 一种新的混合SoC处理器—GPNPU!
一种新的混合SoC处理器—GPNPU!

Performance, Power, Area(PPA)是半导体行业中常用的衡量标准。这三个指标对开发的所有电子产品都产生了巨大的影响。影响的程度当然取决于具体的电子产品以及目标终端市场和应用。因此,PPA权衡决策由产品公司在为各自的终端产品选择各种芯片(以及ASIC的IP)时做出。
另一个重要的考虑因素是在不需要重新设计的情况下确保产品的寿命。换句话说,就是让自己的产品适应不断变化的市场和产品需求。虽然产品公司在重新设计之前会采用辅助方法来延长产品的使用寿命,但直接提供future proofing的解决方案是首选的方法。例如,在需求快速变化的市场积极增长时期,FPGA在面向未来的通信基础设施产品中发挥了关键作用。当然,替代路径可能比FPGA路径提供更好的PPA收益。但是FPGA路径通过避免重新设计帮助产品公司节省了大量的时间和金钱,并确保他们能够保持或增长他们的市场份额。
还有一个考虑因素是,开发产品的路径可以提供方便和速度。这直接转化为上市时间,进而转化为市场份额和盈利能力。最后,客户可以轻松地在产品上开发应用软件。
市场情况
人工智能(AI)驱动的、支持机器学习(ML)的产品和应用正在快速增长,并带来巨大的市场增长机会。新的ML模型正在快速引入,现有的模型也在增强。市场机会范围从数据中心到边缘人工智能产品和应用。许多针对这些市场的产品无法在PPA和产品/应用程序开发的易用性之间进行权衡。
如果有一种方法可以提供PPA优化、future proofing、便于产品和应用程序开发,所有这些都集中到一个产品中会怎么样呢?它是一个统一的体系结构,简化SoC硬件设计和编程的混合处理器IP。可以解决ML推理、预处理和后处理的一体化问题。
新型混合SoC处理器
最近,Quadric宣布了第一个通用神经处理器(GPNPU)系列,这是一种半导体知识产权(IP)产品,融合了神经处理加速器和数字信号处理器(DSP)。IP使用一个统一的体系结构,解决ML性能特征和DSP功能,具有完全的C++可编程性。本文将从一个典型的支持ML的SoC架构的组件、其局限性、Quadric产品、优点和可用性等方面展开介绍。
典型的支持ML的SoC架构的组件
支持ML架构的关键组件包括神经处理单元(NPU)、数字信号处理(DSP)单元和实时中央处理单元(CPU)。NPU用于运行当今最流行的ML网络的图形层,并且在已知的推理工作负载上表现非常好。DSP用于有效地执行语音和图像处理,并涉及复杂的数学运算。实时CPU用于协调NPU、DSP和存储ML模型权重的内存之间的ML工作负载。通常,只有CPU可直接供软件开发人员用于代码开发。NPU和DSP只能通过预定义的应用程序编程接口(API)访问。
典型架构的局限性
如上所述,典型的加速器NPU不是完全可编程的处理器。虽然它们非常高效地运行已知的图形层,但它们不能随着ML模型的发展而运行新的层。如果需要通过API不可用的ML操作符,则需要将其添加到CPU上,因为知道它的性能会很差。该架构不适合新ML模型和ML操作符的future proofing。充其量,可以通过在实时CPU上实现新的ML操作符来呈现性能较低的解决方案。
另一个限制是,程序员必须在NPU、DSP和实时CPU上划分代码,然后调整交互以满足期望的性能目标。典型的架构还可能导致在NPU核和CPU核之间拆分矩阵操作。由于需要在内核之间交换大数据块,因此此操作会导致推断延迟和功耗问题。
来自不同IP供应商的多个IP核迫使开发者依赖于多个设计和生产力工具链。必须使用多个工具链通常会延长开发时间,并使调试具有挑战性。
Quadric方法的好处
Quadric的Chimera GPNPU家族为ML推理和相关的传统C++图像、视频、雷达和其他信号处理创建了统一的单核体系结构。这允许将神经网络和C++代码合并到单个软件代码流中。内存带宽通过单一的统一编译堆栈进行优化,并使功耗显著减小。编程单核系统也比处理异构多核系统容易得多。标量、向量和矩阵计算只需要一个工具链。
统一的Chimera GPNPU架构的其他好处包括,由于不必在NPU、DSP和CPU之间移动激活数据,从而节省了面积和功耗。统一的核心架构大大简化了硬件集成,使性能优化任务更加容易。
分析内存使用情况以确定最佳片外带宽的系统设计任务也得到了简化。这也直接导致了功率最小化。
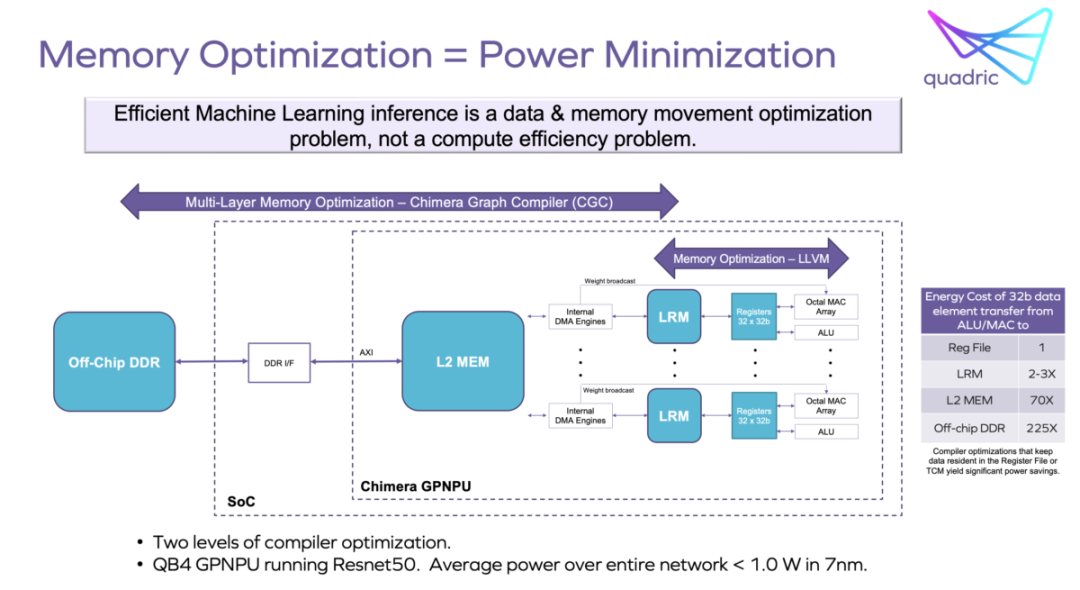
应用程序开发
Chimera软件开发工具包(SDK)允许通过两步编译过程将来自通用ML训练工具集的图代码与客户的C++代码合并。这导致可以在统一的Chimera单处理器核心上运行的单一代码流。目前广泛使用的ML训练工具集有TensorFlow、PyTorch、ONNX和Caffe。实现的SoC的用户将拥有对Chimera所有核心资源的完全访问权,以实现应用程序编程的最大灵活性。整个系统也可以从单个调试控制台进行调试。
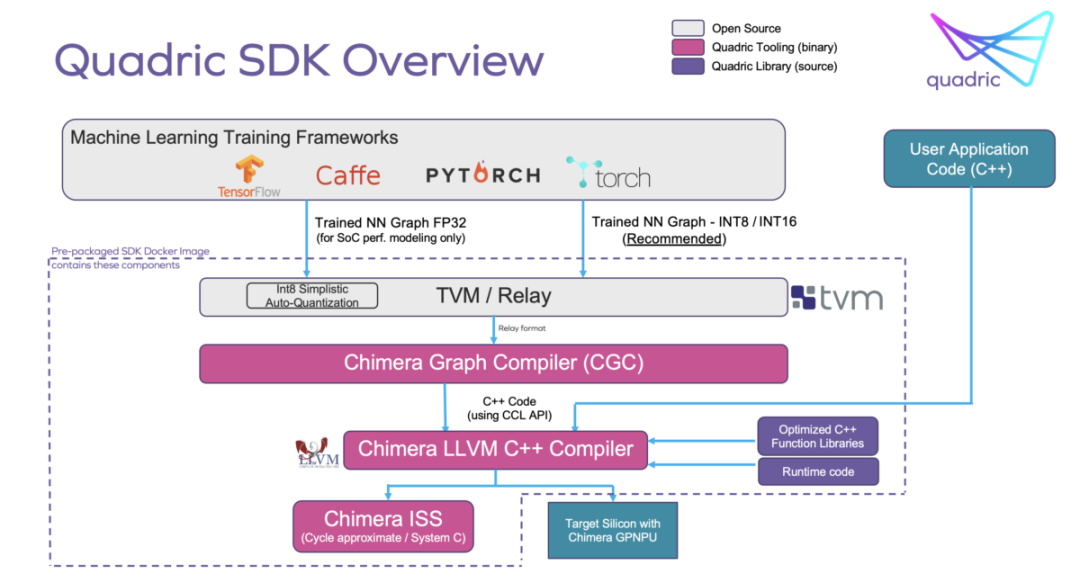
在不损失性能的情况下实现future proofing
Chimera GPNPU架构擅长处理卷积层,这是卷积神经网络(CNNs)的核心。Chimera GPNPU可以运行任何ML操作符。通过使用Chimera计算库(CCL) API编写C++内核并使用Chimera SDK编译该内核,可以添加自定义ML操作符。自定义运算符的性能与本地运算符相同,因为它们利用了Chimera GPNPU的相关核心资源。
SoC开发人员可以在SoC被剥离后很长时间内实现新的神经网络运算符和库。这本身就大大增加了芯片的使用寿命。
软件开发人员可以在产品的整个生命周期中继续优化他们的模型和算法的性能。他们可以添加新的特性和功能,为他们的产品在市场上获得竞争优势。
Quadric的当前产品
Chimera架构已经在芯片领域得到了快速验证。QB系列GPNPU的整个家族可以在主流的16nm和7nm工艺中使用传统的标准电池流和常用的单端口SRAM实现1GHz的工作。Chimera核心可以针对任何芯片铸造厂和任何工艺技术。
Chimera GPNPU系列的QB系列包括三个核心:
Chimera QB1 -每秒1万亿次机器学习运算(TOPS),每秒64千兆次DSP运算(GOPs);
Chimera QB4 - 4 TOPS机器学习,256 GOP DSP;
Chimera QB16–16 TOPS机器学习,1 TOPS DSP;
如果需要,可以将两个或多个Chimera核心配对在一起,以满足更高级别的性能要求。
审核编辑 :李倩
-
处理器
+关注
关注
68文章
20324浏览量
254682 -
soc
+关注
关注
40文章
4619浏览量
230078 -
人工智能
+关注
关注
1819文章
50287浏览量
266826
原文标题:一种新的混合SoC处理器—GPNPU!
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
STA2064:高度集成的信息娱乐应用处理器
用 ISL6323 为 AMD 处理器供电:设计与评估全解析
ADSP-CM40xF系列混合信号控制处理器:高性能与多功能的完美融合
DPU数据处理器的核心功能和应用领域

MAXIM 纳米功耗微处理器监控电路:设计与应用指南
【「龙芯之光 自主可控处理器设计解析」阅读体验】--LoongArch的SOC逻辑设计
【「龙芯之光 自主可控处理器设计解析」阅读体验】--全书概览与概述
瑞芯微SOC智能视觉AI处理器
算力积木+3D堆叠!GPNPU架构创新,应对AI推理需求
MD5信息摘要算法实现二(基于蜂鸟E203协处理器)
Cortex-M0+处理器的HardFault错误介绍
AUDIO SoC的解决方案
德州仪器AM68x Jacinto 8处理器技术解析




评论