 50亿海量数据如何高效存储和分析? 华为云数据库GaussDB (for Cassandra) 3个秘诀搞定
50亿海量数据如何高效存储和分析? 华为云数据库GaussDB (for Cassandra) 3个秘诀搞定
50亿海量数据如何高效存储和分析?
华为云数据库GaussDB (for Cassandra) 3个秘诀搞定
当下,信息社会正在从互联网时代走向物联网时代,信息交互变得更加庞杂、高效和智能。对于互联网公司和IOT企业来说,既是机遇,也是挑战。因为,企业不可避免的要面对数据量剧增带来的一系列问题:如何高效存储和扩容,如何在对原有业务改动最小的情况下做到智能化和实时分析。
针对挑战,华为云GaussDB (for Cassandra)为客户提供了强扩展、高存储、高效导入/导出和实时分析等一系列能力,并成功服务了众多互联网公司和IOT企业,获得了客户的高度认可和支持。本文将以其中一个客户业务的痛点问题举例,聊聊高效存储和实时分析的3个秘诀。
海量存储,PB级无感扩展
该用户在线下本地化部署使用数据库或者使用其他的存储为云盘的数据库时,常常需要在容量达到阈值时,提前规划和申购存储资源,可能还需要连带扩容不必要的计算资源。而使用GaussDB (for Cassandra)之后,便再无此烦恼。GaussDB (for Cassandra)采用存算分离架构,可单独扩展存储,高效扩容,业务无感,最高可扩展到PB级。
此外,客户为了做大数据分析,将数据库中的数据再写入一份到HDFS中,供MapReduce和Spark分析,同时需要维护两套资源,维护和资源成本成为了痛点。而客户使用GaussDB (for Cassandra)之后,可以仅采用GaussDB (for Cassandra)即可完成数据库存储和对接大数据分析的功能,同时GaussDB (for Cassandra)提供了更为易用的CQL接口,让用户更加专注功能开发,而不是资源管理。
数据变更捕获和实时分析
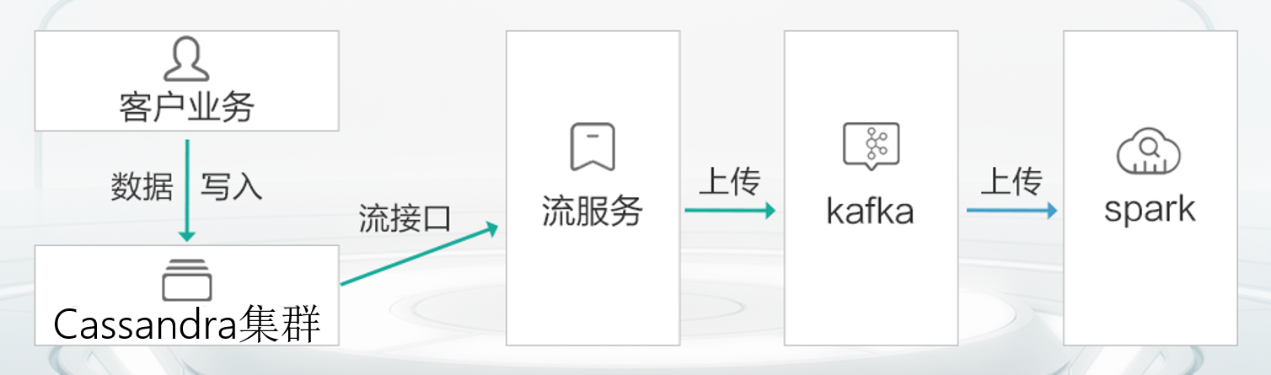
客户的一个使用场景需要将爬虫或用户输入的数据,进行在线分析和实时推荐业务,该业务中全量数据达到了50亿条,但增量数据不足5亿,分析对象主要是每日新增数据。在这个场景中,GaussDB (for Cassandra)为客户提供了streaming服务+实时分析解决方案,在损失小部分读写性能的前提下,客户端无需改造即可做到数据读写和实时分析并行,解决方案如下图,该解决方案主要有以下几个阶段:
1.客户业务用过开源驱动写入数据到GaussDB (for Cassandra)
2.GaussDB (for Cassandra)对外提供streaming接口,该接口可获取数据变更捕获
3.客户构建的流服务组件读取streaming接口数据写入到指定的Kafka队列
4.Kafka队列将streaming数据写入到Spark或者Flink中
5.客户在Spark中可对增量数据做分析,也可合并之后做全量分析
全量数据导出分析
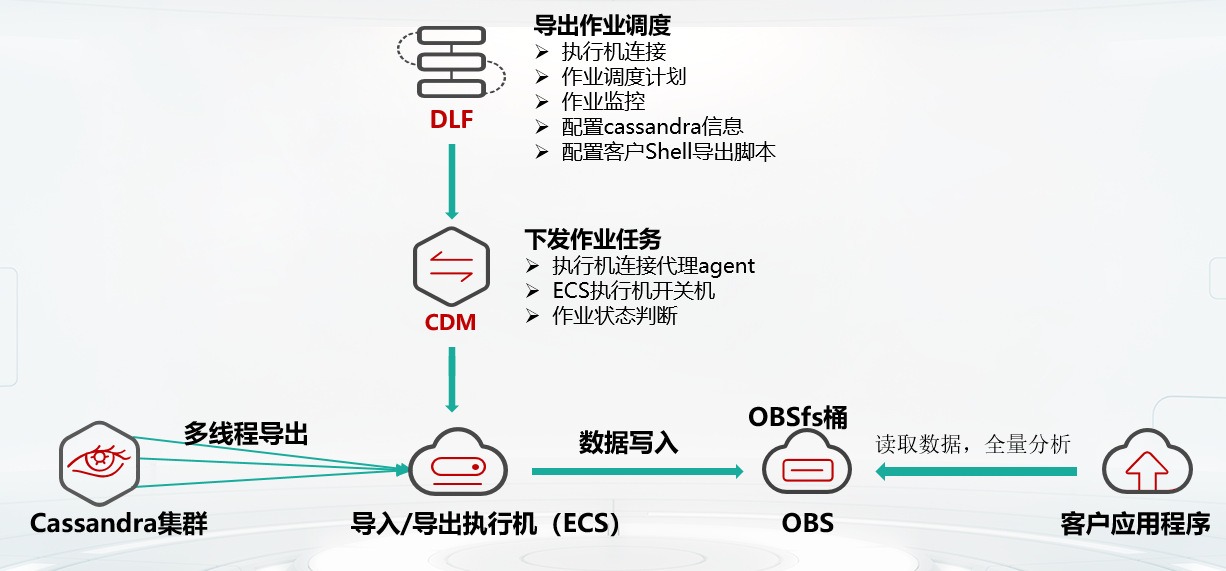
客户的另一个业务需要周期性对全量数据进行分析和处理,但不想影响在线业务,希望在闲时处理。GaussDB (for Cassandra)提供了全量数据导出和分析解决方案,可在业务低峰期触发任务进行数据导出和冷数据分析,数据导出速率是开源的10+倍,同时做到对业务读写基本无影响。如下为互联网客户每周定期导出数据分析用户画像的解决方案,该方案有以下几个阶段:
1.客户根据需求配置ECS规格,并挂载obsfs并行文件系统
2.客户在DLF上配置导出作业,包括ECS信息,导出参数和定时任务
3.CDM下发作业任务
4.ECS上的导出任务将GaussDB (for Cassandra)中的指定表指定条件的数据导出到obsfs
5.Spark从obsfs中读取全量数据进行数据分析
通过这3个秘诀,华为云GaussDB (for Cassandra)完美解决了难扩展、高成本、变更不及时等问题,实现了海量数据的高效存储和实时分析,为互联网公司和IOT企业的数字化发展提供了更多可能。
审核编辑黄昊宇
-
华为云
+关注
关注
3文章
2491浏览量
17426
发布评论请先 登录
相关推荐
使用华为云 X 实例部署图数据库 Virtuoso 并存储 6500 万条大数据的完整过程与性能测评
数据库数据恢复—通过拼接数据库碎片恢复SQLserver数据库

恒讯科技分析:云数据库rds和redis区别是什么如何选择?
恒讯科技分析:sql数据库怎么用?
数据库数据恢复—raid5阵列上层Sql Server数据库数据恢复案例

华为云GaussDB数据库基础版发布:旗舰性能、价格下降超60%
华为云多模数据库 GeminiDB 架构与应用实践直播问答实录
华为云原生多模数据库 GeminiDB 架构与应用实践

选择 KV 数据库最重要的是什么?
2024年,国产数据库正酝酿新变局!





 工商网监
工商网监
评论