什么意思。希望本文可以帮你理解树结构生成的过程。
在说 B+ 树之前,需要知道,一页的大小是多少。
showglobalstatuslike'innodb_page_size'
 MySQL一页16kb
MySQL一页16kb
这个是看出,一页是 16384 也就是16384/1024 = 16kbinnodb 中一页的大小默认是 16kb。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
正文
创建表结构 指定引擎为 Innodb。
CREATETABLEtree(
idintPRIMARYkeyauto_increment,
t_nameVARCHAR(20),
t_codeint
)ENGINE=INNODB
查看一下当前表的索引情况
showindexfromtree
B 树和 B+ 树的显示都是 BTREE,但是实际使用的 B+ 树。B+ 树也是 B 树的升级版,这里显示为 B 树也是没有问题的。
 BTREE
BTREE创建数据,这里会有一个小知识点,如果看过上一篇文章的朋友可以明白是为什么。
INSERTintotreeVALUES(3,"变成派大星",3);
INSERTintotreeVALUES(1,"变成派大星",1);
INSERTintotreeVALUES(2,"变成派大星",2);
INSERTintotreeVALUES(4,"变成派大星",4);
INSERTintotreeVALUES(7,"变成派大星",7);
INSERTintotreeVALUES(5,"变成派大星",5);
INSERTintotreeVALUES(6,"变成派大星",6);
INSERTintotreeVALUES(8,"变成派大星",8);
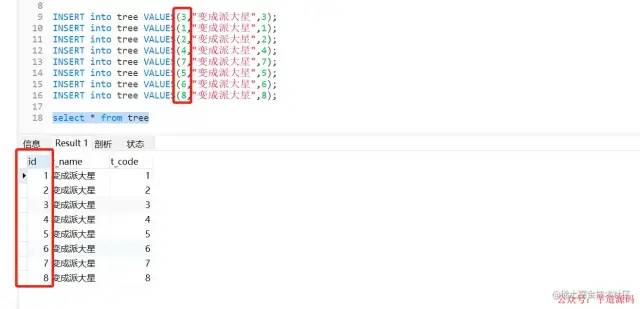 插入测试数据
插入测试数据疑问
为什么创建数据的时候数据是乱序的,但是在创建好数据,被排好顺序了。
基础知识
我们在寻找答案之前,想明白一些基础知识。
细心的朋友可以看出来,我们插入 Id 时候数据是乱的,插入进去之后,数据就自动帮我通过 Id 进行排序了,这是为什么呢?接着往下看。
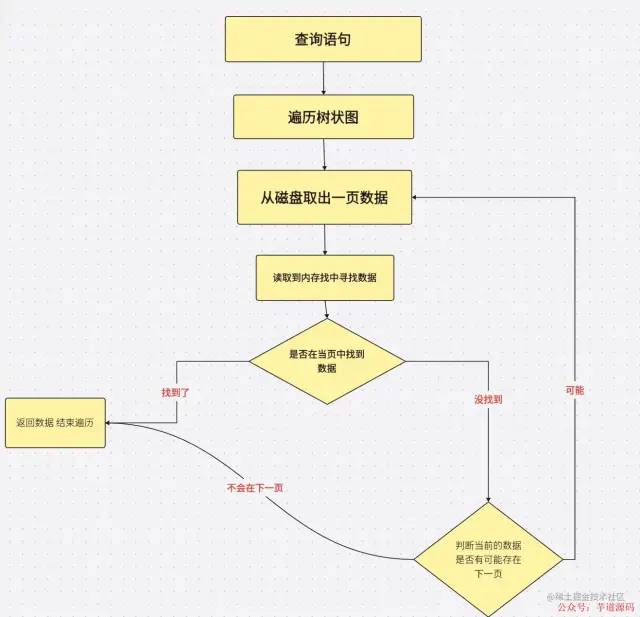
我们如果对于 B+ 树有点了解的话就知道 B+ 树是每页 16KB 进行数据储存。在进行数据查询的时候也是一页一页的去查询。
相当于下面的数据。
首先每一页都有很多数据,就像我们平常去写分页的时候我们返回给前端的数据也会有很多属性。
 MySQL数据页
MySQL数据页这个可能比较抽象,我是把他当成平常,分页查询的思想代入进去。
我们可以把一页想成是一个对象。
@Data
publicclasspage{
Listdata;
//....省略其余属性
}
我们先看一下,一页数据的图是什么样子,仅仅是进行逻辑思考画的图。
这里的 Data,就相当于 一页中的数据区域。
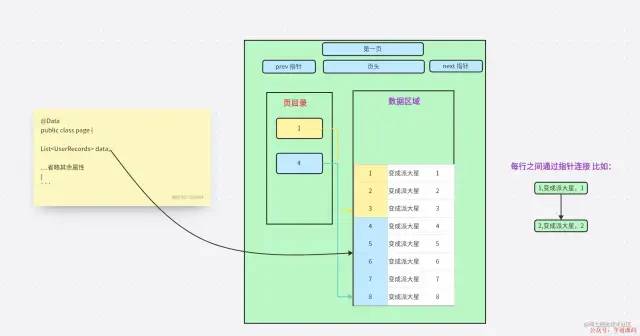 数据区域
数据区域但是这里是有限制的,上面我们说到,一页的数据只能是 16Kb,也就是一个 Page 里面的 data 只能16Kb。当数据超过 16Kb,就会新开一个对象相当于在进行创建树的时候增加了判断。
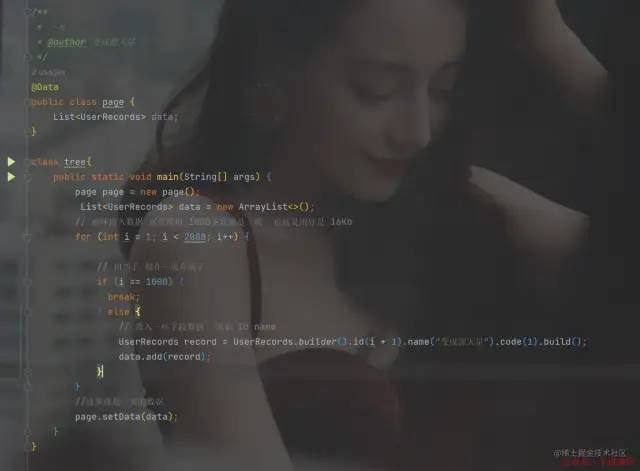 Java模拟MySQL数据页
Java模拟MySQL数据页当 Page 对象的大小已经达到16Kb 就算完成这一页。把这一页放到,磁盘中等待使用就行了,到时候进行查询数据的时候会直接返回这一页,里面包含这些数据。
我们回到最初的问题 为什么我们在进行插入的时候明明 Id 是乱的?等到插入到数据的时候,数据就变成有序的了?我们知道,同时这个数据是根据主键进行排序的,InnoDB 的数据储存一定是要依赖主键的,有些人会想,我就是不创建主键,他还能排序吗?
疑问二
我们在疑问一的基础上,产生出的疑问,不设置主键 Mysql 怎么办?
解答
InnoDB 对聚簇索引处理如下:
- 如果定义了主键,那么 InnoDB 会使用主键作为聚簇索引
- 如果没有定义主键,那么会使用第一非空的唯一索引(NOT NULL and UNIQUE INDEX)作为聚簇索引
- 如果既没有主键也找不到合适的非空索引,InnoDB 会自动帮你创建一个不可见的、长度为 6 字节的 row_id,而且 InnoDB 维护了一个全局的 dictsys.row_id,所以未定义主键的表都共享该row_id,每次插入一条数据,都把全局 row_id 当成主键 id,然后全局 row_id 加 1
很明显,缺少主键的表,InnoDB 会内置一列用于聚簇索引来组织数据。而没有建立主键的话就没法通过主键来进行索引,查询的时候都是全表扫描,小数据量没问题,大数据量就会出现性能问题。
但是,问题真的只是查询影响吗?不是的,对于生成的 ROW_ID,其自增的实现来源于一个全局的序列,而所以有 ROW_ID 的表共享该序列,这也意味着插入的时候生成需要共享一个序列,那么高并发插入的时候为了保持唯一性就避免不了锁的竞争,进而影响性能
解答
我们看完疑问二的解答就知道,即便我们不设置主键。数据也会帮我们去生成一个默认的主键,有点像,类默认生成构造器的思想。
有了主键之后呢?
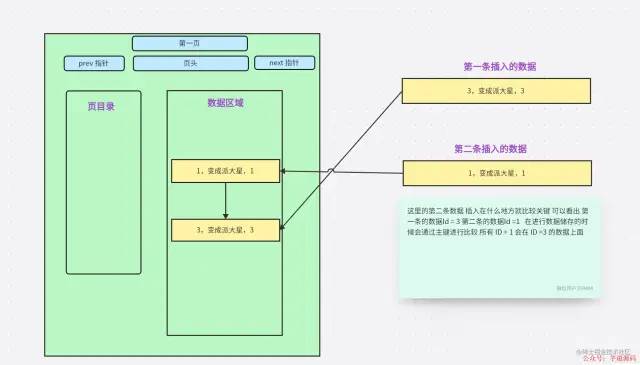 表中有主键
表中有主键为什么会自动排序,大家都知道了。其实在文章之初就会有很多人明白是为什么,大概脑子里会有答案。
疑问三
为什么要进行排序?
解答
我们都知道,在进行数据查找的时候,比如几个基础的查找算法的,前提都是,先进行排序。再者 List 和 Map 的一些区别肯定都很熟悉了。排序当然是为了更快,所以无须的 Id 会对插入效率造成影响,也就是为什么很多文章说使用自增 Id 比 UUID 或者雪花算效率高的原因。第一个是 UUID 他们是随机的 每次都要重新排序,甚至可能会因为排序的原因造成页数据的更换。还有就是 UUID 一般都比较长,一页是 16Kb 数据越短。一页的数据就会越多,查询的速度也就比较快。
这里说完为什么排序 还有一个点就是上面的「页目录」
疑问三
页目录的作用是什么?
页目录的作用是减少范围。
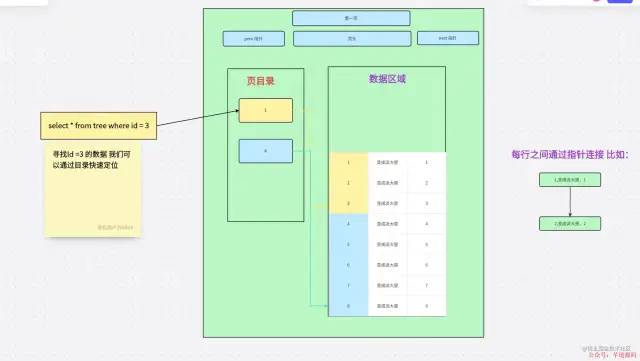
 页目录
页目录这里的第三层是数据,上面都是目录,可以增加数据的检索效率。
 页目录增加数据的检索效率
页目录增加数据的检索效率如果没有目录我们需要去直接遍历数据区域,会降低效率。目录能帮我们缩小范围,这里,我们查询 ID = 3。我们可以通过目录知道 1 < 3 < 4,如果在 1 中没有找到对应数据。但是因为 3 < 4 就不会接着往下查询了,直接返回空结果。
当第一页没有的时候去第二页查询,不会直接跳到第二页查询。
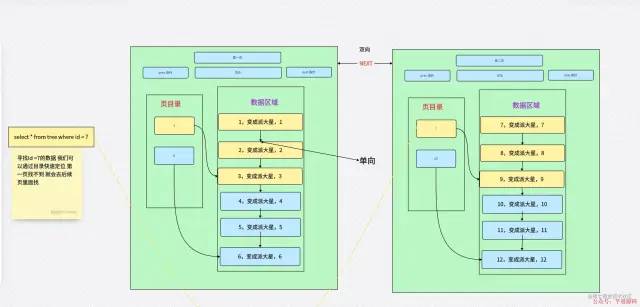 提高范围查找效率
提高范围查找效率为了提高效率,当目录数据数量过多时,就会网上延伸一层树,同时可以减少磁盘的 IO 次数。
 索引就是一颗树
索引就是一颗树关于所有叶子节点都处于同一深度是如何实现的?这与 B+ 树具体的插入和删除算法有关。简单解释一下插入时的情况,根据插入值的大小,逐步向下直到对应的叶子节点。如果叶子节点关键字个数小于 2t,则直接插入值或者更新卫星数据;如果插入之前叶子节点已经满了,则分裂该叶子节点成两半,并把中间值提上到父节点的关键字中,如果这导致父节点满了的话,则把该父节点分裂,如此递归向上。所以树高是一层层的增加的,叶子节点永远都在同一深度。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
小总结
- 内部节点并不存储真正的信息,而是保存其叶子节点的最小值作为索引。
- 每次插入删除都进行更新(此时用到parent指针),保持最新状态。
- B+ 树非叶子节点上是不存储数据的,仅存储键值
- B+ 树只在叶子节点上储存“数据”,上层就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的 IO 次数又会再次减少,数据查询的效率也会更快。
- B+ 树的阶数是等于键值的数量的,如果我们的 B+ 树一个节点可以存储 1000 个键值,那么 3 层 B+ 树可以存储 1000×1000×1000=10 亿个数据。
- 一般根节点是常驻内存的,所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。
- 因为 B+ 树索引的所有“数据”均存储在叶子节点,而且数据是按照顺序排列的。
- 那么 B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单
- 有心的读者可能还发现上图 B+ 树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。
- 其实上面的 B 树我们也可以对各个节点加上链表。这些不是它们之前的区别,是因为在 MySQL 的 InnoDB 存储引擎中,索引就是这样存储的。
- 我们通过数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。
结尾
感觉写的有点啰嗦了 但是还是有点加深印象的 后续会接着整理一下相关的资料 补充进来
-
如果你是直接跳到这里,看看文章有多长
建议收藏 -
如果你一步步看到这里,感觉有点帮助
赞赞来一个 -
如果感觉文章有问题,建议评论区指出
会修正
审核编辑 :李倩
-
数据
+关注
关注
8文章
7014浏览量
88982 -
MySQL
+关注
关注
1文章
808浏览量
26551
原文标题:图解B+树的生成过程!
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
飞凌嵌入式ElfBoard ELF 1板卡-内核移植之编译后生成文件说明
飞凌嵌入式ElfBoard ELF 1板卡-内核移植之编译后生成文件说明
人工智能大模型公司卓世科技完成亿元B+轮融资
壹沓科技完成B+轮融资,加速大供应链超自动化进程
地芯科技完成近亿元B+轮融,加速高端模拟射频芯片发展
如何使用CubeMX生成的设备树编译镜像?
北一半导体完成B+轮融资,用于SiC MOSFET技术研发
AI医学影像企业深智透医完成B+轮近千万美元融资
北一半导体完成B+轮1.5亿元融资,加快SiC MOSFET技术研发






 工商网监
工商网监
评论