 始于硬件却也被硬件所限的深度学习
始于硬件却也被硬件所限的深度学习
电子发烧友网报道(文/周凯扬)深度学习硬件在AI时代已经引领了不少设计创新,无论是简单的边缘推理,还是大规模自然语言模型的训练,都有了性能上的突破。作为业内在深度学习上投入最多的公司之一,英伟达无疑是这类硬件的领军者。
近日,在伯克利大学的电子工程与电脑科学学院研讨会上,英伟达的首席科学家、研究部门高级副总裁同时兼任该校副教授的BillDally,分享了从他这个从业人士看来,发生在深度学习硬件上的一些趋势。
硬件成为限制
AI的浪潮其实早在20世纪就被多次掀起过,但真正成为人们不可忽视的巨浪,还是这十几年的事,因为这时候AI有了天时地利人和:算法与模型,大到足够训练这些模型的数据集,以及能在合理的时间内训练出这些模型的硬件。
但从带起第一波深度学习的AlexNet,到如今的GPT-3和TuringNLG等,人们不断在打造更大的数据集和更大的模型,加上大语言模型的兴起,对训练的要求也就越来越高。可在摩尔定律已经放缓的当下,训练时间也在被拉长。

基于Hopper架构的H100GPU/英伟达
以英伟达为例,到了帕斯卡这一代,他们才真正开始考虑单芯片的深度学习性能,并结合到GPU的设计中去,所以才有了Hopper这样超高规格的AI硬件出现。但我们在训练这些模型的时候,并没有在硬件规模上有所减少,仍然需要用到集成了数块HopperGPU的DGX系统,甚至打造一个超算。很明显,单从硬件这一个方向出发已经有些不够了,至少不是一个“高性价比”的方案。
软硬件全栈投入
硬件推出后,仍要针对特定的模型进行进一步的软件优化,因此即便是同样的硬件,其AI性能也会在未来呈现数倍的飞跃。从上个月的MLPerf的测试结果就可以看出,在A100GPU推出的2.5年内,英伟达就靠软件优化实现了最高2.5倍的训练性能提升,当然了最大的性能提升还是得靠H100这样的新硬件来实现。
BillDally表示这就是英伟达的优势所在,虽然这几年投入进深度学习硬件的资本不少,但随着经济下行,不少投资者已经丧失了信心,所以不少AI硬件初创公司都没能撑下去,他自己也在这段时间看到了不少向英伟达投递过来的简历。
他认为不少这些公司都已经打造出了自己的矩阵乘法器,但他们并没有在软件上有足够的投入,所以即便他们一开始给出的指标很好看,也经常拿英伟达的产品作为对比,未来的性能甚至比不过英伟达的上一代硬件,更别说Hopper这类新产品了。
加速器
相较传统的通用计算硬件,加速器在深度学习上明显要高效多了,因为加速器往往都是作为一种专用单元存在的,比如针对特定的数据类型和运算。加速器可以在一个运算周期内就完成通常需要花上10秒或100秒才能完成的工作量,效率最高可提升1000倍。
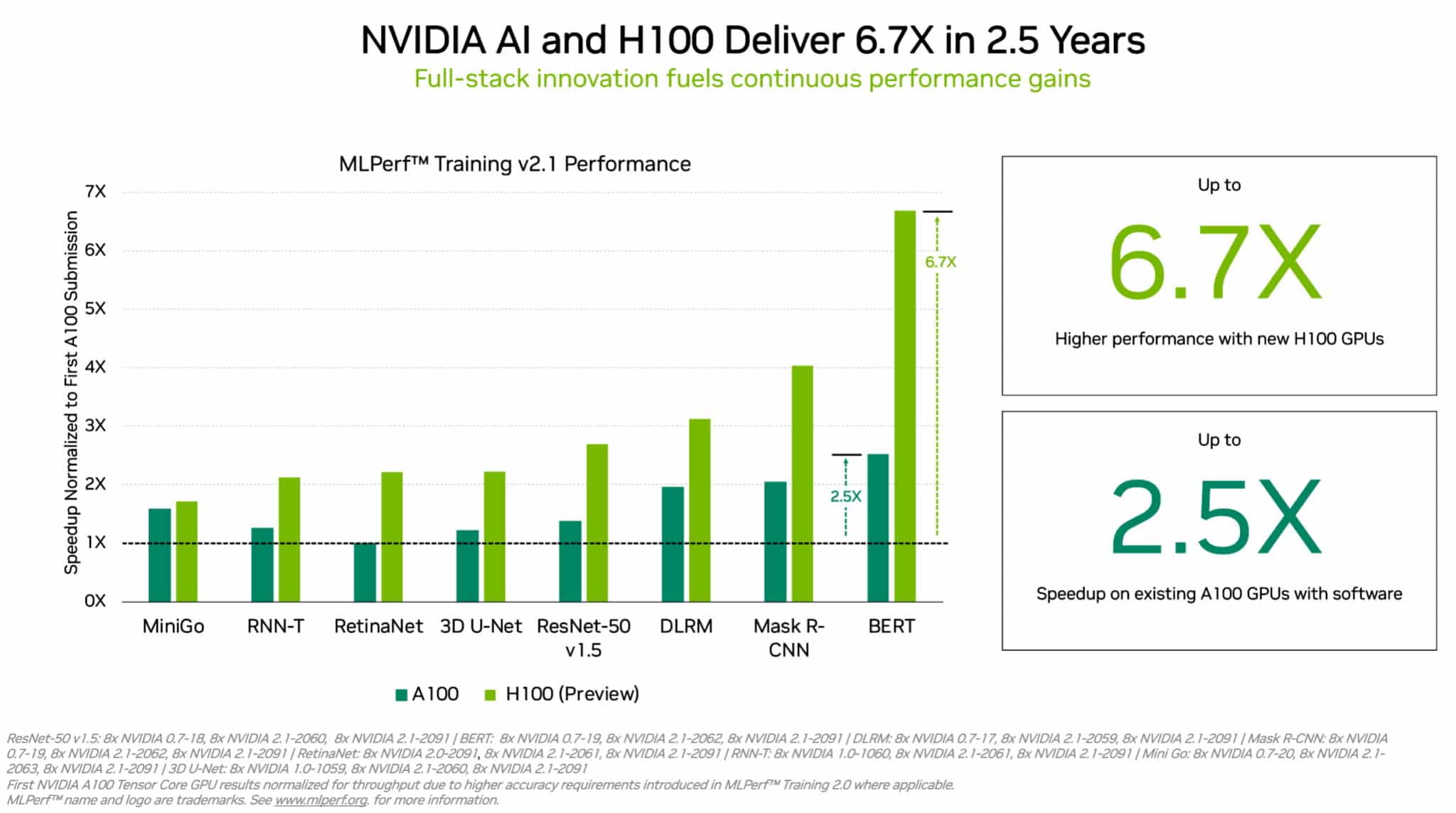
A100和H100的MLPerf跑分/英伟达
当然了要追求纯粹的性能提升,而不是效率提升的话,这些加速器也可以采用大规模并行设计,比如典型的32x32矩阵乘法单元,同时运行的运算有了千百倍的提升。加速器在内存设计上也更具有优势,比如针对特定的数据结构和运算,选择优化过的高带宽低能耗内存,同时尽可能使用本地内存,减少数据搬运来控制开销。
对于英伟达来说,他们在加速器上的研究更像是为GPU准备的试验田,一旦有优秀的成果出现,这些加速器就会成为GPU上的新核心。
小结
从BillDally的分享中,我们可以看出英伟达这样的巨头在深度学习上选择的技术路线,以及他们为何能在众多初创公司涌现、大厂入局的当下岿然不动的底气。这并不是说深度学习硬件的道路只有这一条,类脑芯片等技术的出现也提供了新的破局机会,但有了前人经验的借鉴后,在兼顾性能、数值精度、模型的同时,还是得在软件上下大功夫才行。
-
计算
+关注
关注
2文章
450浏览量
38835 -
AI
+关注
关注
87文章
31155浏览量
269494 -
深度学习
+关注
关注
73文章
5507浏览量
121299
发布评论请先 登录
相关推荐
学习硬件的第一节课:学习读懂原理图
NPU在深度学习中的应用
pcie在深度学习中的应用
GPU深度学习应用案例
FPGA加速深度学习模型的案例
AI大模型与深度学习的关系
FPGA做深度学习能走多远?
如何帮助孩子高效学习Python:开源硬件实践是最优选择
启明智显:深度融合AI技术,引领硬件产品全面智能化升级
深度学习中的时间序列分类方法
深度学习编译工具链中的核心——图优化
深度解析深度学习下的语义SLAM






 工商网监
工商网监
评论