 目标检测算法有哪些 目标检测算法原理图
目标检测算法有哪些 目标检测算法原理图
目标检测是计算机视觉领域的核心问题之一,其任务就是找出图像中所有感兴趣的目标,确定他们的类别和位置。由于各类不同物体有不同的外观,姿态,以及不同程度的遮挡,加上成像是光照等因素的干扰,目标检测一直以来是一个很有挑战性的问题。
目标检测算法原理
目标检测定义,识别图片中有哪些物体以及物体的位置(坐标位置)。其中,需要识别哪些物体是人为设定限制的,仅识别需要检测的物体;物体的坐标位置由两种表示方法:极坐标表示(xmin, ymin, xmax, ymax)和中心点坐标表示(x_center, y_center, w, h)。
目标检测算法原理:清晰记住算法的识别流程,解决某些问题用到的算法的关键技术点。
常见经典目标检测算法
目标检测算法分类:
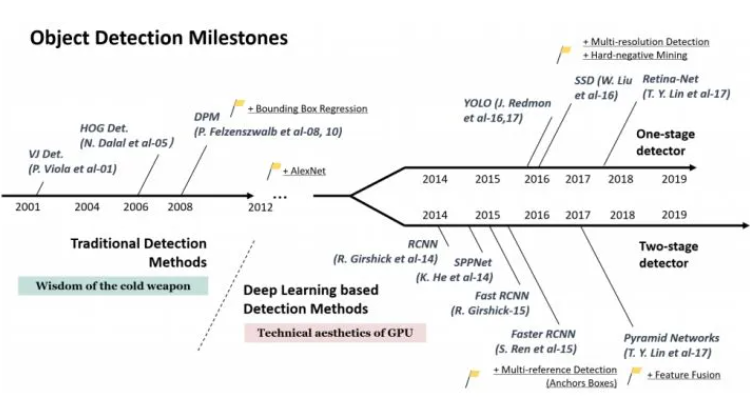
目标检测近年来已经取得了很重要的进展,主流的算法主要分为两个类型:
(1)two-stage方法,如R-CNN系算法,其主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,two-stage方法的优势是准确度高。
(2)one-stage方法,如Yolo和SSD,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡,导致模型准确度稍低。
目标检测和目标识别的区别
目标检测和识别,是计算机视觉最常见的挑战之一。
目标检测和识别的区别在于:目标检测是用来确定图像的某个区域是否含有要识别的对象,而识别是程序识别对象的能力。识别通常只处理已检测到对象的区域。
目标检测算法的发展现状
目标检测是计算机视觉中最重要的任务之一,主要目标是在真实场景或输入图像中检测出特定目标以及目标的具体位置,并为每个检测到的对象分配预先标注的类别标签。由于其应用广泛、发展迅速,近年来目标检测引起了巨大的关注。
基于深度学习的计算模型主要用于通用或是特定领域的目标检测。这些计算模型作为大多数目标检测器的骨干网络(backbone),主要作用为从输入图像中提取特征、分割、分类和目标定位等。
事实上,作为图像分析的重要方法,目标检测在许多计算机视觉任务中广泛应用,比如人脸识别、行人检测、标志检测和视频分析等方向。人脸识别的目的是检测出图像中存在的人脸,由于存在许多不确定的遮挡和光照变化,人脸识别在现阶段研究中仍然是一项困难的任务。
-
目标检测
+关注
关注
0文章
209浏览量
15612 -
深度学习
+关注
关注
73文章
5503浏览量
121192
发布评论请先 登录
相关推荐
基于深度学习的目标检测算法解析
PowerPC小目标检测算法怎么实现?
基于YOLOX目标检测算法的改进
基于像素分类的运动目标检测算法

基于多尺度融合SSD的小目标检测算法综述
基于Grad-CAM与KL损失的SSD目标检测算法
浅谈红外弱小目标检测算法

无Anchor的目标检测算法边框回归策略

基于强化学习的目标检测算法案例
基于Transformer的目标检测算法






 工商网监
工商网监
评论