 采用AMD赛灵思数字前端(DFE)和Versal处理器实现设计
采用AMD赛灵思数字前端(DFE)和Versal处理器实现设计
mMIMO有源天线单元
决定 mMIMO AAU 性能的主要因素有:
天线——所有与辐射层有关的参数
产品——影响AAU性能的其他因素
机械设计、散热设计和外部操作环境,每个因素都将在本节中详细讲解。
天线
AAU 中的天线的性能特征包括增益、等效全向辐射功率(EIRP)、旁瓣电平、转向角和仰角倾斜。
增益和EIRP
mMIMO 面板的最大可实现增益决定了可以指向特定用户的最大传输功率,而EIRP则直接与天线阵列的增益有关。在接收用户信号时,对应的衡量指标是等效全向灵敏度(EIS)。
增益有其代价。要提高增益,必须扩大天线的有效面积,也就是说面板的尺寸越大,增益就越高。随着增益的增加,波束宽度变窄。这可以从天线焦距的增大直观地做出判断。由于收发器的数量有限,给定最大旁瓣电平下的转向角(即波束从视轴偏离的方位角或仰角范围)也会变小。天线设计由部署环境和所需的转向范围共同决定。对于典型的宏基站而言,根据最小波束宽度,应需要高达±60度的横向转向范围。通常情况下,偏离视轴 ±10 度或更小的纵向转向范围已经足够。
旁瓣电平(SLL)
mMIMO 和 RU 性能取决于天线辐射层产生的旁瓣。如今的 O-RAN mMIMO 系统致力于在整个球体上将旁瓣电平限制在低于 -10dB,特别是在横纵转向范围上。如果旁瓣没有得到主动抑制,功率也会在旁瓣方向上发送,导致有用方向上的发送功率下降。虽然主动抑制技术能够降低旁瓣电平,但同时也会降低主瓣上的功率。
从旁瓣辐射出的信号能在有害方向上导致干扰。横向旁瓣将干扰相邻扇面,纵向扇面将干扰相邻蜂窝。上下旁瓣都应该纳入考虑。上旁瓣在主波束向下转向时,会进入另一蜂窝。下纵向旁瓣的地面反射能产生类似效果。
在接收时,可能接收到通过旁瓣传递的有害方向上的功率。虽然 DU 能对此进行补偿,但补偿通常会增大剩余信号的噪声水平。
转向
转向范围由 AAU 使波束偏离视轴并保持低 SLL 的能力决定。随着波束偏离视轴,旁瓣有增大的趋势。纵向上转向范围往往受到栅瓣的限制。栅瓣导致 SLL 超出规定的限值。
对于一个 64T64R AAU (SLL≤-10dB),动态转向范围典型值是横向 ±45 度,纵向 ±5 度。对于每列只有两个单元子阵列的 32T32R AAU,纵向转向范围更小。对于大多数宏基站, ±2 度已经足够。
预倾角
宏基站 AAU 常安装在高架站点。从天线的角度来看,用户流量大部分来自水平线以下。因为纵向转向范围受限,天线在安装时常带有预倾角。实现方式可以是机械方式,也可以通过在子阵列间形成线性渐变相位差(图1)。预倾角常见于收发器不超过 32 个的 AAU。
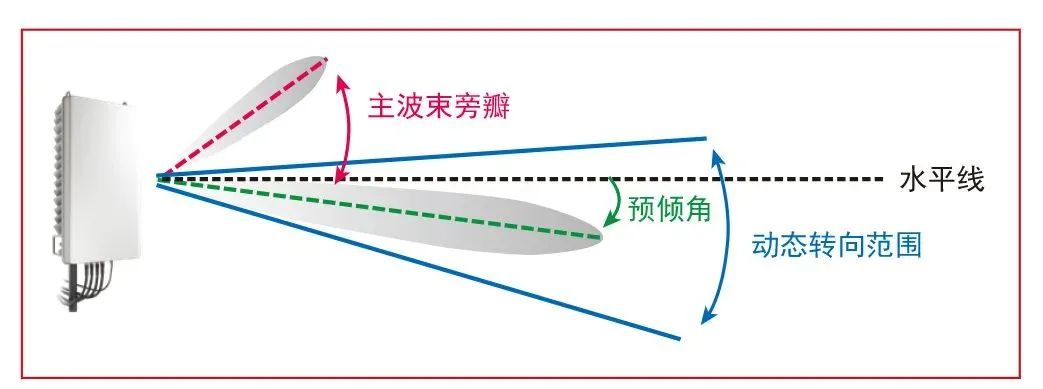
图1 天线波束纵向转向和预倾角。
上下滑动查看更多内容
远程电倾斜
远程电倾斜(RET)能远程调节 AAU 的预倾角。实现方法较为简单,或远程调节内置在子阵列中的移相器,或使用电机驱动的支架改变天线的倾斜。与预倾角相似,远程电倾斜一般也只用于收发器数量不大于 32 个的 AAU,因为与收发器数量更多的 AAU 相比,它们的纵向转向范围有限。
RF信号链
与天线相连的 RF 信号链在发送功率、带宽和误差矢量幅度(EVM)方面影响 AAU 的性能。
传导RF功率——功率放大器(PA)向天线提供的发送功率也被称为传导 RF 功率,决定了最大覆盖范围和蜂窝最大容量。发送功率和天线增益共同决定着链路能承受的最大传播损耗。在 mMIMO AAU 中,RF 功率分布在多个空间流和资源块(RB)上。对于较大蜂窝而言,提高 PA 功率能增大蜂窝的下行链路容量。
带宽
三个带宽与 AAU 有关。首先是占用带宽(OBW)。它是 AAU 主动发送和接收时使用的总带宽。与占用频谱同义,OBW 是所有活动载波带宽之和,也是RU能处理的上限。其次是 AAU 的瞬时带宽(IBW)。它是最低载频左边缘到最高载频右边缘的带宽。最后是工作带宽,也就是 AAU 支持的带宽。一般也被称为工作频段。为了获得频谱敏捷性,运营商要求 RU 的 IBW 能够为整个频段提供支持,也就是 IBW 应等于 OBW。
误差矢量幅度(EVM)
EVM 是衡量调制信号失真度、体现发送链路线性度的指标。在大多数高效的调制方案中,如 256-QAM 或 1024-QAM,更多比特被映射到副载波。与较低阶的调制相比,这需要不断提高发送信号的质量。发送链路中的非线性增大了发送信号的噪声,导致星座点偏离理想值,使得接收器解调发送信息更加困难。
产品
除了天线和 RF 信号链,设计还从这些方面影响 mMIMO AAU 系统的性能:数据流数量、相位与幅度控制和校准、前传、可编程性、安全性和功耗。
数据流数量
mMIMO 架构的目的是利用空间域增大数据容量。如果传播条件允许用户分开,RU 能处理的空间流数量是有限的。对于 64T64R AAU 而言,通常认为能够处理 16 层下行链路和 8 层上行链路就足以满足要求。而对于 32T32R AAU 而言,空间可解析信号的数量会变少。为了降低前传数据速率,32T32R AAU 常使用 8 个下行链路流和 4 个上行链路流。
相位与幅度控制和校准
3GPP 标准规定了 5G 信号的结构。3虽然规定了用于生成通道和信号的方法,但 3GPP 标准没有明确接收器应如何处理信号。这方面的算法留给设备设计师处理。
类似地,3GPP 标准也没有对无线电资源管理器(RRM)所使用的算法做出规定。RRM 的功能是通过向用户分配 RB 并控制调制和误差编码等参数,让基站向用户合理分配无线电资源,以最大限度提升蜂窝容量与覆盖率,并改善用户体验。
在 mMIMO 中,RRM 还用于控制波束赋形矢量等参数。某些算法可能需要特定的波束形状,对将相应的波束赋形图型下载到 AAU 后产生的旁瓣电平也有要求。为获得准确的波束形状,辐射单元的实际幅度和相位一定不得显著偏离波束赋形矢量定义的值。主瓣对幅度偏差和相位偏差的要求相对不那么严格。仿真证明,相位偏差最大 5 度,幅度偏差最大 0.5dB,不会对波束总体形状造成“可察觉”的影响。在时分复用(TDD)系统中,上行链路和下行链路共享同一频段,DU 可以利用传播通道的逆特性。例如,DU 可以使用上行链路估算值推导下行链路波束权重矢量。因此,AAU 应确保发送器和接收器不劣化共享通道的可逆性。为了让用户避开其他用户信号的干扰,DU 必须能够在其他用户方向上的波束图型中布置 -35 到 -40dB 的凹槽。如果在假设具有可逆性的情况下计算这些凹槽,收发器的相位差和幅度差必须分别不大于 1 度和 1dB。
由于组件参数会随温度、电压和使用年限发生变化,因此需要用精确的闭环校准来保持所需的精度。所需的校准频次随部署场景和地域发生变化,因此,mMIMO 设计应允许在多种精度和校准频次间做出选择。
前传
前传(FH)负责将 DU 连接到 RU。一般而言,RU 和 DU 应通过技术手段缩小FH带宽,因为带宽会增大互联解决方案的成本,即线缆、交换机和收发器的成本会随带宽增大而增大。O-RAN “控制面、用户面与同步面规范”定义了几种减少 FH 流量的压缩方法。4对于用户面而言,它规定了各种比特宽度,该规范以调制压缩为最主要方法,这种方法是将调制函数转移到 RU。DU 将原始的未调制比特发送到 RU,无需发送频域符号。通过将用户面划分为不同的段,通过 FH 接口即可发送被使用的符号。控制面流量包括更新波束赋形矢量。在 5G 中,这些矢量可以随每一个正交频分复用(OFDM)符号更新。在每个时隙更新矢量,构成了超过 30% 的FH流量。因此,O-RAN 联盟已经推出了减少控制面流量的方法。O-RAN 标准使用索引,将波束赋形矢量存储在 O-RAN AAU 上的数据库中。通过引用相应的索引,就能从这个数据库检索出存储的波束赋形矢量。这样就能更新波束赋形矢量。此外,O-RAN 标准也支持在 AAU 中计算波束赋形矢量。但是这种方法并没有完全实现标准化,造成 DU 可能不知道计算的实际结果,使这种方法的使用受到限制。
O-RAN 联盟正在制定互操作性配置文件,以便 AAU 兼容多家厂商的 DU。只要 AAU 遵循所选的互操作性测试(IOT)配置文件,就能确保互操作性。
可编程性
5G O-RAN 系统中的 mMIMO 仍然相对较新,需要在现场应用中完善。部署后的现场使用经验很可能要求 AAU 增加功能以提升系统性能。由于蜂窝网络中设备的更换成本相当高昂,因此在设计上应支持设备在部署后拥有较长的使用寿命,至少应达到七年。为实现这个目标,AAU 必须具备固有的灵活性,能通过更新获得新功能,无论是 AAU 主控制器中的软件,还是数据路径上的功能。
O-RAN 联盟将通过增加压缩方法(更高效地利用可用的FH带宽),继续提升FH性能。方法之一是在 AAU 中为半持续调度(SPS)提供支持。如果将 SPS 信息发送给 AAU,调度信息只需发布一次。如果欠缺这项功能的可用 FH 带宽制约着波束赋形矢量的更新速率,在 AAU 中启用 SPS,将释放带宽,从而提升系统性能。在其他常发生更新的例子中,启用 SPS 将改善 DFE 中的线性度、降低功耗,并改善温度控制。
灵活的 AAU 架构设计让制造商能在新技术问世后立即采用,还能针对各种市场需求定制衍生产品。为了更新已经部署到现场的单元,O-RAN 联盟已经制定了通过移动面进行现场升级的标准。
安全
为保护基础设施免受攻击,RU 必须具备安全机制,包括针对软件更新的认证和完整性检查。
功耗
RU 的功耗增大了网络的运营开销,当数千部单元投入使用,每部耗电约 1kW,能耗成本相当可观。mMIMO 基站的功耗取决于负载、瞬时 RF 输出功率和系统效率。满载时功耗主要由 PA 和发送链路效率决定。虽然 PA 效率相当重要,PA 与天线间的损耗以及接收链路、数字电路和电源稳压器的功耗也必须最小化。
多数情况下,AAU 的最大负载发生在每天高峰时段的极端状况下。典型负载状况和低负载状况下的功耗也应优化。这一般通过使用 AAU 省电方法来实现,如关闭 PA,甚至关闭完整的载波。除了 RF 辐射功率,AAU 消耗的功率被转换成热量,需要高效率地耗散到周边环境中,以最大限度降低电子装置的温度。功耗推动系统的散热设计,增大 AAU 的尺寸和重量。
机械与环境
AAU 的尺寸是一项重要要求,因为塔台或电杆上可供安装使用的空间有限。在某些情况下,现有的多频段无源天线上方的空间刚够安装一个 5G 面板,前提是它不太高。风载也是一个重要因素,因为电杆和塔台构件的建造和认证需要满足最大风载要求。基站一般要求在最大风速 150km/h下保持正常运行,在最大风速 200km/h下不发生损坏。AAU 的风载与它的表面积(即面板尺寸)和它的外形有关。圆润化边缘,并采用专用鳍片,可以在不改变外形尺寸的情况下降低风载。
AAU 的重量决定安装成本。需要多少技术人员安装设备?是否需要车载式升降台等设备辅助安装?在某些情况下,塔台公司会按风载和重量收取租金,这增大了运营商的月开支。
对所有无线电设计都适用的其他常见要求包括:
工作温度范围,通常在 -40°C 至 +55°C。为保障单元可靠运行,较高温度下需降低输出功率。
由于 AAU 内含大量组件,长于 200,000 小时的典型平均故障间隔时间(MTBF)成为一个难题。浪涌保护,保护 AAU 免受雷击破坏。
防护等级,一般额定标准 IP65。
美观大方。
O-RAN Split7.x mMIMO
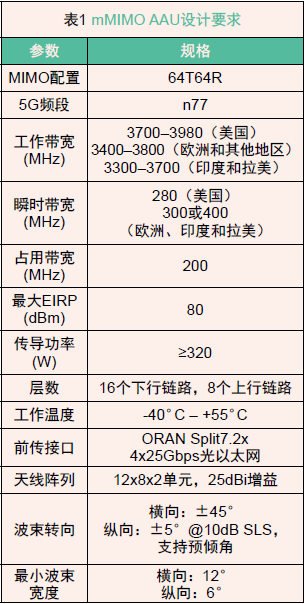
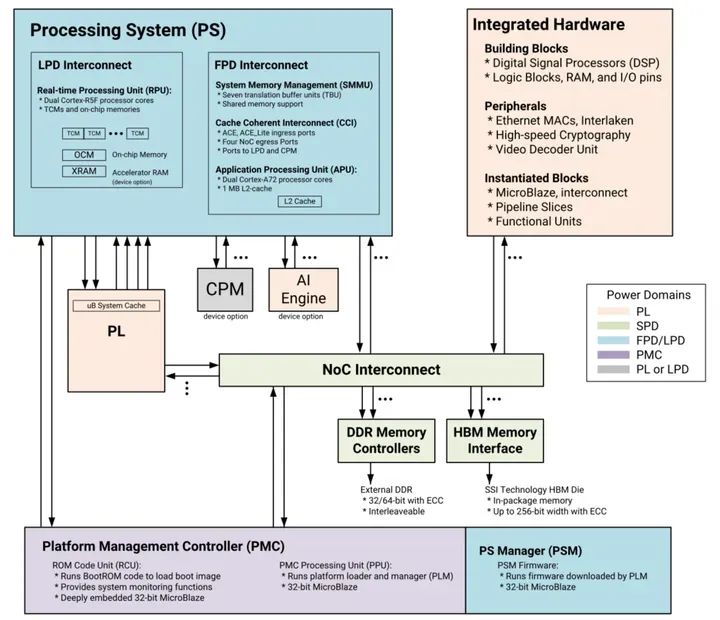
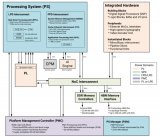
为加快 mMIMO AAU 在 O-RAN 中的部署,AMD 赛灵思已基于 AMD 赛灵思IC技术开发出参考设计与原型(图2)。作为示例,表1列出的是对覆盖 5G 频段 n77 的 64T64R mMIMO AAU 的设计要求。该单元采用了 AMD 赛灵思架构和芯片组实现。
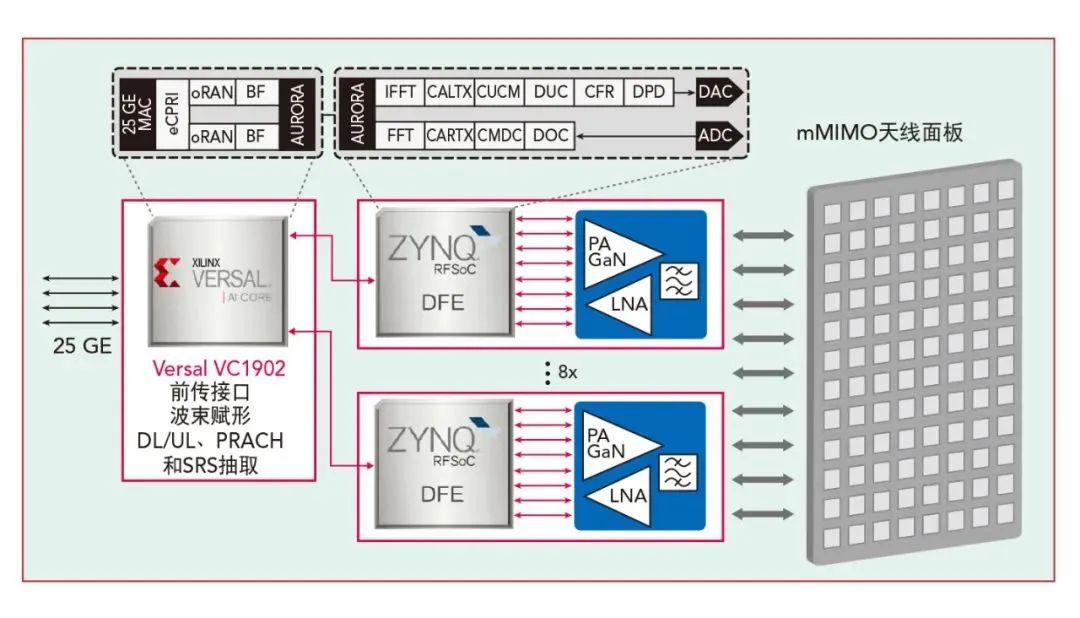
图2 AMD 赛灵思 64T64R AAU 硬件架构。
O-RAN FH 接口、波束赋形器、物理随机接入信道(PRACH)和探测用参考信号(SRS)抽取均实现在单片 Versal VC1902 SoC 上。Versal ACAP 是一种完全软件可编程异构计算平台。它融合灵活应变的标量引擎与智能引擎,提供优于最高速 FPGA 实现方案高达 20 倍、最高速 CPU 实现方案百倍以上的性能提升。6Versal 器件内置功能强大的 ARM 处理器子系统、可编程逻辑(PL)和 AI 引擎。AI 引擎是超长指令字、单指令多数据矢量处理引擎,很适合高效计算波束赋形器运算,如矩阵乘法、奇异值分解,以及逆矩阵(若需要)。7
Zynq UltraScale+ RFSoC 主要针对 RF 应用而设计。它集成了实现直接 RF 采样收发器所需的主要子系统。其采用16nm FinFET CMOS 技术的高性能数据转换器是大量投资的成果。每个 Zynq UltraScale+ RFSoC 内置多个 GSPS 模数和数模数据转换器。这些转换器具有高精度、高速度、高能效,且高度可配置。
最新一代 Zynq UltraScale+ RFSoC,也被称为 Zynq UltraScale+ RFSoC DFE,专门提供通信中常用的数字功能。它们支持各种类型的蜂窝应用,包括工作在 sub-6GHz (FR1)频段和毫米波(FR2)频段的室内基站、宏基站和 FR1 mMIMO AAU。DFE的专用逻辑功能经过优化,可扩展、可参数化。这些逻辑功能用标准单元硬化块开展计算,与 PL 相结合后,能适应不同的应用需求。标准单元硬化块的性能可媲美 ASIC,与此同时 PL 提供 FPGA 所具备的灵活性。综合这两种功能,Zynq UltraScale+ RFSoC DFE 提供了相当于上代 RFSoC 两倍的性能,同时功耗减半。
逻辑块用于滤波、数字升频/降频(DUC和DDC)、内插和抽取、峰值因子减少(WCFR)和数字预失真(DPD)。
其他逻辑块还包括 OFDM 调制常用的快速傅里叶变换(FFT)。因为 O-RAN 联盟选择了 7.2 功能划分,这项功能归属于RU。
RFSoC 上未使用的 FPGA 容量用于补充功能,方便 AAU 部署到现场后追加新功能。
图3所示的是使用 AMD SoC 和 GaN PA 的 320W 功率 64T64RmMIMO 无线电单元的各组件能耗对比。65% 的功耗来自模拟组件,如 PA 和驱动器。17% 的功耗来自 RFSoC DFE。其中相当一部分用于模数转换和 DFE 功能。ASIC 实现方案中存在同样的情况。
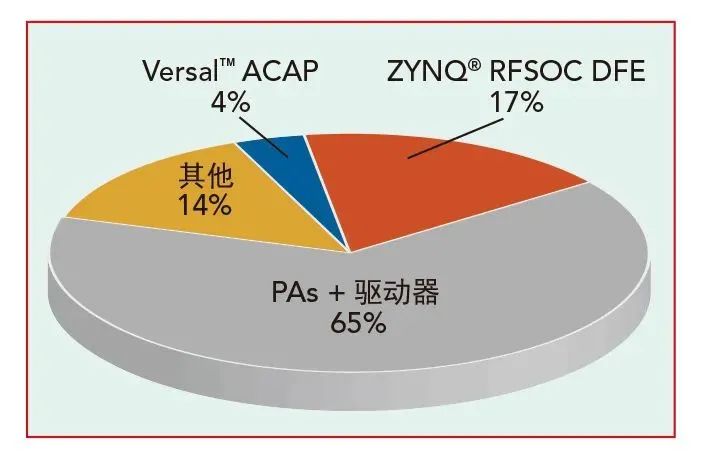
图3采用 AMD 赛灵思 SoC 和 GaN PA 的320W功率
64T64R mMIMO 无线电单元的组件能耗。
AAU的性能
AMD 针对北美 n77 频段制作了这个 AAU 的原型并对其测试。根据 3GPP 规范测试并比较发送、接收和波束赋形性能。用是德科技的 DU 模拟器仿真使用 O-RAN FH 接口的 AAU。图 4 所示的是 256-QAM 调制下 100MHz 信号带宽、8.8dB CFR 时该 AAU 的测试性能。测得的 RF 输出功率满足每端口 37dBm (5W)的要求,EVM 指标良好,在物理下行链路共享信道(PDSCH)上仅有 2.6%。测得的邻道泄漏比(ACLR)为 -49dBc,证明数字预失真算法有效地线性化 GaN PA,满足泄漏要求。频率对准误差与时间对准误差符合 3GPP 规范要求,定义的信号带宽为 97.3MHz,符合具体要求。
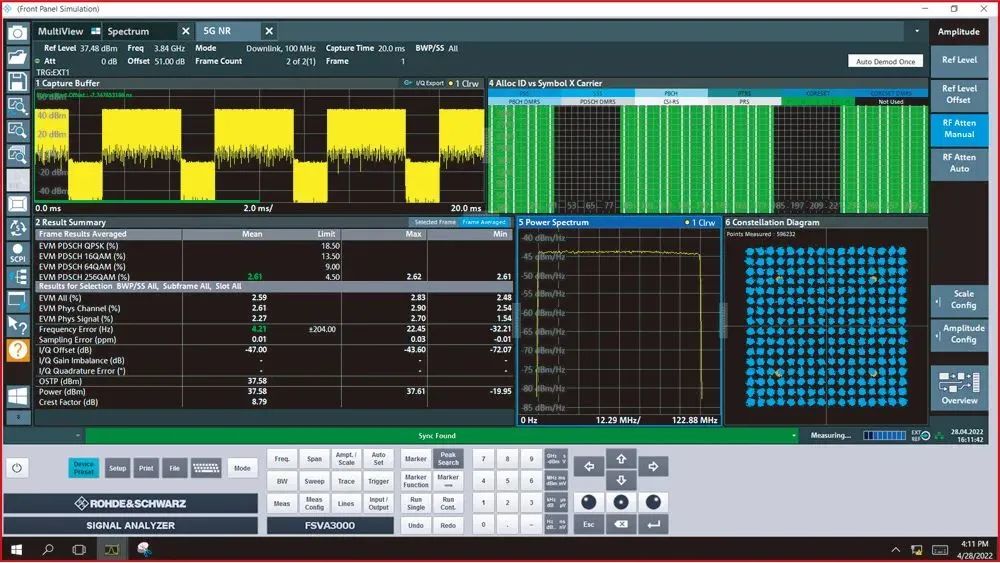
图4 100MHz带宽256-QAM调制信号的EVM测量。
使用该 AAU 的全部 64 个收发器,在暗室内测量空中的波束赋形性能。测量结果与天线层测量结果比对(参见图5)。天线被设置在视轴上,即横向转向角和纵向转向角均为0度,并使用均匀系数的波束赋形矢量。对于 ±45 转向范围,两图在 0 到 30 度范围重叠,在 30 到 45 度范围有一定差异。
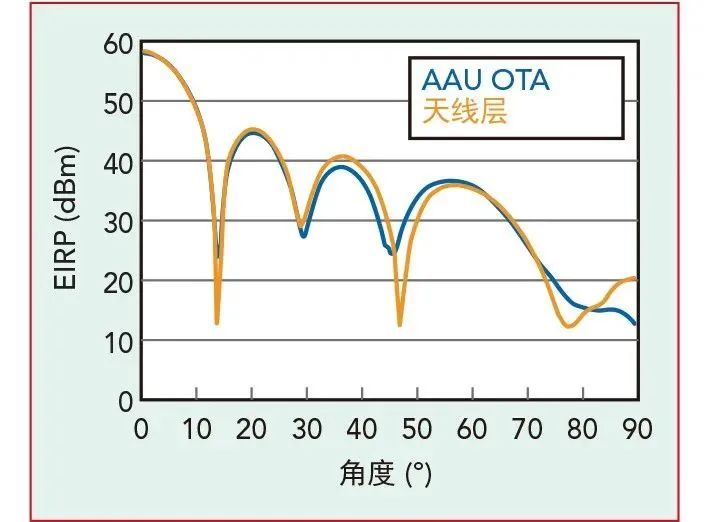
图5 天线层和AAU OTA波束赋形测量。
总结
O-RAN 生态系统尚处于发展初期。O-RAN 系统正在与资深网络设备制造商提供的端到端解决方案竞争。要获得市场认可,O-RAN 解决方案需要在成本低于现有厂商提供的解决方案的情况下,提供不亚于甚至更优秀的性能。
mMIMO AAU 因其架构新、历史短,平添一层不确定性。只有在天线塔上能可靠运行数年,不必拆下进行更新或维护,mMIMO 面板的安装成本才具有合理性。值得关注的是,mMIMO 的性能肯定会随时间不断提升,主要来自软件改进和算法改进。因此如果现场部署当前一代的硬件,其必须能灵活地接纳提升系统性能的新功能。
AMD 赛灵思 UltraScale+ RFSoC DFE 向 mMIMO 应用提供直接RF采样收发器平台。它兼具媲美 ASIC 的性能,FPGA 的灵活性和适中的功耗。测量证明,采用这种 SoC 解决方案能够达成 3GPP 规范和 O-RAN 联盟要求的性能目标。通过将高性能和高度灵活的功能引入 O-RAN,AMD 赛灵思希望加快市场对 O-RAN 和 mMIMO AAU 的采用。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19252浏览量
229628 -
amd
+关注
关注
25文章
5466浏览量
134068
原文标题:面向mMIMO的Open RAN无线电单元架构
文章出处:【微信号:赛灵思,微信公众号:Xilinx赛灵思官微】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用 AMD Versal AI 引擎释放 DSP 计算的潜力
AMD Vivado Design Suite 2024.2全新推出
使用AMD Versal AI引擎加速高性能DSP应用
AMD推出第二代Versal Premium系列
思尔芯亮相芯和半导体大会,以数字前端EDA解决方案应对设计新挑战

戴尔灵越14灵龙采用第二代AMD AI PC处理器
使用STM32F407ZGT6的设备无法连接到AMD处理器的电脑上,怎么处理?
戴尔计划2027年推出搭载AMD处理器的XPS 16笔记本
AMD Versal™ Adaptive SoC CPM PCIE PIO EP设计CED示例
AMD EPYC 8004系列处理器优势介绍

什么是模拟前端芯片技术 数字前端和模拟前端的区别
【ALINX 技术分享】AMD Versal AI Edge 自适应计算加速平台之 Versal 介绍(2)
AMD Versal AI Edge自适应计算加速平台之Versal介绍(2)
AMD收购赛灵思两周年之际,全新Embedded+进一步彰显协同效应
第五届EDA挑战赛赛果公布!思尔芯“战队”成绩斐然





 工商网监
工商网监
评论