 Cerebras的实力 用整块晶圆做的大芯片
Cerebras的实力 用整块晶圆做的大芯片
Cerebras以设计晶圆级别的芯片闻名,CS-2由世界最大芯片Cerebras WSE-2处理器提供动力(WSE-2将2.6万亿个晶体管和85万个内核装在一块餐盘大小的晶圆上)。
在 SC22 上,Cerebras 展示了我们很少看到的东西,即其 CS-2 计算平台的核心,即引擎块。就此而言,我们不仅仅指的是我们之前多次看到的该公司的巨型 WSE-2 芯片。相反,是围绕着一个巨大芯片的东西让它运转起来。
当我们讨论 Cerebras 产品时,我们要么讨论两种观点中的一种。第一个是该公司销售的 CS-2 系统。
我们通常讨论 Cerebras 产品的第二种方式是根据其巨大的芯片或其 Wafer-Scale Engine-2。
尽管如此,从一个巨大的人工智能芯片到一个系统并不是一件容易的事。这就是在 SC22 上展示的内容。
在展会上,该公司展示了看起来像一堆金属的东西,上面有一些 PCB 伸出来。该公司称其为发动机缸体。在我们之前与 Cerebras 的讨论中,这是一项巨大的工程壮举。弄清楚如何封装、供电和冷却这个巨大的芯片是一项关键的工程挑战。让代工厂制造特殊晶圆是一回事。让晶圆开启而不是过热并做有用的工作是另一回事。
当我们谈论服务器由于密度而不得不转向液体冷却时,我们谈论的是 2kW/U 服务器或者可能是带有 8x 800W 或 8x 1kW 部件的加速器托盘。对于 WSE/WSE-2,所有的电力和冷却都需要输送到一个大晶圆上,这意味着即使是不同材料的热膨胀率等因素也很重要。另一个含义是该组件上的几乎所有部件都采用液冷方式。
我们的一些读者可能会在底板上的配件上看到文字。这是配件上的 Koolance 标签,供有兴趣的人使用。)
最上面一排木板非常密集。展位上的 Cerebras 代表告诉我,这些是有意义的电源,因为我们看到它们的连接器密度相对较低。
在 SC22 上展示 CS-2 发动机缸体的方式对某些人来说可能看起来很奇怪。这就是发动机缸体位于系统后部的方式(CS-2 是“后置发动机超级计算机”?):
这个用整块晶圆做的芯片,性能超乎想象
Cerebras Systems 及其晶圆级硬件由于其完全非传统的制造方法在业界引起了轰动。他们没有像 AI 中的所有其他参与者一样构建一个专用于机器学习的大芯片,而是瞄准了一个完全不同的扩展途径。他们奉行将整个晶圆制成单个芯片的策略。该硬件已显示出令人惊讶的多功能性,甚至在其他高性能计算应用程序中也取得了突破性进展。
这是由一个简单的观察结果驱动的,即摩尔定律已经显著放缓。大幅增加晶体管数量的唯一途径是增加每个芯片中的硅数量。Cerebras 正在开发他们的第二代产品 Cerebras WSE-2。该芯片的尺寸为 215mm x 215mm。

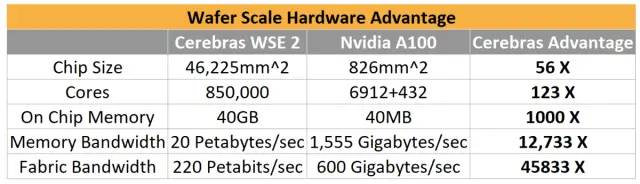
与可用的最大 GPU Nvidia A100 相比,Cerebras 取得了巨大的优势,尤其是在将片上 40GB 的内存带宽与 A100 的类似大小的 HBM 内存进行比较时。Cerebras 拥有令人难以置信的高结构带宽,远远超过 GPU 到 GPU 的互连。
Cerebras 通过在水冷机箱中提供它来驯服他们的 20KW 野兽。作为参考,Nvidia A100 的功率范围从 250W 到 500W,具体取决于配置。在创建这种冷却解决方案时必须特别小心。由于该芯片的尺寸和功耗,诸如硅和其他组件的不同热膨胀等问题成为主要问题。

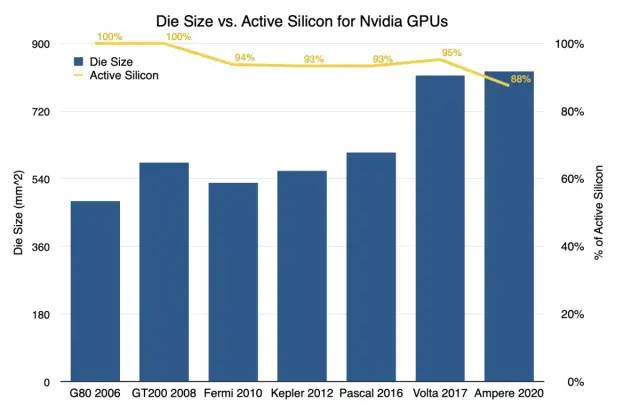
长期以来,半导体制造受限于裸片尺寸,一直受到掩模版的限制。掩模版限制为 33×26,这意味着这是 ASML 的光刻浸入式步进器可以在晶片上图案化的最大尺寸。Nvidia 最大的芯片都在 800mm^2 的低范围内,主要是因为超越这个范围是不可能的。
Cerebras WSE 实际上是在掩模版限制范围内的晶圆上的许多芯片。他们没有沿着芯片之间的划线将芯片切割开,而是开发了一种跨芯片线的方法。这些导线与实际芯片分开图案化,并允许芯片相互连接。实际上,芯片可以扩展到超出掩模版的限制。
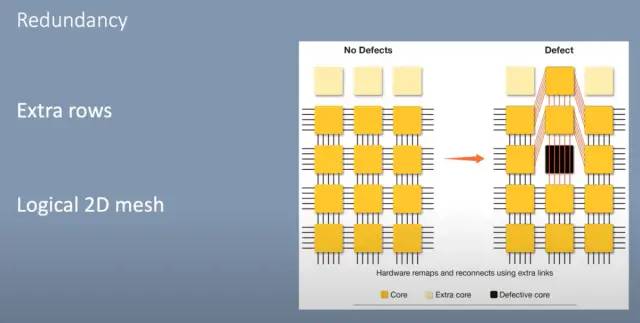
以经典方式构建芯片时,通常会存在缺陷。因此,必须丢弃来自每个晶片的多个芯片或必须禁用芯片的元件。Nvidia 通常将这种做法用于他们的 GPU。每一代都存在禁用更大比例内核的持续趋势,而在当前一代 Ampere 中,大约有 12% 的内核被禁用。
Cerebras 通过在每个标线子芯片(reticle sub-chip)上添加 2 行额外的核心来解决这个问题。这些芯片内的互连是 2D 网格,其中每个核心在垂直和水平方向上连接。它们还为每个对角线核心提供额外的互连。这允许对有缺陷的核心进行布线,并且软件仍然可以识别 2D 网格。

在这个 2D 网格中,Cerebras 设定了几个目标。他们希望所有内存都保留在芯片上,而不必等待片外内存缓慢。唯一的外部连接是到主机系统。每个内核都有细粒度的并行性(fine grained parallelism ),彼此之间不共享任何内容。它们是具有 MIMD 能力的节能通用内核,并拥有自己的本地存储器。
主要用例是机器学习训练或推理。网络层被映射到晶片大小的芯片区域。每个矩形块对应一个层,有趣的是这被称为“Colorado”。卷积、矩阵向量和矩阵乘法是在每一层的核心上计算的。2D 网格处理网络每一层内和网络层之间的核心间通信。
大多数通信通常在沿芯片的 X 或 Y 方向进行,但有些通信需要跨越芯片的大部分。网格可以处理这个而不会变得拥挤。这允许网络中的层不必是连续的或彼此直接相邻。Cerebras 软件堆栈放置和路由这些层,同时保持核心和结构的高利用率。该软件能够在单个芯片上仅放置几层网络,或者在芯片上放置整个网络的多个副本,以实现数据并行。
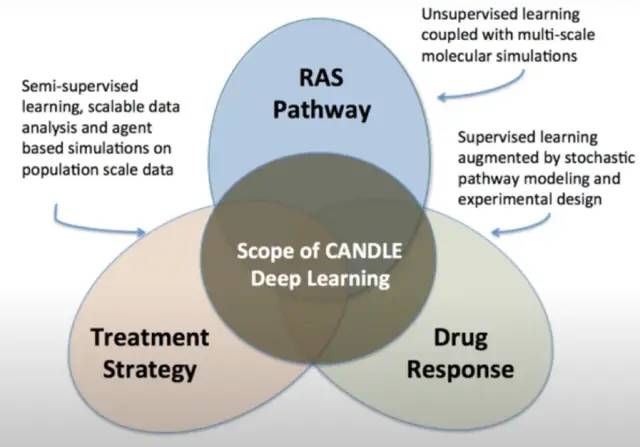
Cerebras 的客户拥有实时生产的晶圆级引擎。这些用于许多不同的工作负载,但最有趣的一种是 CANDLE。WSE 用于精确模拟药物组合的药物反应及其对癌症的影响。然后选择最有希望的模拟结果进行实验研究。
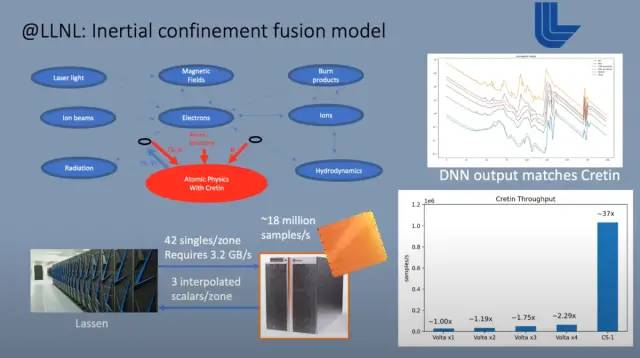
目前在这些芯片上运行的另一个用例是内部限制融合。它运行在一台大型超级计算机上,该计算机还包含多个互连的 Cerebras WSE。这种大规模模拟的组成部分之一涉及原子和亚原子粒子之间的相互作用。该计算被一个在 Cerebras 硬件上运行的大型预训练神经网络所取代。这是一个仅使用推理的用例。它在模拟的每个时间步中都会被唤起。数据从较大的超级计算机流式传输到 Cerebras WSE,后者又为这些原子和亚原子交互提供输出。
Cerebras 硬件也不仅仅用于机器学习。Joule 超级计算机在 3D 网格中运行的传统硬件上运行计算流体动力学。他们以两种不同的方式遇到了扩展问题。由于网络带宽的限制,他们无法通过核心数量来提高性能。此外,由于缓存未命中,内核通常会在表上留下很多性能,从而导致内存不足。该内存随后遇到了巨大的带宽瓶颈。
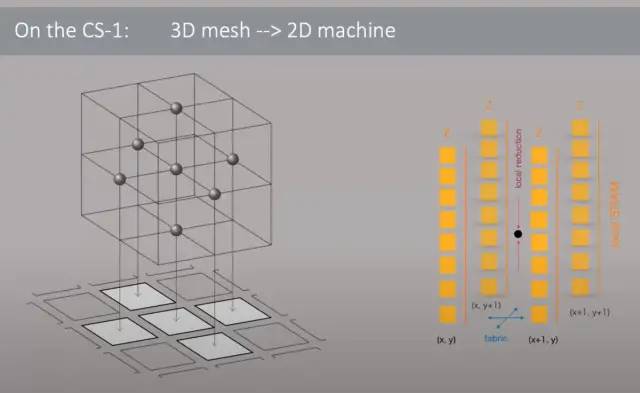
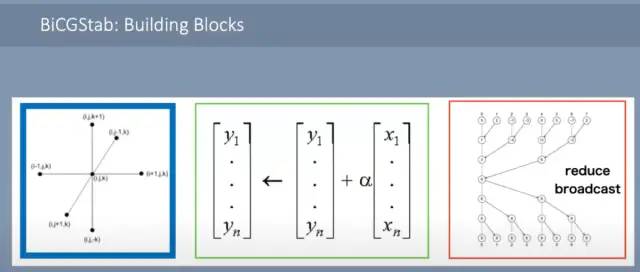
流体动力学模型的 3D 网格被映射到 WSE 芯片的 2D 网格。邻居交换、向量 AXPY 和全局向量的点积,这需要局部点积和全局 all-reduce。由于大量的 SRAM 和每个单独内核的相对较高的复杂性,所有这些操作都可以轻松处理。

有大量的内核间通信,但片上内部网络足够强大,可以以低延迟处理它们。网络通过沿着称为“颜色”的虚拟通道而不是预先确定的地址发送消息来实现这一点。这种基于硬件的通信允许数据在整个芯片上每时钟传输 1 跳。
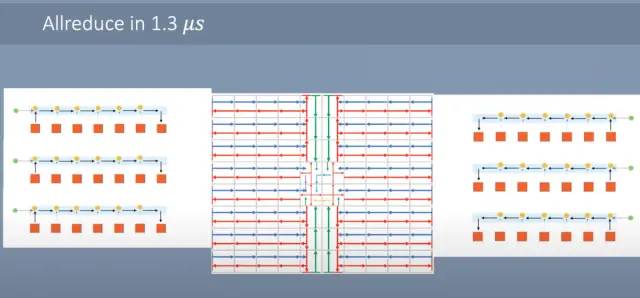
Allreduce 可以非常快地完成。每个内核将其标量发送到它旁边的内核。当它到达那里时,标量被加在一起并向前发送。芯片的边缘向东/西向中心发送数据。一旦它到达中心,就会发生同样的过程,但北/南。结果被合并,然后在核心网格上广播回来。只需1微秒,就可以完成这个allreduce。作为参考,超级计算机中的典型集群从一个处理器到另一个相邻处理器的单个 MPI 通信需要大约这么长时间。
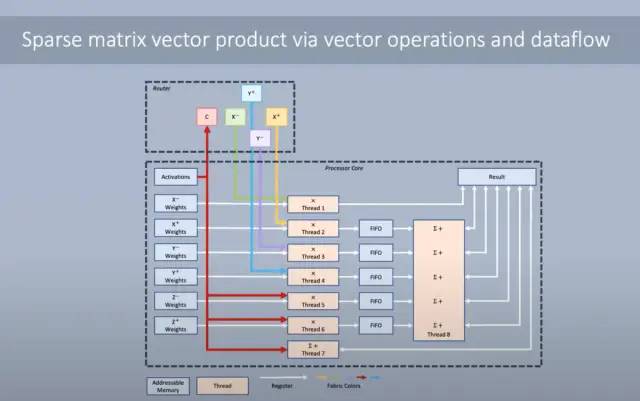
无论引入数据的延迟如何,都可以进行计算以实现全带宽。路由器具有来自每个相邻核心的 4 个传入数据集。此外,内核可以将其输出重新路由回,这样就不需要将其存储在 SRAM 中。内核可以同时运行多个线程。有一个主线程被赋予优先级,但是如果它在等待数据,其他线程就会前进。通过使用大量 SRAM 和多线程架构保持数据局部性,利用率保持极高。
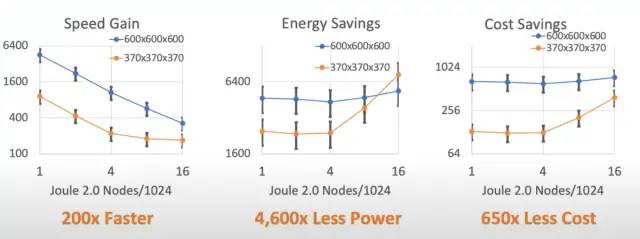
对硬件进行低级优化的结果使计算流体动力学速度提高了 200 倍。这与同样高度优化的大型超级计算机集群相比。除了速度上的提升,成本,尤其是功耗,也有着巨大的优势。这种优势在某种程度上是显而易见的,因为将超级计算机集群与单个(尽管是晶圆大小)芯片进行比较。

不幸的是,软件还没有完全符合要求。Beta SDK 将于今年晚些时候推出,用于编写自定义内核操作。这种语言将完全特定于 WSE 的领域。他们将拥有数学函数和通信库,有望在一定程度上减轻负担。除此之外,还有一些功能和工具会有所帮助,但这将是高技能程序员的任务。这是唯一可以实现这种计算规模的硬件,因此对于那些需要这种性能水平的任务来说,它可能不是进入的巨大障碍。
Cerebras 将实时计算流体动力学作为利用 WSE 的下一个工作负载。有相当大的希望,这将打开一个全新的用例。
我们很高兴基于 7nm 的 WSE2 全面推出。看看 SDK 是否可以允许开发人员生成其他工作负载,WSE 可以带来数量级的性能提升,这将是令人兴奋的。人工智能是 Cerebras 积极进取的领域,但晶圆级计算可能会改变这个行业,而不仅仅是机器学习。
-
芯片
+关注
关注
455文章
50791浏览量
423486 -
晶圆
+关注
关注
52文章
4909浏览量
127967 -
人工智能
+关注
关注
1791文章
47258浏览量
238418 -
计算平台
+关注
关注
0文章
52浏览量
9623 -
AI芯片
+关注
关注
17文章
1886浏览量
35014
原文标题:Cerebras展示用整块晶圆做的大芯片
文章出处:【微信号:TenOne_TSMC,微信公众号:芯片半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
晶圆背面涂敷工艺对晶圆的影响
为什么晶圆是圆的?芯片是方的?

晶圆/晶粒/芯片之间的区别和联系
Cerebras提交IPO申请,估值达41亿美元
碳化硅晶圆和硅晶圆的区别是什么
AI初出企业Cerebras已申请IPO!称发布的AI芯片比GPU更适合大模型训练
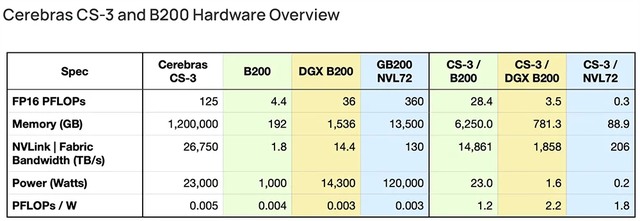
Cerebras Systems推出迄今最快AI芯片,搭载4万亿晶体管

TC WAFER 晶圆测温系统 仪表化晶圆温度测量

芯片制造全流程:从晶圆加工到封装测试的深度解析





 工商网监
工商网监
评论