 李昂:数据规模不是唯一标准,数据纯度更是重要考量
李昂:数据规模不是唯一标准,数据纯度更是重要考量

2022年11月29日,百度Apollo Day技术开放日活动线上举办。百度自动驾驶技术专家全景化展示Apollo技术实力及前沿技术理念。
随着自动驾驶的规模化落地,数据规模将出现爆发式增长。如何寻找更有价值的数据,如何高效地利用数据提升驾驶能力,成为自动驾驶持续学习和实现规模化的关键。百度自动驾驶技术专家李昂提出了「高提纯、高消化」的数据闭环设计理念,全面强化自动驾驶的数据炼金术。据介绍,该方案的数据提纯路径利用车端小模型和云端大模型,实现高效率数据挖掘和自动化标注;数据消化架构实现自动化训练,具备联合优化和数据分布理解的能力,有效地利用高纯度数据进一步提升自动驾驶系统的整体智能水平。
自动驾驶是一个系统性工程,李昂本次关于数据闭环技术的分享,展现了百度在自动驾驶方面进行的是系统的技术创新:既关注常见的感知、决策、控制环节,又在AI算法最关键的数据提纯、标注和模型训练环节进行大胆创新,用新的技术思路和解题模式提升底层技术的支撑力,最终又反过来能促进感知、决策等环节的发展。
清华大学交叉信息研究院助理教授
博士生导师赵行博士
以下为演讲全文
大家好,我是李昂。我为大家带来百度Apollo对于自动驾驶数据闭环的一些实践与思考。
首先,自动驾驶是一个持续学习的问题。无人车持续地在城市道路中行驶,会遇到各式各样的新问题和很多意想不到的新场景。
根据这台车端回传的视频可以发现,其实在城市道路上遇到一群羊,排着队横穿马路的情况,也不是完全没有可能的。

而这些罕见的长尾场景,对于自动驾驶来说是一个急需解决的问题,这也是自动驾驶需要持续学习的一个重要原因。
当无人车实现大规模的商业化落地,大量的无人车在道路上行驶,持续地去搜集海量的数据。
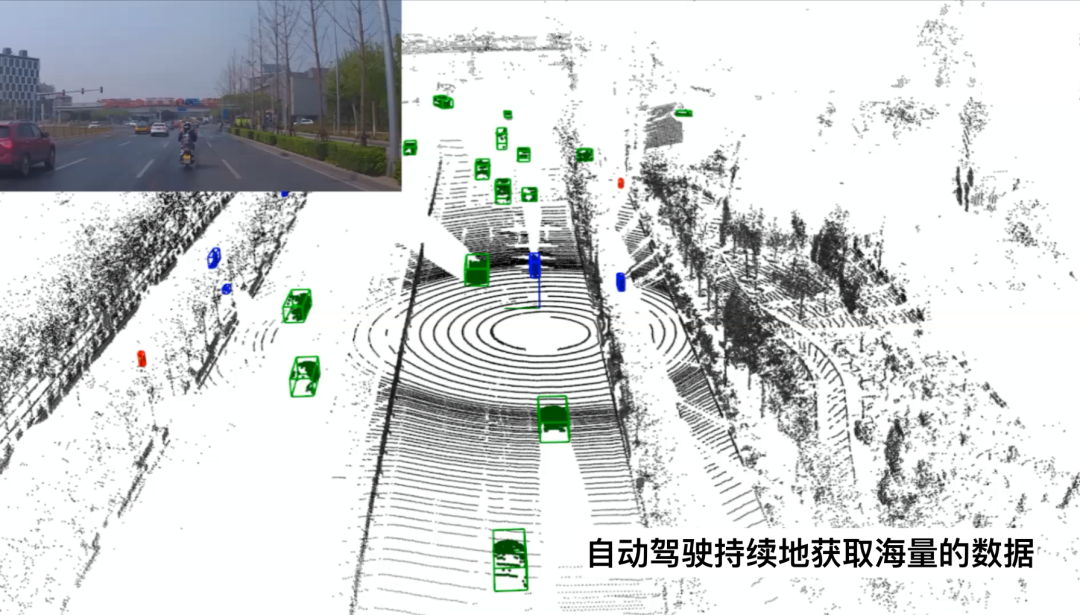
而对于我们的问题是,如何利用好这些大数据,提升无人驾驶整体的安全性与舒适性,这就是数据闭环所需要考虑的一个核心问题。
百度认为数据闭环是无人驾驶最终实现持续学习能力的重要基础架构。
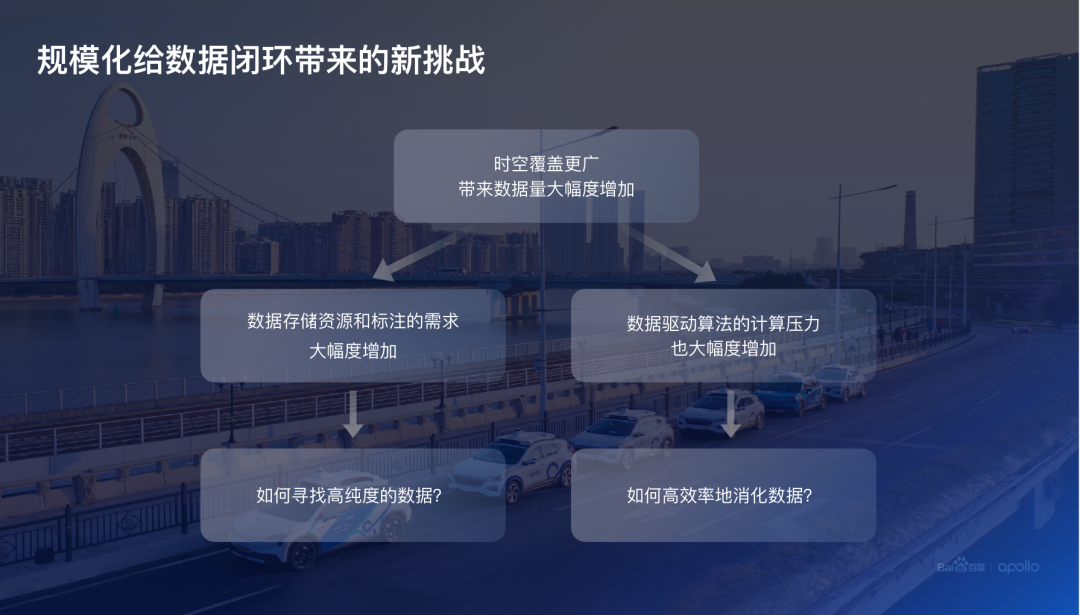
然而,大数据给自动驾驶智能水平带来巨大提升空间的同时,大量的数据也给数据闭环建设带来了全新挑战。
一方面,大规模的数据带来了数据存储以及数据标注的一个巨大压力,全量落盘的模式不再是一个可以持续的方案。
另外一方面,数据闭环的目标是利用数据提升无人驾驶整个的驾驶能力。在大规模数据的情况下,算法迭代所需要的计算量也随之增加。我们将这两个困难总结为两个核心的问题:
首先,如何高效率地从海量的数据里找到高价值或者叫高纯度的数据?
其次,如何利用好这些高纯度的数据,高效、高质量地提升整体数据驱动算法的整体智能水平?
我们从回答这两个问题的角度出发,设计了百度Apollo的数据闭环的整体设计思路。
首先,自动驾驶系统是由车端和云端两个部分组成的。而整个数据闭环是由数据提纯以及数据消化这两个部分构成。
其中数据提纯同时出现在车端和云端,它的目标是找到高价值、高纯度的数据。
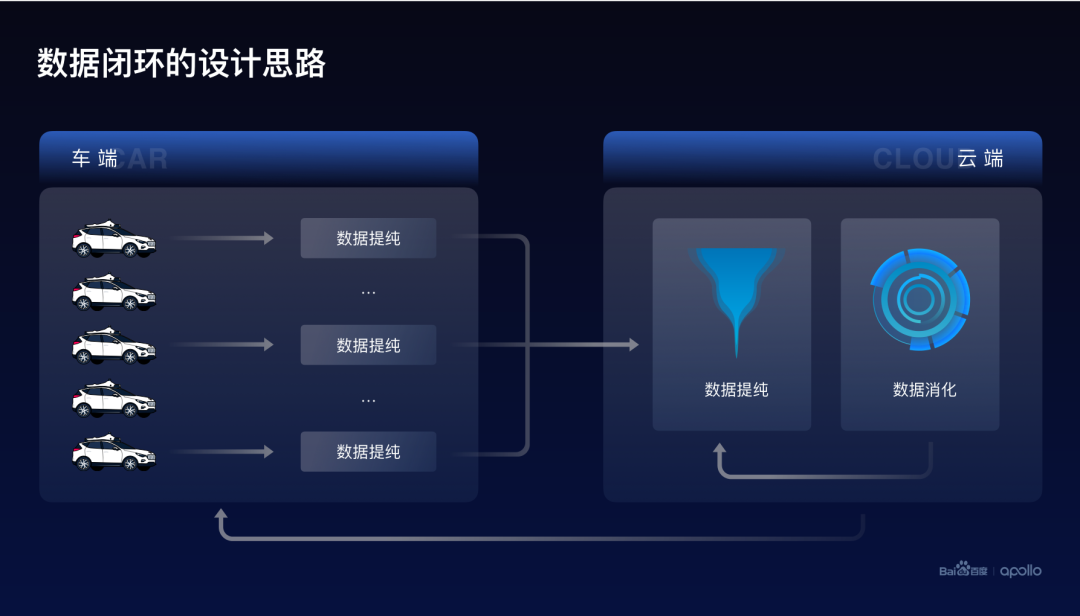
而数据消化部署在云端,它的目标是利用高纯度的数据,提升自动驾驶的整体的智能水平。
接下来,将从这两个方面分别介绍百度关于数据闭环的高提纯、高消化的设计思路。
首先,我们需要建设高效率数据提纯的通路。

大规模的数据对于智能系统的帮助其实已经是业界共识了,然而百度认为数据的规模并不是唯一的标准。数据的纯度也是一个重要的考量。这里定义数据的纯度为,单位数据可以给整个智能系统提供的信息量。一个简单的例子来看一看如何提高数据的纯度。
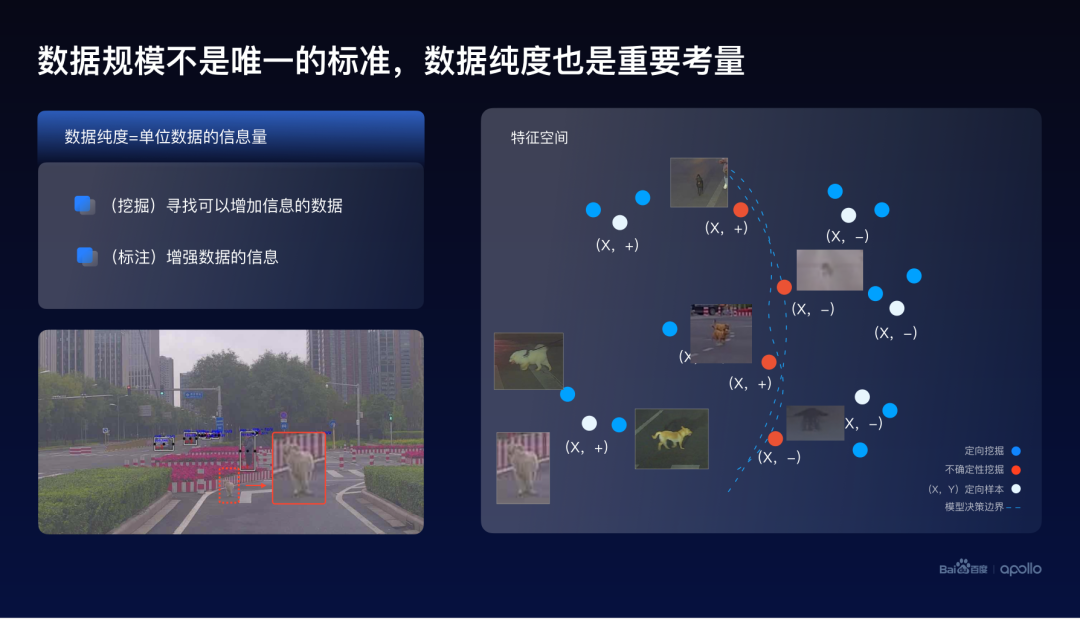
在左下角这个图片中可以发现,正前方有一只小狗,没有被算法检测到。我们称这样的数据为定向样本。而在右边的特征空间的表示中,用白色的圆圈来表示这样的定向样本。这里的正负号是这些样本的标注。
所以一个比较直接的想法就是尝试去找与这只小狗类似的一个照片,而这些图片大概率也会造成系统的漏检。
这些图片的搜索,可以通过比如最近邻检索的一些方式来实现,在这个特征空间上我们用蓝色的圆圈来表示。这种搜索类似样本的一个数据挖掘的方式,把它叫做定向挖掘。
这里可以注意到,其实定向挖掘这个方法,并没有使用到检测模型的一些自身的信息。因而除了相似性,还可以从整个模型的角度来挖掘这个问题。
其实任何的模型都会有自己的决策边界,在这张图上使用虚线来表示。而出现在决策边界上的数据,往往是具有很大不确定性的。
因而,这些数据也会给模型带来额外的信息。所以我们将找到这些数据的方式叫做不确定性挖掘。
可以注意到,在获取这些不确定性数据的同时,其实并没有它们的标签。借助于人工或者自动化标注的一些方式,可以获得这些标签。标签从某种程度上也可以认为是数据的一种,并且可以带来更多关于这些样本的一些信息。当获得这些标签之后,就可以通过模型训练的方式,来改变模型的决策边界。
所以简单地总结一下,数据挖掘与标注都是提高数据纯度的一个重要手段。
根据这样的思路,百度设计了自动驾驶的数据提纯通路。
从这张图上可以看到,数据总是以数据流的形式不断地进入到这个系统里。而数据提纯的一个核心组件是推理引擎,作用是对任意的一个给定的模型和一组数据,给出这个模型在这组数据上的推理结果,这个结果可以包括数据的特征以及模型预测出的标签。

另外一个重要的组件是模型仓库,这里包含了云端大模型、车端小模型,以及一些并没有上车的一些候选小模型。
这里的大模型可以用来通过推理引擎获取对应数据的特征和标签。大模型的特征与向量检索相结合,其实可以用作定向挖掘,大模型的标签可以用作自动化标注。
除了大模型以外,车上的小模型也可以用来做数据提纯。小模型可以通过推理的方式获取小模型的标签,注意,这里小模型的效果其实不如大模型,但由于小模型是实际在车上跑的模型,可以用这些标签来判断哪些数据是目前的小模型无法准确预测的数据。这也就是说这些数据其实是并没有被模型消化的数据。在之后的训练过程当中可以重点关注,提升在这些数据上的一些效果。
除此之外,多个小模型还可以利用比较经典的,一个集成学习的不确定性估计的方法,获得模型对数据的不确定性,从而实现不确定性挖掘。
所以通过推理引擎,实际上对所有数据的各种属性进行了推理,基于这些数据属性,可以进一步地提供复杂的挖掘规则,从而实现更为复杂和更有针对性的挖掘方式。
另外,从这个架构上不难发现,数据提纯的效率很大的程度由推理引擎的效率决定。而推理引擎的效率又可以分为数据的读取速度,以及模型的推理和计算速度。后者其实可以通过一些分布式的方式来提升,而前者主要可以通过文件系统的一些创新来进行优化。
这里我们与百度飞桨团队产生了紧密的合作,将百度自研的PaddleFlow数据缓存的基础架构,集成进入了数据闭环的平台,实现了推理引擎数据读取效率的10倍以上的提升。

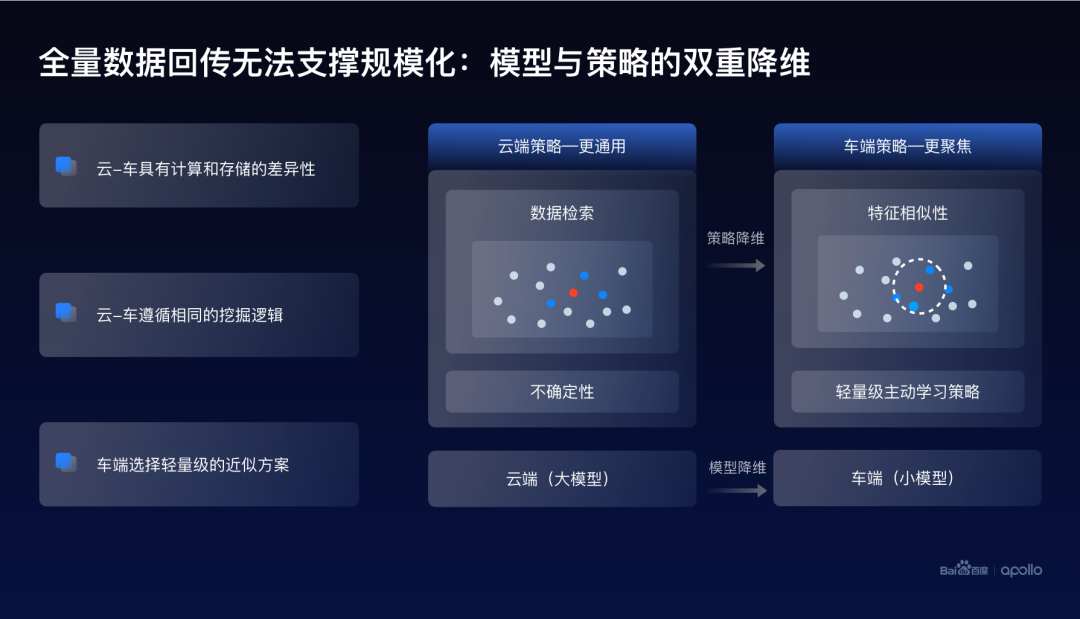
另外一方面,如果只有云端数据提纯这样的一个方式,是没有办法满足大规模自动驾驶的需求的。原因是在于存储空间的上限其实是无法支持全量的数据回传。
因而,在车端也需要部署数据提纯的通路。云端和车端系统的主要区别在于它的存储和计算能力的不同。很多云端可以执行的操作,在车端变得难以实现,比如说集成学习的一些方式。
因而,我们在设计车端挖掘方案的时候,虽然依旧遵循相同的原则和底层逻辑,但更多是采用一些轻量级的策略。比如云端基于大模型的挖掘方式,在车端是没有办法实现的,所以车端会改用小模型的特征提取。
最终简单地总结一下,数据提纯的呈现方式,实际上是云端到车端的一个模型和策略的双重降维。
第二部分:在我们获取了高纯度数据的同时,另一个重要的问题,就是如何高效率、高质量地消化这些数据,将数据转化为无人车的智能与驾驶能力。

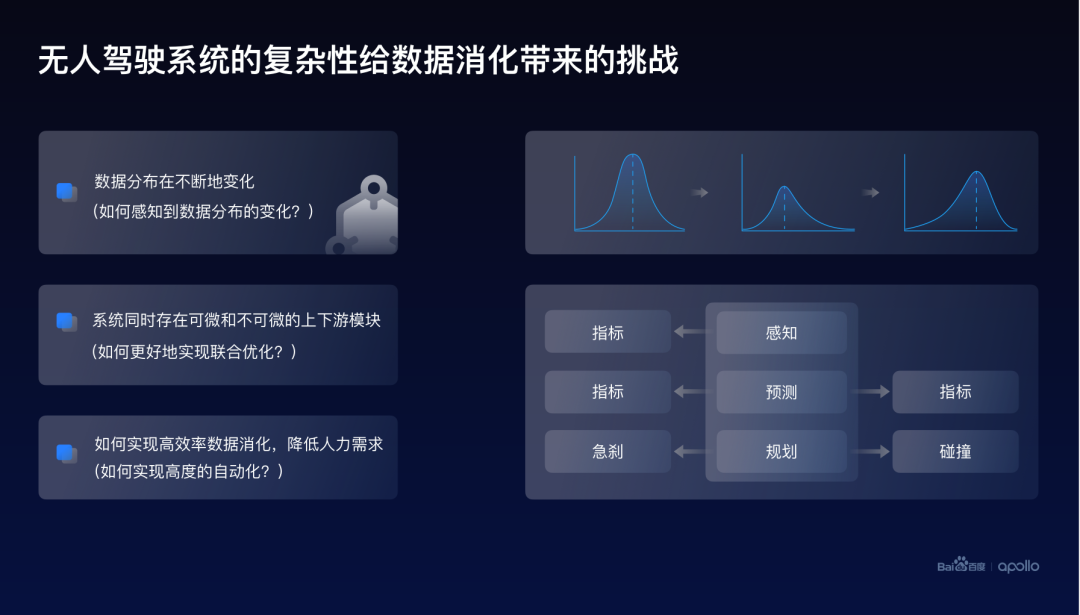
无人驾驶的系统与传统的机器学习的应用其实是有很大的不同的,这样的不同,给整体的数据消化带来了很多挑战。
首先,我们所处的世界其实是不断变化的。因而,无人车搜集到数据的分布也是在不断变化的。
所以如何让无人驾驶这个系统可以感知到数据分布的一个变化,是需要考虑的一个重要问题。
其次,无人驾驶的系统并不是单一的模型,是由多个可微和不可微的模块共同组成的。并且这些模块是相互关联、相互影响的。所以需要考虑如何更好地去联合优化这些模块。
最后,数据消化还存在一个效率的问题,而高效的系统往往是需要实现高度的自动化,从而降低流程中对于人工的需求,最终达到降低系统成本的一个核心目标。
接下来,我会从这三个角度分别去介绍百度对于数据消化的一个实践与思考。它们分别是自动化、联合优化以及数据分布。

首先,基于持续学习与AutoML的一些概念,百度在数据闭环里面设计了一套自动化训练引擎。
数据通过数据缓存的形式、采样的方式进入到训练引擎,这类似于持续学习里面一些比较经典的经验回放机制。
由于自动驾驶系统的优化是多目标的,整个训练引擎需要持续的维护一个模型集合,不仅仅包含最优的模型,还包含在整个训练过程当中产生的中间模型。
我们使用一个异步的推理引擎对这些模型进行评测,因而最终的训练的输出是一个候选模型的集合,而不是一个单一的模型。这个集合在多目标优化里面一般叫做Pareto front。
此外,在概念上,百度认为一个模型它是由参数和超参数共同定义的,这里的参数定义了模型的静态状态,而超参数其实定义了整个模型优化的轨迹或者叫动力学。这两种参数是结合起来一起进行管理的。
通常模型参数是通过梯度优化的方式来优化的,而超参数则需要使用非梯度优化。这里借鉴了基于进化算法的一个架构思路。
首先从模型集合里采样模型参数和超参数。然后对它们做一些探索。这里有与传统的超参数优化有所不同的地方,在于不仅仅对超参数进行探索,同时对整个模型的参数也进行扰动。这也是受到今年Rich sutton等人提出的持续学习的可塑性的影响,以及2019年Jordan ash等人提出的模型热启动工作的启发。百度在实践中发现,这种参数的扰动是可以提高在持续训练的过程当中,整个模型群体的鲁棒性和稳定性。
探索后的模型参数可以作为初始化,与超参数共同传入Paddlecloud分布式训练,而训练的过程中产生的模型将会一起传回整个模型集合进行管理。
需要注意的是,这里的训练步长不一定是要等模型收敛,也可以设置比较短的一些步长,这样的话可以直接实现动态参数优化的一个能力。
利用这样的一个训练引擎,对自动驾驶系统里面的数据驱动模型实行了自动化托管的能力,也就是说在数据确定的情况下,可以实现全无人的训练模式。

继续以刚才的小狗为例,当发现这只小狗出现误检之后,可以利用特征检索的一些方式,挖掘出一批小狗的数据,然后将新数据与旧数据同时传入到训练引擎进行自动化训练。这里可以看到每一个点其实是一个模型,可以看到在整个训练的过程当中,模型的效果是不断提升的,同时在训练的最终结果发现,可以实现小目标和总体指标的同时提升。

此外,这个训练引擎是一个通用的架构,因此它不仅仅是可以用在这样的一个问题上,其他的各种各样的一些问题也可以利用这样的方式提升模型的效果。举个例子比如:低矮绿植问题、栅栏问题以及悬浮塑料袋的问题。


点击查看大图
不难想象,在持续优化这样的一个系统的时候,所有的这些挖掘的数据最终是以一个个的数据集的形态传输到训练引擎当中的。
而在迭代的过程当中发现,其实每一次新数据进来的时候,整个模型的效果是呈持续提升的一个趋势。并且尚没有观测到数据饱和的一个状态。
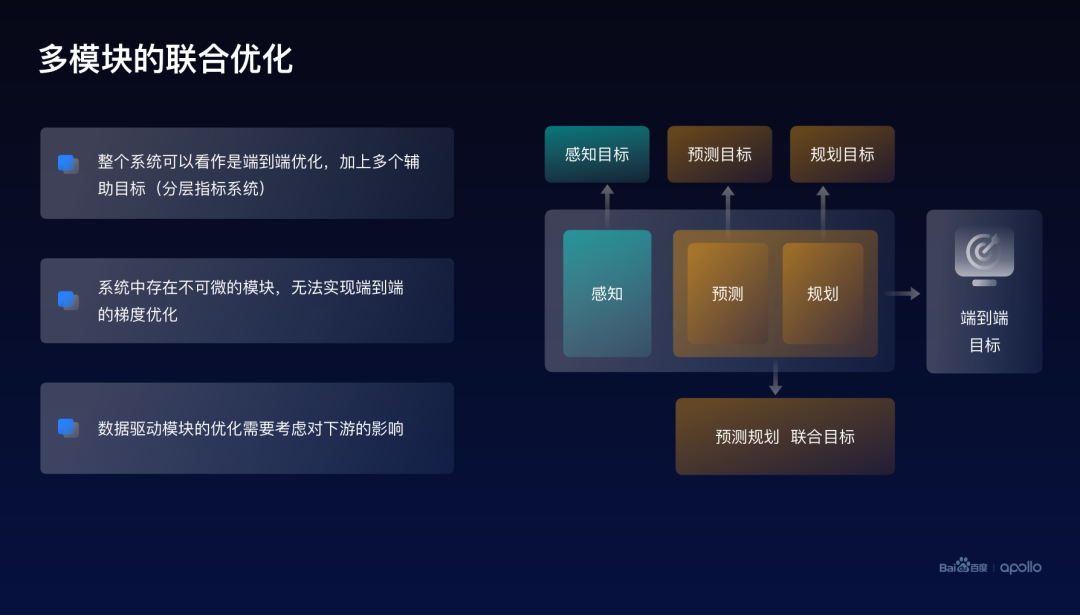
大家可以注意到,其实刚才提到的例子都是对单一模型的一个优化。而整体自动驾驶是一个多模块的复杂系统,因而更需要去关注联合优化的问题。

本质上来看,整个自动驾驶系统可以看作是一个端到端的优化,因为我们最终在乎的,是这个无人车在车上的一个效果,而优化的方式是通过加上很多模块级别的辅助目标。比如感知会有自己的目标,预测、规划都会有自己独立的目标。而之所以没有办法真正地实现端到端的优化这个能力,是由于在整个系统里面存在很多不可微的模块,因而没有办法计算它们的梯度。
此外,对于系统里面某一些数据驱动模块的优化,从端到端的角度,也是需要考虑它对下游的一个影响,可以认为目前整个的工程架构所做的方式,应该是类似于系统级的Coordinate descent,又叫做坐标下降方法。
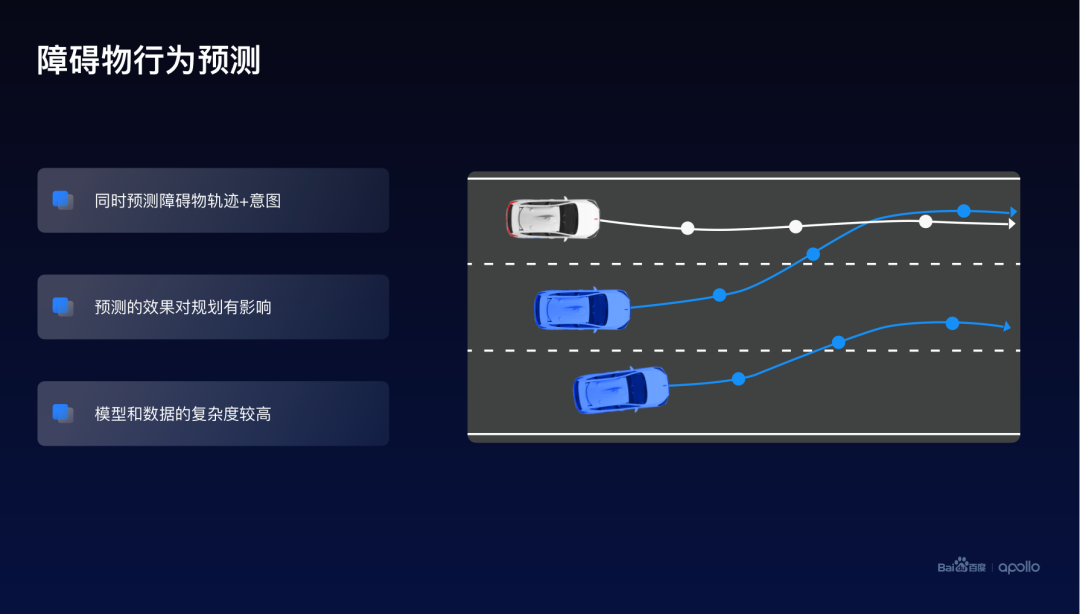
一个比较经典的联合优化的例子就是行为预测,在这张图上可以发现,行为预测这个模块它是处于中间的,它有上游,也有下游。这里的行为预测模型同时考虑了障碍物轨迹以及面对障碍物的意图,它的效果会直接影响下游的轨迹规划这个模块。
而预测的模型,预测的数据以及它的问题的复杂度都相对比较高。
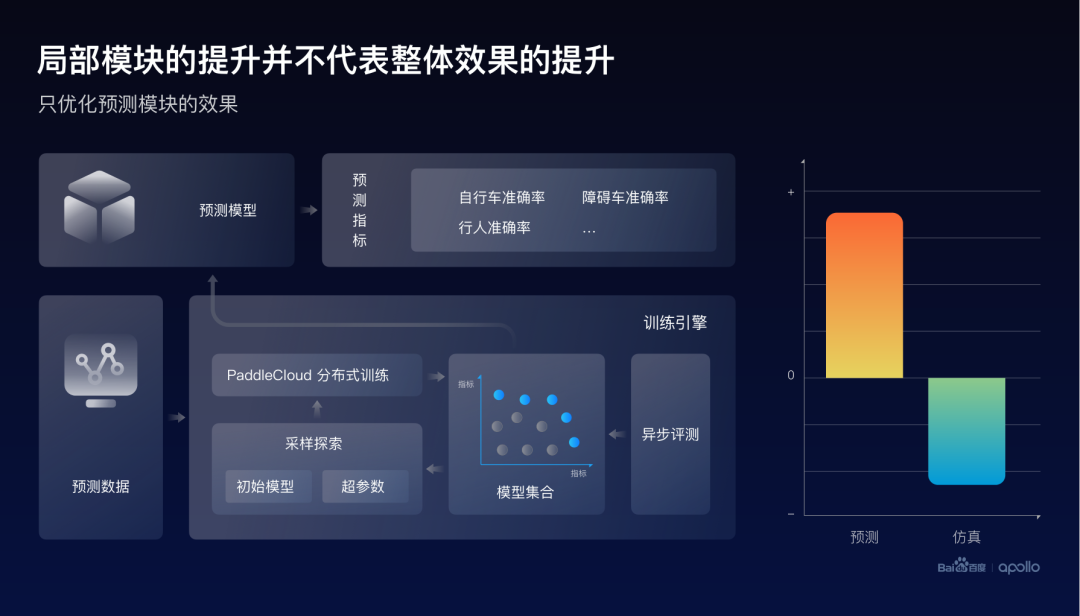
首先我们做了一个初步的尝试,尝试了与之前感知比较类似的一个方法,搜集一些数据,利用自动化优化的引擎来优化预测的评测指标。这里的指标是由不同的障碍物的类型构成,比如自行车、障碍车或者是行人。
从右边的结果可以发现,的确发现了这个预测的整体指标取得了提升,但是当把最好的预测模型放进这个端到端系统时,发现仿真的指标却下降了。实际上,我们认为这是由于预测指标与仿真指标的目标不一致所造成的。
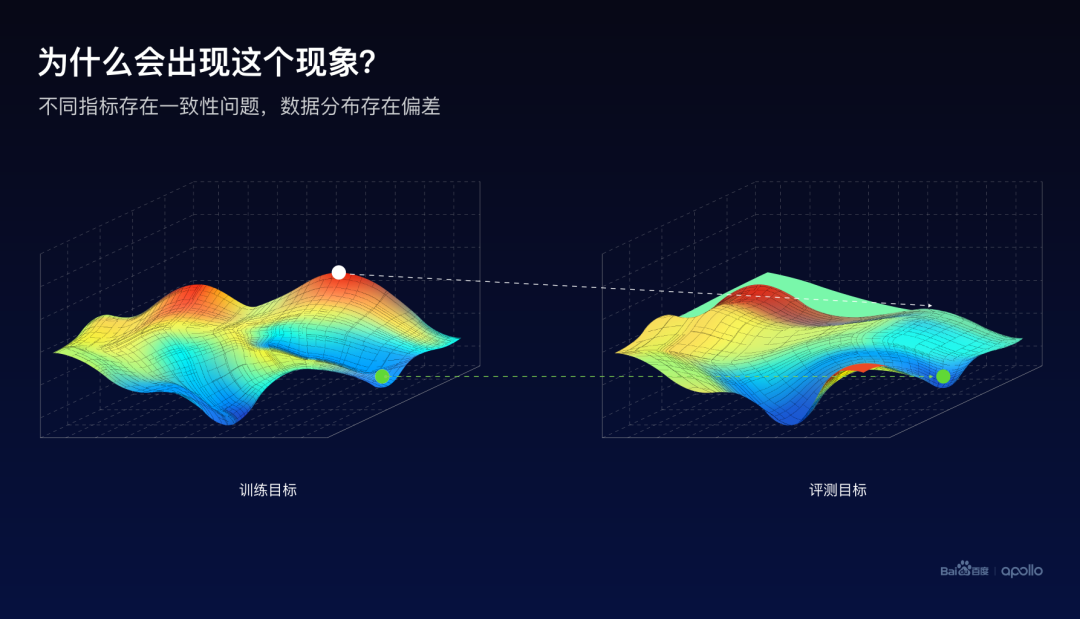
这里使用地形图来示意训练和评测的优化目标。假设越高的点越好,越红的点越好,指标越好。如果只看训练的指标,使用梯度优化的方式,的确是可以找到红色的比较高的区域。然后它的对应位置的评测目标,却并非是处于一个比较高的状态。
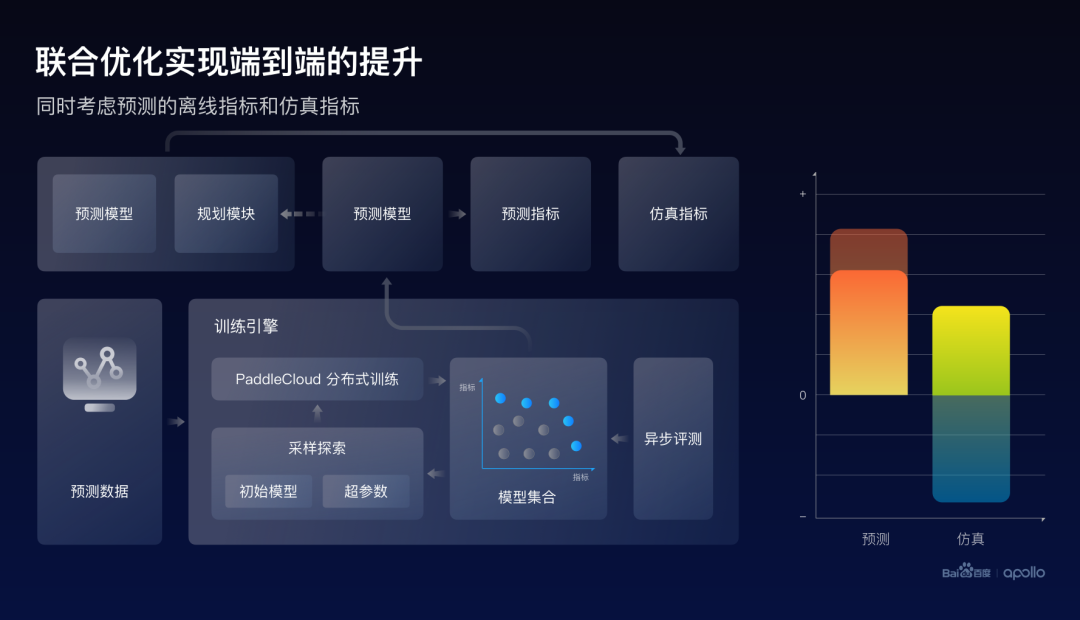
因而一个比较直观的想法就是,在优化这个模型的时候,同时去看两个地形图的高度,这样就有更大的概率,去找到两个指标都好的一个最终状态。
基于这样的一个想法,百度实现了一个工程架构。在训练的同时,将产生的预测模型实时地与下游规划模块进行打包,同步地进行仿真评测。因而,最终的训练引擎同时优化的是离线的预测指标以及仿真的端到端指标。
通过结果可以发现,虽然预测的指标有小幅度的下降,但是其实最终这个仿真的效果是有大幅度提升的。
刚才已经提到了一些关于数据分布对于训练的影响的一些问题。可以认为整个数据消化的能力是与数据分布的理解能力息息相关的,因而着重也需要去考虑这个系统如何去理解数据分布。
数据分布其实在机器学习里面是一个非常重要的概念。这个原因是在于目前比较有效的数据驱动的方式主要是基于深度学习。而深度学习的核心原则是经验风险最小化。
这里我列举出了训练和评测的经验风险最小化的公式。而重点关注的是这个w和v数值,它们分别是训练时的每个样本的权重,或者叫分布或者是密度,和评测时候的每个样本的权重。
所以从这个公式可以发现,如果w和v不一样,那通过这个训练公式获得的模型,在评测的时候大概率也不是最好的。而评测的效果往往是需要真正关心的。因而,这里一个核心的问题就是如何找到正确的数据分布。
为此,百度在数据闭环里设计了一套对于数据分布的管理和探索的方案。


点击查看大图
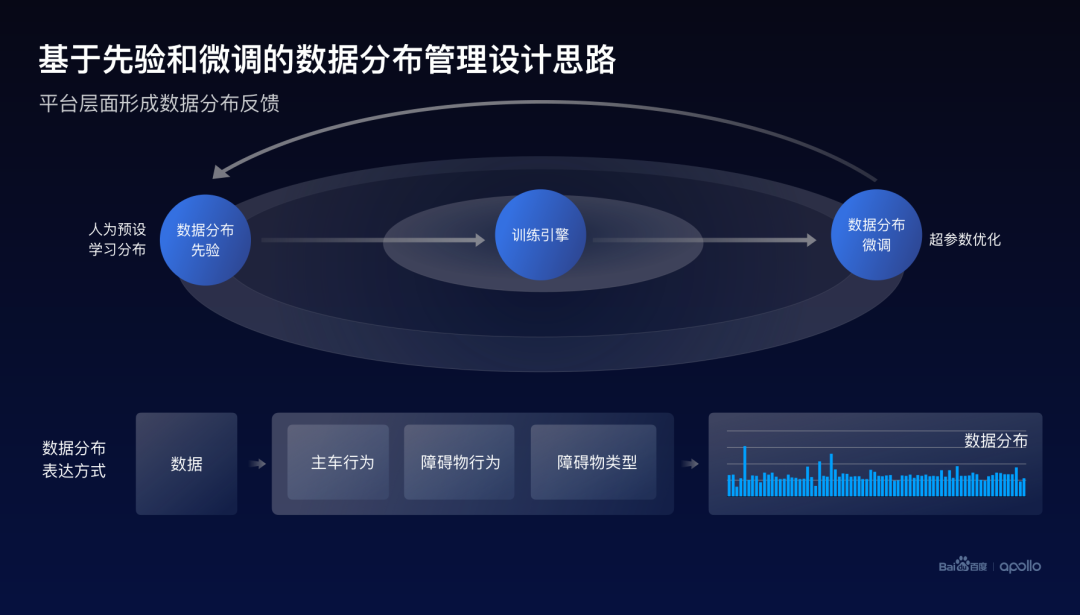
这里主要分为两个部分,首先,对数据分布的先验进行统一的管理,这里的先验可以是人为设定的,也可以是通过学习来获得。
当这个先验进入到训练引擎之后,训练引擎其实可以把这个先验或者这个数据分布当作超参数,做一定程度的探索或搜索。当我们发现更好的分布之后,可以通过一个反馈的机制修正数据分布的先验。
而另外一个问题就是,数据分布到底应该如何去描述它,百度主要采用标签化或者叫场景化的一个方式。
以刚才行为预测为例,其实可以通过问三个问题来映射所有的数据到不同的场景,而这三个问题,可以分别是主车的行为、障碍物的行为,以及障碍物的类型。
当对每个场景的数据进行统计,就可以最终获得整个数据集所对应的数据分布的描述。
这里介绍一个比较有意思的学习数据分布的一个尝试。主要的想法是由于整个数据闭环的平台其实管理了所有的模型训练,因而在百度平台的Log里面存在大量的模型和对应的指标。
例如在刚才的行为预测训练里面,我们发现Log里面其实有很多模型、预测指标、仿真指标的配对数据。
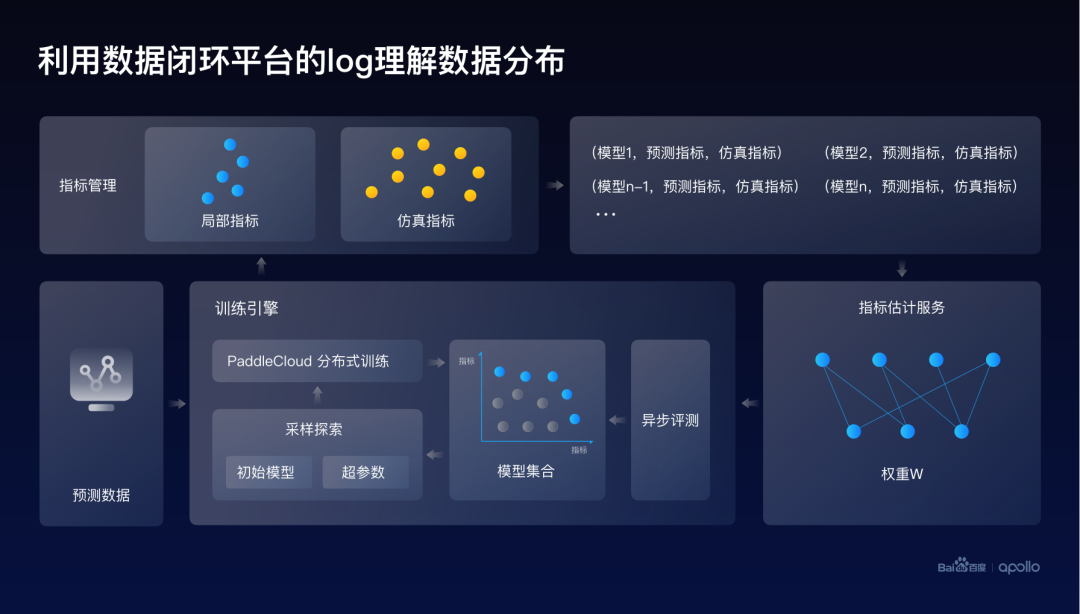
所以一个自然而然的想法就是,是不是可以训练一个线性的预测器,它的输入是不同场景的预测指标,而输出是仿真的指标。这个线性预测器的权重,最终就对应了指标之间的相关性,其实也代表了不同场景下障碍物的预测能力,对于仿真效果的一个重要度的体现。
以环岛的数据举例,从这批预测数据中学习到了关于仿真急刹的数据分布。这里权重最高的场景是主车绕行环岛,障碍物进入环岛,障碍物为车辆时的意图预测能力。
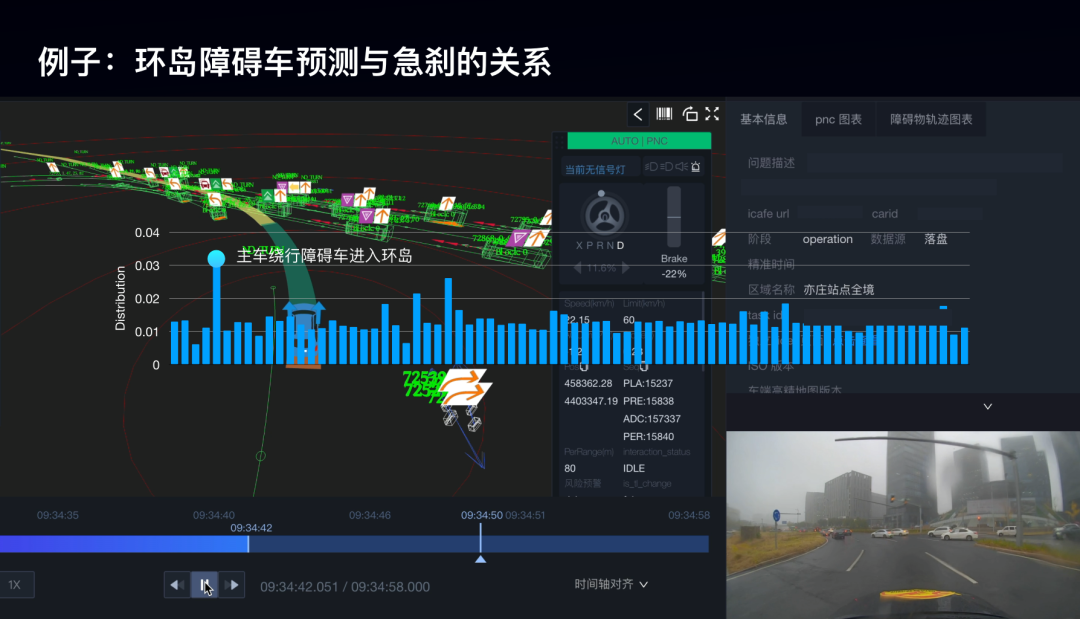
从这个对应场景视频我们不难看出,当在这个时候,障碍车预测不准确的时候,主车很有可能出现急刹的情况。
虽然这样的分布,并非是完全真实的分布,但平台具备这样贡献度的估计能力,其实可以给研发带来一定程度的帮助。
从另外一个角度,我们可以适度地根据这样的一个数据分布,提供一个指导,来调整数据分布的一个先验或者是指标评测时候的数据分布,从而达到加强训练指标和评测指标的一致性的方式。
例如在刚才的预测的例子里,这样的一个方式可以大幅度降低在训练流程中对于仿真评测的需求,从而达到降低成本。
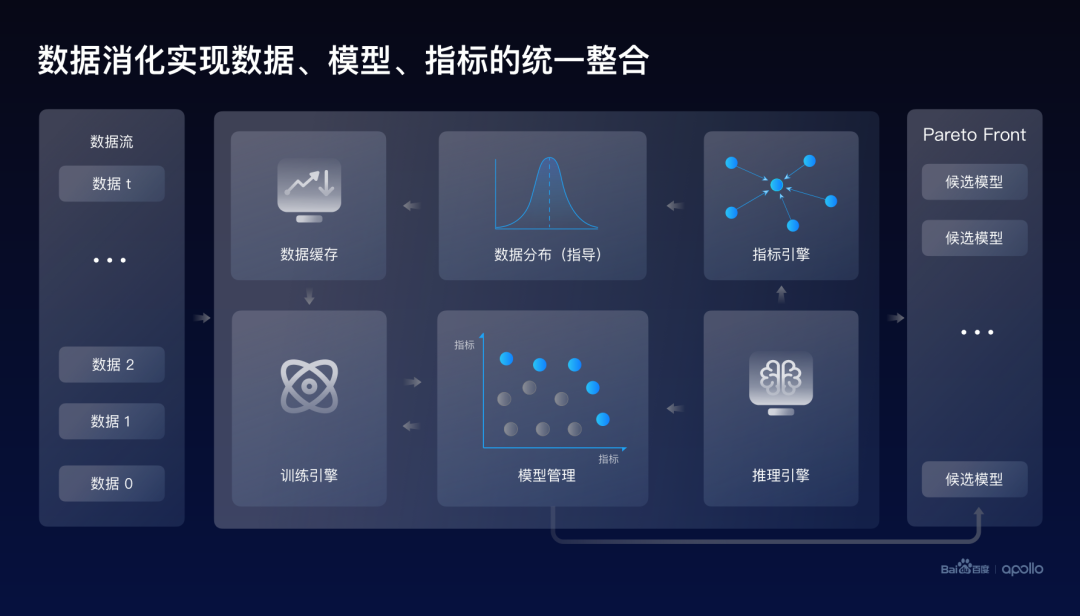
最终总结一下:百度提出了以高提纯、高消化为核心驱动力的数据闭环的设计思路。这里的高提纯通过小模型和大模型的车云协同,实现高效的数据挖掘和自动化标注。
而高消化则通过数据、模型、指标的集中式、端到端整合来实现。
除此之外,训练、推理以及数据分布是在数据消化中可以形成有效的一个反馈机制,进一步提升数据消化的整体效率和效果。
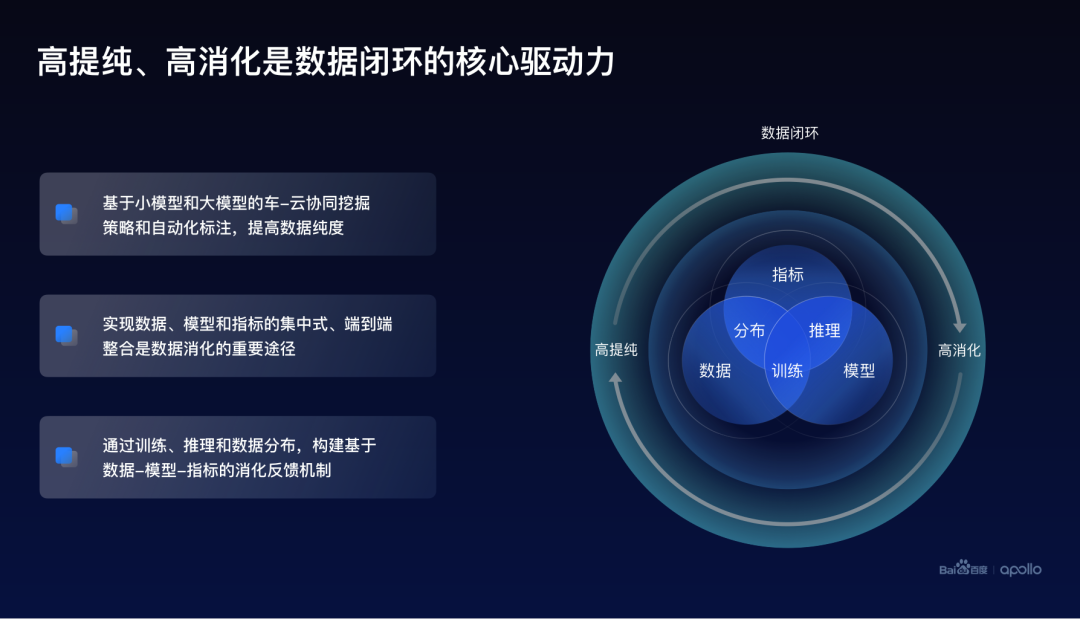
最后,希望百度Apollo的高提纯、高消化的数据闭环技术思想,可以给业界同行们带来更多的启发,共同推动和实现自动驾驶大规模的商业化落地。
好,谢谢大家!
审核编辑 :李倩
-
自动驾驶
+关注
关注
794文章
14976浏览量
181355 -
无人车
+关注
关注
1文章
319浏览量
37773 -
Apollo
+关注
关注
5文章
351浏览量
19762
原文标题:百度Apollo Day|李昂:数据规模不是唯一标准,数据纯度更是重要考量
文章出处:【微信号:baiduidg,微信公众号:Apollo智能驾驶】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
金属越纯,性能越好?一文了解纯度与电化学的关系

MySQL数据库备份恢复方式对比
标准铂电阻温度计与高精度测温仪的重要作用
技术解析:58同城房产数据平台 - 根据项目ID获取详情数据的API接口实践

募投绘蓝图-昂瑞微的成长密码与未来布局
如何制定电能质量在线监测装置的数据校验标准?

工业数据管理平台的重要性体现在哪
厚声电阻的环保材料是否符合RoHS标准?
伟创力高效电源模块在超大规模数据中心的应用
通过标准化数据通路来实现数据共享
LED灯珠金线纯度识别
AIoT设备数据规模增速位居前列,物联网成为数据资源增长的主力?




评论