 存内计算对“存”的选择
存内计算对“存”的选择
电子发烧友网报道(文/周凯扬)无论是前段时间爆火的绘图模型Stable Diffusion,还是大规模语言模型ChatGPT,AI无疑已经成了新时代的自动化工具,哪怕是在某些与认知相关的任务上,也能通过深度学习实现高于人类的精度。
但正因我们提过多次的算力问题,对于大型AI训练的计算要求已经在每两个月翻倍了,别说可持续能源供应了,就连硬件的可持续都有些陷入停滞了。其实以目前各种模型的迭代速度来看,更高的运算效率才是重中之重,毕竟这些模型并不需要每两个月就推陈出新。
深度学习还有哪些环节可以提升效率
我们先从深度学习运算来看哪些算数运算占比最高,根据IBM给出的统计数据,无论是语音识别的RNN、语言模型DNN和视觉模型CNN,矩阵向量乘法都占据了运算总数的70%到90%,所以打造一个矩阵矢量乘法加速器,是多数AI加速器的思路。
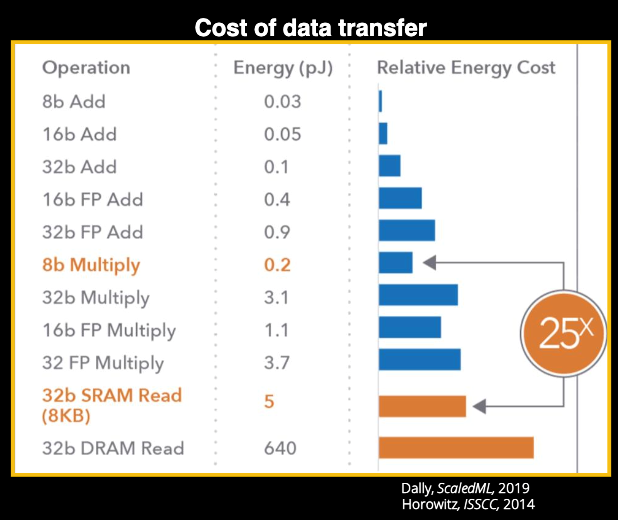
数据传输和运算的功耗对比 / ISSCC
要考虑效率,我们就不能不谈到功耗的问题,如果只顾算力而不考虑功耗,任由庞大规模的GPU等硬件消耗能量不顾碳排放的话,也不符合全球当下的节能减排趋势。而在深度学习中,各种精度的加法乘法都会消耗能量,但这些运算消耗的能量与传统冯诺依曼结构中数据移动消耗的能量相比,就显得微不足道了,尤其是从DRAM中读写高精度数值时,能耗差距甚至可以达到数十倍以上。
这还只是在数据中心场景中,如果我们放到边缘来看,如今的移动设备需要语音识别、图像识别之类的各种深度学习应用。所以提升这类设备的效率,才有可能在功耗和内存都有所限制的嵌入式应用中普及深度学习。
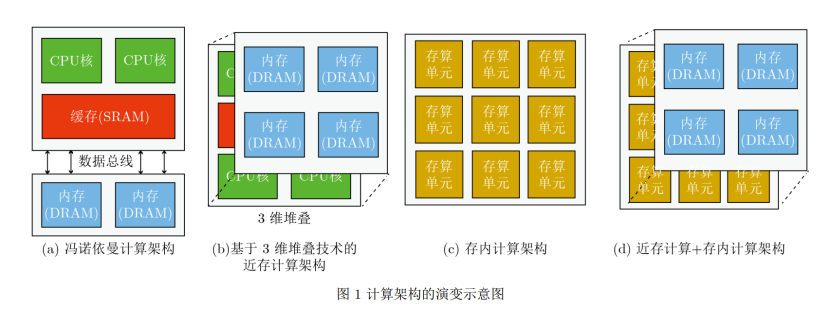
存内计算的存储选择
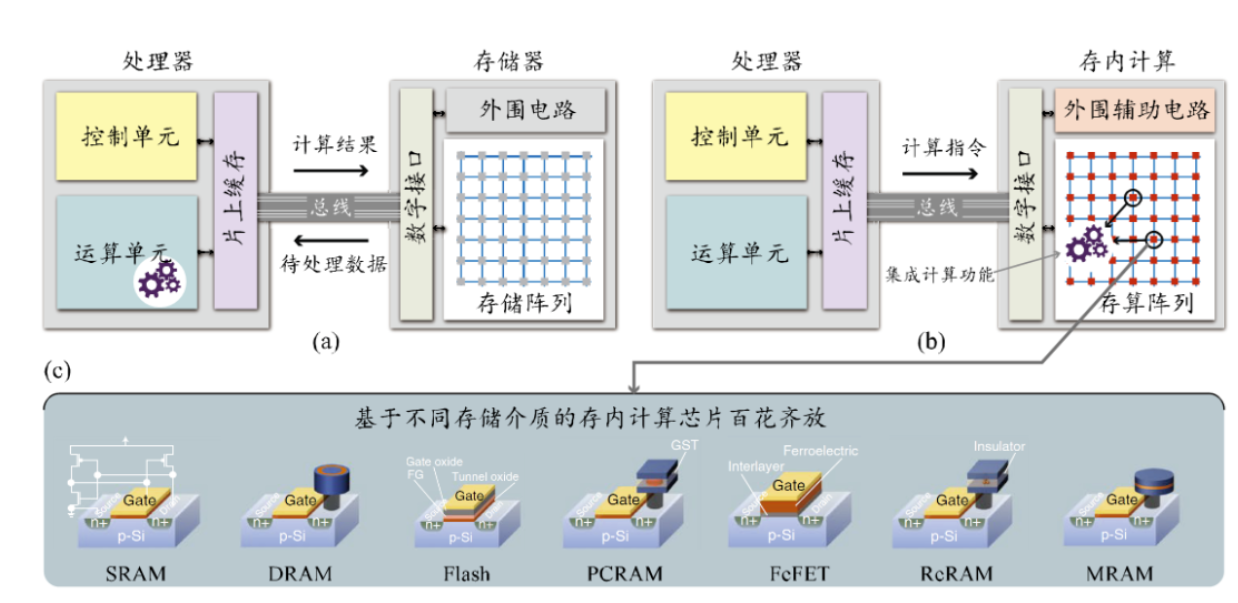
为了减少数据移动消耗的能量,提高MVM的计算性能,存内计算成了一个不错的选择。存内计算(IMC)是一项创新的计算方式,将特定的计算任务放到存储设备中,并使用模拟或混合信号的计算技术。相较冯诺依曼结构或近存计算来说,最大程度地减少了数据移动。
而早期利用IMC进行神经网络推理的测试结果证明,在软硬件结合的情况下,可以得到优秀的精度结果,而DAC、ADC、功能激活之类的数字操作则是通过片外的软件或硬件来实现的。自那之后,各种使用SRAM、NOR Flash、RRAM、PCM和MRAM的单核或多核存内计算芯片纷纷面世。
在对于正确存储类型的选择上,存内计算必须面临取舍的问题,比如性能、密度、写入时间、写入功耗、稳定性以及制造工艺上。性能自然就是直接影响到我们说的TOPS算力以及效率,目前SRAM优势较大,密度则决定了裸片大小,同时也影响到了成本。
而在边缘场景下,环境一致性往往不比数据中心,所以如果不能保证稳定性的话,就会影响到存内计算进行深度学习的精度。最后的制造工艺不仅决定了这类存内计算芯片能否量产,是否存在供应链危机或成本问题,也决定了它有没有继续推进的空间,比如目前工艺较为先进的主要是PCM和SRAM,最高分别已经到了14nm和12nm。
在2021年的VLSI技术大会上,IBM发表了一篇文章,讲述了他们以14nm CMOS工艺打造的一个64核PCM模拟存内计算芯片,HERMES。该芯片采用了后端集成的多层相变化内存,由256个线性化的CCO ADC组成,可以在1GHz的工作频率之上进行精确的片上矩阵矢量乘法运算。在深度学习的运算测试中,HERMES获得了10.5 TOPS/W的运算效率以及1.59TOPS/mm2的性能密度。
而荷兰初创企业Axelera AI则选了数字SRAM这一路线,他们在去年12月成功流片第一代IMC芯片Thetis Core。Thetis Core的面积不到9mm2,却可以在INT8精度下提供39.3TOPS的算力和14.1 TOPS/W的性能,甚至还可以超频到48.16TOPS。但不少存内计算芯片提到性能表现时,往往都是指满载的情况,正因如此,Thetis Core在低利用率下的效率表现才显得无比亮眼。哪怕从100%利用率降低至25%的,该芯片也能展现13TOPS/W的效率,降幅只有7%左右。
小结
除了“存”以外,存内计算在“算”上的选择也不尽相同,比如进行模拟或数字MAC运算等等。从斯坦福大学教授Boris Murmann提出的观点来看,在低精度下模拟运算要比数字运算更高效,但一旦精度拔高,比如8位以后,模拟计算的功耗就会成倍增加了。考虑到落地应用较少,未来的存内计算会更倾向于哪种形式仍有待观察,但从存储厂商、存算一体芯片厂商的动向来看,这或许是存储市场迎来又一轮爆发的绝佳机遇。
但正因我们提过多次的算力问题,对于大型AI训练的计算要求已经在每两个月翻倍了,别说可持续能源供应了,就连硬件的可持续都有些陷入停滞了。其实以目前各种模型的迭代速度来看,更高的运算效率才是重中之重,毕竟这些模型并不需要每两个月就推陈出新。
深度学习还有哪些环节可以提升效率
我们先从深度学习运算来看哪些算数运算占比最高,根据IBM给出的统计数据,无论是语音识别的RNN、语言模型DNN和视觉模型CNN,矩阵向量乘法都占据了运算总数的70%到90%,所以打造一个矩阵矢量乘法加速器,是多数AI加速器的思路。
数据传输和运算的功耗对比 / ISSCC
要考虑效率,我们就不能不谈到功耗的问题,如果只顾算力而不考虑功耗,任由庞大规模的GPU等硬件消耗能量不顾碳排放的话,也不符合全球当下的节能减排趋势。而在深度学习中,各种精度的加法乘法都会消耗能量,但这些运算消耗的能量与传统冯诺依曼结构中数据移动消耗的能量相比,就显得微不足道了,尤其是从DRAM中读写高精度数值时,能耗差距甚至可以达到数十倍以上。
这还只是在数据中心场景中,如果我们放到边缘来看,如今的移动设备需要语音识别、图像识别之类的各种深度学习应用。所以提升这类设备的效率,才有可能在功耗和内存都有所限制的嵌入式应用中普及深度学习。
存内计算的存储选择
为了减少数据移动消耗的能量,提高MVM的计算性能,存内计算成了一个不错的选择。存内计算(IMC)是一项创新的计算方式,将特定的计算任务放到存储设备中,并使用模拟或混合信号的计算技术。相较冯诺依曼结构或近存计算来说,最大程度地减少了数据移动。
而早期利用IMC进行神经网络推理的测试结果证明,在软硬件结合的情况下,可以得到优秀的精度结果,而DAC、ADC、功能激活之类的数字操作则是通过片外的软件或硬件来实现的。自那之后,各种使用SRAM、NOR Flash、RRAM、PCM和MRAM的单核或多核存内计算芯片纷纷面世。
在对于正确存储类型的选择上,存内计算必须面临取舍的问题,比如性能、密度、写入时间、写入功耗、稳定性以及制造工艺上。性能自然就是直接影响到我们说的TOPS算力以及效率,目前SRAM优势较大,密度则决定了裸片大小,同时也影响到了成本。
而在边缘场景下,环境一致性往往不比数据中心,所以如果不能保证稳定性的话,就会影响到存内计算进行深度学习的精度。最后的制造工艺不仅决定了这类存内计算芯片能否量产,是否存在供应链危机或成本问题,也决定了它有没有继续推进的空间,比如目前工艺较为先进的主要是PCM和SRAM,最高分别已经到了14nm和12nm。
在2021年的VLSI技术大会上,IBM发表了一篇文章,讲述了他们以14nm CMOS工艺打造的一个64核PCM模拟存内计算芯片,HERMES。该芯片采用了后端集成的多层相变化内存,由256个线性化的CCO ADC组成,可以在1GHz的工作频率之上进行精确的片上矩阵矢量乘法运算。在深度学习的运算测试中,HERMES获得了10.5 TOPS/W的运算效率以及1.59TOPS/mm2的性能密度。

而荷兰初创企业Axelera AI则选了数字SRAM这一路线,他们在去年12月成功流片第一代IMC芯片Thetis Core。Thetis Core的面积不到9mm2,却可以在INT8精度下提供39.3TOPS的算力和14.1 TOPS/W的性能,甚至还可以超频到48.16TOPS。但不少存内计算芯片提到性能表现时,往往都是指满载的情况,正因如此,Thetis Core在低利用率下的效率表现才显得无比亮眼。哪怕从100%利用率降低至25%的,该芯片也能展现13TOPS/W的效率,降幅只有7%左右。
小结
除了“存”以外,存内计算在“算”上的选择也不尽相同,比如进行模拟或数字MAC运算等等。从斯坦福大学教授Boris Murmann提出的观点来看,在低精度下模拟运算要比数字运算更高效,但一旦精度拔高,比如8位以后,模拟计算的功耗就会成倍增加了。考虑到落地应用较少,未来的存内计算会更倾向于哪种形式仍有待观察,但从存储厂商、存算一体芯片厂商的动向来看,这或许是存储市场迎来又一轮爆发的绝佳机遇。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
存内计算
+关注
关注
0文章
30浏览量
1382
发布评论请先 登录
相关推荐
知存科技启动首届存内计算创新大赛
存内计算作为一项打破“内存墙”“功耗墙”的颠覆性技术,消除了存与算的界限,相比CPU或GPU能够实现更高计算并行度、更大专用算力,达成数量级
d锁存器解决了sr锁存器的什么问题
D锁存器(Data Latch)和SR锁存器(Set-Reset Latch)是数字电路中常见的两种存储元件。它们在数字系统中扮演着重要的角色,用于存储和传递信息。然而,这两种锁存器在设计和应用上
知存科技推动新一代存内计算芯片产品产业化进程
6月3日,知存科技总部启航仪式在杭州临平算力小镇正式举行,标志着公司在存内计算芯片领域开启技术研发、人才战略、产业升级的新征程。临平区委书记陈如根,区委常委、组织部长杨霞,区委常委
存内计算——助力实现28nm等效7nm功效
当的性能。存算一体尝试通过集成存储和计算在一个芯片甚至一个容器内,来突破访存限制,发挥芯片的最大算力。下面我们将重点介绍存算一体技术。

论基于电压域的SRAM存内计算技术的崭新前景
这篇文章总结了冯·诺伊曼架构及其在处理数据密集型应用中所面临的性能和能耗问题。为了应对这一挑战,文章介绍了存内计算技术,其中重点讨论了基于电压域的SRAM存
浅谈存内计算生态环境搭建以及软件开发
应用架构,提高开发效率。
此外,在搭建存内计算环境时,关键的硬件和软件是不可或缺的。硬件方面,需要足够的RAM来存储数据集和支持计算过程。软件方面,则涉及
发表于 05-16 16:40
知存科技助力AI应用落地:WTMDK2101-ZT1评估板实地评测与性能揭秘
算一体领域,全球参与者可分为国际巨头和新兴企业两大阵营。国际巨头如英特尔、IBM、特斯拉等早已布局存算技术,并推出代表未来趋势的产品。而新兴企业则更灵活选择存内
发表于 05-16 16:38
存内计算WTM2101编译工具链 资料
存内计算是突破物理极限的下一代算力技术- AIGC等人工智能新兴产业的快速发展离不开算力,算力的基础是人工智能芯片。
当前CPU/GPU在执行计算密集型任务时需要将海量参数(ωij)
发表于 05-16 16:33
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究
本文深入探讨了基于SRAM和MRAM的存算一体技术在计算领域的应用和发展。首先,介绍了基于SRAM的存内逻辑计算技术,包括其原理、优势以及在

存内计算芯片研究进展及应用
在NOR Flash存内计算芯片当中,向量-矩阵乘法运算基于电流/电压的跨导与基尔霍夫定律进行物理实现,如图7(a)所示。因此,其核心是设计NOR Flash单元阵列以满足大规模高能效向量-矩阵乘法
浅谈存内计算生态环境搭建以及软件开发
在当今数据驱动的商业世界中,能够快速处理和分析大量数据的能力变得越来越重要。而存内计算开发环境在此领域发挥其关键作用。存内





 工商网监
工商网监
评论