 总线级数据中心网络技术
总线级数据中心网络技术
据Hyperion Research 公司按照系统验收的时间估算,2021至2026年期间,全球将建成28~38台E级或接近 E 级的超级计算机。
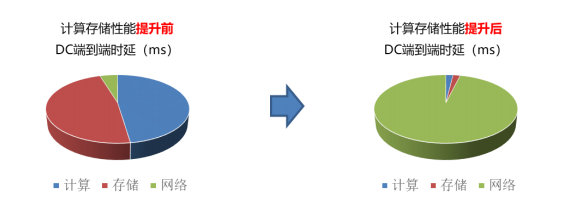
在原先传统数据中心内,计算存储性能未提升前,端到端的时延主要在端侧,即计算和存储所消耗的时延占比较大,而当计算存储器件性能大幅提升后,网络成为了数据中心内端到端的性能瓶颈。下图显示了计算存储性能提升前后,端到端时延的占比变化。
01RDMA 技术实现业务加速
但制式种类繁多
存储和计算性能提升后,数据中心内二者的访问时延已经从 10ms优化达到了 20us 的水平量级,相比原来有了近千倍的提升。而此时,如若仍旧采用基于 TCP 协议的网络传输机制,由于 TCP 的丢包重传机制,其网络时延仍旧维持在 ms 级水平,无法满足高性能计算存储对于时延的要求。此时,RDMA 技术的出现,为网络性能的提升提供了新的技术思路。
RDMA 是一种概念,在两个或者多个计算机进行通讯的时候使用 DMA, 从一个主机的内存直接访问另一个主机的内存。传统的 TCP/IP 技术在数据包处理过程中,要经过操作系统及其他软件层,需要占用大量的服务器资源和内存总线带宽,数据在系统内存、处理器缓存和网络控制器缓存之间来回进行复制移动,给服务器的 CPU 和内存造成了沉重负担。尤其是网络带宽、处理器速度与内存带宽三者的严重“不匹配性”,更加剧了网络延迟效应。
RDMA 是一种新的直接内存访问技术,RDMA 让计算机可以直接存取其他计算机的内存,而不需要经过处理器的处理。RDMA 将数据从一个系统快速移动到远程系统的内存中,而不对操作系统造成任何影响。
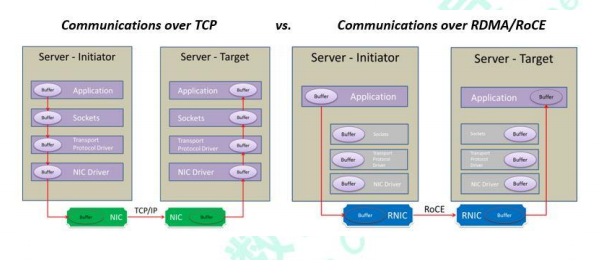
在实现上,RDMA 实际上是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术,通过将 RDMA 协议固化于硬件(即网卡)上,以及支持 Zero-copy和 Kernel bypass 这两种途径来达到其高性能的远程直接数据存取的目标。下图为 RDMA 工作的原理图,其通信过程使得用户在使用 RDMA 时具备如下优势:
➢零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
➢内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
➢不需要 CPU 干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何 CPU。远程主机内存能够被读取而不需要远程主机上的进程(或 CPU)参与。远程主机的 CPU 的缓存(cache)不会被访问的内存内容所填充。
➢消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
➢支持分散/聚合条目(Scatter/gather entries support) - RDMA 原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
目前,RDMA 技术在超算、AI 训练、存储等多个高性能场景大量部署,已形成广泛应用。但是 RDMA 技术路线也有很多,用户及各家厂商对于 RDMA 技术路线的选择也不尽相同。
在三种主流的 RDMA 技术中,可以划分为两大阵营。一个是 IB 技术, 另一个是支持 RDMA 的以太网技术(RoCE 和 iWARP)。其中,IBTA 主要聚焦 IB 和 RoCE 技术,而 iWARP 则是在 IEEE/IETF 标准化的技术。在存储领域,支持 RDMA 的技术早就存在,比如SRP(SCSI RDMA Protocol)和iSER(iSCSI Extensions for RDMA)。如今兴起的 NVMe over Fabrics 如果使用的不是 FC 网络的话,本质上就是 NVMe over RDMA。换句话说,NVMe over InfiniBand, NVMe over RoCE 和 NVMe over iWARP 都是 NVMe over RDMA。
02RoCE 成为主流
但仍难以满足业务需求
以太网自面世以来,其生态开放多元、速率高速增长、成本优势明显,因此业界应用十分广泛。在 RDMA 的多种技术路线中,RoCE 技术的应用最为广泛。在全球著名高性能计算榜单 Top500 中,以太互联技术占比超过一半。
然而受限于传统以太网络的性能瓶颈,一般的 RoCE 应用在高性能业务中,仍然存在拥塞丢包、延迟抖动等性能损失,难以满足高性能计算和存储的需求。
在高性能存储集群中,FC 网络具备连接保持技术,网络升级&进程故障业务不感知,同时 FC 协议长帧头具备传输功能保障,协议开销小,网络无丢包,数据帧按序传送,网络可靠、时延低。相比 FC,传统以太网容易出现拥塞丢包现象,丢包重传容易产生数据乱序,网络抖动较大,并且以太网采用的存储转发模式,查找流程较为复杂导致转发时延较高,多打一场景会导致队列积压加剧,队列时延不可忽视。在 HPC 应用中,传统以太消息封装能力较弱,查表流程复杂导致转发时延较高,网络的传输损失会造成处理器空闲等待数据,进而拖累整体并行计算性能,根据 2017 年 ODCC 组织的测试结果,传统以太和专网相比,在超算集群应用下,性能最高相差 30%。
03总线级数据中心网络
DCN全以太超融合发展
高性能计算在金融、证券、教育、工业、航天、气象等行业广泛应用,而时延是关键性能指标之一。由于以太网丢包、传输转发机制等诸多原因,基于传统以太的数据中心网络时延大多处于毫秒级水平,无法支撑高性能计算业务。要使得 DC as a Computer 成为可能,数据中心网络时延需要向总线级看齐。
04总线级数据中心网络内涵
传统以太时延较高,无法满足以高性能计算的性能要求。更为严峻的是,当前我国高性能存储和高性能计算所采用的高端网络互联设备,均被国外厂商垄断,价格昂贵、专网设备互通性差,并存在关键供货被卡脖子的风险。
由于以太网的丢包、传输、转发等诸多原因,传统的数据中心网络时延大多处于 ms 级水平,无法支撑高性能计算业务。随着高性能业务的飞速发展,计算设备已由原先以 CPU 为代表的通用器件,转而发展为以 GPU 为主的高性能器件,器件的性能大幅提升,这对以太网络的性能提出了更高的要求。网络时延由四部分组成:
动态时延:主要由排队时延产生,受端口拥塞影响;
静态时延:主要包括网络转发(查表)时延和转发接口时延,一般为固定值,当前以太交换静态时延远高于超算专网;
网络跳数:指消息在网络中所经历的设备数;
入网次数:指消息进入网络的次数。总线级数据中心网络在动态时延、静态时延、网络跳数以及入网次数几个方面均作出了系统性的优化,大幅优化了网络性能,已满足高性能计算场景的实际诉求。
05极低静态转发时延技术,
转发时延从us降至百ns
传统的以太交换机在转发层面,因需要考虑兼容性、支持众多协议,导致转发流程复杂,转发时延较大。与此同时,以太查表算法复杂、查表时延大,导致整体转发处理时延长。目前业界主流商用以太交换机的静态转发时延大约在600ns-1us 左右。面向大数据存储和高性能计算业务,若要以太网做到低时延,必须优化转发流程,降低数据转发时延。
总线级数据中心网络技术提出了一种极简低时延以太转发机制,利用虚拟短地址,实现了快速线性表转发。基于虚拟地址路由转发技术,解决了传统二层环路和链路利用率的问题,同时保证了规模部署和扩展灵活性。
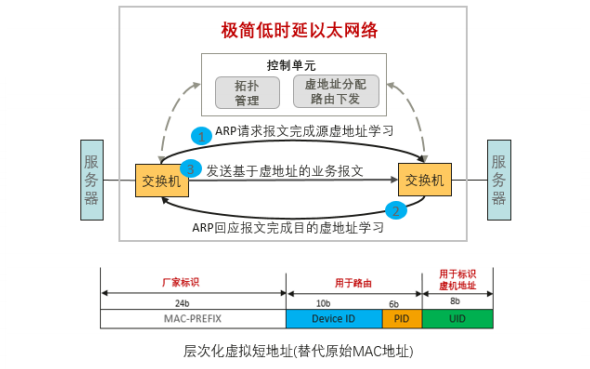
根据应用实测,目前低时延机制转发机制能实现 30ns 以太芯片报文处理,实现 100ns 左右端到端单跳转发静态时延。该时延相比于业界主流欧美厂商的以太芯片转发时延,提升了 6-10 倍。
06Bufferless 无阻塞流控技术,
亚us级动态时延
网络拥塞会引起数据包在网络设备中排队甚至导致队列溢出而丢弃,是导致网络高动态时延的主要原因。
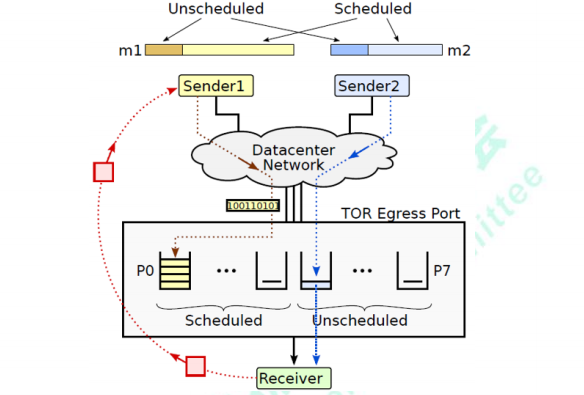
总线级数据中心网络技术创新提出了收发混合驱动的网络拥塞控制机制。数据报文分为无调度(Unscheduled)和有调度(Scheduled)两类:无调度报文在端口级有限窗口控制下直接发送,快速启动,保证高吞吐;有调度报文由接收端分配令牌报文(Token)后继续发送,限制流量注入,提供(近似)零队列,支撑更大的网络规模。对两类报文进行协同调度,进一步保证高吞吐低队列。收发混合驱动的网络拥塞控制机制实现了数据中心网络高吞吐和近似零队列,支撑大规模网络动态实时无阻塞。
最大吞吐保证:仅优先发送部分报文,同样提供最大吞吐保证。
极低平均队列时延:通过接收端调度,严格控制网络注入流量,保证接近于0的平均队列时延。
极低最大队列时延:对于不由接收端调度的报文,通过窗口限制注入流量,不会出现大幅震荡,保证最大队列时延极低。
07DCI 长距无损技术动态时延,
100KM内长距无损
在高性能存储业务使用环境中,数据中心交换机之间涉及到远端设备之间的拥塞问题。传统的链路层流控技术采用粗暴的“停等”机制,当下游设备发现接收能力小于上游设备的发送能力时,会主动发 Pause 帧给上游设备,要求暂停流量的发送。若采用传统的流控机制,数据中心网络远端设备之间的流控会导致极高时延,以 100km 举例,100Gbps 传输速率为例,基于传统的 PFC 机制的设备间流控机制会产生将近 2ms 的时延,无法满足高性能应用的性能要求。
针对这个问题,总线级数据中心网络提出了“点刹”式长距互联的流控机制。采用细粒度的周期性扫描方式进行流控;每个周期检测入口 buffer 的变化速率,通过创新算法计算要求上游停止发送时间;构造反压帧,发送给上游设备,包含了要求上游停止发送的时间。
08网络新拓扑架构路由技术,
大规模组网实现跳数下降20%
针对高性能计算场景,数据中心的流量特征关注静态时延,需要支持超大规模,传统的 CLOS 架构作为主流的网络架构,其主要关注通用性,但是牺牲了时延和性价比。业界针对该问题开展了多样的架构研究和新拓扑的设计。
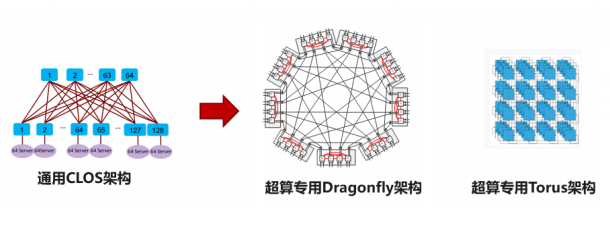
当前数据中心网络架构设计大多基于工程经验,不同搭建方式之间难以选择,缺乏理论指导,缺乏统一性设计语言。另外网络拓扑性能指标繁多,不同指标之间相互制约,指标失衡很难避免。
09网算一体技术,
减少入网次数提升通信效率
随着分布式集群规模的增大,以及单节点算力的增长,分布式集群系统已经逐渐从计算约束转换为网络通信约束。一方面,在过去 5 年,GPU 算力增长了近90 倍,而网络带宽仅增长了 10 倍;另一方面,当前的集群系统中,当 GPU 集群达到一定规模以后,即使增加计算节点数,但由于分布式集群节点之间通信代价的增加,仍可能导致集群每秒训练的图片数量不增反减。
10总结与展望
数据中心集合了极其丰富的软硬件资源,从芯片到服务器,从存储设备到网络设施,从平台软件到应用软件,不一而足。要构建强大算力,各类资源需要高度协同,深度融合。超融合正在成为下一代数据中心网络架构的内涵与精髓,政府、金融、运营商、互联网等行业存在巨大的融合需求。
可以预见,未来超融合数据中心网络与垂直行业的结合将会更加紧密。在这个长期的探索过程中,超融合数据中心网络迈出了坚实的一步。基于总线级数据中心网络技术的超融合数据中心打破了异构协议间的屏障,提升数据跨资源的流通和处理效率,提高算力能效比。在全国一体化大数据中心建设的今天,必将为数据中心新基建的发展提供网络性能的坚实保障。
审核编辑 :李倩
-
总线
+关注
关注
10文章
2870浏览量
87998 -
数据中心
+关注
关注
16文章
4702浏览量
71974 -
RDMA
+关注
关注
0文章
76浏览量
8929
原文标题:总线级数据中心网络技术
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Meta AI数据中心网络用了哪家的芯片
当今数据中心新技术趋势
戴尔科技如何帮助巴克利改造升级数据中心
数据中心液冷需求、技术及实际应用
CXL技术:全面升级数据中心架构













 工商网监
工商网监
评论