 浅析MAK基于开放世界取样提升不平衡对比学习
浅析MAK基于开放世界取样提升不平衡对比学习
3. 引言
众所周知,对比学习现在已经成功地在无监督任务中成功应用,通过学习到泛化能力较强的visual representations。然而,如果要使用大量未标记数据进行预训练训练却显得有些奢侈。由于是进行无监督的对比学习,需要很长的时间收敛,所以对比学习比传统的全监督学习需要更大的模型和更长时间的训练。随着数据量的增加,它也需要更多的计算资源。而计算资源有限的条件下,wild unbalanced distribution的数据很可能会抑制对相关特征的学习。
采样的外部未标注数据通常呈现隐式长尾分布(因为真实世界的场景中,数据就呈现长尾分布,从真实世界中收集数据显然也会服从长尾分布),加入学习的样本很可能跟原始任务没任何关联,这些噪声就会比较大程度地影响表征的学习和收敛。本文就旨在设计一种算法来解决上述情景带来的问题。
论文的问题设定还是比较特别的,首先具体介绍一下:假设我们从一个相对较小的(“种子”)未标记的训练数据集开始,其中数据分布可能高度biased,但未指定相应的分布。我们的目标是在给定的采样样本限制下,从一些外源数据检索额外信息,以增强针对目标分布(种子集)的自监督representation learning。
通过对检索到的unlabeled samples进行训练,本文的目标是学习“stronger and fairer”的representation。
我们可能从一个bias的sample set开始训练,由于不知道相应的标注,传统用来处理不平衡数据集的方法,如伪标签、重采样或重加权不适用。
采用预训练的backbone训练不平衡的seed data。
在缺乏label信息的情况下,探索open world中广泛存在的irrelevant outlier samples检测。
因此,我们的目标是寻求一个有原则的开放世界无标签数据采样策略。论文的出发点非常好概括,就是保证三个采样的原则其核心:
tailness:保证采样的样本频率尽可能是原任务中的长尾数据,保证采样规则尽可能服从原有的分布;
proximity:保证采样的样本尽可能是原任务是相关的,过滤掉分布之外的样本,解决OOD问题。
diversity:让采样的数据类型更加丰富,体现一定的差异性,这样能比较好的提升泛化性和鲁棒性。
3. 方法
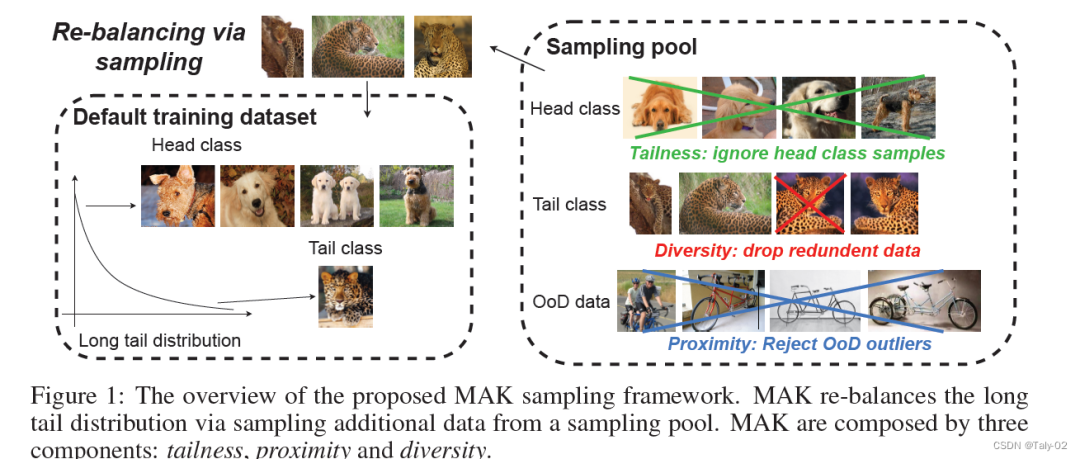
如上图,论文的方法其实很清晰,是分多阶段的。首先定义一个原始的训练集,以图中情景为例,在原始数据中,狗属于Head class,豹属于Tail class,所以在采样时不考虑狗的样本,保证tailness;接着排除掉跟原始数据高度相似的样本,保证diversity;最后删掉跟识别中出现的unrelated的样本,使得采样具有proximity。
3.1 Tailness
初步:在对比学习中,通过强制一个样本v与另一个正样本相似而与负样本不同来学习representation。在各种流行的对比学习框架中,SimCLR是最简单容易实现,也可以产生较好的表现。它利用相同数据的两个增强的image作为正对,而同一批中的所有其他增强样本被视为负样本。SimCLR的形式是:
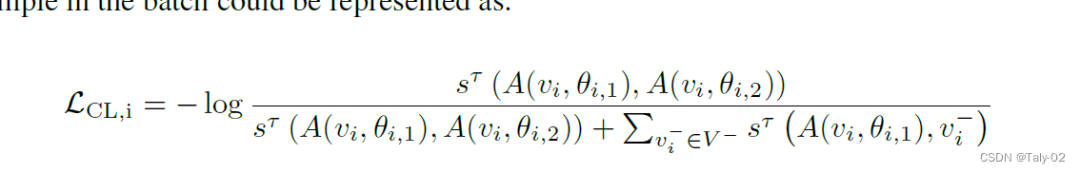
下面来分析下上述的loss function。其实作者主要的目的就是完成对tail classes的特殊处理。而怎么完成呢?其实作者就定义在对比学习框架下hard examples(难样本)可以视为tail的样本。虽然没有更多理论上的支撑,但某种程度上来讲,也是很好理解的,因为在不平衡的数据集上,尾部类别更难分类,所以说有更高的误分率。而对于hard samples,论文直接把contrastive loss最大的样本作为hard sample。
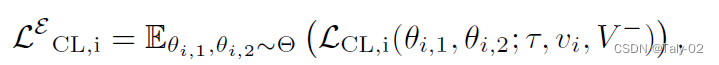
但由于对比损失受数据增强方式的影响,而通常增强方式都是采用随机性,造成噪声过大。因此作者引入了empirical contrastive loss expectation,也就是基于期望来计算SimCLR,从而来来判断hard samples。
3.2 Proximity
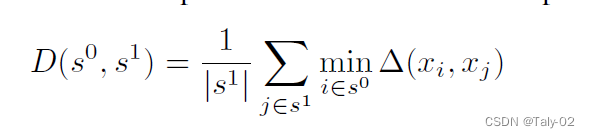
很直观,这个loss就在拉近原始数据集和外部采样数据集特征之间的期望,期望越小,表示未标注的open set和原任务越相关。
3.3 Diversity
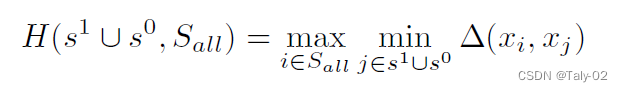
为了追求采样的多样性,利用上述策略避免采样的样本跟原始样本过于相似。
最后的loss如下所示:
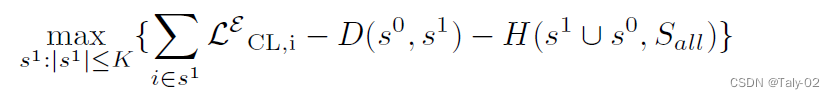
算法概括如下:

4. 实验
实验采用ImageNet-LT作为数据集:
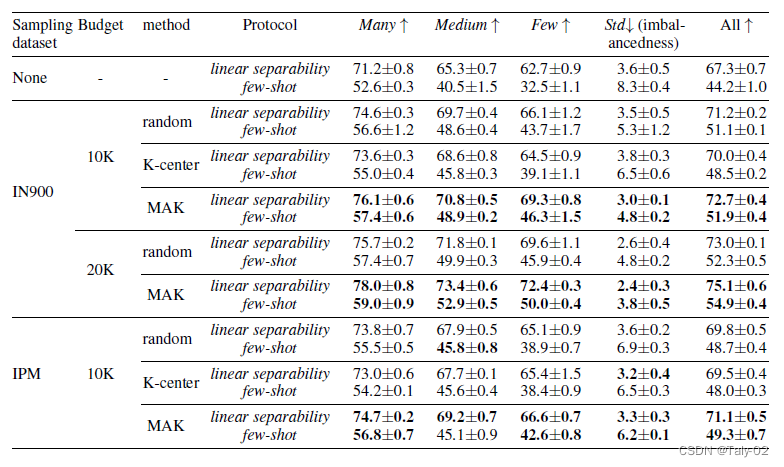
可以大发现,在原始数据集上通过对外部数据集采样进行提升,可以有效地改进模型处理open world中长尾效应的性能。
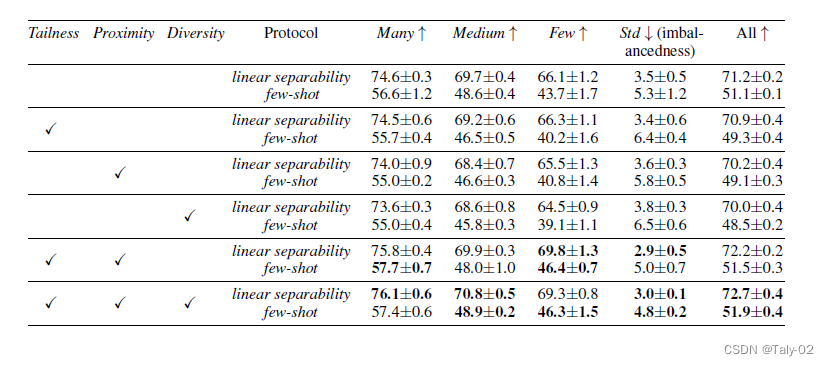
笑容实验来看,其实Tailness和Proximity比较重要,而多样性这种约束提升有限。个人觉得主要的原因还是,实际上还是在利用有限的close set来辅助训练,模型本身的diversity也没有很丰富,所以加入这个优化目标作用有限。
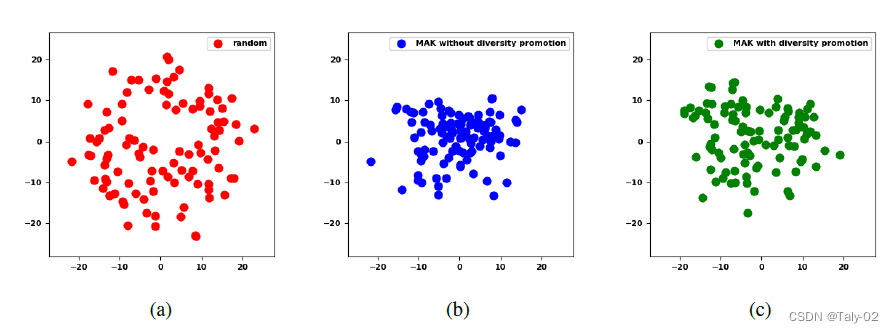
利用t_SNE可视化的效果如上图所示。
5. 结论
开放世界的样本数据往往呈现长尾分布,进一步破坏了对比学习的平衡性。论文通过提出一个统一的采样框架MAK来解决这个重要的问题。它通过抽样额外的数据显著地提高了对比学习的平衡性和准确性。论文提出的方法有助于在实际应用中提高长尾数据的平衡性。
审核编辑:刘清
-
Mak
+关注
关注
0文章
2浏览量
7174
原文标题:MAK 基于开放世界取样提升不平衡对比学习
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何理解矢量测量中“平衡”与“不平衡





 工商网监
工商网监
评论