 如何使用CLM自身的embedding来得到OOD score?
如何使用CLM自身的embedding来得到OOD score?
背景
OOD现象和OOD检测在分类任务中已经被广泛研究:
OOD score:maximum softmax probability(MSP),K个类别中最大的概率来作为衡量OOD的指标
selective classification:对于OOD score太低的输入,模型拒绝输出
在conditional language model(CLM)任务(主要是summarization,translation)中,而由于language generation主要是通过auto-regressive的方式,错误更容易积累,因此OOD问题可能更严重。
本文的主要贡献:
提出一中轻量的、准确的基于CLM的embedding的OOD检测方法
发现perplexity(ppx)不适合作为OOD检测和文本生成质量评估的指标
提出了一套用于OOD检测和selective generation的评测框架
CLM中的OOD detection
如果直接套用classification任务中使用MSP作为OOD score的话,那么对于NLG问题我们就应该采用perplexity(ppx),然而作者实验发现使用ppx的效果很不好:

从上图可以看到,不用domain来源的数据,其ppx的分布重叠程度很高;甚至有些明明是OOD的数据,但其综合的ppx比ID的数据还要低。因此ppx对ID vs OOD的区分能力很差。
如何使用CLM自身的embedding来得到OOD score?
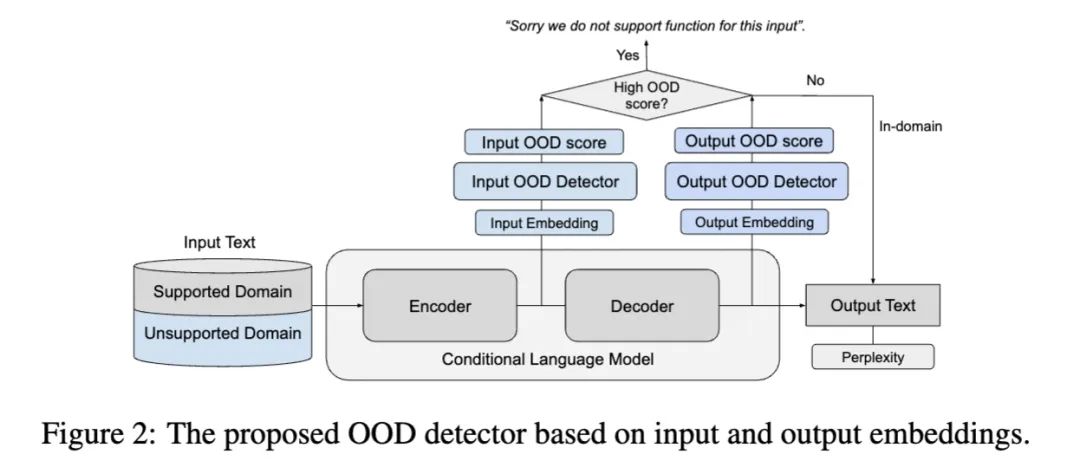
input embedding: encoder最后一层所有hidden states平均
output embedding: decoder最后一层所有hidden states平均(ground truth对应的位置)
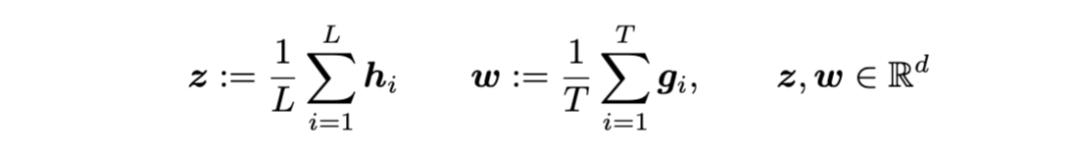
1. 使用两个分布的距离来判断——RMD score
直觉上讲,当一个样本的输入/输出的embedding跟我训练样本的embedding分布距离很远的话,就很可能是OOD样本。
因此,可以先用训练数据集,对输入和输出空间拟合一个embedding的高斯分布:
input embedding distribution:
output embedding distribution:
然后,就可以使用马氏距离(Mahalanobis distance,MD)来衡量新来的embedding跟训练集embedding的距离:
马氏距离是基于样本分布的一种距离。物理意义就是在规范化的主成分空间中的欧氏距离。(维基百科)
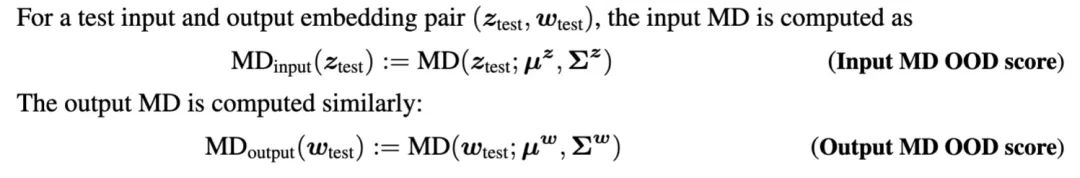
然而,已有一些研究表明,使用相对马氏距离(即增加一个background distribution来作为一个参照),可以更好地进行OOD检测。于是对上述公式改进为:
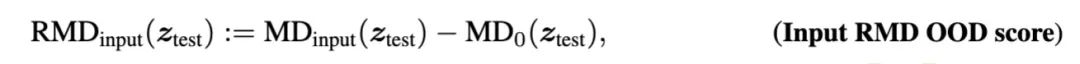
其中是衡量test input跟一个background高斯分布的距离,这个background分布,是使用一个通用语料拟合出来的,比方使用C4语料库。
而对于CLM这种需要成对语料的任务,通用语料中一般是没有的,所以使用通用文本通过CLM decode出来的 outputs来拟合分布:
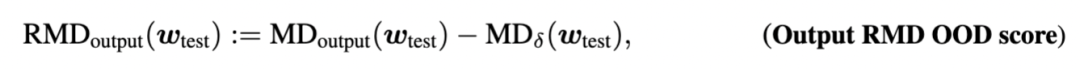
这样一来,RMD scores实际上可能为正也可能为负:
当RMD score < 0 时,说明 test example跟training distribution更接近
当RMD score > 0 时,说明 test example跟background更接近,因此更有可能是OOD的
因此,RMD score可以直接作为OOD detection的指标。
2. 基于embedding训练一个detector
上面是一种无监督的办法,作者还提出了一种有监督的办法,使用training samples和general samples作为两个类别的数据,使用embedding作为feature来训练一个logistic regressive model,使用background类的logits作为OOD score:
Input Binary logits OOD score
Output Binary logits OOD score
3. OOD detection实验
以summarization为例,实验所用数据为:
In-domain:10000条 xsum 样本
General samples:10000条 C4 样本
OOD datasets:near-OOD数据集(cnn dailymail,newsroom)和far-OOD数据集(reddit tifu,forumsum,samsum)
OOD detection衡量指标:area under the ROC curve (AUROC)
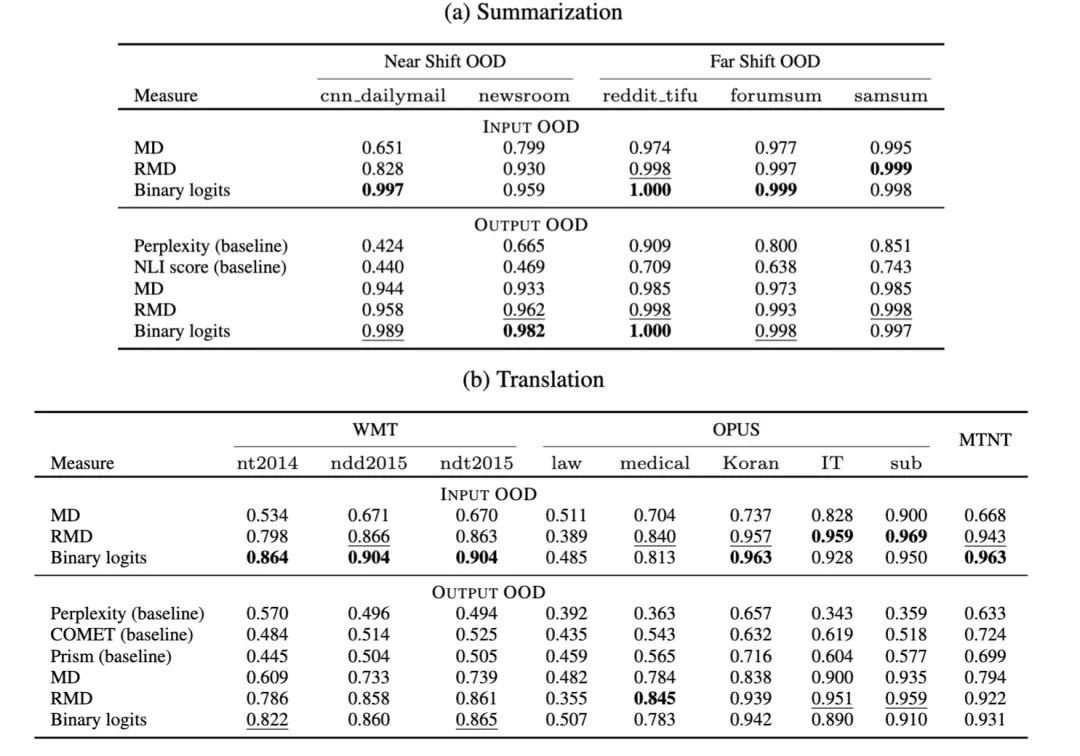
实验结论:
本文提出的RMD和Binary classifier都比baseline有更好的OOD检测能力
能更好地对near-OOD这种hard cases进行检测
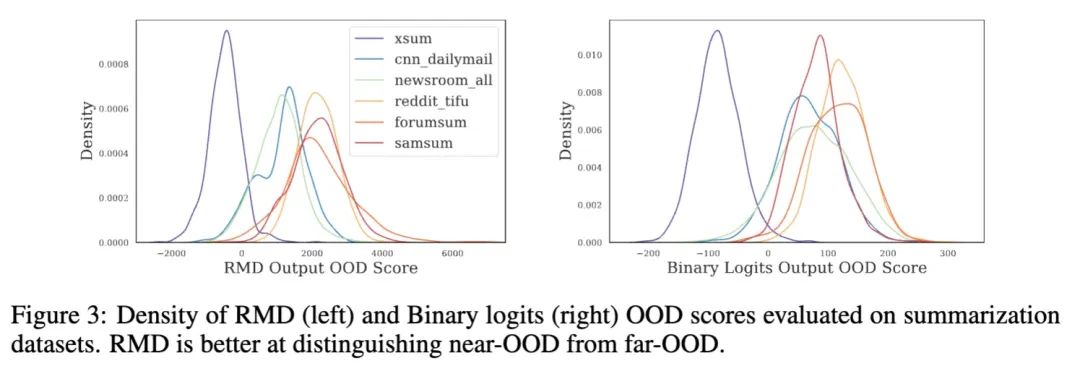
Selective Generation
当检测到OOD时,一个最保守的做法就是直接拒绝给出输出,从而避免潜在的风险。但是,我们依然希望当模型的输出质量足够高时,即使是OOD也能输出。
当有参考答案时,如何衡量输出文本的质量?
对于translation问题,使用BLEURT作为衡量指标;
对于summarization,常见是使用ROUGE score,但由于不同数据集的摘要模式差别很大,所以只使用ROUGE还不够,作者使用亚马逊众筹平台来对一批数据进行人工质量打标。
能否找到一个指标,不需要参考答案也能衡量文本质量?
实验发现,对于in-domain数据,ppx跟质量有比较好的相关性,但是对于OOD数据,相关性很差。
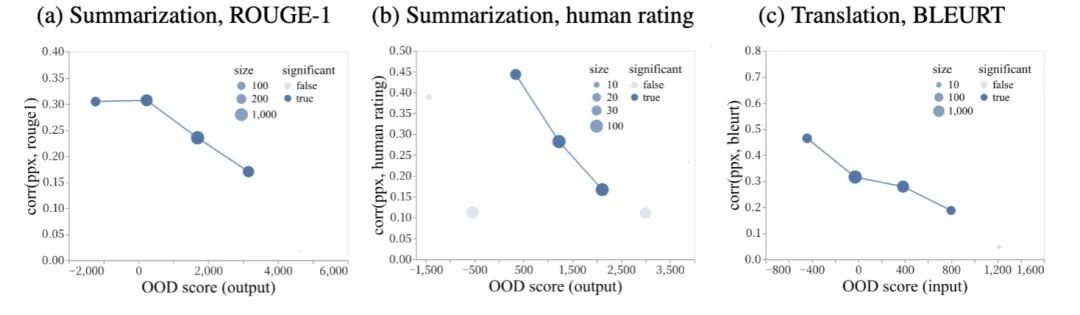
但是OOD score可以跟ppx互相补充,从而形成一个比较好的对应指标:
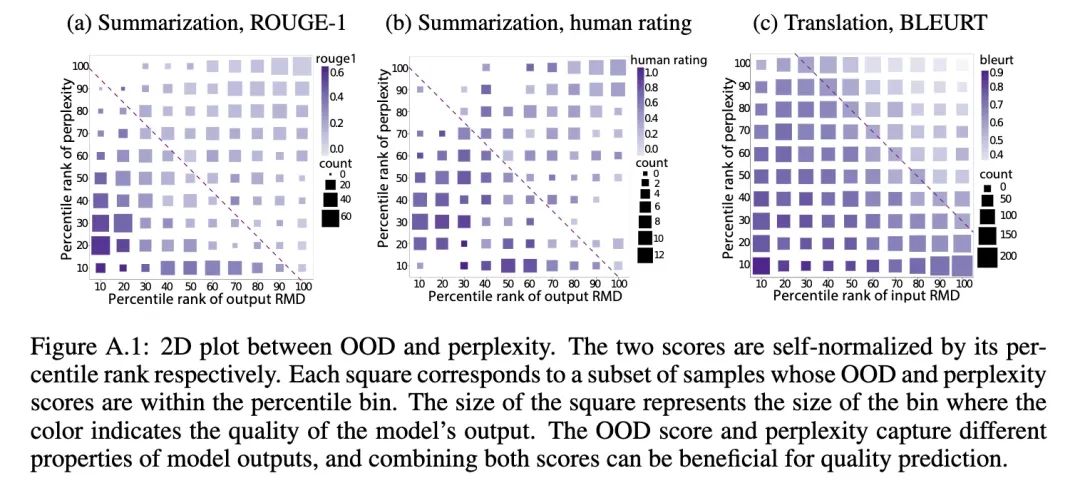
单独只考察ppx或者RMD OOD score的话,难以区分质量的高低,但是同时考察二者,就有较高的区分度。究其原因,作者这么解释:
ppx反映的是由于内部噪音/模糊造成的的不确定性
RMD score反映的是由于缺乏训练数据所造成的不确定性
因此二者是互补的关系。
那么二者如何结合呢:
训练一个linear regression
或者直接使用二者的某种“和”:,其中PR代表percentile ranks
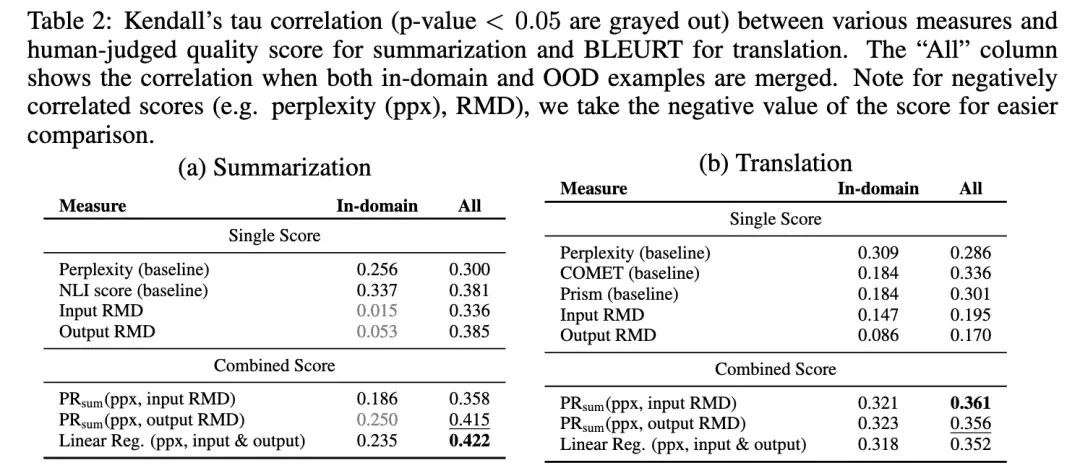
可以看出,这种二者结合的方法,比各种只用单个指标的baselines都能更好地反映生成的质量。
在selective generation阶段,设定一个遗弃比例,然后把quality score最低的那部分丢弃。
Key takeaways:
在生成模型中,ppx无论是作为OOD detection还是quality evaluation都是不太好的选择
基于模型的extracted feature来做OOD detection更好,文中的RMD score就是一个例子。
审核编辑:刘清
-
msp
+关注
关注
0文章
153浏览量
35309
原文标题:CMU&Google提出:条件语言模型中的OOD检测与选择性生成
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「基于大模型的RAG应用开发与优化」阅读体验】+Embedding技术解读
激光自身空间维度加工系统综述

发电机失磁对发电机自身的影响有哪些
怎么才能得到LM3886的输出阻抗?
INA237的内部I2C是否支持timeout将自身reset?
CYW4373E的两个clm_blob文件有何不同?
无法将blob文件下载到evb,为什么?
请问CYW4373是否支持Wi-Fi Enhanced Open (OWE)?
一种多重汗液传感贴片,实现精准的汗液分析
基于掩码模型的LiDAR感知模型预训练策略







 工商网监
工商网监
评论