 基于Open3D的Lidar-Segment
基于Open3D的Lidar-Segment
1. Open3D-ML安装和使用
首先对于Open3d,我们要先对源码下载
# make sure you have the latest pip version pip install --upgrade pip # install open3d pip install open3d
然后选择要安装兼容版本的PyTorch或TensorFlow,Open3d中提供了两种安装方式:
# To install a compatible version of TensorFlow pip install -r requirements-tensorflow.txt # To install a compatible version of PyTorch with CUDA pip install -r requirements-torch-cuda.txt
这里作者选择的是Pytorch,因为作者对Pytorch比较熟悉,然后使用下面命令测试Open3d是否安装成功
# with PyTorch python -c "import open3d.ml.torch as ml3d" # or with TensorFlow python -c "import open3d.ml.tf as ml3d"
下面我们可以下载数据集进行测试了
SemanticKITTI (project page)
Toronto 3D (github)
Semantic 3D (project-page)
S3DIS (project-page)
Paris-Lille 3D (project-page)
Argoverse (project-page)
KITTI (project-page)
Lyft (project-page)
nuScenes (project-page)
Waymo (project-page)
ScanNet(project-page)
这里选择了SemanticKITTI的数据集进行测试
# Launch training for RandLANet on SemanticKITTI with torch. python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path--pipeline SemanticSegmentation --dataset.use_cache True # Launch testing for PointPillars on KITTI with torch. python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --split test --dataset.dataset_path data --pipeline SemanticSegmentation --dataset.use_cache True --batch_size 16
虽然官方提供的predefined scripts非常便捷,但是既然我们装好了Open3d,那我们就可以通过自己编写代码的方式来完成。
2. 基于Open3d的二次开发
下面将展示如何自己去调用Open3d的api去写训练集、测试集、可视化
模型训练:
import os import open3d.ml as _ml3d import open3d.ml.torch as ml3d cfg_file = "ml3d/configs/randlanet_semantickitti.yml" cfg = _ml3d.utils.Config.load_from_file(cfg_file) cfg.dataset['dataset_path'] = "./data" dataset = ml3d.datasets.SemanticKITTI(cfg.dataset.pop('dataset_path', None), **cfg.dataset) # create the model with random initialization. model = ml3d.models.RandLANet(**cfg.model) pipeline = ml3d.pipelines.SemanticSegmentation(model=model, dataset=dataset,device="cuda:0", **cfg.pipeline) # prints training progress in the console. pipeline.run_train()
在这里主要需要侧重关注的有两处:cfg_file和cfg.dataset['dataset_path'],这两处分别是环境配置和数据集设置。
在randlanet_semantickitti.yml中里面包含了所有需要配置的内容
randlanet_semantickitti.yml
dataset: name: Semantic3D dataset_path: # path/to/your/dataset cache_dir: ./logs/cache_small3d/ class_weights: [5181602, 5012952, 6830086, 1311528, 10476365, 946982, 334860, 269353] ignored_label_inds: [0] num_points: 65536 test_result_folder: ./test use_cache: true val_files: - bildstein_station1_xyz_intensity_rgb - domfountain_station1_xyz_intensity_rgb steps_per_epoch_train: 500 steps_per_epoch_valid: 10 model: name: RandLANet batcher: DefaultBatcher ckpt_path: # path/to/your/checkpoint num_neighbors: 16 num_layers: 5 num_points: 65536 num_classes: 8 ignored_label_inds: [0] sub_sampling_ratio: [4, 4, 4, 4, 2] in_channels: 6 dim_features: 8 dim_output: [16, 64, 128, 256, 512] grid_size: 0.06 augment: recenter: dim: [0, 1] normalize: feat: method: linear bias: 0 scale: 255 rotate: method: vertical scale: min_s: 0.9 max_s: 1.1 noise: noise_std: 0.001 pipeline: name: SemanticSegmentation optimizer: lr: 0.001 batch_size: 2 main_log_dir: ./logs max_epoch: 100 save_ckpt_freq: 5 scheduler_gamma: 0.9886 test_batch_size: 1 train_sum_dir: train_log val_batch_size: 2 summary: record_for: [] max_pts: use_reference: false max_outputs: 1
模型测试:
import os import open3d.ml as _ml3d import open3d.ml.torch as ml3d cfg_file = "ml3d/configs/randlanet_semantickitti.yml" cfg = _ml3d.utils.Config.load_from_file(cfg_file) model = ml3d.models.RandLANet(**cfg.model) cfg.dataset['dataset_path'] = "./data" dataset = ml3d.datasets.SemanticKITTI(cfg.dataset.pop('dataset_path', None), **cfg.dataset) pipeline = ml3d.pipelines.SemanticSegmentation(model, dataset=dataset, device="cuda:0", **cfg.pipeline) # download the weights. ckpt_folder = "./logs/" os.makedirs(ckpt_folder, exist_ok=True) ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth" randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth" if not os.path.exists(ckpt_path): cmd = "wget {} -O {}".format(randlanet_url, ckpt_path) os.system(cmd) # load the parameters. pipeline.load_ckpt(ckpt_path=ckpt_path) test_split = dataset.get_split("test") print("len%d",test_split) data = test_split.get_data(0) # run inference on a single example. # returns dict with 'predict_labels' and 'predict_scores'. result = pipeline.run_inference(data) # evaluate performance on the test set; this will write logs to './logs'. pipeline.run_test()
在模型测试中和模型训练一样也需要cfg_file和cfg.dataset['dataset_path'],但是同时需要加入ckpt_path作为训练模型的导入。
模型可视化
import os
import open3d.ml as _ml3d
import open3d.ml.torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d.utils.Config.load_from_file(cfg_file)
cfg.dataset['dataset_path'] = "./data"
# construct a dataset by specifying dataset_path
dataset = ml3d.datasets.SemanticKITTI(cfg.dataset.pop('dataset_path', None),**cfg.dataset)
# get the 'all' split that combines training, validation and test set
all_split = dataset.get_split('test')
# print the attributes of the first datum
print(all_split.get_attr(0))
# print the shape of the first point cloud
print(all_split.get_data(0)['point'].shape)
# show the first 100 frames using the visualizer
vis = ml3d.vis.Visualizer()
vis.visualize_dataset(dataset, 'all', indices=range(100))
模型可视化就没什么好说的了,基本上和上述两种差不不多,只是使用了ml3d.vis.Visualizer()做了可视化。
3. 如何理解SemanticKITTI数据集
KITTI Vision Benchmark 的里程计数据集,显示了市中心的交通、住宅区,以及德国卡尔斯鲁厄周围的高速公路场景和乡村道路。
原始里程计数据集由 22 个序列组成,将序列 00 到 10 拆分为训练集,将 11 到 21 拆分为测试集。
SemanticKITTI数据集采用和 KITTI 数据集相同的标定方法。这使得该数据集和kitti数据集等数据集可以通用。
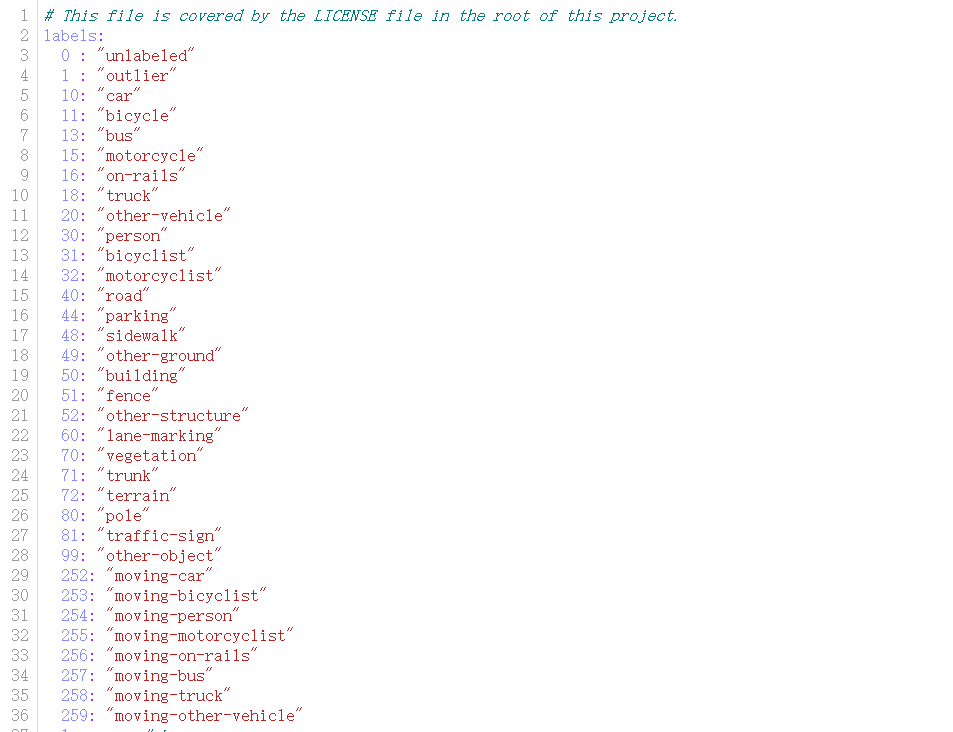
该数据集中对28个类进行了注释,确保了类与Mapillary Visiotas数据集和Cityscapes数据集有很大的重叠,并在必要时进行了修改,以考虑稀疏性和垂直视野。
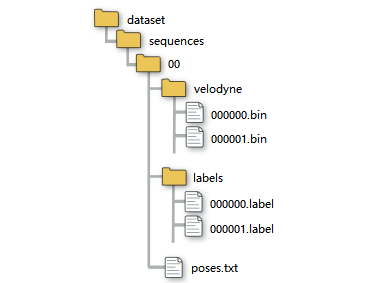
bin文件中存储着每个点,以激光雷达为原点的x,y,z,i信息,其中i是强度。
把数据提取出来也很简单。用numpy库。提取出来就是一个n行4列的矩阵。
points = np.fromfile(".bin文件路径", dtype=np.float32).reshape(-1, 4)
接下来就是.label文件,在KITTI API的github中能找到说明。
里面东西也挺多的,主要就看.label那部分。
在remap_semantic_labels.py文件中。终于知道,label中每个值表示什么了。
在config目录下的semantic-kitti.yaml文件中。
label = np.fromfile(".label文件路径", dtype=np.uint32)
label = label.reshape((-1))
我们还区分了移动和非移动车辆与人类,即,如果车辆或人类在观察时在某些扫描中移动,则会获得相应的移动类别。
下图列出了所有带注释的类,补充材料中可以找到对不同类的更详细讨论和定义。
总之,我们有28个类别,其中6个类别被指定为移动或非移动属性
每个velodyne文件夹下的xxxx.bin文件为每次扫描的原始数据,每个数据点的标签的二进制表示储存在文件xxxx.label中。
每个点的标签是32位无符号整数(也称为’uint32_t’),其中较低的16位对应于标签。
较高位对应了16位编码实例id,该id在整个序列中时间上是一致的,即两次不同扫描中的同一对象获得相同的id。
这也适用于移动车辆,但也适用于环路闭合后看到的静态对象。
这里是开源SemanticKITTI的API。功能包括但不限于:可视化、计算IOU等。按照脚本的介绍即可完成使用。
审核编辑:汤梓红
-
开源
+关注
关注
3文章
3356浏览量
42512 -
源码
+关注
关注
8文章
641浏览量
29224 -
pytorch
+关注
关注
2文章
808浏览量
13232
原文标题:基于Open3D的Lidar-Segment
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
浅谈SiPM 传感器在汽车 LiDAR的应用
LiDAR如何构建3D点云?如何利用LiDAR提供深度信息
Atmel Segment LCD1用户指南
TriLumina将推出940nm VCSEL照明,包罗3D LiDAR系统
微雪电子STM32开发板 Open32F3-D简介

微雪电子STM32开发板 Open32F3-D简介
微雪电子STM32开发板 Open32F3-D简介

日本Konami与假Open Bionic合作,推出了一款3D打印的仿生手臂
如何在LiDAR点云上进行3D对象检测

Quanergy和PARIFEX合作发布基于3D LiDAR的超速抓拍系统
3D LiDAR 社交距离解决方案

彻底搞懂基于Open3D的点云处理教程!

应用于机器人3D感知的高精度LiDAR与电机驱动解决方案
基于LiDAR的行人重识别的研究分析





 工商网监
工商网监
评论