 如何用Java几分钟处理完30亿个数据?
如何用Java几分钟处理完30亿个数据?
1. 场景说明
现有一个 10G 文件的数据,里面包含了 18-70 之间的整数,分别表示 18-70 岁的人群数量统计。假设年龄范围分布均匀,分别表示系统中所有用户的年龄数,找出重复次数最多的那个数,现有一台内存为 4G、2 核 CPU 的电脑,请写一个算法实现。
23,31,42,19,60,30,36,........
2. 模拟数据
Java 中一个整数占 4 个字节,模拟 10G 为 30 亿左右个数据, 采用追加模式写入 10G 数据到硬盘里。
每 100 万个记录写一行,大概 4M 一行,10G 大概 2500 行数据。
package bigdata;
import java.io.*;
import java.util.Random;
/**
* @Desc:
* @Author: bingbing
* @Date: 2022/5/4 0004 19:05
*/
public class GenerateData {
private static Random random = new Random();
public static int generateRandomData(int start, int end) {
return random.nextInt(end - start + 1) + start;
}
/**
* 产生10G的 1-1000的数据在D盘
*/
public void generateData() throws IOException {
File file = new File("D:\ User.dat");
if (!file.exists()) {
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
int start = 18;
int end = 70;
long startTime = System.currentTimeMillis();
BufferedWriter bos = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file, true)));
for (long i = 1; i < Integer.MAX_VALUE * 1.7; i++) {
String data = generateRandomData(start, end) + ",";
bos.write(data);
// 每100万条记录成一行,100万条数据大概4M
if (i % 1000000 == 0) {
bos.write("
");
}
}
System.out.println("写入完成! 共花费时间:" + (System.currentTimeMillis() - startTime) / 1000 + " s");
bos.close();
}
public static void main(String[] args) {
GenerateData generateData = new GenerateData();
try {
generateData.generateData();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上述代码调整参数执行 2 次,凑 10G 数据在 D 盘 User.dat 文件里:
准备好 10G 数据后,接着写如何处理这些数据。
3. 场景分析
10G 的数据比当前拥有的运行内存大的多,不能全量加载到内存中读取。如果采用全量加载,那么内存会直接爆掉,只能按行读取。Java 中的 bufferedReader 的 readLine() 按行读取文件里的内容。
4. 读取数据
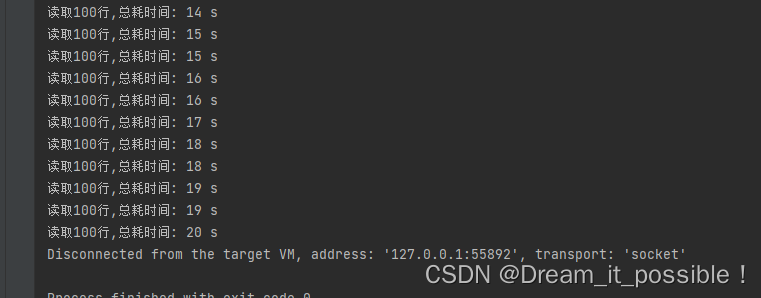
首先,我们写一个方法单线程读完这 30 亿数据需要多少时间,每读 100 行打印一次:
privatestaticvoidreadData()throwsIOException{
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE_NAME), "utf-8"));
String line;
long start = System.currentTimeMillis();
int count = 1;
while ((line = br.readLine()) != null) {
//按行读取
if (count % 100 == 0) {
System.out.println("读取100行,总耗时间: " + (System.currentTimeMillis() - start) / 1000 + " s");
System.gc();
}
count++;
}
running = false;
br.close();
}
按行读完 10G 的数据大概 20 秒,基本每 100 行,1 亿多数据花 1 秒,速度还挺快。
5. 处理数据
5.1 思路一
通过单线程处理,初始化一个 countMap,key 为年龄,value 为出现的次数。将每行读取到的数据按照 "," 进行分割,然后获取到的每一项进行保存到 countMap 里。如果存在,那么值 key 的 value+1。
for (int i = start; i <= end; i++) {
try {
File subFile = new File(dir + "" + i + ".dat");
if (!file.exists()) {
subFile.createNewFile();
}
countMap.computeIfAbsent(i + "", integer -> new AtomicInteger(0));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
单线程读取并统计 countMap:
publicstatic void splitLine(String lineData) {
String[] arr = lineData.split(",");
for (String str : arr) {
if (StringUtils.isEmpty(str)) {
continue;
}
countMap.computeIfAbsent(str, s -> new AtomicInteger(0)).getAndIncrement();
}
}
通过比较找出年龄数最多的年龄并打印出来:
private static void findMostAge() {
Integer targetValue = 0;
String targetKey = null;
Iterator> entrySetIterator = countMap.entrySet().iterator();
while (entrySetIterator.hasNext()) {
Map.Entry entry = entrySetIterator.next();
Integer value = entry.getValue().get();
String key = entry.getKey();
if (value > targetValue) {
targetValue = value;
targetKey = key;
}
}
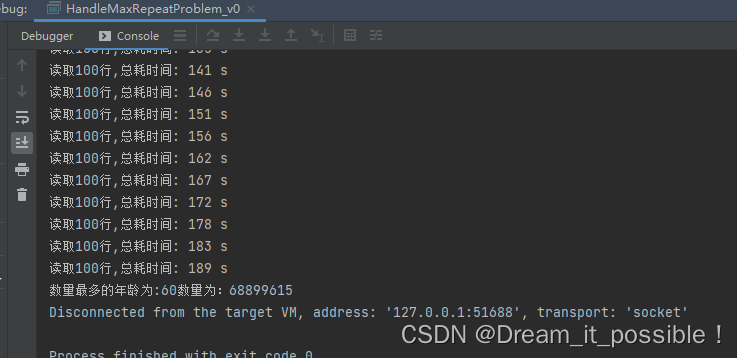
System.out.println("数量最多的年龄为:" + targetKey + "数量为:" + targetValue);
}
测试结果
总共花了 3 分钟读取完并统计完所有数据。
内存消耗为 2G-2.5G,CPU 利用率太低,只向上浮动了 20%-25% 之间。
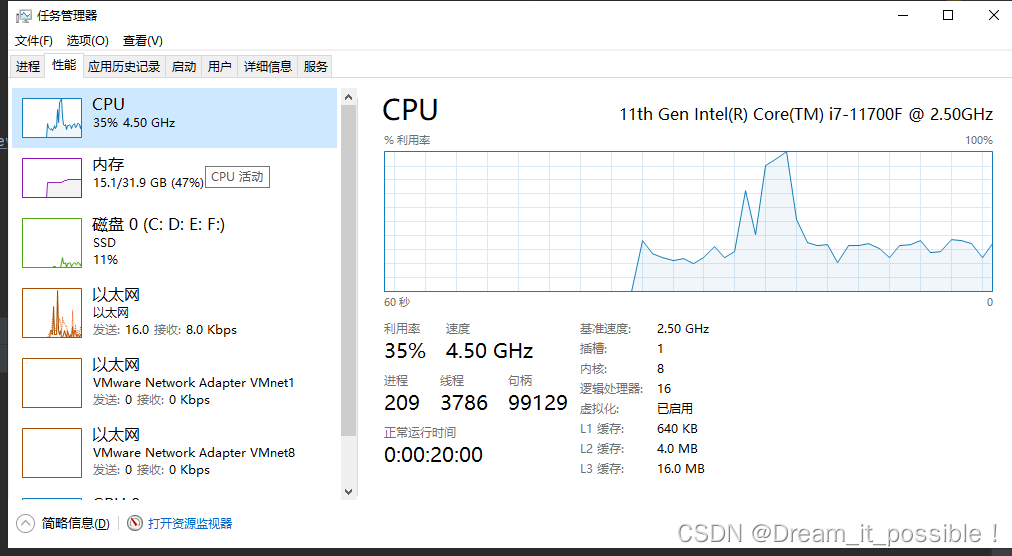
要想提高 CPU 利用率,那么可以使用多线程去处理。
下面我们使用多线程去解决这个 CPU 利用率低的问题。
5.2 思路二:分治法
使用多线程去消费读取到的数据。采用生产者、消费者模式去消费数据。
因为在读取的时候是比较快的,单线程的数据处理能力比较差。因此思路一的性能阻塞在取数据的一方且又是同步操作,导致整个链路的性能会变的很差。
所谓分治法就是分而治之,也就是说将海量数据分割处理。根据 CPU 的能力初始化 n 个线程,每一个线程去消费一个队列,这样线程在消费的时候不会出现抢占队列的问题。同时为了保证线程安全和生产者消费者模式的完整,采用阻塞队列。Java 中提供了 LinkedBlockingQueue 就是一个阻塞队列。
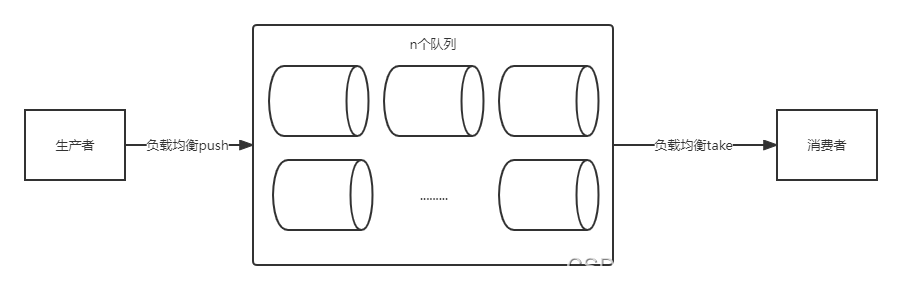
初始化阻塞队列
使用 LinkedList 创建一个阻塞队列列表:
privatestaticListString >>blockQueueLists=newLinkedList<>();
在 static 块里初始化阻塞队列的数量和单个阻塞队列的容量为 256。
上面讲到了 30 亿数据大概 2500 行,按行塞到队列里。20 个队列,那么每个队列 125 个,因此可以容量可以设计为 256 即可。
//每个队列容量为256
for (int i = 0; i < threadNums; i++) {
blockQueueLists.add(new LinkedBlockingQueue<>(256));
}
生产者
为了实现负载的功能,首先定义一个 count 计数器,用来记录行数:
privatestaticAtomicLongcount=newAtomicLong(0);
按照行数来计算队列的下标 long index=count.get()%threadNums。
下面算法就实现了对队列列表中的队列进行轮询的投放:
static classSplitData{
publicstaticvoidsplitLine(StringlineData){
String[] arr = lineData.split("
");
for (String str : arr) {
if (StringUtils.isEmpty(str)) {
continue;
}
long index = count.get() % threadNums;
try {
// 如果满了就阻塞
blockQueueLists.get((int) index).put(str);
} catch (InterruptedException e) {
e.printStackTrace();
}
count.getAndIncrement();
}
}
消费者
1) 队列线程私有化
消费方在启动线程的时候根据 index 去获取到指定的队列,这样就实现了队列的线程私有化。
private static void startConsumer() throws FileNotFoundException, UnsupportedEncodingException {
//如果共用一个队列,那么线程不宜过多,容易出现抢占现象
System.out.println("开始消费...");
for (int i = 0; i < threadNums; i++) {
final int index = i;
// 每一个线程负责一个 queue,这样不会出现线程抢占队列的情况。
new Thread(() -> {
while (consumerRunning) {
startConsumer = true;
try {
String str = blockQueueLists.get(index).take();
countNum(str);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
2) 多子线程分割字符串
由于从队列中多到的字符串非常的庞大,如果又是用单线程调用 split(",") 去分割,那么性能同样会阻塞在这个地方。
// 按照 arr的大小,运用多线程分割字符串
private static void countNum(String str) {
int[] arr = new int[2];
arr[1]=str.length()/3;
for (int i = 0; i < 3; i++) {
finalStringinnerStr=SplitData.splitStr(str,arr);
new Thread(() -> {
String[] strArray = innerStr.split(",");
for (String s : strArray) {
countMap.computeIfAbsent(s, s1 -> new AtomicInteger(0)).getAndIncrement();
}
}).start();
}
}
3) 分割字符串算法
分割时从 0 开始,按照等分的原则,将字符串 n 等份,每一个线程分到一份。
用一个 arr 数组的 arr[0] 记录每次的分割开始位置。arr[1] 记录每次分割的结束位置,如果遇到的开始的字符不为 "," 那么就 startIndex-1。如果结束的位置不为 "," 那么将 endIndex 向后移一位。
如果 endIndex 超过了字符串的最大长度,那么就把最后一个字符赋值给 arr[1]。
/**
* 按照 x坐标 来分割 字符串,如果切到的字符不为“,”, 那么把坐标向前或者向后移动一位。
*
* @param line
* @param arr 存放x1,x2坐标
* @return
*/
public static String splitStr(String line, int[] arr) {
int startIndex = arr[0];
int endIndex = arr[1];
char start = line.charAt(startIndex);
char end = line.charAt(endIndex);
if ((startIndex == 0 || start == ',') && end == ',') {
arr[0] = endIndex + 1;
arr[1] = arr[0] + line.length() / 3;
if (arr[1] >= line.length()) {
arr[1] = line.length() - 1;
}
return line.substring(startIndex, endIndex);
}
if (startIndex != 0 && start != ',') {
startIndex = startIndex - 1;
}
if (end != ',') {
endIndex = endIndex + 1;
}
arr[0] = startIndex;
arr[1] = endIndex;
if (arr[1] >= line.length()) {
arr[1] = line.length() - 1;
}
return splitStr(line, arr);
}
测试结果
内存和 CPU 初始占用大小:
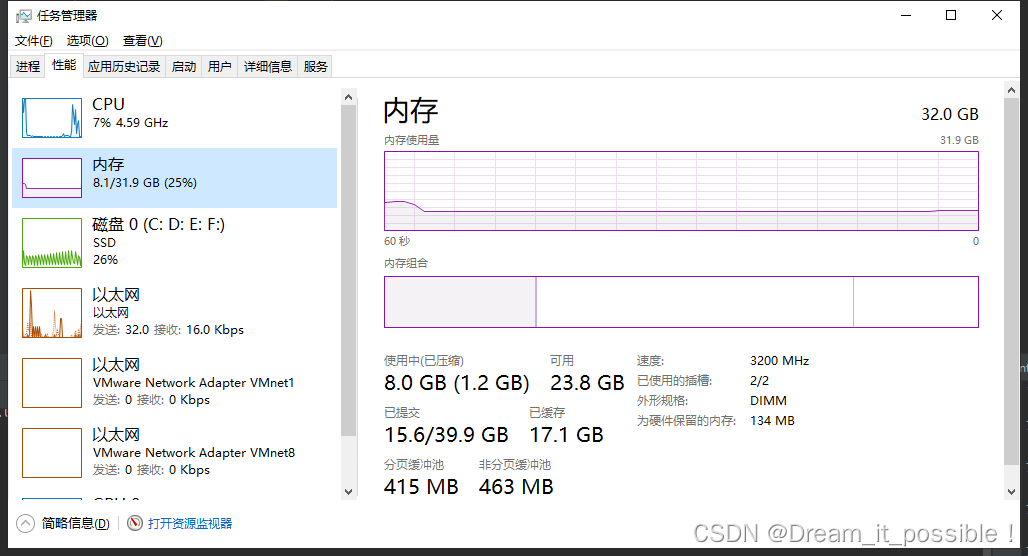
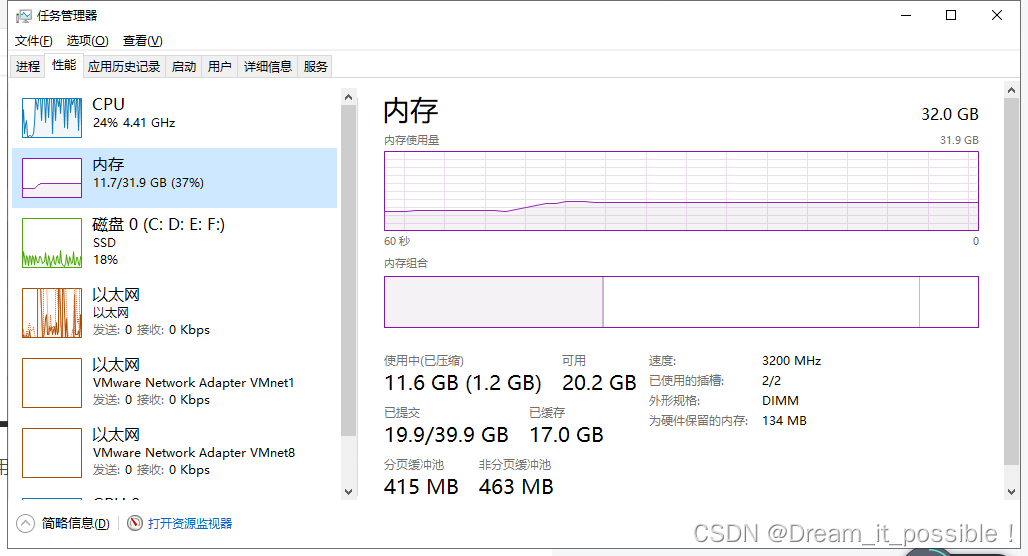
启动后,运行时内存稳定在 11.7G,CPU 稳定利用在 90% 以上。
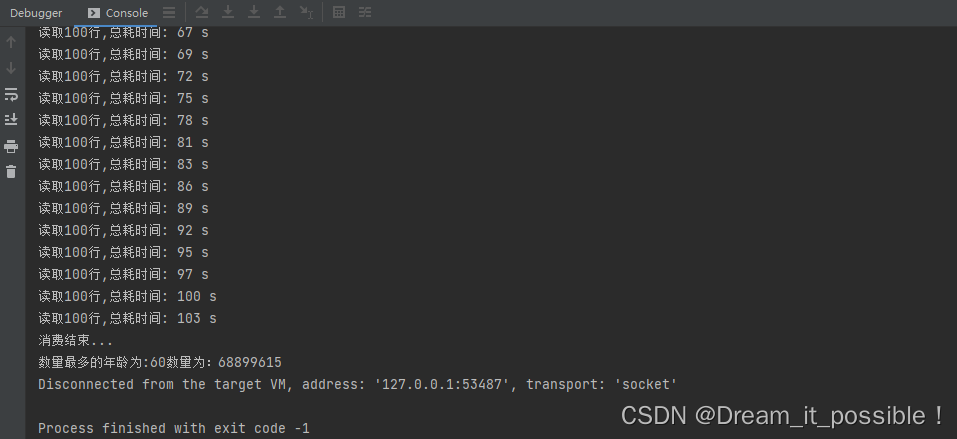
总耗时由 180 秒缩减到 103 秒,效率提升 75%,得到的结果也与单线程处理的一致。
6. 遇到的问题
如果在运行了的时候,发现 GC 突然罢工不工作了,有可能是 JVM 的堆中存在的垃圾太多,没回收导致内存的突增。
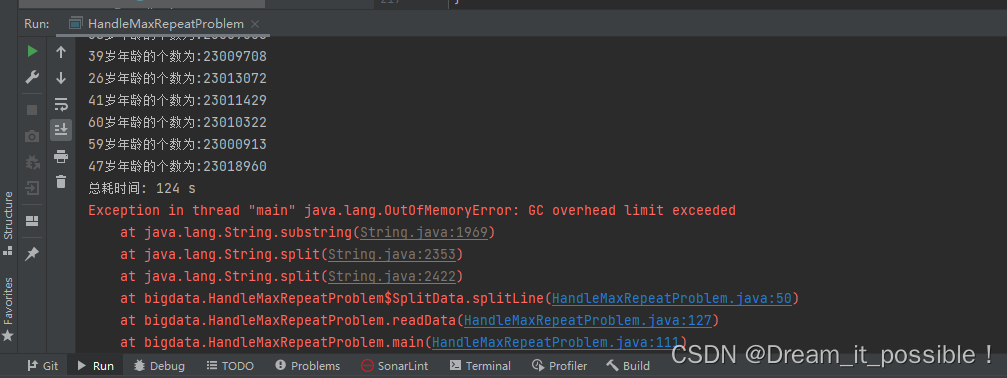
解决方法
在读取一定数量后,可以让主线程暂停几秒,手动调用 GC。
提示: 本 demo 的线程创建都是手动创建的,实际开发中使用的是线程池。
审核编辑 :李倩
-
数据
+关注
关注
8文章
7223浏览量
90162 -
JAVA
+关注
关注
19文章
2980浏览量
105652 -
代码
+关注
关注
30文章
4857浏览量
69515
原文标题:如何用 Java 几分钟处理完 30 亿个数据?
文章出处:【微信号:TheBigData1024,微信公众号:人工智能与大数据技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
几分钟带你搞懂什么是压力传感器
AFE4400做高温试验时,工作几分钟就停止工作读不出数据了,是什么原因导致的?
使用ADS1292R的内部测试信号采样结果漂移严重,怎么处理?
ADS1299运行几分钟后就出现失真的原因?怎么解决?
DAC8740H配合DAC8750使用,连续工作几分钟后DAC8740损坏,怎么回事?
LMK05318在TICS Pro中怎样设置,可以加快同步的速度,实现几分钟之内相位同步?
PCM1794数字模拟分开供电,二者地通过一个磁珠连接,pcm1794有轻微发热正常吗?
TPA3116D2采用PBTL模式,工作几分钟就出现功放增益自动减小,请帮忙看看问题出在哪里?
“云计算一哥”深夜放大招:几分钟,纯靠Prompt打造一个App!





 工商网监
工商网监
评论