 一文详解Linux awk命令
一文详解Linux awk命令
Awk是一种通用脚本语言,用于高级文本处理的。它主要用作报告和分析工具。与大多数其他程序性编程语言不同。
Awk是数据驱动的,这意味着您必须定义一组针对输入文本要执行的操作。它获取输入数据,对其进行转换,然后将结果发送到标准输出。
awk有几种不同的实现。我们将使用Awk的GNU实现,称为gawk。在大多数Linux发行版可用,awk命令只gawk的符号链接。
在本教程的所有示例中,我们将使用teams.txt文件作为awk的输入,teams.txt文件内容如下所示。
Bucks Milwaukee 60 22 0.732
Raptors Toronto 58 24 0.707
76ers Philadelphia 51 31 0.622
Celtics Boston 49 33 0.598
Pacers Indiana 48 34 0.585
teams.txt
记录和字段
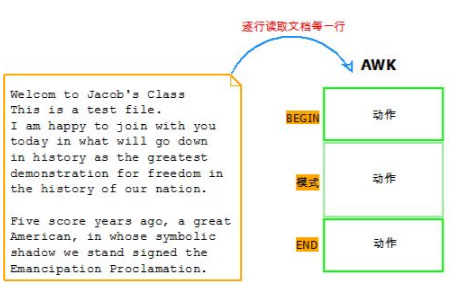
Awk可以处理文本数据和流。将输入的数据分为记录和字段。Awk一次对一条记录进行操作,直到达到输入结束为止。
记录由记录分隔符分隔。默认的记录分隔符是换行符,这意味着文本数据中的每一行都是一条记录。可以使用RS变量来设置记录分的隔符。
记录由多个字段组成,并且使用字段分隔符分隔。默认情况下,字段之间用空格分隔,可以是一个或多个制表符,空格等,你可以使用awk命令的-F选项指定字段的分隔符。
每条记录中的字段都可以使用美元符号$后跟字段编号表示,从1开始。第一个字段由$1表示,第二个字段由$2表示。
依此类推,最后一个字段也可以用特殊变量$NF表示。整个记录可以用$0表示。
下面可以直观展示记录和字段的关系,也是awk处理文本数据默认使用的记录分隔符,即换行符。字段分隔符是空格符。
tmpfs 788M 1.8M 786M 1% /run/lock
/dev/sda1 234G 191G 31G 87% /
|-------| |--| |--| |--| |-| |--------|
$1 $2 $3 $4 $5 $6 ($NF) --> 字段 $1,$2...字段
|-----------------------------------------|
$0 --> 记录由多个字段组成的单行记录
正则表达式模式
正则表达式是与一组字符串匹配的模式。Awk正则表达式模式包含在斜杠//中。这是正则表达式模式语法形式/regex pattern/ { action }。
模式可以是任何类型的扩展正则表达式,换句话说,你在其它语言使用的正则表达式都可以用于awk。
例如命令awk '/0.5/ { print $1 }' teams.txt仅打印包含0.5记录的第一个字段。
命令awk '/^[0-9][0-9]/ { print $1 }' teams.txt将会搜索以两个或多个数字开头的记录,并打印第一个字段。
awk '/0.5/ { print $1 }' teams.txt
Celtics
Pacers
awk '/^[0-9][0-9]/ { print $1 }' teams.txt
76ers
关系表达模式
关系表达式模式通常用于匹配指定字段或变量的内容。默认情况下,正则表达式模式与记录进行匹配。
要将正则表达式与字段进行匹配,请指定字段并针对模式使用包含比较运算符约等于号~。要匹配不包含指定模式的字段,请使用不约等于运算符!~。
除了约等于和不約等于符号之外,您可以比较字符串或数字之间的关系,例如大于>,小于<,等于=符号。
例如命令awk '$2 ~ /ia/ { print $1 }' teams.txt将会搜索第二个字段包含ia的记录并打印第一个字段。
awk '$2 ~ /ia/ { print $1 }' teams.txt
76ers
Pacers
例如命令awk '$2 !~ /ia/ { print $1 }' teams.txt将会搜索第二个字段不包含ia的记录并打印第一个字段。
awk '$2 !~ /ia/ { print $1 }' teams.txt
Bucks
Raptors
Celtics
例如命令awk '$3 > 50 { print $1 }' teams.txt将会搜索三字段大于50的所有记录,并打印第一字段。
awk '$3 > 50 { print $1 }' teams.txt
Bucks
Raptors
76ers
范围模式
范围模式由用逗号分隔的两个模式组成,从匹配第一个模式的记录开始,直到匹配第二个模式的记录停止匹配。
也就是说匹配两个模式之间的记录都会被执行相关的操作。即使中间记录没有匹配模式也将会被执行相关操作。
但有一点值得注意的是范围模式不能与某些模式表达式组合使用。但范围模式可以与关系表达式组合使用。
例如命令awk '/Raptors/,/Celtics/ { print $1 }' teams.txt将会搜索从包含Raptors的记录开始到包含Celtics记录结束的所有记录。
然后打印两个模式之间所有记录的第一个字段{ print $1 }。
awk '/Raptors/,/Celtics/ { print $1 }' teams.txt
Raptors
76ers //这个记录没有匹配到两个模式中任意一个,但它在两个模式之间,所以也会打印
Celtics
例如命令awk '$4 == 31, $4 == 33 { print $0 }' teams.txt组合范围模式和关系表达式。
将会搜索第四个字段等于31记录开始,直到第四个字段等于33的所有记录。然后打印整个记录$0。
awk '$4 == 31, $4 == 33 { print $0 }' teams.txt
76ers Philadelphia 51 31 0.622
Celtics Boston 49 33 0.598
特殊表达模式
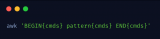
Awk可以使用的特殊模式是。BEGIN用于在处理记录之前执行的操作。END用于在处理记录后执行操作。
BEGIN模式通常用于声明变量,END模式通常用于处理记录中的数据,例如统计指定字段的总数。
如果程序只有BEGIN模式,则执行操作,并且不处理输入数据。如果程序只有END模式,则在执行操作之前先处理输入。
awk的Gnu版本还包含另外两个特殊模式BEGINFILE和ENDFILE,它们允许您在处理文件时执行操作。
在下面的示例中将打印Start Processing.,然后打印每个记录的第三个字段,最后打印End Processing.。这是一个简单的示例,你也可以用于打印字段的名称。
awk 'BEGIN { print "Start Processing." }; { print $3 }; END { print "End Processing." }' teams.txt
Start Processing
60
58
51
49
48
End Processing.
组合模式
Awk允许您使用逻辑AND运算符&&和逻辑或运算符||组合两个或多个模式。
例如命令awk '$3 > 50 && $4 < 30 { print $1 }' teams.txt使用&&运算符搜索第三字段大于50而第四字段小于30的记录,然后打印已匹配记录的第一个字段。
awk '$3 > 50 && $4 < 30 { print $1 }' teams.txt
Bucks
Raptors
-
Linux
+关注
关注
87文章
11196浏览量
208670 -
命令
+关注
关注
5文章
674浏览量
21962 -
脚本语言
+关注
关注
0文章
47浏览量
8203
发布评论请先 登录
相关推荐
Linux中grep、sed和awk命令详解
linux awk命令简单易懂分分钟学会
Linux Awk用法总结





 工商网监
工商网监
评论