 CXL对数据中心的意义
CXL对数据中心的意义

CXL(Compute Express Link)将成为一种变革性技术,将重新定义数据中心的架构和构建方式。这是因为 CXL 为跨芯片的缓存一致性、内存扩展和内存池提供了标准化协议。在本文中,我们将重点介绍微软正在做的事情,以帮助大家了解CXL对数据中心的意义。
数据中心是一件非常昂贵的事情。微软表示,他们高达50% 的服务器成本仅来自 DRAM。所需的资本支出是巨大的,但您构建的服务器并不是同质的。工作负载不是静态的。它们在不断地成长和进化。计算资源、DRAM、NAND 和网络类型的组合将根据工作负载而变化。
一刀切的模式是行不通的,这就是为什么您会看到云提供商拥有数十种甚至数百种不同的实例类型。这些正在尝试针对不同的工作负载优化硬件产品。即便如此,许多用户最终还是为他们真正不需要的东西付费。
实例选择并不完美,这些实例与硬件的匹配也不完美。随之而来的是平台级内存搁浅问题。服务器配置为不合适的实例类型场景。
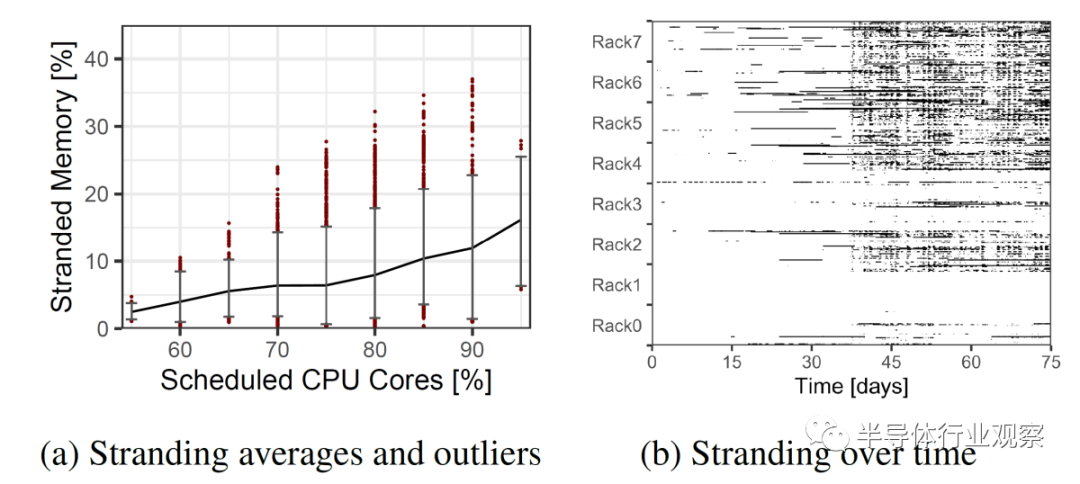
这个问题的解决方案是内存池。多个服务器可以共享一部分内存,并且可以动态地将其分配给不同的服务器。与其过度地配置服务器,不如将它们配置为更接近平均 DRAM 与内核的比率,并且可以通过内存池来解决客户的过多 DRAM 需求。此内存池将通过 CXL 协议进行通信。未来,随着对 CXL 协议的修订,服务器甚至可以共享相同的内存来处理相同的工作负载,这将进一步减少 DRAM 需求。
拥有大规模应用程序的复杂运营商可以通过向其开发人员提供具有不同带宽和延迟的多层内存来解决这个问题。这对于亚马逊、谷歌、微软和其他公司运营的公共云环境来说是站不住脚的。
Microsoft 概述了与公共云环境中的内存池有关的 3 个主要功能挑战。无法修改客户工作负载,包括guest操作系统。内存池系统还必须与虚拟化加速技术兼容,例如直接将 I/O 设备分配给 VM 和 SR-IOV。池化还必须可用于商用硬件。
在过去他们也试过内存池,但它需要自定义硬件设计、更改 VM guest并依赖页面错误。这种组合使其无法部署在云中。这就是 CXL 的用武之地。英特尔、AMD 和多个 Arm 合作伙伴已经加入了该标准。带有 CXL 的 CPU 将于今年晚些时候开始问世。此外,三星、美光和 SKHynix 三大 DRAM 制造商也都承诺支持该标准。
即使有硬件供应商的广泛支持,仍有很多问题需要回答。在硬件方面:应该如何构建内存池以及如何平衡池大小与较大池的较高延迟?在软件方面:如何管理这些池并将池暴露给guest操作系统,云工作负载可以容忍多少额外的内存延迟?
在分布层:提供者应如何在具有 CXL 内存的机器上调度 VM,内存中的哪些项目应存储在池中与直接连接的内存中,它们能否预测内存行为和延迟敏感性有助于产生更好的性能,如果是,准确度如何这些是预测吗?
微软提出了这些问题,并试图回答这些问题。我们将在这里概述他们的发现。他们的第一代的解决方案架构取得了令人印象深刻的成果。
随着未来 CXL 版本的推出和延迟降低,这些收益可能会进一步扩大。
首先是硬件层。Microsoft 使用直接连接到 8 到 32 个插槽 CPU 的多端口外部存储器对此进行了测试。内存扩展是通过连接 CXL 的外部内存控制器 (EMC) 完成的,该控制器具有四个 80 位 ECC DDR5 池 DRAM 通道和多个 CXL 链路,以允许多个 CPU 插槽访问内存。此 EMC 管理请求并跟踪分配给各个主机的各个内存区域的所有权。
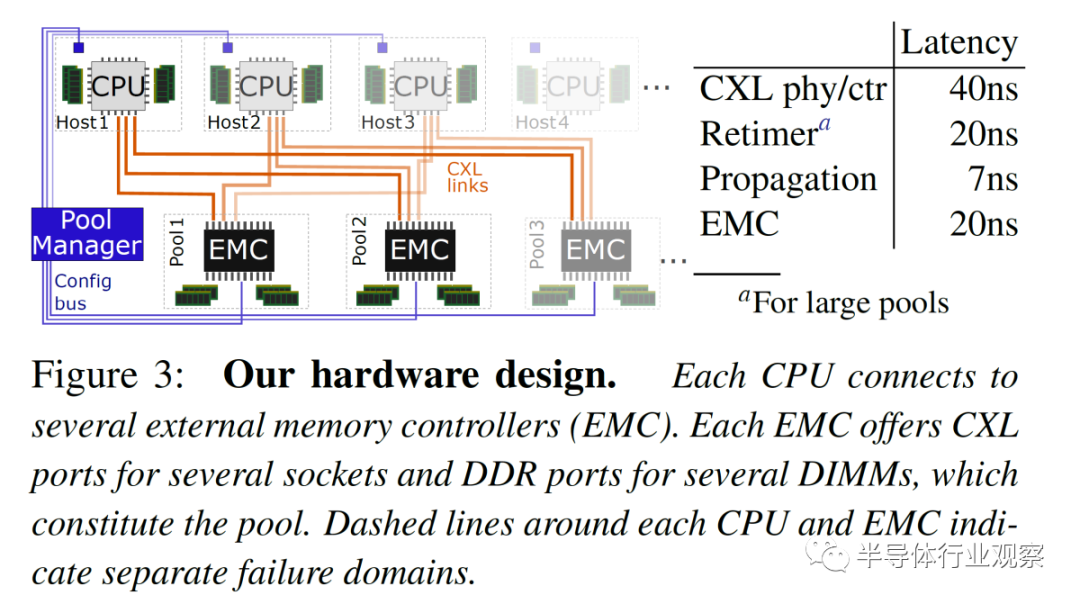
CXL x8 通道的带宽约为 DDR5 内存通道的带宽。每个 CPU 都有自己更快的本地内存,但它也可以访问具有更高延迟的 CXL 池化内存,相当于单个 NUMA 跃点。跨 CXL 控制器和 PHY、可选重定时器、传播延迟和外部存储器控制器的延迟增加了 67ns 到 87ns。
下图显示了当前本地 DRAM 的固定百分比(10%、30% 和 50%)切换到池化资源。池化内存与本地内存的百分比越大,节省的 DRAM 就越多。就 DRAM 节省而言,增加Socket数量会很快消失。
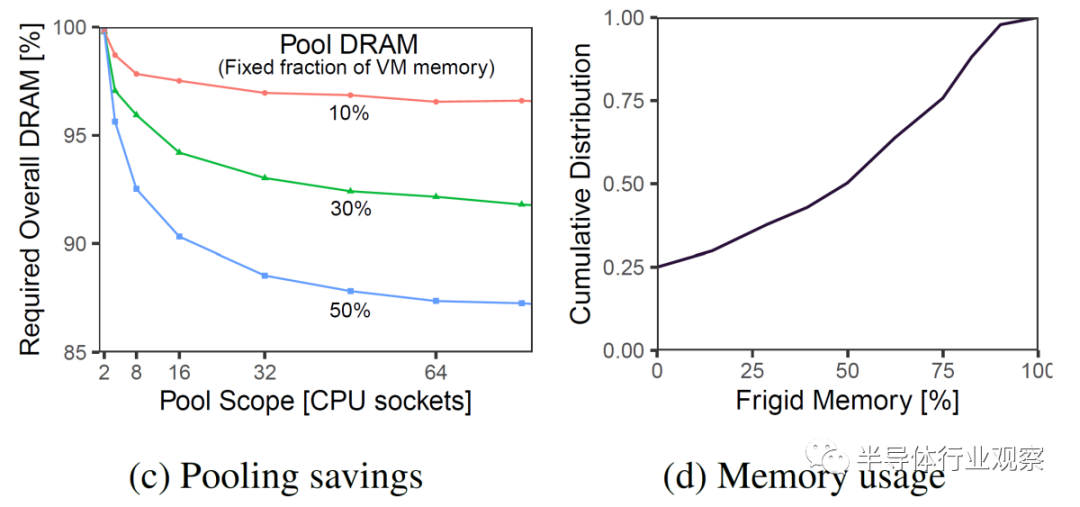
虽然更大的池大小和更多的socket看起来是最好的选择,但这里有更多的性能和延迟影响。如果池大小降为 4 到 8 个 CPU 插槽,则不需要重定时器。这将延迟从 87ns 降低到 67ns。此外,在这些较小的插槽数中,EMC 可以直接连接到所有 CPU 插槽。
更大的 32 个插槽池将 EMC 连接到不同的 CPU 子集。这将允许在更多数量的 CPU 插槽之间共享,同时保持 CPU 端口的 EMC 设备数量固定。这里需要重定时器,这导致每个方向的延迟为 10ns。
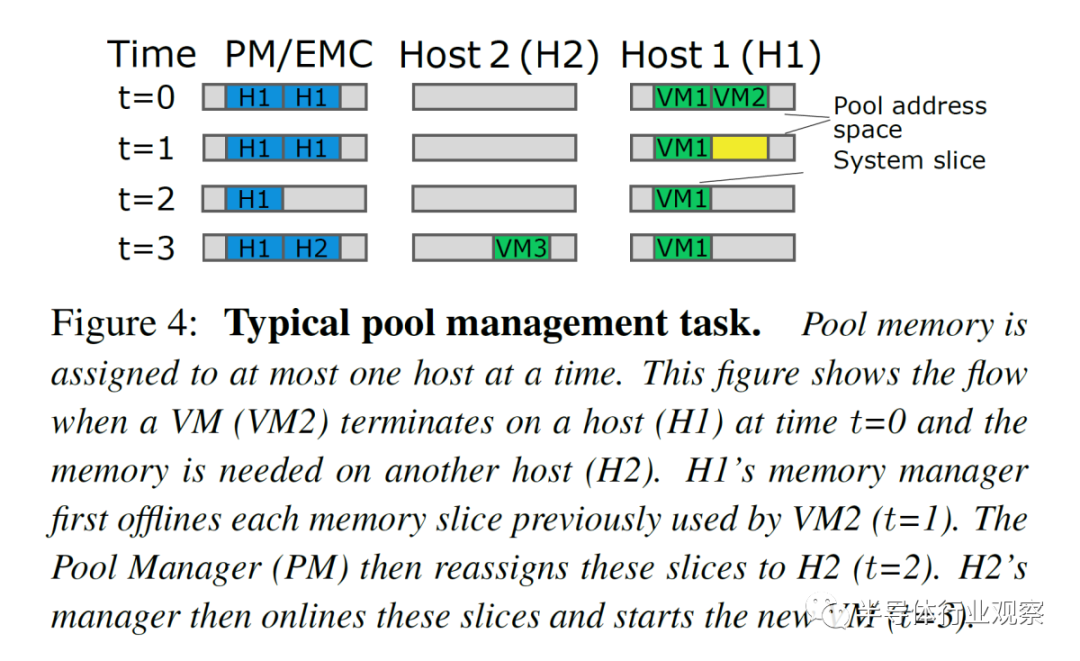
在软件方面,解决方案相当巧妙。
Microsoft 经常部署多插槽系统。在大多数情况下,VM 足够小,它们完全适合单个 NUMA 节点、内核和内存。Azure 的管理程序尝试将所有核心和内存放在单个 NUMA 节点上,但在极少数情况下(2% 的时间),VM 有一部分资源跨越socket。这不会暴露给用户。
内存池在功能上的工作方式相同。内存设备将作为零核虚拟 zNUMA 节点公开,没有内核,只有内存。内存偏离这个 zNUMA 内存节点,但允许溢出。粒度(granularity)是每片内存 1GB 。
分布式系统软件层依赖于对 VM 的内存延迟敏感度的预测。未触及的存储被称为“frigid memory”。Azure 估计第 50 个百分位的 VM 具有 50% 的冷(frigid)内存。这个数字似乎很圆。预计对内存延迟不敏感的 VM 完全支持池 DRAM。为内存敏感的 VM 配置了一个 zNUMA 节点,仅用于它们的冷内存。预测是在虚拟机部署时完成的,但它是异步管理的,并在检测到预测不正确时更改虚拟机放置。
这些算法的准确性对于节省基础设施成本至关重要。如果操作不当,性能影响可能会很大。
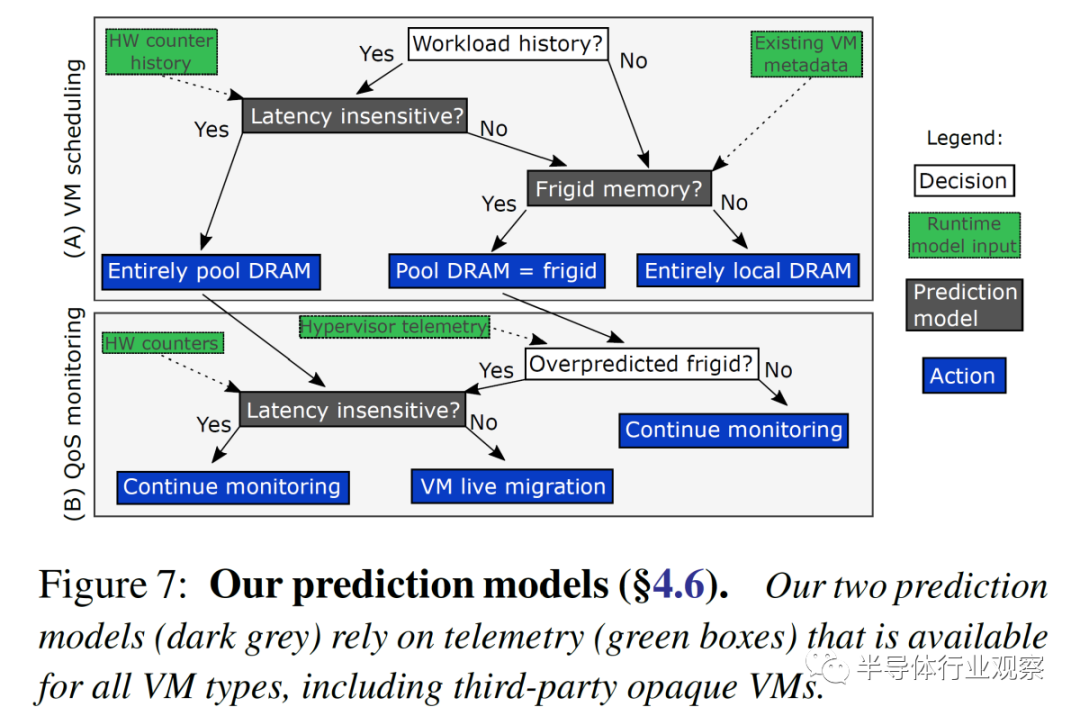
考虑到潜在的性能影响可能是巨大的,将云居民(cloud resident)的内存移动到 67ns 到 87ns 的池中是非常糟糕的。
因此,Microsoft 在两种情况下对 158 个工作负载进行了基准测试。一种是只有本地 DRAM 的控制。另一个是模拟 CXL 内存。应该强调的是,尽管英特尔早前声称其支持 Sapphire Rapids CXL 的平台将于 2021 年底推出。或者声称 Sapphire Rapids 将于 2022 年初推出。因此,微软必须模拟延迟影响。Microsoft 使用了 2 路 24C Skylake SP 系统。
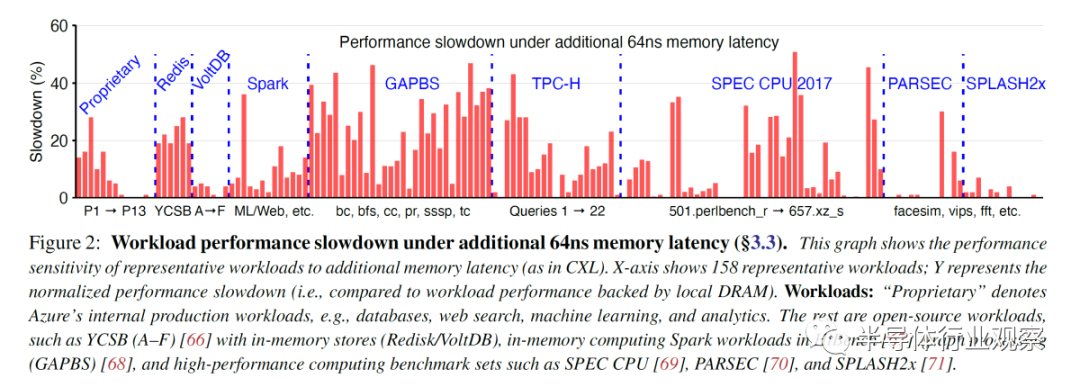
当带宽超过 80GB/s 时,内存访问延迟为 78ns。当一个 CPU 跨 NUMA 边界访问另一个 CPU 的内存时,会导致额外的 64ns 内存延迟。这非常接近外部存储设备 (EMC) 在低插槽数系统中的 67ns 额外延迟。
20% 的工作负载没有性能影响。另有 23% 的工作负载出现了不到 5% 的减速。25% 的工作负载严重减速,性能下降超过 20%,其中 12% 的工作负载甚至出现超过 30% 的性能下降。根据工作负载的本地与池内存量,该数字会发生相当大的变化。
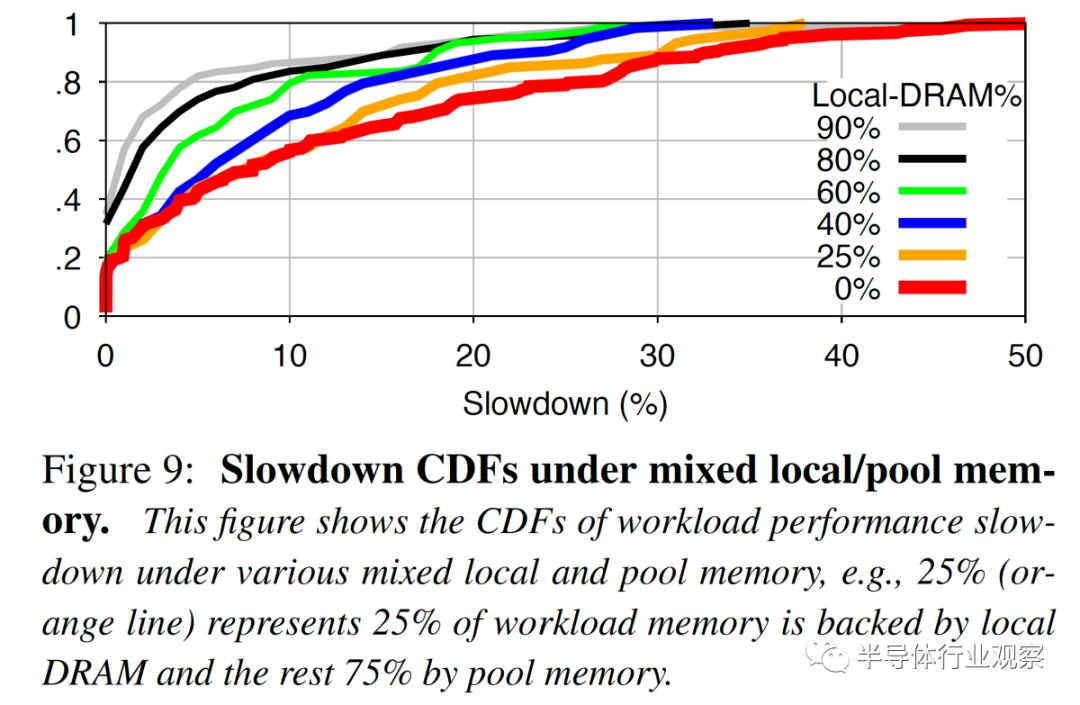
这进一步强调了预测模型的重要性。Microsoft 的基于随机森林(random forest) ML 的预测模型更准确,并且产生的误报减速更少。随着更多的内存被池化,越多变得越重要。
随着 CXL 规范的改进、延迟的降低和预测模型的改进,内存池节省的可能性可能会增长到云服务器成本的两位数百分比
审核编辑 :李倩
-
芯片
+关注
关注
463文章
54463浏览量
469619 -
NAND
+关注
关注
16文章
1766浏览量
141311 -
数据中心
+关注
关注
18文章
5780浏览量
75212
原文标题:为什么看好CXL?一文看懂!
文章出处:【微信号:IC学习,微信公众号:IC学习】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
高密度布线在数据中心建设中的挑战与应对策略
AOC光纤跳线在数据中心的应用与发展趋势


数据中心发展的三大驱动力
新思科技ZeBu助力富士通数据中心创新
人工智能数据中心的光纤布线策略
物联网数据中心是什么?有什么功能?
澜起科技推出CXL® 3.1内存扩展控制器,助力下一代数据中心基础设施性能升级
中型数据中心中的差分晶体振荡器应用与匹配方案
小型数据中心晶振选型关键参数全解
曙光数创SLiquid智能运维系统解决数据中心运维难题

数据中心液冷技术和风冷技术的比较



评论