 使用YOLOX检测PCB的缺陷
使用YOLOX检测PCB的缺陷
PCB(印刷电路板)
我知道,你一定在问,什么是PCB?不是吗?对于不知道PCB是什么的人,这里有一个来自维基百科的定义:
PCB(Printed Circuit Board),中文名称为印制电路板,又称印刷线路板,是重要的电子部件,是电子元器件的支撑体,是电子元器件电气相互连接的载体。由于它是采用电子印刷术制作的,故被称为“印刷”电路板。[1]
我打赌你一生中至少见过一次PCB,但可能不想知道它是什么。以下是维基百科DVD读取器上的PCB图像:

PCB无处不在。几乎所有的电子设备都有一个隐藏在其中的印刷电路板。在很多情况下,这些PCB在设计时或使用后都可能存在缺陷。
以下是互联网上列出的PCB中一些常见缺陷的列表,以及免费提供的数据集中的示例图像?.
1.Opens
2.Excessive solder
3.Component shifting
4.Cold joints
5.Solder bridges
6.Webbing and splashes
我们不会深入探讨它们的确切含义,因为这不是博客的内容。但是,从懂一点计算机视觉和深度学习的计算机工程师的角度来看,似乎检测PCB数字图像中的缺陷是一个可以解决的问题。
我们将使用mmdetection? 检测PCB图像中的缺陷。OpenMMLab? 是一个深度学习库,拥有计算机视觉领域大多数最先进实现的预训练模型。它实现了几乎所有众所周知的视觉问题,如分类、目标检测与分割、姿态估计、图像生成、目标跟踪等等。
YOLOX:2021超越YOLO系列?
本文中,我们将使用YOLOX? ,我们将微调mmdetection?. YOLOX? 是2021发布的最先进模型,是YOLO系列的改进。作者做出了一些重大改进,如下所示。
2.移除锚箱
3.注意数据增强
4.用于检测和分类的独立头
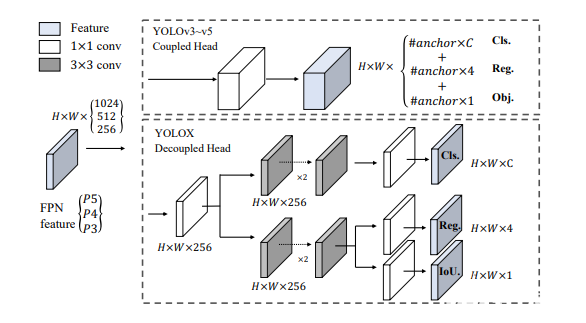
之前从v3到v5的YOLO系列都有一个单一的预测头,其中包括边界框预测、分类分数预测以及对象性分数预测,如上图上半部分所示。
这在YOLOX中发生了变化? 作者选择使用具有独立头的解耦头进行所有预测的系列。
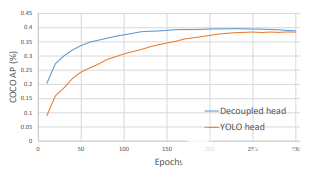
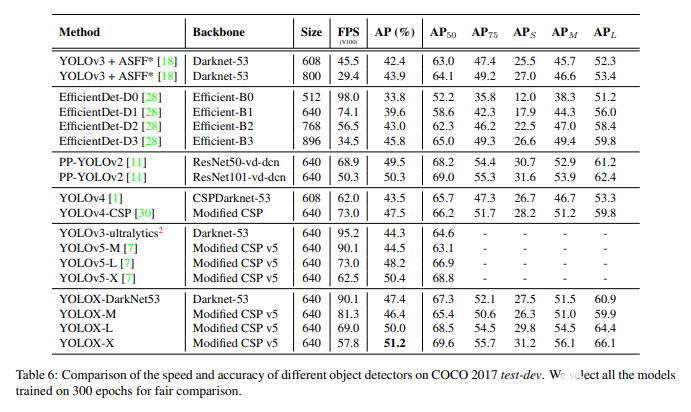
如图所示,检测头和分类头位于不同的头中。这有助于改善训练期间的收敛时间(如图3所示),并略微提高模型精度。
由于分离为两个头部,参数数量显著增加,因此模型的速度确实受到了影响。正如我们在图4中看到的,YOLOX-L比YOLOv5-L慢一点。它也有专门为参数低得多的边缘设备构建的微型版本。
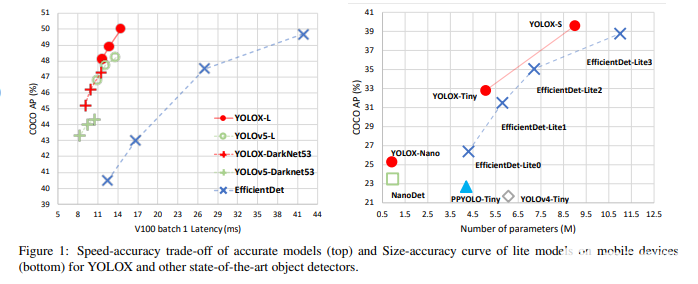
与以前最先进的对象检测模型相比,它们在平均精度方面确实有所提高,但FPS略有下降。
最后,正如伟大的莱纳斯·托瓦尔兹所说,
废话少说。放码过来。
让我们直接跳到代码里!
使用mmdetection微调YOLOX
我们有一个名为DeepPCB的开源PCB缺陷数据集?. 该数据集由1500个图像对组成,每个图像对具有一个无缺陷模板图像和一个具有缺陷的图像,该图像具有6种常见类型缺陷的边界框注释,即open, mouse-bite, short, spur, spurious copper, 和pin-hole。
图像的尺寸为640×640,在我们的YOLOX案例中非常完美? 在相同的维度上进行训练。
OpenMMLab?
OpenMMLab可以非常轻松地微调最先进的模型,只需很少的代码更改。它具有针对特定用例的全面API。我们将使用mmdetection? 用于微调YOLOX? 在DeepPCB上? 数据集。
数据集格式
注:PCB缺陷数据集是一个开源数据集,取自具有MIT许可证的DeepPCB Github repo
我们需要将数据集修改为COCO格式或Pascal VOC格式来重新训练模型。这是MMD检测所必需的? 加载自定义数据集进行训练。
出于训练目的,我们将采用COCO格式。你无需费尽心思将数据集转换为COCO格式,因为它已经为你完成了。你可以从这里直接下载转换后的数据集。整个数据集与DeepPCB中的数据集相同? 只需添加带有COCO格式注释的训练和测试JSON文件即可进行训练。
我将不进行COCO格式的转换,因为你可以找到许多文档,就像mmdetection文档中提到的那样。
将此数据集转换为COCO格式的脚本:
import json
import os
TRAIN_PATH = 'PCBData/PCBData/trainval.txt'
TEST_PATH = 'PCBData/PCBData/test.txt'
def create_data(data_path, output_path):
images = []
anns = []
with open(data_path, 'r') as f:
data = f.read().splitlines()
dataset = []
counter = 0
for idx, example in enumerate(data):
image_path, annotations_path = example.split()
image_path = os.path.join('PCBData', 'PCBData', image_path.replace('.jpg', '_test.jpg'))
annotations_path = os.path.join('PCBData', 'PCBData', annotations_path)
with open(annotations_path, 'r') as f:
annotations = f.read().splitlines()
for ann in annotations:
x, y, x2, y2 = ann.split()[:-1]
anns.append({
'image_id': idx,
'iscrowd': 0,
'area': (int(x2)-int(x)) * (int(y2)-int(y)),
'category_id': int(ann.split()[-1])-1,
'bbox': [int(x), int(y), int(x2)-int(x), int(y2)-int(y)],
'id': counter
})
counter += 1
images.append({
'file_name': image_path,
'width': 640,
'height': 640,
'id': idx
})
dataset = {
'images': images,
'annotations': anns,
'categories': [
{'id': 0, 'name': 'open'},
{'id': 1, 'name': 'short'},
{'id': 2, 'name': 'mousebite'},
{'id': 3, 'name': 'spur'},
{'id': 4, 'name': 'copper'},
{'id': 5, 'name': 'pin-hole'},
]
}
with open(output_path, 'w') as f:
json.dump(dataset, f)
create_data(TRAIN_PATH, 'train.json')
create_data(TEST_PATH, 'test.json')
数据集配置
下一步是修改数据集配置以使用自定义数据集。我们需要添加/修改特定的内容,如类的数量、注释路径、数据集路径、epoch数量、基本配置路径和一些数据加载器参数。
我们将复制一个预先编写的YOLOX-s配置,并为我们的数据集修改它。其余的配置,如增强、优化器和其他超参数将是相同的。
我们不会改变太多,因为这个博客的主要目的是熟悉手头的问题,尝试最先进的YOLOX架构,并实验mmdetection库。我们将把这个文件命名为yolox_s_config。py并将其用于训练。
我们将添加类名并更改预测头的类数。由于将从根目录而不是configs目录加载配置,因此需要更改基本路径。
_base_ = ['configs/_base_/schedules/schedule_1x.py', 'configs/_base_/default_runtime.py']
classes = ('open', 'short', 'mousebite', 'spur', 'copper', 'pin-hole')
bbox_head = dict(type='YOLOXHead', num_classes=6, in_channels=128, feat_channels=128)
我们需要稍微修改train dataset loader以使用我们的类和注释路径。
train_dataset = dict(
type='MultiImageMixDataset',
dataset=dict(
type=dataset_type,
classes=classes,
ann_file='train.json',
img_prefix='',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
],
filter_empty_gt=False,
),
pipeline=train_pipeline)
我们需要在这里对验证和测试集执行相同的操作。这里我们不打算使用单独的测试集,相反,我们将使用相同的测试集进行验证和测试。
data = dict(
samples_per_gpu=8,
workers_per_gpu=4,
persistent_workers=True,
train=train_dataset,
val=dict(
type=dataset_type,
classes=classes,
ann_file='test.json',
img_prefix='',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
classes=classes,
ann_file='test.json',
img_prefix='',
pipeline=test_pipeline))
我们将只对模型进行20个epoch的训练,并每5个阶段获得一次验证结果。我们不需要再训练了,因为我们只在20个epoch里取得了不错的成绩。
max_epochs = 20
interval = 5
训练
我们很乐意使用数据集部分。接下来我们需要做的是训练模型。mmdetection最棒的部分? 是,所有关于训练的事情都已经为你们做了。你所需要做的就是从tools目录运行训练脚本,并将路径传递给我们在上面创建的数据集配置。
python3 tools/train.py yolox_s_config.py
你已经成功训练了!
推理
让我们看看我们的模型在一些示例上的表现。你一定想知道,训练模型有多容易,必须有一个命令来对图像进行推理?
有!但是,不要让训练模型的简单程序拖累了你。让我们编写一些用于推理的代码,但让你感到高兴的是,它不到10行代码。
from mmdet.apis import init_detector, inference_detector, show_result_pyplot
config_file = 'yolox_s_config.py'
checkpoint_file = 'best_bbox_mAP_epoch_20.pth'
device = 'cuda:0'
# init a detector
model = init_detector(config_file, checkpoint_file, device=device)
# inference the demo image
image_path = 'demo.jpg'
op = inference_detector(model, image_path)
show_result_pyplot(model, image_path, op, score_thr=0.6)
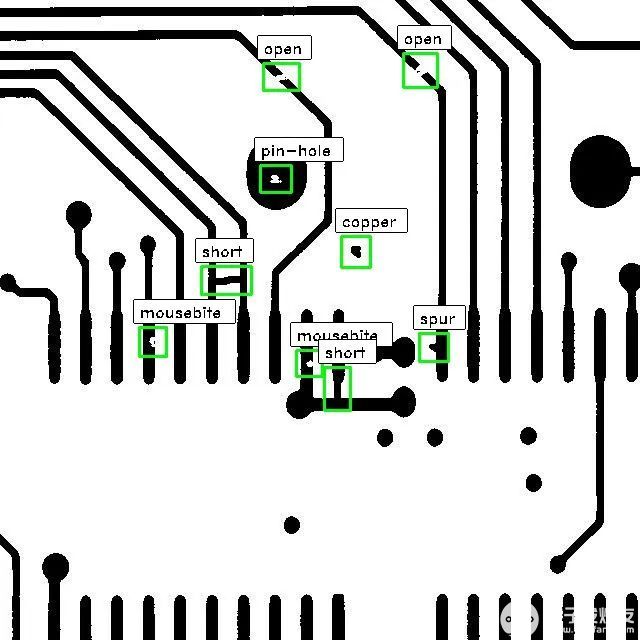
这将显示一个带有边界框的图像,边界框上绘制有预测的类名。下面是一个来自数据集的示例图像,其中包含模型预测。
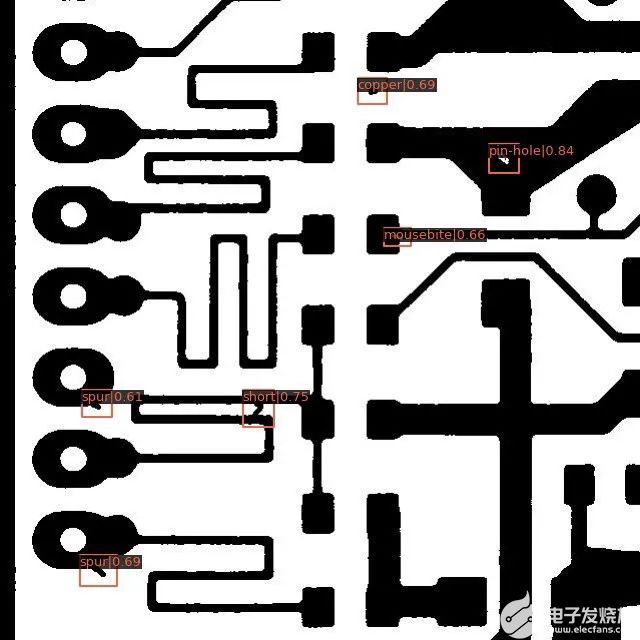
我们做到了!
你也可以尝试我们预先训练的模型,并使用它进行推理。
结论
今天,我们了解了现实世界中普遍存在的一个新问题,并尝试使用像YOLOX这样的最先进模型来解决这个问题?.
我们还使用了mmdetection? ,它是深度学习社区中用于训练对象检测模型的领先开源库之一。如果我不提如何检测,那将是不公平的? 。
在几乎没有任何自定义脚本的情况下,让我们如此快速、轻松地解决问题。
磐创AI
审核编辑 :李倩
-
计算机视觉
+关注
关注
8文章
1698浏览量
46047 -
深度学习
+关注
关注
73文章
5508浏览量
121320 -
PCB
+关注
关注
1文章
1814浏览量
13204
发布评论请先 登录
相关推荐
PCB线路板常见缺陷原因分析:解锁电路板制造的隐秘挑战
X射线工业CT检测设备用于复合新材料内部缺陷检测

基于AI深度学习的缺陷检测系统
yolox_bytetrack_osd_encode示例自带的yolox模型效果不好是怎么回事?
外观缺陷检测原理

产品标签OCR识别缺陷检测系统方案

蔡司工业ct内部瑕疵缺陷检测机

赛默斐视X射线薄膜测厚仪与薄膜表面缺陷检测
友思特应用 | 高精度呈现:PCB多类型缺陷检测系统

如何应对工业缺陷检测数据短缺问题?

洞察缺陷:精准检测的关键

基于深度学习的芯片缺陷检测梳理分析
2023年工业视觉缺陷检测经验分享

无纺布缺陷在线检测仪怎么用

描绘未知:数据缺乏场景的缺陷检测方案






 工商网监
工商网监
评论