 华为自研分布式时序数据库集群:初始GaussDB(for Influx)
华为自研分布式时序数据库集群:初始GaussDB(for Influx)
前言
随着云计算规模越来越大,以及物联网应用逐渐普及,在物联网(AIoT)以及运维监控(AIOps)领域,存在海量的时序数据需要存储管理。以华为云监控服务(Cloud Eye Service,CES)为例,单个Region需要监控7000多万监控指标,每秒需要处理90万个上报的监控指标项,假设每个指标50个字节,一年的数据将达到PB级。另以地震监测系统为例,数万监测站点24小时不间断采集数据,平均每天要处理的指标数据达到TB级,一年的数据同样达到PB级,并且数据需要永久存储。传统的关系型数据库很难支撑这么大的数据量和写入压力,Hadoop等大数据解决方案以及现有的开源时序数据库也面临非常大的挑战。对时序数据实时交互、存储和分析的需求,将推动时序数据库在架构、性能和数据压缩等方面不断进行创新和优化。
GaussDB(for Influx)时序数据库依靠华为在数据存储领域多年的实践经验,整合华为云的计算、存储、服务保障和安全等方面的能力,大胆在架构、性能和数据压缩等方面进行了技术创新,达到了较好的效果,对内支撑了华为云基础设施服务,对外以服务的形式开放,帮助上云企业解决相关业务问题。
云原生存储与计算分离架构

GaussDB(for Influx)接口完全兼容InfluxDB,写入接口兼容OpenTSDB、Prometheus和Graphite。从架构上看,一个时序数据库集群可以分为三大组件。它们分别是:
Shard节点:节点采用无状态设计,主要负责数据的写入和查询。在节点内,除了分片和时间线管理之外,还支持数据预聚合、数据降采样和TAG分组查询等专为时序场景而优化的功能。
Config集群:存储和管理集群元数据,采用三节点的复制集模式,保证元数据的高可靠性。
分布式存储系统:集中存储持久化的数据和日志,数据采用三副本方式存放,对上层应用透明。存储系统为华为自研,经过多年产品实践检验,系统的高可用和高可靠性都得到了验证。
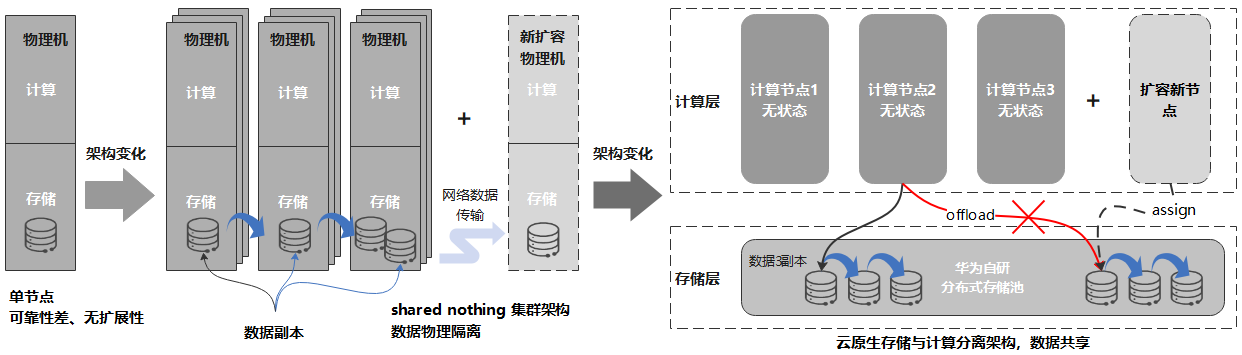
相比InfluxDB等开源时序数据库,采用存储与计算分离的云原生数据库设计具备以下优势:
容忍N-1节点故障,更高可用。存储与计算分离,可以复用成熟的分布式存储系统,提供系统的极致可靠性。时序数据通常会持续高性能写入,同时还有大量的查询业务,任何系统故障导致业务中断甚至数据丢失都会造成严重的业务影响,而利用经过验证的成熟的分布式存储系统,能够显著的提升系统可靠性,降低数据丢失风险。
分钟级计算节点扩容,秒级存储扩容。解除在传统Shared Nothing架构下,数据和节点物理绑定的约束,数据只是逻辑上归宿于某个节点,使的计算节点无状态化。这样在扩容计算节点时,可以避免在计算节点间迁移大量数据,只需要逻辑上将部分数据从一个节点移交给另一个节点即可,可以将集群扩容的耗时从以天为单位缩短为分钟级别。
消除多副本冗余,降低存储成本。通过将多副本复制从计算节点卸载到分布式存储节点,可以避免用户以Cloud Hosting形态在云上自建数据库时,分布式数据库和分布式存储分别做3副本复制导致总共9副本的冗余问题,能够显著降低存储成本。
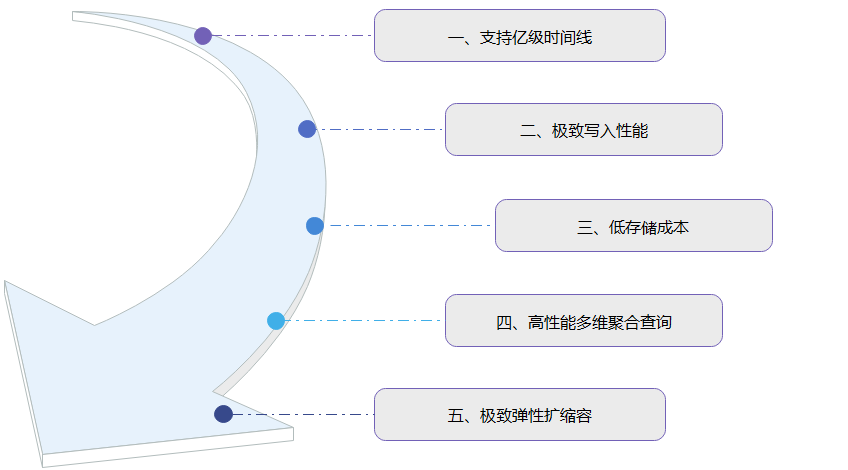
GaussDB(for Influx)采用云原生存储与计算分离架构,具有支持亿级时间线、极致写入性能、低存储成本、高性能多维聚合查询和极致弹性扩缩容等5大特性。
支持亿级时间线
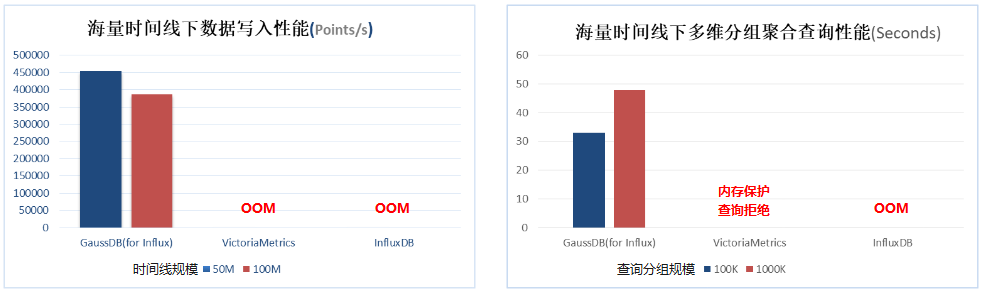
在时序数据库系统中,存在大量并发查询和写入操作,合理控制内存的使用量显得十分重要。开源时序数据库VictoriaMetrics和InfluxDB在写入数据的时间线增加到千万级别时,进程会因内存耗尽而OOM退出。为了避免写入海量时间线数据导致内存资源被耗尽,GaussDB(for Influx)做了如下优化:
●在内存分配上,大量使用内存池复用技术,减少临时对象内存申请,降低内存碎片;
●在内存回收上,实现算法根据内存负载,动态调整GC频率,加快内存空间回收;
●在单查询上,实行Quota控制,避免单查询耗尽内存;
●在缓存使用上,针对不同节点规格提供不同的最优配置。
经过改进,在海量时间线下,系统写入性能保持稳定,大幅超出InfluxDB开源实现。对于涉及海量时间线的聚合查询,如高散列聚合查询,查询性能提升更为显著。
极致写入性能:支持每天万亿条数据写入

相比单机模式,集群模式可以将写入负载分散到集群中各个计算节点上,从而支持更大规模的数据写入。GaussDB(for Influx)支持每天万亿条数据写入,在工程实现上进行了以下优化:
首先,时序数据按照时间线做Hash Partition,利用所有节点并行写入,充分发挥集群优势。
其次,Shard节点采用针对写场景优化的LSM-Tree布局,写WAL后确保日志持久化,再写入内存Buffer即可返回。
最后,数据库多副本复制卸载到分布式存储,降低计算节点到存储节点的网络流量。
在大规模写入场景下,GaussDB(for influx)的写入性能线性扩展度大于80%。
低存储成本:只需1/20的存储成本
在时序数据库面对的AIOps运维监控和AIoT物联网两个典型应用场景中,每天会产生数GB甚至数TB的时序数据。如果无法对这些时序数据进行很好的管理和压缩,那将会给企业带来非常高的成本压力。
GaussDB(for Influx)对数据采用列式存储,相同类型的数据被集中存储,更有利于数据压缩。采用自研的时序数据自适应压缩算法,在压缩前对数据进行抽样分析,根据数据量、数据分布以及数据类型选择最合适的数据压缩算法。在压缩算法上,相比原生的InfluxDB,重点针对Float、String、Timestamp这三种数据类型进行了优化和改进。
Float数据类型:对Gorilla压缩算法进行了优化,将可以无损转换的数值转为整数,再根据数据特点,选择最合适的数据压缩算法。
String数据类型:采用了压缩效率更好的ZSTD压缩算法,并根据待压缩数据的Length使用不同Level的编码方法。
Timestamp数据类型:采用差量压缩方法,最后还针对数据文件内的Timestamp进行相似性压缩,进一步降低时序数据存储成本。
下图是分别采用实际业务场景的事件日志数据(数据集1)和云服务器监控指标数据 (数据集2)与InfluxDB进行了数据压缩效率的性能对比。

节约存储成本并非只有数据压缩一种办法。针对时序数据越旧的数据被访问的概率越低的特点,GaussDB(for Influx)提供了时序数据的分级存储,支持用户自定义冷热数据,实现数据的冷热分离。热数据相对数据量小,访问频繁,被存储在性能更好、成本较高的存储介质上;冷数据相对数据量大,访问概率低,保存时间较久,被存储在成本较低的存储介质上,进而达到节约存储成本的目的。根据实际业务数据测算,相同数据量下存储成本仅有关系型数据库的1/20。
高性能多维聚合查询
多维聚合是时序数据库中较为常见,且会定期重复执行的一种查询,例如AIOps运维监控场景中查询CPU、内存在指定时间范围内的平均值。
|
SELECTmean(usage_cpu), mean(usage_mem) FROMcpu_info WHEREtime >= '2020-11-01T06:05:27Z' and time < '2020-11-01T18:05:27Z' GROUPBYtime(1h), hostname |
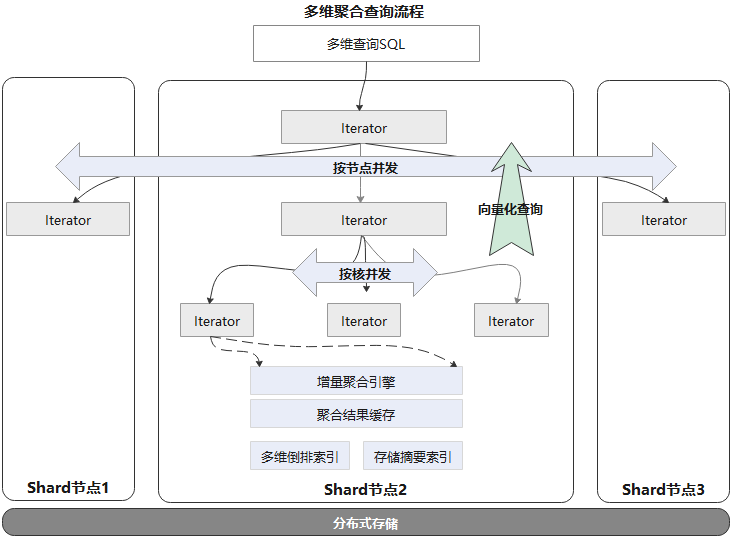
在提升聚合查询整体性能方面,GaussDB(for Influx) 做了如下优化:
●采用MPP架构:一条查询语句可以在多节点及多核并发执行。
●向量化查询引擎:在查询结果数据量很大时,传统的火山模型每次迭代返回一条数据,存在过多的开销导致性能瓶颈。GaussDB(for Influx)内部实现了向量化查询引擎,每次迭代批量返回数据,大大减少了额外开销。
●增量聚合引擎:基于滑动窗口的聚合查询,大部分从聚合结果缓存中直接命中,仅需要聚合增量数据部分即可。
●多维倒排索引:支持多维多条件组合查询,避免大量Scan数据。
●存储摘要索引,加快数据查询中过滤无关数据。
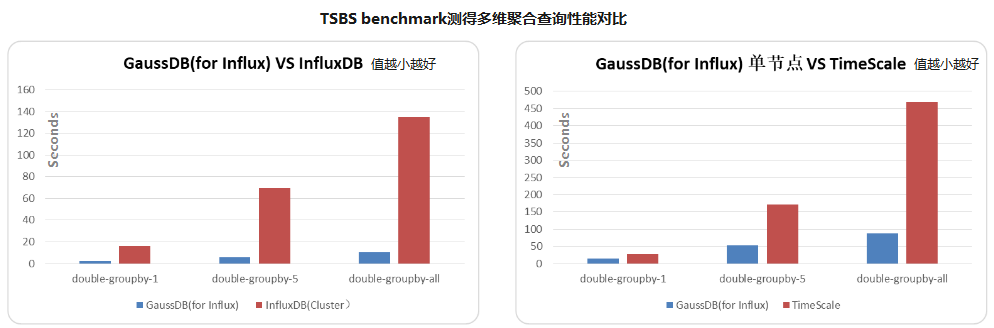
相同节点规格,GaussDB(for Influx)的聚合查询性能是InfluxDB Enterprise的10倍,是Timescale的2到5倍。
分钟级弹性扩缩容
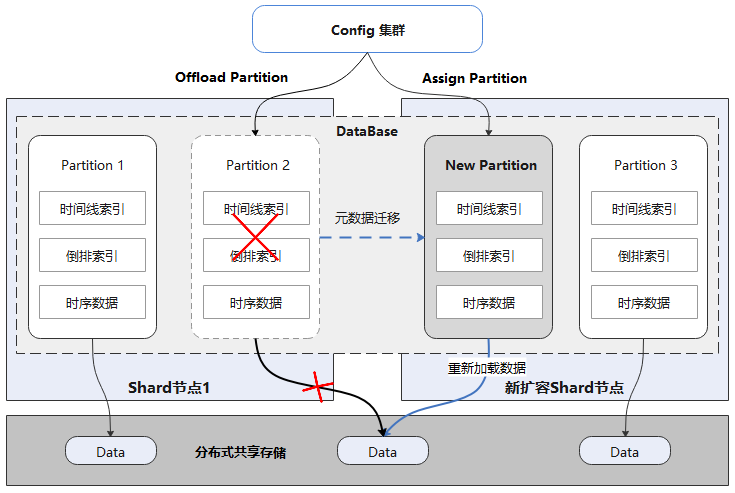
在时序数据库的运行过程中,随着业务量的增加,常常需要对数据库进行在线扩容,以满足业务的要求。传统数据库中的数据存储在本地,扩容后往往需要迁移数据。当数据量达到一定规模时,数据迁移所耗费的时间往往按天计算,给运维带来了很大的困难。
如上图所示,每个Database逻辑上由多个Partition组成,每个Partition独立存储,且都可自描述。所有Partition数据都存储在分布式共享存储上,数据库Shard节点和数据没有物理绑定关系。扩容时首先offload源节点Partition,再在目标节点assign即可。
总结
时序数据应该存储在专门为时序数据进行优化的时序数据库系统中。华为云某业务从Cassandra切换到GaussDB(for Influx)后,计算节点从总共39个(热集群18个,冷集群9个,大数据分析集群 12个)降低到了9个节点,缩减4倍计算节点。存储空间消耗从每天1TB降低到100GB以内,缩减10倍存储空间消耗。
GaussDB(for Influx)提供了独特的数据存储管理解决方案,云原生的存储与计算架构,可根据业务变化快速扩容缩容;高效的数据压缩能力和数据冷热分离设计,可大幅降低数据存储成本;高吞吐的集群,可满足大规模运维监控和物联网场景海量数据写入和查询性能要求。
审核编辑:汤梓红
-
华为
+关注
关注
216文章
34818浏览量
254150 -
云计算
+关注
关注
39文章
7949浏览量
138639 -
数据库
+关注
关注
7文章
3869浏览量
65212
发布评论请先 登录
相关推荐
时序数据库TDengine 2024年保持高增长,实现收入翻倍

HarmonyOS Next 应用元服务开发-分布式数据对象迁移数据权限与基础数据
PingCAP推出TiDB开源分布式数据库

分布式云化数据库的优缺点分析
集中式与分布式一体化架构,达梦给企业更好的选择
自研创新 数智未来 2024中国数据库技术大会盛大召开

鸿蒙开发接口数据管理:【@ohos.data.distributedData (分布式数据管理)】

时序数据库是什么?时序数据库的特点

鸿蒙HarmonyOS开发实例:【分布式关系型数据库】





 工商网监
工商网监
评论