 用于NAT的选择性知识蒸馏框架
用于NAT的选择性知识蒸馏框架
01
研究动机
在本文中,我们研究了一种能够高效推理的机器翻译模型NAT (Non-Autoregressive Transformer)[1]。相较于传统的Transformer,NAT能够在解码阶段并行预测,从而大幅提升模型的推理速度。此外,NAT可以使得模型在训练和测试阶段从相同的分布进行预测,从而有效避免了顺序解码模型中经常出现的exposure bias问题。在WMT21 news translation shared task for German→English translation中,已经有NAT模型在翻译质量上超过了许多顺序解码的模型。
尽管NAT在拥有许多潜在的优势,目前的工作中这类模型仍然在很大程度上依赖于句子级别的知识蒸馏(sequence-level knowledge distillation, KD)[2]。由于需要并行预测所有token,NAT对单词间依赖关系的建模能力较弱。这个特点使得在真实数据集上,NAT很容易受到multi-modality问题的影响:训练数据中一个输入可能对应多个不同的输出。在这样的背景下,Gu提出训练一个AT (Autoregressive Transformer)[3]模型作为老师,将它的输出作为NAT的学习对象。这种KD方式可以帮助NAT绕过multi-modality问题,从而大幅提升NAT的翻译表现。
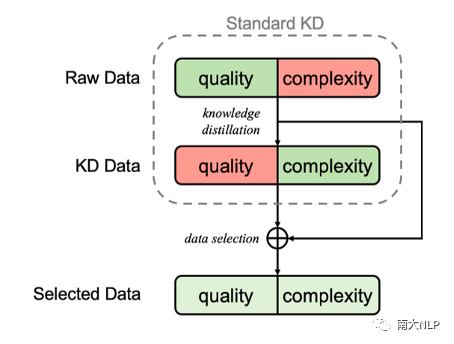
图1:Selective KD的流程示意图
KD在帮助NAT提升表现的同时,也会带来一些负面影响,例如模型在低频词上的准确率较低[4]、AT teacher的错误会传播到NAT上等。此外,如果NAT仅能在AT teacher的输出上学习,这类模型的翻译质量将很难有更进一步的突破。我们的研究希望能够在避免multi-modality的情况下,让NAT能够从真实的数据分布中学到知识蒸馏的过程中缺失的信息,从而提升NAT的表现。
为达到这样的目的,我们提出了selective KD:在KD数据上训练一个NAT作为评估模型,并通过它来选择需要蒸馏的句子。通过这种方式,我们可以让模型接触到翻译质量更高的真实数据,同时避免了严重的multi-modality情况。受课程学习的影响,我们也在训练过程中动态调整蒸馏数据的比例。“用评估模型有选择地蒸馏数据”和“动态调节蒸馏数据的比例”共同构成了我们的Selective KD训练框架。
02
解决方案
2.1评估模型
我们首先将数据蒸馏产生的结果划分为四种不同的情况:
较轻的modality change:某些单词可能被替换为同义词,句式和语义并没有发生显著的变化
较轻的错误:在保持原有句式和语义的情况下,发生了一些小错误,例如单词重复
严重的modality change:语义不变的情况下,句子的表达方式发生了显著的变化
严重的错误:翻译的质量很糟糕
对于情况1,我们可以容忍较轻的modality change,这种情况下真实数据和蒸馏数据都可以被视作正确的学习目标,同时引入真实数据不会大幅增加数据集的复杂程度。情况2中,用真实数据替换蒸馏数据可以得到更高的翻译质量,找出属于这种情况的样本是我们方法的主要目标。情况3中,由于引入真实数据会恶化multi-modality问题,我们希望蒸馏这部分数据。情况4很少发生,我们认为这种情况下该训练样本对NAT可能太过困难,引入真实数据带来的提升很有限。总的来说,我们希望能找到情况1、2对应的训练样本,在训练过程中将它们的原始数据作为学习对象。

图2:4种不同的情况对应的案例
为了筛选情况1、2中的数据,我们在蒸馏数据上训练一个NAT作为评估模型,通过比较评估模型的输出和真实数据计算一个score,判断一个真实翻译是否适合被直接用于训练。若对于某个样本评估模型的输出和真实数据较为接近,则score较高,我们可以认为蒸馏数据仅有微小的错误或modality change,从而认为它属于情况1、2,无需蒸馏。反之,可以认为蒸馏数据发生了较大的变化,因此属于情况3、4,或是这个样本在蒸馏后不发生太大变化的情况下对NAT而言仍过于困难。经过筛选,我们仅蒸馏那些不适合用于训练的真实数据。
2.2动态调整蒸馏比例:由困难到容易
我们在训练过程中会调整蒸馏数据的比例。一般来说,刚开始训练时绝大多数训练样本为真实数据,训练的尾声则会蒸馏整个训练集。具体实现中,我们通过动态调节score的阈值来调整蒸馏的比例。

图3:selective KD在第k次update的算法示意
03
实验
我们在WMT14 EN-DE和WMT16 EN-RO上开展了实验,包括了两种代表性的NAT架构:CMLM [5]和GLAT+CTC [6],以及一种inference-efficient的AT架构:DeepShallow [7](6层编码器,1层解码器)。
3.1翻译质量与推理速度
我们通过BLEU score [8]和一种learned metric COMET [9]来衡量模型的翻译质量,并通过和标准Transformer比较来衡量推理速度。可以发现,相比于常规的知识蒸馏,Selective KD可以在不同数据集、不同架构以及不同metric上稳定取得翻译质量的提升,同时保持模型自身在推理速度上的优势。我们方法在inference-efficient AT上也有明显的效果,这进一步说明了selective KD具有广泛的价值。
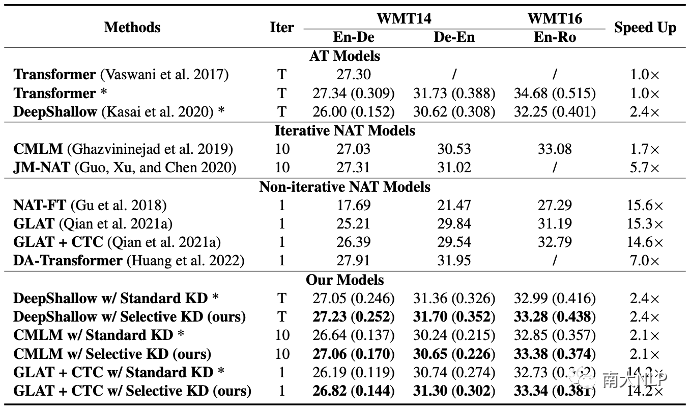
图4:翻译质量与推理速度。翻译质量括号外为BLEU,括号内为COMET
3.2调节quality和complexity
真实数据的翻译质量往往是优于蒸馏数据的,通过调节蒸馏数据的比例,Selective KD可以调节训练集的quality。与此同时,我们希望知道这个方法是否可以灵活调节训练集的complexity。为了更好地观察这一点,文章中用了两个metric来衡量数据的复杂程度:Translatioin Uncertainty [10]和Alignment Shift。Translation Uncertainty反映了源句单词对应翻译结果的多样性,Alignment Shift反映了句式的变化程度。
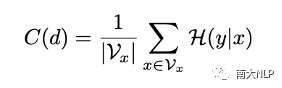
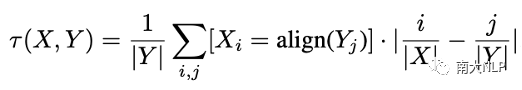
图5:Translation Uncertainty(左)和Alignment Shift(右)的计算方式
如图6所示,我们的方法可以有效控制数据的complexity。我们保留的真实数据(绿色折线)在两个指标上都远远低于被蒸馏的真实数据(红色折线)。在增加真实数据的比例同时,整个数据集complexity的提升是缓慢而平滑的。
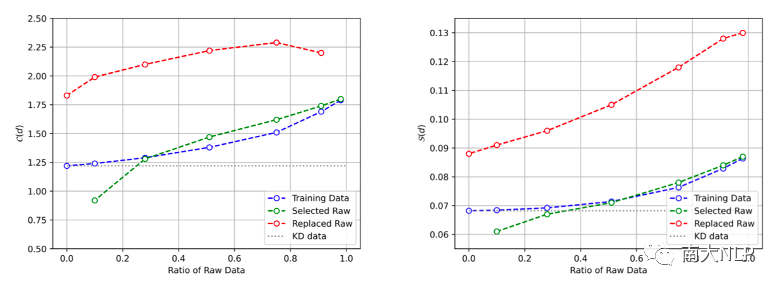
图6:数据的Translation Uncertainty(左)和Alignment Shift(右)
3.3蒸馏数据占比的影响
如图7所示,我们在不同蒸馏比例的数据上进行了实验。可以发现,通过selective KD仅蒸馏5%的数据就可以提升2.4 BLEU。在蒸馏数据比例为80%时,模型的表现甚至超过了完全蒸馏的数据,根据[10],一种可能的解释是这种比例下数据的complexity更适合我们实验中采用的GLAT+CTC架构。另外,动态调节真实数据的比例(蓝色虚线)可以进一步提升模型的表现。
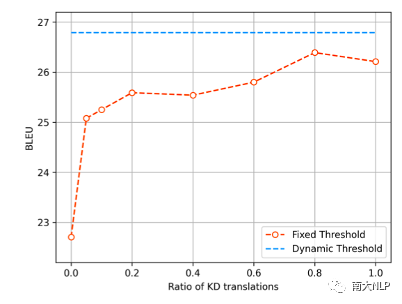
图7:在不同蒸馏比例下模型的表现
04
总结
在这篇文章中,我们提出了选择性知识蒸馏,从而使得NAT模型可以从真实的数据分布中学到知识蒸馏过程中缺失的部分信息。具体来说,我们采用一个NAT作为评估模型来判断哪些句子需要蒸馏,并动态提高蒸馏数据的比例。我们用实验结果证明了该方法可以有效提升NAT在机器翻译任务上的表现。
审核编辑 :李倩
-
NAT
+关注
关注
0文章
145浏览量
16236 -
机器翻译
+关注
关注
0文章
139浏览量
14880 -
数据集
+关注
关注
4文章
1208浏览量
24690
原文标题:AAAI'23 | 用于NAT的选择性知识蒸馏框架
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SiGe与Si选择性刻蚀技术
选择性沉积技术介绍
基于介电电泳的选择性液滴萃取微流体装置用于单细胞分析
Nat server技术原理和配置过程
过电流保护的选择性是靠什么来实现的

NAT技术及其应用






 工商网监
工商网监
评论