 Arm NEON编程技术上手指南
Arm NEON编程技术上手指南
1 简介
本文旨在介绍Arm NEON技术,希望NEON初学者在阅读本文后能很快上手开始NEON编程。
2 NEON概览
本节介绍NEON技术及一些背景知识。
2.1 什么是NEON?
NEON是指适用于Arm Cortex-A系列处理器的一种高级SIMD(单指令多数据)扩展指令集。NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成)。
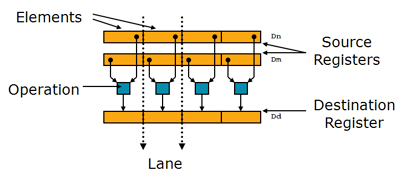
NEON 指令可执行并行数据处理:
寄存器被视为同一数据类型的元素的矢量
数据类型可为:8 /16 /32/64 位整数,单精度(Arm 32位平台),单精度浮点/双精度浮点(Arm 64位平台)
指令在所有通道中执行同一操作
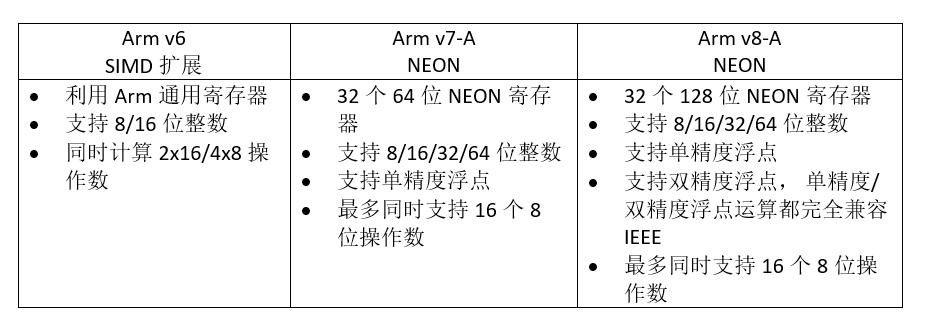
2.2 Arm 高级SIMD发展历史
2.3 为什么要用NEON
NEON提供:
支持整数和浮点操作,以确保适合从编解码器、高性能计算到 3D 图形等广泛应用领域。
与 Arm处理器紧密结合,提供指令流和内存的统一视图,编程比外部硬件加速器更简单。
3 Arm v8架构简介
Arm v8-A是一个非常重要的架构变化,它支持64位执行模式 “AArch64” ,并且带来了全新的64位指令集 “A64” 。同时,为了兼容Arm v7-A (32位架构)指令集,也引入了 “AArch32” 的概念。大部分Arm v7-A代码可以运行在Arm v8-A AArch32执行模式下。
本节会对Arm v8-A 架构NEON相关的特点做出一些介绍。此外,本节也会略微介绍在NEON编程时经常使用的CPU通用目的寄存器和CPU指令,但是重点依然是NEON技术。
3.1 寄存器
Arm v8-A AArch64有31个64位通用目的寄存器,每一个通用寄存器具有64位(X0-X30)或是32位模式(W0-W30)。其寄存器视图如下: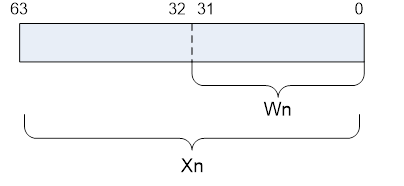
Arm v8-A AArch64有32个128位寄存器,也能当作32位Sn寄存器或是64位Dn寄存器使用。其寄存器视图如下:
3.2 指令集
Arm v8-A AArch32指令集是由A32(Arm指令,32 位固定长度指令集)和T32(Thumb指令集,16 位固定长度指令集;Thumb2指令集, 16/32位长度指令集)指令集组成。它是Arm v7 Cortex-A指令集的超集,因此Arm v8-A AArch32能后向兼容Arm v7-A以便运行早期软件。同时,为了维持与A64指令集的一致性,AArch32指令集又新增了NEON除法,加密指令扩展。
与AArch32指令集相比,AArch64指令集A64(32位固定长度)发生了很大变化,比如,它们具有完全不同的指令格式。但是在功能上来说,AArch64指令集基本上实现了AArch32指令集的全部功能,另外添加了NEON双精度浮点的支持。
3.3 NEON指令格式
现在大部分已经是Arm v8平台,因此本节只介绍AArch64 NEON指令格式。通用描述如下:
{
这里:
P:将向量按对操作,例如ADDP
V:跨所有的数据通道操作,例如FMAXV
2:在宽指令/窄指令中操作数据的高位部分。例如ADDHN2,SADDL2。
ADDHN2:两个128位矢量相加,得到64位矢量结果,并将结果存到NEON寄存器的高64位部分。
SADDL2:两个NEON寄存器的高64位部分相加,得到128-位结果。
下面列出具体的NEON指令例子:
UADDLP V0.8H, V0.16B
FADD V0.4S, V0.4S, V0.4S
更多内容请参考 Armasm_user_guide.pdf(http://infocenter.arm.com/help/topic/com.Arm.doc.dui0801g/DUI0801G_Armasm_user_guide.pdf)
13~15章介绍A32和T32指令。
16~20章介绍A64指令,其中第20章专门介绍NEON指令。
4 NEON编程基础
上面几章已经介绍了NEON的概念,硬件资源和指令集。现在我们可以开始使用NEON开始加速我们的应用了。使用NEON 技术通常有下列四种方式:
调用NEON优化过的库函数
使用编译器自动矢量化选项
使用NEON intrinsics指令
手写NEON汇编
4.1 调用库函数
用户只需要在程序中直接调用NEON优化过的库函数就可以了,简单易用。目前你有下列库可以选择:
Arm Compute library
一系列经过Arm CPU和GPU优化过的底层函数库。用于图像处理、机器学习和计算机视觉。更多信息: https://developer.Arm.com/technologies/compute-library
Ne10开源库
由Arm主导开发的,目前提供了比较通用的数学函数,部分图像处理函数,以及FFT函数。http://projectne10.github.io/Ne10/
4.2 自动矢量化
在GCC编译器选项中有自动矢量化编译选项可以帮助现有的代码编译生成NEON代码。GNU GCC提供一系列的选项,有的能提升性能,有的能降低生成可执行文件的代码大小。
对于每一行代码,有很多种汇编指令可以选择。编译器在寄存器、堆栈空间、代码大小、编译时间、便于调试、指令执行时间等许多选项中必须有所取舍,这样才能生成最优的映像文件。
4.3 NEON intrinsics
NEON intrinsics可以视作在NEON指令上面封装了一层接口。当用户在C程序中调用NEON intrinsics接口时,编译器会自动生成相关的NEON指令。
NEON intrinsics可以跨Arm v7-A/v8-A运行。只要编程一次,就可以借助编译器生成相应的NEON代码。
如果用户在代码中使用了Arm v8-A AArch64特有的NEON指令,只要如下例所示,用宏定义(__aarch64__)将这部分代码分隔即可。
下面是NEON intrinsics的一个例程。
//下面是浮点数组的加法,假设count为4的整数倍 #include通过查看反汇编,在Arm v7-A下,可以看到vld1/vadd/vst1 NEON指令。在Arm v8-A下可以看到ldr/fadd/str NEON指令。voidadd_float_c(float*dst,float*src1,float*src2,intcount) { inti; for(i=0;i< count; i++) dst[i] = src1[i] + src2[i]; } void add_float_neon1(float* dst, float* src1, float* src2, int count) { int i; for (i = 0; i < count; i += 4) { float32x4_t in1, in2, out; in1 = vld1q_f32(src1); src1 += 4; in2 = vld1q_f32(src2); src2 += 4; out = vaddq_f32(in1, in2); vst1q_f32(dst, out); dst += 4; // 下列代码只是描述如何使用AArch64专有代码的一个例子,不具有实际含义。 #if defined (__aarch64__) float32_t tmp = vaddvq_f32(in1); #endif } }
4.4 NEON汇编
NEON手写汇编主要有两种方式:
独立汇编文件
内嵌汇编
4.4.1 独立汇编文件
独立汇编文件可以用“.S”作为文件后缀,也可以用“.s”作为文件后缀。区别在于.S文件会经过C/C++预处理器处理,这样我们可以利用宏定义等C语言特性。
手写NEON汇编文件时,我们需要注意寄存器的保存。对于Arm v7/v8我们需要保存下列寄存器: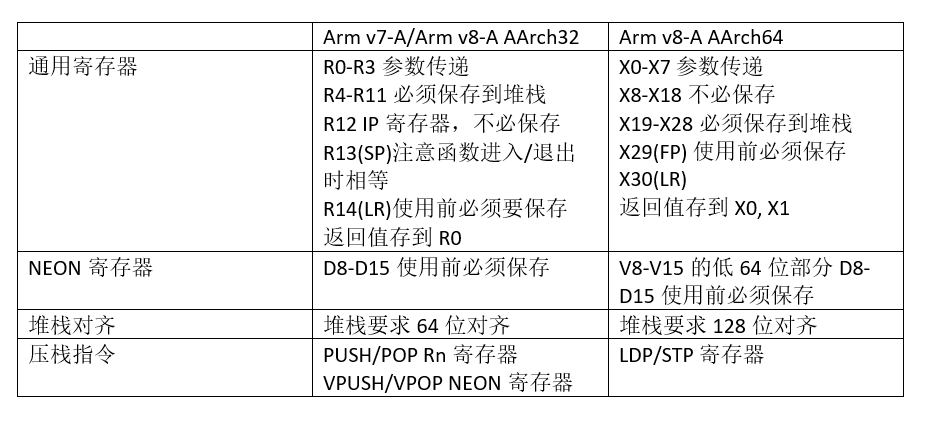
下面是Arm v7-A/v8-A NEON 汇编的一个例程。
//在头文件中定义 voidadd_float_neon2(float*dst,float*src1,float*src2,intcount);下面是手写汇编代码,保存到.S文件中
//Armv7-A/Armv8-AAArch32版本 .text .syntaxunified .align4 .globaladd_float_neon2 .typeadd_float_neon2,%function .thumb .thumb_func add_float_neon2: .L_loop: vld1.32{q0},[r1]! vld1.32{q1},[r2]! vadd.f32q0,q0,q1 subsr3,r3,#4 vst1.32{q0},[r0]! bgt.L_loop bxlr
//Armv8-AAArch64版本
.text
.align4
.globaladd_float_neon2
.typeadd_float_neon2,%function
add_float_neon2:
.L_loop:
ld1{v0.4s},[x1],#16
ld1{v1.4s},[x2],#16
faddv0.4s,v0.4s,v1.4s
subsx3,x3,#4
st1{v0.4s},[x0],#16
bgt.L_loop
ret
更多代码请参考: https://github.com/projectNe10/Ne10/tree/master/modules/dsp 4.4.2 内嵌汇编
顾名思义,内嵌汇编是和C代码紧密结合在一起的一种方式。我们可以直接把汇编代码内嵌在C/C++代码中,我们可以在需要NEON的地方即时添加。
优点:
过程调用规则简单,不需要自己手动保存寄存器。
可以使用 C/C++ 变量和函数,因此它能非常容易地整合到 C/C++ 代码
缺点:
内嵌汇编有一套复杂的语法规则
NEON代码内嵌在C/C++代码中,不易于移植到其他平台
例程:
//Armv7-A/Armv8-AAArch32
voidadd_float_neon3(float*dst,float*src1,float*src2,intcount)
{
asmvolatile(
"1:
"
"vld1.32{q0},[%[src1]]!
"
"vld1.32{q1},[%[src2]]!
"
"vadd.f32q0,q0,q1
"
"subs%[count],%[count],#4
"
"vst1.32{q0},[%[dst]]!
"
"bgt1b
"
:[dst]"+r"(dst)
:[src1]"r"(src1),[src2]"r"(src2),[count]"r"(count)
:"memory","q0","q1"
);
}
//Armv8-AAArch64
voidadd_float_neon3(float*dst,float*src1,float*src2,intcount)
{
asmvolatile(
"1:
"
"ld1{v0.4s},[%[src1]],#16
"
"ld1{v1.4s},[%[src2]],#16
"
"faddv0.4s,v0.4s,v1.4s
"
"subs%[count],%[count],#4
"
"st1{v0.4s},[%[dst]],#16
"
"bgt1b
"
:[dst]"+r"(dst)
:[src1]"r"(src1),[src2]"r"(src2),[count]"r"(count)
:"memory","v0","v1"
);
}
更多例程请参考libyuv 4.5 NEON intrinsics和NEON汇编
NEON intrinsics和NEON手写汇编是最常使用的NEON优化方式。
下面就这两种方式的优缺点做一些简单对比。
| NEON 汇编 | NEON intrinsic | |
|---|---|---|
| 性能 | 对于指定平台,汇编总是呈现最好性能。 | 现在的编译器已经能得到媲美手工汇编的性能。 |
| 可移植性 | Arm v7-A/v8-A平台 具有不同的汇编格式。即使在Arm v8-A平台,汇编程序可能也需要针对Cortex A53/A57微架构做出不同调整,才能呈现最好性能。 | 选择合适的编译器选项,一次编程即可以很容易实现跨平台并针对该平台微架构调整性能,例如Arm v7-A Cortex A9/A7/A15和Arm v8-A Cortex A53/A57。 |
| 可维护性 | 相比C语言,较难编程,可读性较差 |
跟C语言类似,比较容易编程与维护 |
这只是简单的优缺点对比,当应用NEON的情景比较复杂时,会有更多的特殊情况出现,在另一篇文章“Arm NEON 优化”中,我会对这个问题进行进一步分析。
有了以上基础,选择一种NEON实现方式,现在可以开始NEON编程之旅了!
审核编辑:刘清
-
ARM
+关注
关注
134文章
9079浏览量
367293 -
SIMD
+关注
关注
0文章
33浏览量
10288 -
NEON技术
+关注
关注
1文章
9浏览量
6078
原文标题:技术分享|Arm NEON编程快速上手指南
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用Arm Compiler 6自动矢量化功能为Neon编译
ModelSim快速上手指南
RT-Thread文档_RT-Thread 潘多拉 STM32L475 上手指南






 工商网监
工商网监
评论