 如何通过poly实现C++编译期多态
如何通过poly实现C++编译期多态
引言
前面的文章中我们更多的聚焦在运行期反射,本篇我们将聚焦在一个与反射使用的机制有所类同,但更依赖编译期特性的机制-》编译期多态实现。
c++最近几版的更新添加了大量的compiler time特性支持,社区轮子的热情又进一步高涨。这几年go与rust等语言也发展壮大,那么,我们能不能在c++中实现类似go interface和rust traits的机制呢?
答案是肯定的,开源社区早已经开始了自己的行动,dyno与folly::poly都已经有了自己的实现。两者的实现思路基本一致,差别主要在于dyno使用了boost::hana和其他一些第三方库来完成整体机制的实现。
而folly::poly出来的晚一些,主要使用c++的新特性来实现相关的功能,依赖比较少,所以本文将更多的以poly的实现来分析编译期多态的整体实现。
一、从c++的运行时多态说起
(一)一个简单的例子
struct Vehicle {
virtual void accelerate() = 0;
virtual ~Vechicle() {}
};
struct Car: public Vehicle {
void accelerate() override;
};
struct Truck: public Vehicle {
void accelerate() override;
};
(二)对应的运行时内存结构
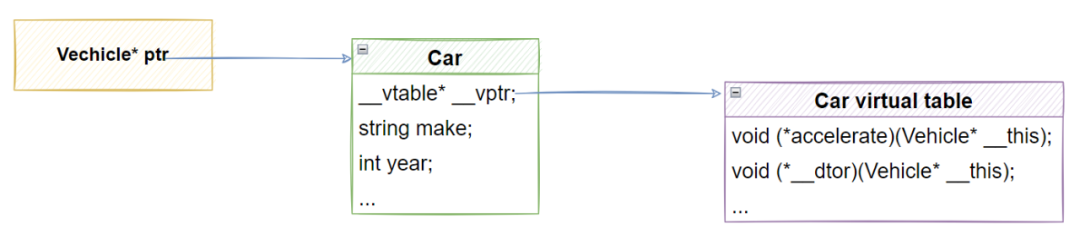
(三)运行时多态带来的问题
性能问题
大量的文章都提到,因为virtual table的存在,对比纯c的实现,c++运行时多态的使用会付出额外的性能开销。
指针带来的问题
运行时多态一般多配合指针一起使用,这也导致基本相关代码都是配合堆内存来使用的,后续又引入了智能指针缓解堆内存分配导致的额外心智负担,但智能指针的使用本身又带来了其他问题。
侵入性问题
类继承需要强制指定子类的基类,当我们引入第三方库的时候,要么不可避免的需要对其进行修改,要么需要额外的包装类,这些都会带来复杂度的上升和性能的下降。还有一些其他的问题,这里就不再展开了,最近的cppconn多态本身相关的讨论也是一个热点,许多项目开始尝试用自己的方法试图解决运行时多态的问题,感兴趣的可以自行去了解相关的内容。
本部分例子和内容主要来自Louis Dionne的Runtime Polymorphism: Back To The Basics。
二、dyno与poly的实现思路
(一)dyno与poly的目的-编译期多态
dyno想达成的效果其实就是实现编译期多态,如作者所展示的代码片段:
interface Vechicle { void accelerate(); };
namespace lib{
struct Motorcycle { void accelerate(); };
}
struct Car { void accelerate(); };
struct Truck { void accelerate(); };
int main() {
std::vector vehicles;
vehicles.push_back(Car{...});
vehicles.push_back(Truck{...});
vehicles.push_back(lib::Motorcycle{...});
for(auto& vehicle: vehicles) {
vehicle.accelerate();
}
}
想法很美好, 但现实是残酷的, 并没有interface存在, 在可预知的一段时间里, 也不会有, 那么如果要自己实现相关的机制, 该如何来达成呢? 我们在下文中先来看一下整体的实现思路。
(二)编译期多态的设计思路
参考前面的运行时多态模型:
dyno的思路比较直接,尝试使用两个独立的部分来解决编译期多态的支持问题:
Storage policy-负责对象的存储。
VTable policy-负责函数分发调用。
folly::Poly的实现思路大量参考了dyno,与dyno一致,也是同样的结构。我们继续以Vechicle举例,假设真的存在Vechicle对象,那么它的组织肯定是如下图所示的:
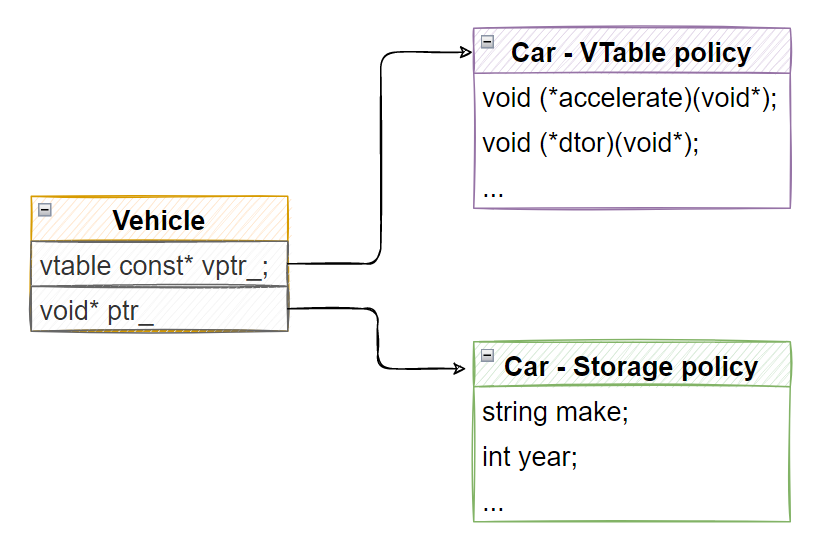
通过这种结构,我们就能正常的访问到Car等具体对象的accelerate()方法了,原理上还是比较简洁的,但是要做到完全的编译期多态,并不是一个简单的事情。接下来我们先来看一个poly的示例代码,先从应用侧了解一下它的使用。
三、poly的示例代码
我们还是以Vechicle为例,给出一段poly的示例代码:
struct IVehicle {
// Define the interface for vehicle
template <class Base> struct Interface : Base {
void accelerate() const {
folly::poly_call<0>(*this);
}
};
// Define how concrete types can fulfill that interface (in C++17):
template <class T> using Members = folly::PolyMembers<&T::accelerate>;
};
using vehicle = folly::Poly;
struct Car {
void accelerate() const {
std::cout << "Car accelerate!" << std::endl;
}
};
struct Trunk {
void accelerate() const {
std::cout << "Trunk accelerate!" << std::endl;
}
};
void accel_func(vehicle const& v) {
v.accelerate();
}
int main() {
accel_func(Car{}); // Car accelerate
accel_func(Trunk{}); // Trunk accelerate
return 0;
}
从上面的示例可以看到,poly的封装使用还是比较简洁的,主要是两个辅助对象的定义:
IVehicle 类的定义
vehicle类的定义
(一)IVehicle类
struct IVehicle {
// Define the interface for vehicle
template <class Base> struct Interface : Base {
void accelerate() const {
folly::poly_call<0>(*this);
}
};
// Define how concrete types can fulfill that interface (in C++17):
template <class T> using Members = folly::PolyMembers<&T::accelerate>;
};
IVehicle类主要提供两个功能:
通过内嵌类型Members来完成接口包含的所有成员的定义,如上例中的&T::accelerate。
通过内嵌类型Interface提供类型擦除后的poly《》对象的访问接口。
两者的部分信息其实有所重复,另外因为poly是基于c++17特性的,所以也没有使用concept对Interface的类型提供约束,这个地方约束性和简洁性上会有一点折扣。
(二) vehicle类
using vehicle = folly::Poly《IVehicle》;
这个类使用我们前面定义的IVehicle类来定义一个folly::Poly《IVechicle》容器对象,所有满足IVehicle定义的类型都可以被它所容纳,与std::any类似,只是std::any用于装填任意类型,folly::Poly《》只能用来装填符合相关Interface定义的对象,比如上面定义的vehicle,就能用来容纳前面示例中定义的Car和Trunk等实现了void accelerate() const方法的类型。同样,区别于std::any只是用作一个万能容器,这里的vehicle本身也是支持函数调用的,比如例子中的:accelerate()。
(三)示例小结
通过上面的示例代码,我们对poly的使用有了初步的了解,从上面的代码中可以看出,编译期多态的使用还是比较简洁的,整体过程跟c++标准的继承比较类似,有几点差别比较大:
我们不需要侵入性的去指定子类的基类,我们通过非侵入性的方式来使用poly库。
我们是通过构建的folly::Poly《》来完成对各种子类型的容纳的,而不是直接使用基类来进行类型退化再统一存储所有子类,这样也就避免了继承一般搭配堆内存分配使用的问题。
那么,整套机制是如何实现的呢? 我们在下文中将具体展开。
四、关于实现的猜想
前面的文章中我们介绍了运行时反射的相关机制,所以类似poly这种使用侧的包装,如果我们抛开性能,考虑用反射实现类似机制,还是比较容易的。
(一)VTable与meta::class
VTable的概念其实与前面的篇章里提到的meta::class功能基本一致:
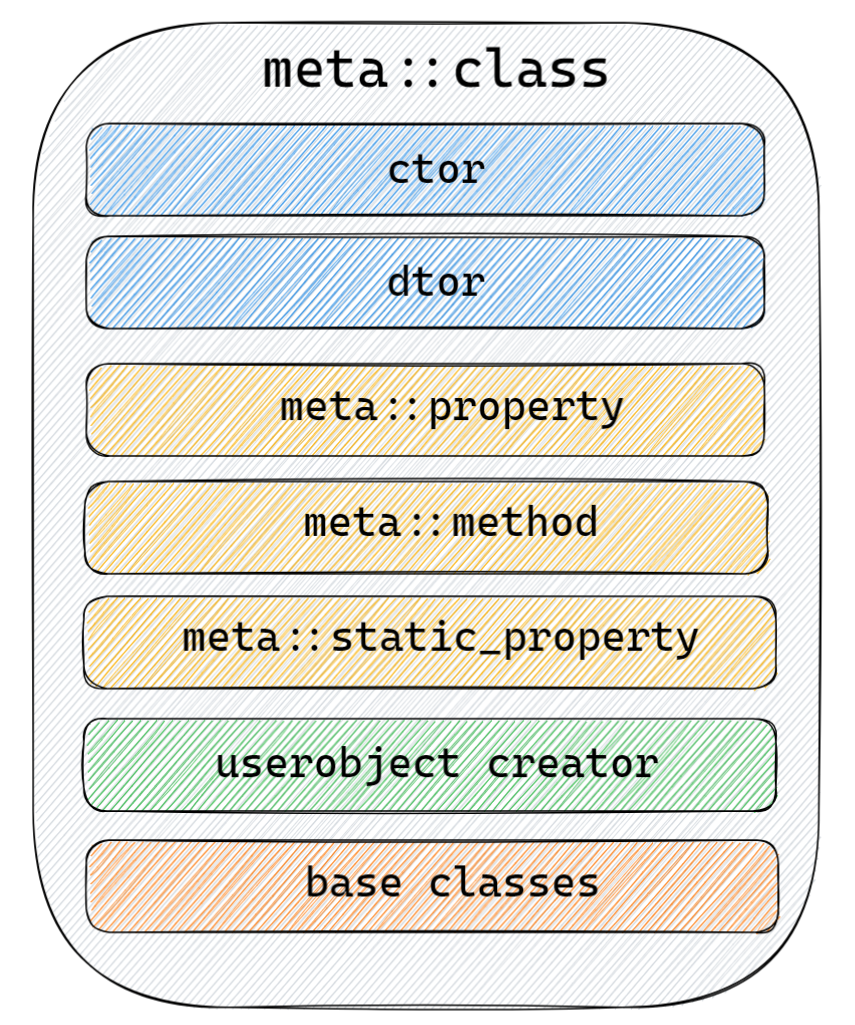
meta::class上存的meta::method都是已经完成类型擦除的版本,所以我们可以通过名称很容易的从中查询出自己需要的函数,比如上例中的accelerate,相关代码类似于:
const reflection::Function* accel_func = nullptr;
car_meta_class.TryGetFunction("accelerate", accel_func);
runtime::Call(*accel_func, car_obj);
当然,此处我们省略了meta::class的注册过程,也省略了car_obj这个UserObject的创建过程。
(二)folly::Poly《》与UserObject
我们很容易想到,使用UserObject作为Car和Trunk的容器,能够起到跟folly:Poly《》类似的效果。利用UserObject,我们可以很好的完成各种不同类型对象的类型擦除,很好的完全不同类型对象的统一存储和函数参数传递的目的。
(三)运行时反射实现的例子
这样,对于原来的例子,省略meta class的注册过程,大致的代码如下:
struct Car {
void accelerate() const {
std::cout << "Car accelerate!" << std::endl;
}
};
struct Trunk {
void accelerate() const {
std::cout << "Trunk accelerate!" << std::endl;
}
};
void accel_func(UserObject& v) {
auto& meta_class = v.GetClass();
const reflection::Function* accel_func = nullptr;
meta_class.TryGetFunction("accelerate", accel_func);
runtime::Call(*accel_func, v);
}
int main() {
//Car meta class register ignore here
// ...
//Trunk meta class register ignore here
accel_func(UserObject::MakeOwned(Car{})); // Car accelerate
accel_func(UserObject::MakeOwned(Trunk{})); // Trunk accelerate
return 0;
}
功能上似乎是那么回事,甚至因为运行时反射本身各部分类型擦除很彻底,好像实现上更灵活了,但是,这其实只是形势上实现了一个运行时interface like的功能,我们容易看出,这个实现达成了以下目的:
非侵入性,Car与Trunk不需要额外的修改就能支持interface like的功能。
我们可以利用类型擦除的UserObject对Car和Trunk这些不同类型的对象进行存储。
不同对象上的accelerate()实现可以被正确的调用。
同时,这个实现存在诸多的问题:
运行时实现,性能肯定有比较大的折扣。
比较彻底的类型擦除带来的问题,整个实现一点都不compiler time,编译期的基础类型检查也完全没有了。
那么我们肯定会想到,poly是如何利用compiler time特性,实现更快的interface like的版本的呢? 这也是我们下一章节开始想展开的内容。
五、poly的实现分析
在开始分析前,我们先来回顾一下前面的示例代码:
using vehicle = folly::Poly;
void accel_func(vehicle const& v) {
v.accelerate();
}
int main() {
accel_func(Car{}); // Car accelerate
accel_func(Trunk{});
return 0;
}
一切的起点发生在accel_func()将临时构造的Car{}和Trunk{}向vehicle转换的过程中,而我们知道vehicle实际类型是folly::Poly
上例中,Car和Trunk类型向Duck Type类型转换的代码如下:
template <class I>
template ::value, int>>
inline PolyVal::PolyVal(T&& t) {
using U = std::decay_t;
//some compiler time && runtime check ignore here
//...
if (inSitu()) {
auto const buff = static_cast<void*>(&_data_()->buff_);
::new (buff) U(static_cast(t));
} else {
_data_()->pobj_ = new U(static_cast(t));
}
vptr_ = vtableFor();
}
非常直接的代码,可以看出与dyno的思路完全一致,主要完成我们前面提到过的两件事:
Storage policy-分配合适的空间以存储对象。
VTable policy-为对象关联正确的VTable。
当然,实际的实现过程其实还有比较多的细节,我们先来具体看一下storage与VTable这两部分的实现细节。
(一)storage处理
整个poly的storage处理完全参考了dyno的实现,当然并没有像dyno那样提供多种storage policy,而是固定的分配策略:
if (inSitu()) {
auto const buff = static_cast<void*>(&_data_()->buff_);
::new (buff) U(static_cast(t));
} else {
_data_()->pobj_ = new U(static_cast(t));
}
适合原地构造的,则直接使用replacement new来原地构造对象(性能最优的方式),否则则还是使用堆分配。这里会用到一个Data类型,也是完全copy的dyno的实现,定义如下:
struct Data {
Data() = default;
// Suppress compiler-generated copy ops to not copy anything:
Data(Data const&) {}
Data& operator=(Data const&) { return *this; }
union {
void* pobj_ = nullptr;
std::aligned_storage_t<sizeof(double[2])> buff_;
};
};
其实我们已经不难猜到inSitu()的实现了,其中肯定有对对象大小的判断:
template <class T>
inline constexpr bool inSitu() noexcept {
return !std::is_reference::value &&
sizeof(std::decay_t) <= sizeof(Data) &&
std::is_nothrow_move_constructible<std::decay_t>::value;
}
除了原地构造的大小限制外-写死的两个double大小,poly增加了对无异常移动构造的约束,也就是对象的移动构造如果不是nothrow的,就算大小满足要求,也依然会使用堆分配进行构造。
storage这部分主要还是使用SBO的优化策略,这部分dyno相关的视频中有详细的介绍,poly的实现完全照搬了那部分思路,感兴趣的同学可以自行去看一下参考部分的相关视频,了解更多的细节,也包括dyno作者自己做的性能分析。
(二)VTable处理
vptr_ = vtableFor《I, U》();
处理的难点
对于Car和Trunk,它们同名的void accelerate()函数,其实类型并不相同,这是因为类的成员函数都隐含了一个this指针,将自己的类型带入进去了。简单的保存成员函数的指针的方式肯定不适用了,另外因为我们需要最终得到统一的Duck Type-vehicle,我们也需要统一Car和Trunk的VTable类型,所以这里肯定是要对接口函数的类型做一次擦除操作的。
另外,因为我们需要尽可能的避免运行时开销,所以在我们使用Duck Type对对象的相关接口,如上面的accelerate()进行访问的时候,我们希望中间过程是足够高效的。
poly是如何做到这两点的呢? 我们带着这两个疑问,逐步深入相关的代码了解具体的实现。
-
vtableFor<>实现
template <class I, class T>
constexpr VTable const* vtableFor() noexcept {
return &StaticConst>> ::value;
}
这个地方的StaticConst是一个类似singleton的封装:
// StaticConst
//
// A template for defining ODR-usable constexpr instances. Safe from ODR
// violations and initialization-order problems.
template <typename T>
struct StaticConst {
static constexpr T value{};
};
template <typename T>
constexpr T StaticConst::value;
这样我们就有了一个根据类型来查询全局唯一VTable指针的机制了,足够高效。
核心问题的解决都是发生在VTableFor
-
VTableFor与VTable的实现
template <class I, class T>
struct VTableFor : VTable {
constexpr VTableFor() noexcept : VTable{Type{}} {}
};
template <
class I,
class = MembersOf<I, Archetype>>,
class = SubsumptionsOf<I>>
struct VTable;
template <class I, FOLLY_AUTO... Arch, class... S>
struct VTable, TypeList>
: BasePtr..., std::tuple...> {
private:
template <class T, FOLLY_AUTO... User>
constexpr VTable(Type, PolyMembers) noexcept
: BasePtr{vtableFor()}...,
std::tuple...>{thunk_()...},
state_{inSitu() ? State::eInSitu : State::eOnHeap},
ops_{getOps()} {}
public:
constexpr VTable() noexcept
: BasePtr{vtable()}...,
std::tuple...>{
static_cast>(throw_())...},
state_{State::eEmpty},
ops_{&noopExec} {}
template <class T>
explicit constexpr VTable(Type) noexcept
: VTable{Type{}, MembersOf{}} {}
State state_;
void* (*ops_)(Op, Data*, void*);
};
这个地方的代码实现其实有点绕,一开始我以为是使用的CTAD,c++17的模板参数自动推导的功能,按照类似的方式在自己的代码上尝试始终失败,最后才发现跟CTAD一点关系没有。
首先是第一点,VTable通过I(也就是例子中的IVehicle),就能够完全构建出自己的类型了,这也是为什么Car与Trunk的VTable类型完全一致的原因,因为类型定义上,完全不依赖具体的Car和Trunk。
然后是第二点,VTable的第一个构造函数为VTable提供实际的数据来源,这里才会用到具体的类型Car和Trunk。
那么VTable的设计是如何实现具体的类型分离的呢? 这里直接给出答案,我们可以认为,poly对接口函数做了一个部分的类型擦除,相比于之前介绍的反射对所有函数进行类型统一,poly的函数擦除方法可以说是刚刚好,以上文中的accelerate()举例,在Car中的时候原始类型为:
void(const Car::*)();
最终类型擦除后产生的函数类型为:
void(*)(const folly::Data &);
这样,不管是Car和Trunk,它们对应接口的类型就被统一了,同时,Data本身也跟我们前面提到的Duck Type-PolyVal关联起来了。
这种转换老司机们肯定容易想到lambda,lambda肯定也是用于处理这种参数统一的利器,不过poly这里选用了一种编译开销更有优势的方式:
template <
class T,
FOLLY_AUTO User,
class I,
class = ArgTypes,
class = Bool>
struct ThunkFn {
template <class R, class D, class... As>
constexpr /* implicit */ operator FnPtr() const noexcept {
return nullptr;
}
};
template <class T, FOLLY_AUTO User, class I, class... Args>
struct ThunkFn<
T,
User,
I,
TypeList,
Bool<
!std::is_const>::value ||
IsConstMember>::value>> {
template <class R, class D, class... As>
constexpr /* implicit */ operator FnPtr() const noexcept {
struct _ {
static R call(D& d, As... as) {
return folly::invoke(
memberValue(),
get(d),
convert(static_cast(as))...);
}
};
return &_::call;
}
};
通过一个结构体的静态函数来绕开lambda来对函数的参数类型进行转换,当然,通过这里我们也能了解到具体的接口函数的执行过程了,有几点需要注意一下:
-
folly::invoke()的功能与标准库的std::invoke()功能一致。
-
get
(d)完成Data类型到具体类型的还原。
-
与反射中类似,也存在对参数表中的参数的convert的处理,这块就不再展开了,基本都是原始类型参数的派发,因为一些进阶功能存在Poly类型转换派发的情况,此处不再详细描述了。
再回到多个接口函数的存储上,这个是通过继承的std::tuple<>来完成的,所以我们在Interface的定义中也会发现
struct VTable, TypeList>
: BasePtr..., std::tuple...>
template <class T, FOLLY_AUTO... User>
constexpr VTable(Type, PolyMembers) noexcept
: BasePtr{vtableFor()}...,
std::tuple...>{thunk_()...},
state_{inSitu() ? State::eInSitu : State::eOnHeap},
ops_{getOps()} {}
trunk_()函数完成对上面函数类型转换函数ThunkFn()的调用,这样整个虚表中最重要的信息就构造完成了。
(三)关于性能
我们直接以windows上的release版为例,通过生成的asm大致推测poly实际的运行时性能:
//...
accel_func(Car{}); // Car accelerate
00007FF696421166 mov qword ptr [rsp+20h],0
00007FF69642116F lea rdi,[__ImageBase (07FF696420000h)]
00007FF696421176 lea rax,[rdi+33B0h]
00007FF69642117D mov qword ptr [rsp+30h],rax
00007FF696421182 lea rcx,[rsp+20h]
00007FF696421187 call ?? ::`folly::ThunkFn,std::integral_constant1 > >::operatorconst > void (__cdecl*)(folly::Data const &)'::`2'::call (07FF696421490h)
00007FF69642118C nop
00007FF69642118D mov rax,qword ptr [rsp+30h]
00007FF696421192 mov r9,qword ptr [rax+10h]
00007FF696421196 xor ecx,ecx
00007FF696421198 xor r8d,r8d
00007FF69642119B lea rdx,[rsp+20h]
00007FF6964211A0 call r9
00007FF6964211A3 nop
accel_func(Trunk{}); // Trunk accelerate
//...
到真正调用到实际的accelerate()函数,编译期的各种中间过程,基本都能被优化掉,整体性能估计跟virtual dispatch接近或者更高,有时间再结合实际的工程示例测试一下相关的数据,本篇性能相关的分析就先到这里了。
(四)poly小结
poly核心机制的实现并不复杂,主要也就是本章介绍的这部分,但poly还实现了一些进阶功能,比如interface之间的继承,非成员函数的支持等,导致整个实现的复杂度飙升,感兴趣的可以自行翻阅相关的代码,推荐的熟悉顺序是:
TypeList.h-里面封装了大量类型和类型运算相关的功能,整体思路类似boost::mpl的meta function,但基本没有其他依赖,实现也足够简单,值得一看。
PolyNode等其它用于支撑Interface继承的结构。
正常来说,熟悉了TypeList中的meta function以及常用的TypeFold等实现,读懂相关代码不会存在太多的障碍。
另外,Windows上不推荐直接使用源码编译folly,依赖库比较多,并且应该很久没人维护了,获取dependency的python脚本都直接报错,建议windows上直接使用vcpkg 安装folly进行使用,因为folly与boost 类似,基本只有头文件实现,通过这种方式并不影响源码的阅读和调试。
六、总结
本篇我们重点介绍了编译期多态,也讲到了它与反射的一些关联和差异,最后结合poly的相关实现介绍了一些核心的技术点。当然,就编译期反射来说,我们还有更多可以做的内容:
比如参考视频中提到的结合未来的语言新特性如reflect,meta class来进一步简化使用接口。
或者通过离线的方式做一部分代码生成来进一步简化使用侧的Interface定义,甚至提供更强的编译期约束等。
这些我们会尝试在实际的落地中逐步完善,有相关的进展再来分享了。
审核编辑:郭婷
-
C++
+关注
关注
22文章
2116浏览量
74277 -
代码
+关注
关注
30文章
4861浏览量
69673
原文标题:如何优雅地实现C++编译期多态?
文章出处:【微信号:C语言与CPP编程,微信公众号:C语言与CPP编程】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
rtsmart开启C++特性支持后,工具链编译内核不通过怎么解决?
源代码加密、源代码防泄漏c/c++与git服务器开发环境

HighTec C/C++编译器套件全面支持芯来RISC-V IP
HighTec C/C++编译器支持Andes晶心科技RISC-V IP
TMS320C28x优化C/C++编译器v22.6.0.LTS

OpenHarmony标准系统C++公共基础类库案例:HelloWorld

c++编译后链接失败的原因?如何解决?
C++中实现类似instanceof的方法

SEGGER编译器优化和安全技术介绍 支持最新C和C++语言






 工商网监
工商网监
评论