 FPGA布线拥塞主要原因及解决方法
FPGA布线拥塞主要原因及解决方法

在FPGA开发设计中,我们可能会经历由于资源占用过高的情况,例如BRAM、LUT和URAM等关键资源利用率达到或超过80%,此时出现时序违例是常有的事,甚至由于拥塞导致布线失败,整个FPGA工程面临无法生成bit文件的危险。
那么,有没有办法来解决这类问题呢?
此类问题是FPGA设计实现中比较棘手的问题,Xilinx针对7系列及以后的UltraScale/UltraScale+等,提出了UltraFast设计方法论,用于指导该系列器件的成功设计和实现,完成复杂系统设计。
时序收敛是指设计满足所有的时序要求。针对综合采用正确的 HDL 和约束条件就能更易于实现时序收敛。通过选择更合适的 HDL、约束和综合选项,经过多个综合阶段进行迭代同样至关重要,如下图所示。
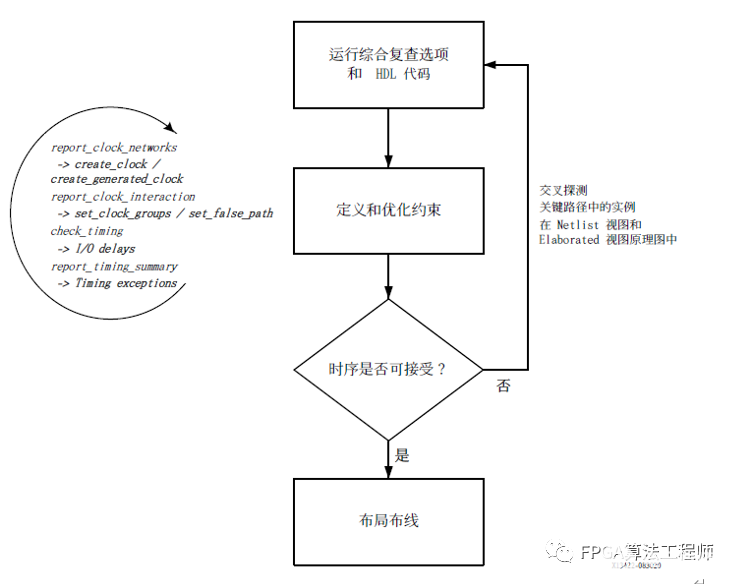
Xilinx提出的实现快速收敛的设计方法论
FPGA布线拥塞怎么办?
如果关键路径在拥塞区域内或者紧邻拥塞区域,或者是资源利用率较高,都会导致时序收敛困难。在很多情况下,拥塞会消耗大量的布线时间,甚至布线失败。如果布线延迟显著大于预期值,那么我们就得考虑降低设计的拥塞程度。
在确保时序约束和物理约束正确的情况下,我们可以通过以下方法解决拥塞问题。
1.拥塞类型
Xilinx FPGA布线结构包括东、南、西、北共4个方向不同长度的互联资源。拥塞区域以最小的正方形体现,这个正方形覆盖了相邻的互联资源或CLB单元。
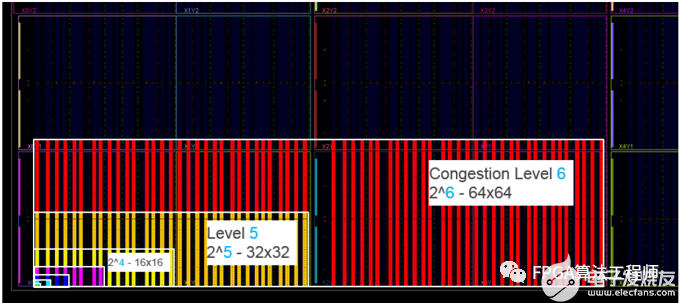
“Device”视图中的拥塞等级和拥塞区域
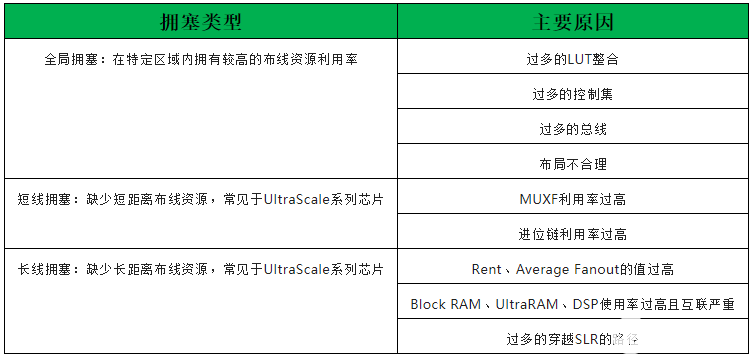
拥塞包括3种类型:全局拥塞、短线拥塞和长线拥塞。
拥塞类型
2.生成设计拥塞报告
为了检查拥塞程度,我们可以基于布局之后生成的DCP,通过以下Tcl命令生成设计拥塞报告。
report_design_analysis -congestion -name cong
分析拥塞时,工具报告的等级可按下表所示方式进行分类。拥塞等级为 5 或更高时,通常会影响 QoR 并且必然会导致布线器运行时间延长。
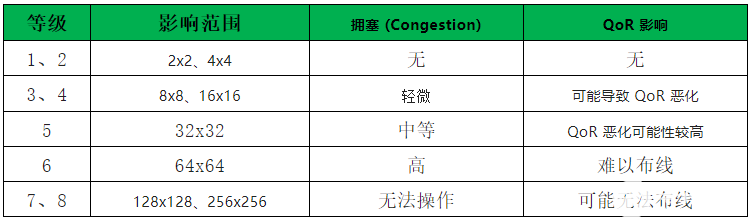
为帮助识别拥塞,Report Design Analysis命令支持生成拥塞报告以显示器件的拥塞区域,以及这些区域内存在的设计模块的名称。此报告中的拥塞表会显示布局器和布线器算法发现的拥塞区域。下图显示了拥塞表示例。

拥塞表
“Placed Maximum”、“Initial Estimated Router Congestion”和“Router Maximum”拥塞表可提供有关东西南北四个方向上拥塞最严重的区域的信息。选中该表中的窗口时,在“Device”窗口中会突出显示对应的拥塞区域。
3.生成设计复杂性报告
我们也可以通过设计复杂性报告来预判是否出现拥塞。我们可以对布局生成的DCP,通过以下Tcl命令生成设计复杂度报告。
report_design_analysis -complexity -name comp
复杂性报告 (Complexity Report) 可按顶层设计和/或层级单元的叶节点单元的类型显示 Rent 指数 (Rent Exponent)、平均扇出 (Average Fanout) 和分布方式。Rent 指数是指在使用min-cut算法以递归形式对设计进行分区时,网表分区的端口数量和单元数量之间的关系。其计算方法与在全局布局期间布局器所使用的算法类似。因此,它可准确表明布局器所面临的困难,当设计的层级与在全局布局期间所发现的物理分区匹配良好时尤其如此。
Rent 指数较高的设计表示此类设计中包含逻辑紧密相连的分组,并且这些分组与其它分组同样连接紧密。这通常可理解为全局布线资源利用率较高并且布线复杂性也更高。此报告中提供的 Rent 指数是根据未布局和未布线的网表来计算的。完成布局后,相同设计的 Rent 指数可能改变,因为它基于物理分区而不是逻辑分区。
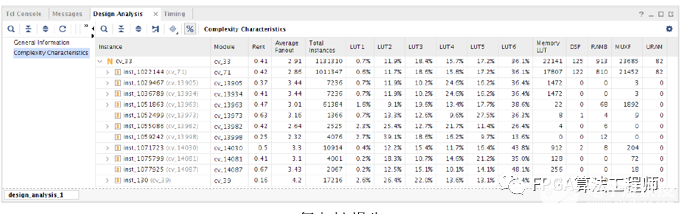
复杂性报告
Rent 指数的典型范围

“平均扇出”典型范围

4.解决拥塞问题
根据前文所述造成拥塞的原因,我们可以采用以下办法解决布线拥塞问题。
拥塞原因1:过多的MUXF(将MUXF转化为LUT)
方法1:利用模块化综合技术,对特定模式设置MUXF_REMAPPING:
set_property BLOCK_SYNTH.MUXF_MAPPING 1 [get_cells top/instance]
方法2:在opt_design阶段使用-remap选项:
opt_design -mux_remap -remap
方法3:针对特定MUXF设置MUXF_REMAP属性为ture
set_property MUXF_REMAP 1 [get_cells -hier-filter {NAME=~ cpu*&& REF_NAME=~MUXF*}]
拥塞原因2:过长的进位链(将进位链转化为LUT)
方法1:在opt_design阶段使用-remap选项:
opt_design -carry_remap -remap
方法2:针对特定MUXF设置CARRY_REMAP属性
set_property CARRY_REMAP 2 [get_cells -hier-filter { REF_NAME==CARRY8}]
拥塞原因3:过多的控制集(合并控制集)
方法1:利用模块化综合技术,对特定模式设置CONTROL_SET_THRESHOLD:
set_property BLOCK_SYNTH. CONTROL_SET_THRESHOLD 10 [get_cells top/instance]
方法2:在opt_design阶段,使用-control_set_merge合并等效控制集
opt_design -control_set_merge
方法3:在opt_design阶段,使用merge_equivalent_drivers合并等效控制集,包括非控制逻辑
opt_design -merge_equivalent_drivers
拥塞原因4:过多的LUT整合(阻止LUT整合)
方法1:利用模块化综合技术,对特定模式设置LUT_COMBINING:
set_property BLOCK_SYNTH. LUT_COMBINING 0 [get_cells top/instance]
方法2:设定LUT的LUTNM属性为空:
set_property LUTNM “”[get_cells hier-filter {REF_NAME =~LUT*&& NAME=~inst}]
在综合阶段,除了使用以上的方法外,对于IP,我们最好采用OOC的综合方式。
在实现阶段,可以选择适当的实现策略来缓解拥塞。对于UltraScale系列芯片,可尝试采用“Congestion_*”策略缓解拥塞;对于UltraScale+系列芯片,可尝试采用“performance_NetDelay_*” 策略缓解拥塞。如下图所示。
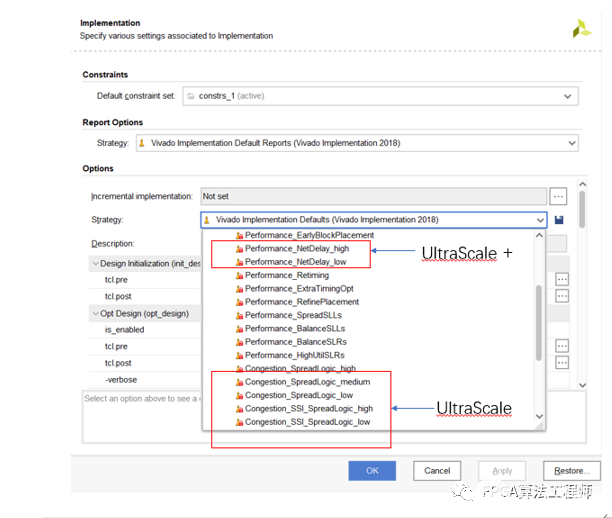
实现时解决拥塞策略
当然,我们也尝试采用“performance_ExtraTimingOpt” 策略进行时序优化,但可能无法解决拥塞问题。
FPGA算法工程师
审核编辑 :李倩
-
FPGA
+关注
关注
1664文章
22553浏览量
640500 -
Xilinx
+关注
关注
73文章
2208浏览量
132145 -
时序
+关注
关注
5文章
411浏览量
39049
发布评论请先 登录
变频器故障的主要原因

UPS电源有刺耳电流声是什么原因?3个实用故障排查技巧及解决方法

MOS 管烧坏、炸管的主要原因有哪些?怎么快速排查和解决?

一般电气线路起火的原因和预防方法
C编译器错误与解决方法
ODF配线架常见故障及解决方法?
轴承锈蚀的主要原因分析
程序加载过程中遇到的问题及其解决方法
TFT液晶屏开机时开机闪屏的原因和解决方法
FPGA测试DDR带宽跑不满的常见原因及分析方法
LVDS接口的显示屏,显示偏暗问题的解决方法
ECN如何在HPC和数据中心中应对网络拥塞
403 Forbidden是什么意思?最佳解决方法有哪些?
如何解决CAN通讯故障?原因分析与解决方法全攻略




评论