 【性能优化】memcpy函数有没有更高效的拷贝实现方法?
【性能优化】memcpy函数有没有更高效的拷贝实现方法?

【C语言经典面试题】memcpy函数有没有更高效的拷贝实现方法?
我相信大部分初中级C程序员在面试的过程中,可能都被问过关于memcpy函数的问题,甚至需要手撕memcpy。本文从另一个角度带你领悟一下memcpy的面试题,你可以看看是否能接得住?
1 写在前面2 源码实现2.1 函数申明2.2 简单的功能实现2.3 满足大数据量拷贝的功能实现3 源码测试4 小小总结5 更多分享
1 写在前面
假如你遇到下面的面试题,你会怎么做?题目大意如下:
请参考标准C库对memcpy的申明定义,使用C语言的语法实现其基本功能,并尽量保证它在拷贝大数据(KK级别)的时候,有比较好的性能表现。
2 源码实现
2.1 函数申明
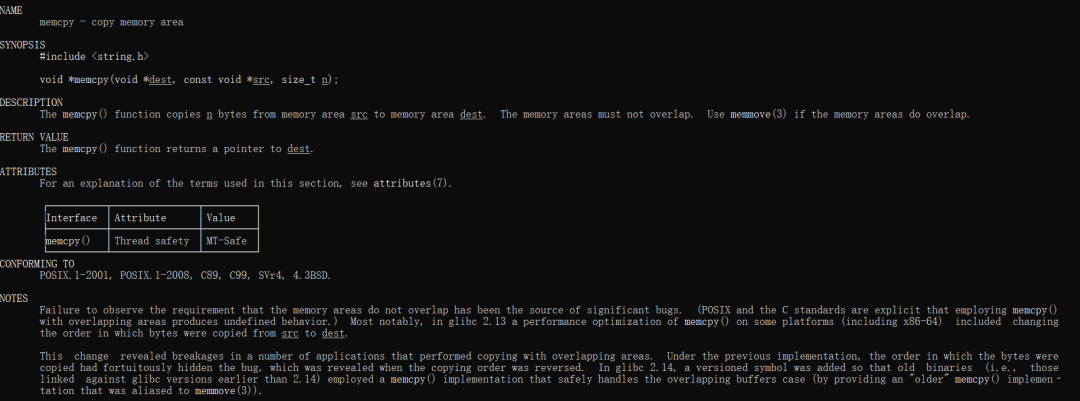
通过查看man帮助,我们可以知道memcpy函数的功能及其简要申明。
NAME
memcpy - copy memory area
SYNOPSIS
#include
英文翻译过来就是说,memcpy实现的就是内存拷贝,其是按字节进行拷贝,同时还可能会存在内存区域重合的情况。
2.2 简单的功能实现
根据功能需求,以下是我的一个简单实现源码,仅供参考:
char *my_memcpy(char* dest, const char *src, size_t len)
{
assert(dest && src && (len > 0));
if (dest == src) {
;
} else {
char *p = dest;
size_t i;
for (i = 0; i < len; i++) {
*p++ = *src++;
}
}
return dest;
}
但是,这段代码的缺陷也比较明显,但数据量过大的时,即len很大时,整一个拷贝耗时将会非常不理想。那么如果考虑性能问题,又该如何实现它呢?
2.3 满足大数据量拷贝的功能实现
下面给出一个参考实现:
/* Nonzero if either X or Y is not aligned on a "long" boundary. */
#define UNALIGNED(X, Y) \\
(((long)X & (sizeof(long) - 1)) | ((long)Y & (sizeof(long) - 1)))
/* How many bytes are copied each iteration of the 4X unrolled loop. */
#define BIGBLOCKSIZE (sizeof(long) << 2)
/* How many bytes are copied each iteration of the word copy loop. */
#define LITTLEBLOCKSIZE (sizeof(long))
/* Threshhold for punting to the byte copier. */
#define TOO_SMALL(LEN) ((LEN) < BIGBLOCKSIZE)
char *my_memcopy_super(char* dest0, const char *src0, size_t len0)
{
assert(dest0 && src0 && (len0 > 0));
char *dest = dest0;
const char *src = src0;
long *aligned_dest;
const long *aligned_src;
/* If the size is small, or either SRC or DST is unaligned,
then punt into the byte copy loop. This should be rare. */
if (!TOO_SMALL(len0) && !UNALIGNED(src, dest)) {
aligned_dest = (long *)dest;
aligned_src = (long *)src;
/* Copy 4X long words at a time if possible. */
while (len0 >= BIGBLOCKSIZE) {
*aligned_dest++ = *aligned_src++;
*aligned_dest++ = *aligned_src++;
*aligned_dest++ = *aligned_src++;
*aligned_dest++ = *aligned_src++;
len0 -= BIGBLOCKSIZE;
}
/* Copy one long word at a time if possible. */
while (len0 >= LITTLEBLOCKSIZE) {
*aligned_dest++ = *aligned_src++;
len0 -= LITTLEBLOCKSIZE;
}
/* Pick up any residual with a byte copier. */
dest = (char *)aligned_dest;
src = (char *)aligned_src;
}
while (len0--)
*dest++ = *src++;
return dest0;
}
我们可以看到,里面做了对齐的判断,还有数据量长度的判断;通过充分利用机器的操作性能,从而提升memcpy拷贝的效率。
3 源码测试
**简单的测试代码如下,目的就是测试在拷贝 **1KB数据和10MB数据 时,标准C的memcpy、自定义的memcpy_normal、以及自定义的memcpy_super直接的性能差异:
#include
#include
static void get_rand_bytes(unsigned char *data, int len)
{
int a;
int i;
srand((unsigned)time(NULL)); //种下随机种子
for (i = 0; i < len; i++) {
data[i] = rand() % 255; //取随机数,并保证数在0-255之间
//printf("%02X ", data[i]);
}
}
static int get_cur_time_us(void)
{
struct timeval tv;
gettimeofday(&tv, NULL); //使用gettimeofday获取当前系统时间
return (tv.tv_sec * 1000 * 1000 + tv.tv_usec); //利用struct timeval结构体将时间转换为ms
}
#define ARRAY_SIZE(n) sizeof(n) / sizeof(n[0])
int main(void)
{
int size_list[] = {
1024 * 1024 * 10, // 10MB
1024 * 1024 * 1, // 1MB
1024 * 100, // 100KB
1024 * 10, // 10KB
1024 * 1, // 1KB
};
char *data1;
char *data2;
int t1;
int t2;
int i = 0;
data1 = (char *)malloc(size_list[0]);
data2 = (char *)malloc(size_list[0]);
get_rand_bytes(data1, size_list[0]);
for (i = 0; i < ARRAY_SIZE(size_list); i++) {
t1 = get_cur_time_us();
memcpy(data2, data1, size_list[i]);
t2 = get_cur_time_us();
printf("copy %d bytes, memcpy_stdc waste time %dus\\n", size_list[i], t2 - t1);
t1 = get_cur_time_us();
my_memcopy_normal(data2, data1, size_list[i]);
t2 = get_cur_time_us();
printf("copy %d bytes, memcpy_normal waste time %dus\\n", size_list[i], t2 - t1);
t1 = get_cur_time_us();
my_memcopy_super(data2, data1, size_list[i]);
t2 = get_cur_time_us();
printf("copy %d bytes, memcpy_super waste time %dus\\n\\n", size_list[i], t2 - t1);
}
free(data1);
free(data2);
return 0;
}
简单执行编译后,运行小程序的结果:
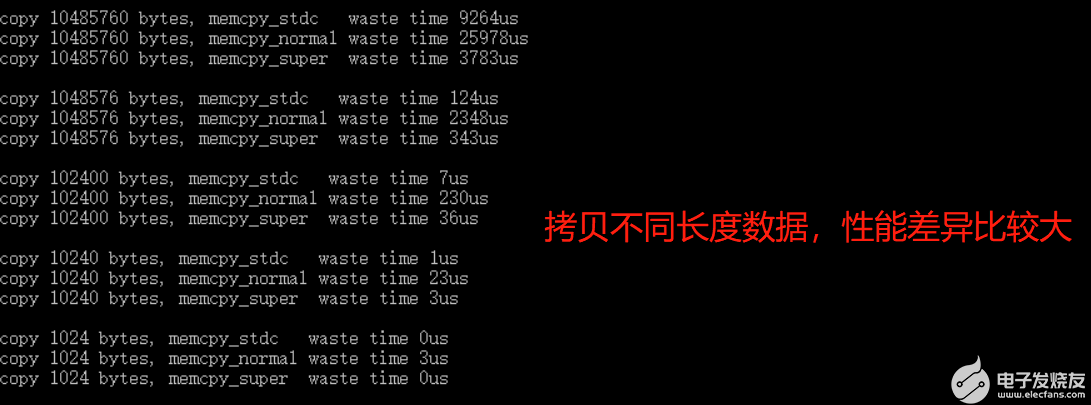
从运行结果上看:
- **拷贝数据量比较小时,拷贝效率排行: **normal < super < stdc
- **拷贝数据量比较大时,拷贝效率排行: **normal < stdc < super
4 小小总结
memcpy的源码实现,核心就是内存拷贝,要想提升拷贝的效率,还得充分利用机器的运算性能,比如考虑对齐问题。
综合来看,标准C库实现的memcpy在大部分的场景下都可以有一个比较好的性能表现,这一点是值得称赞的。
5 更多分享
[架构师李肯]
架构师李肯 ( 全网同名 ),一个专注于嵌入式IoT领域的架构师。有着近10年的嵌入式一线开发经验,深耕IoT领域多年,熟知IoT领域的业务发展,深度掌握IoT领域的相关技术栈,包括但不限于主流RTOS内核的实现及其移植、硬件驱动移植开发、网络通讯协议开发、编译构建原理及其实现、底层汇编及编译原理、编译优化及代码重构、主流IoT云平台的对接、嵌入式IoT系统的架构设计等等。拥有多项IoT领域的发明专利,热衷于技术分享,有多年撰写技术博客的经验积累,连续多月获得RT-Thread官方技术社区原创技术博文优秀奖,荣获[CSDN博客专家]、[CSDN物联网领域优质创作者]、[2021年度CSDN&RT-Thread技术社区之星]、[2022年RT-Thread全球技术大会讲师]、[RT-Thread官方嵌入式开源社区认证专家]、[RT-Thread 2021年度论坛之星TOP4]、[华为云云享专家(嵌入式物联网架构设计师)]等荣誉。坚信【知识改变命运,技术改变世界】!
审核编辑:汤梓红
-
函数
+关注
关注
3文章
4423浏览量
68001 -
RT-Thread
+关注
关注
32文章
1655浏览量
45411 -
memcpy
+关注
关注
0文章
9浏览量
3039
发布评论请先 登录
HBase性能优化方法总结
MSP430FRx MCU如何实现更高性能
memCopy函数怎么实现拷贝的呢?
STM32中的memcpy函数的使用 精选资料推荐
memcpy怎么用_memcpy用法总结

浅谈linux c编程中的拷贝函数

C语言模拟实现memmove函数

memcpy函数实现及其优化
C++之拷贝构造函数的浅copy及深copy
C语言库memcpy和memmove的区别分析
memcpy和memmove的区别是什么



评论