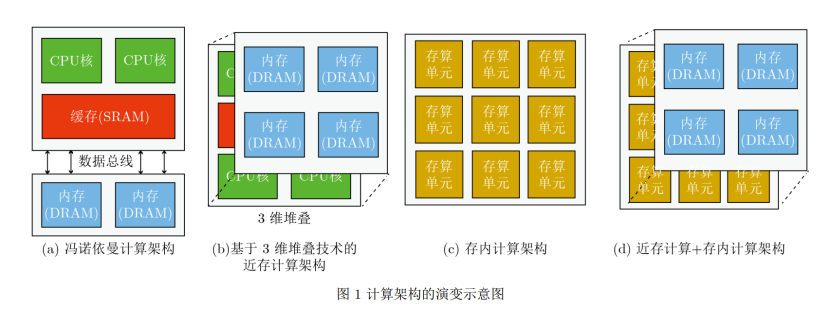
 存内计算对“存”的选择
存内计算对“存”的选择
深度学习还有哪些环节可以提升效率
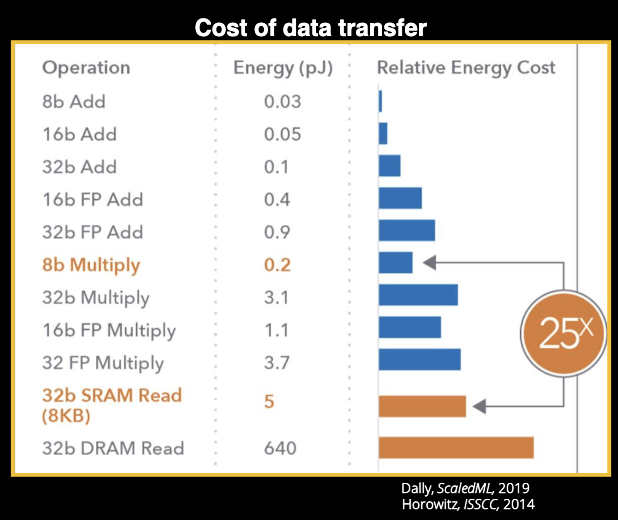
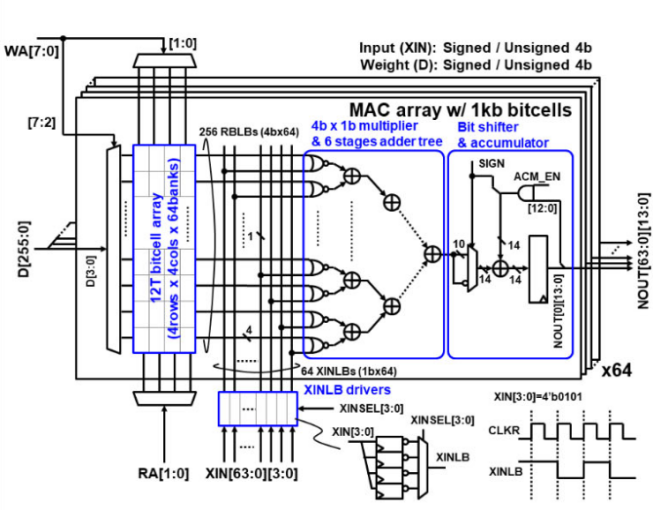
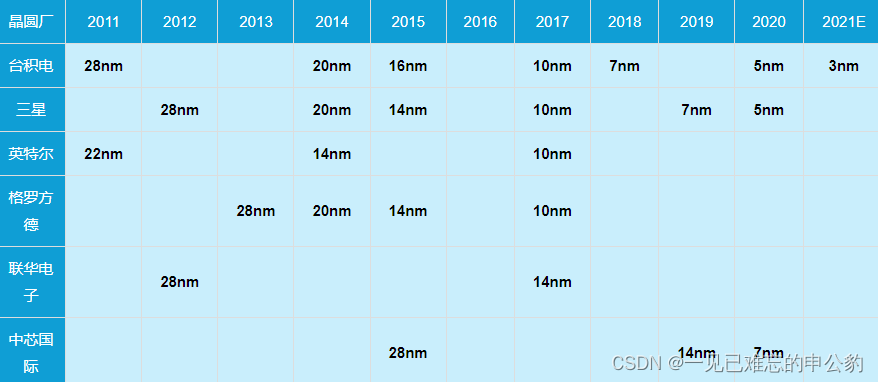
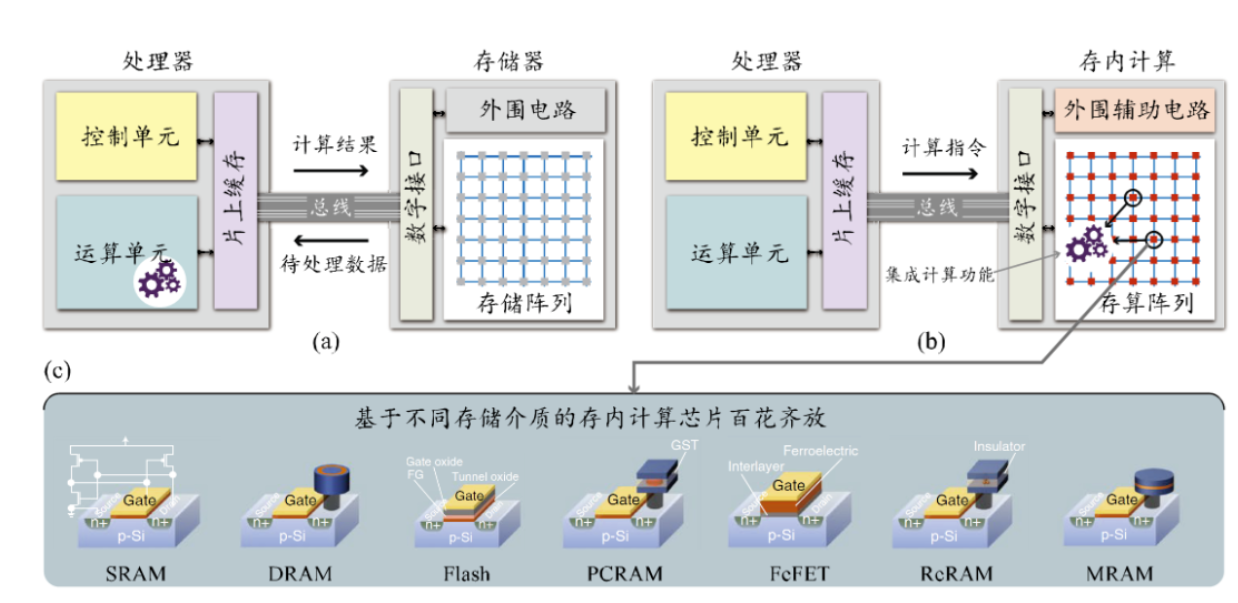
存内计算的存储选择

小结


更多热点文章阅读
狂砸900亿美元!塔塔集团半导体投资超美欧补贴,印度半导体制造这就成了? 全球首架C919正式交付,背后是中国制造业的崛起 包机出海拿下10亿订单!企业面对面沟通,或更利于电子产品出口! 千亿芯片出货的Arm,能在PC市场称王吗? 被裹挟的台积电与昂贵的“美国制造”:投资400亿美元补贴不足5%
原文标题:存内计算对“存”的选择
文章出处:【微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
电子发烧友网
+关注
关注
1010文章
544浏览量
164487
原文标题:存内计算对“存”的选择
文章出处:【微信号:elecfans,微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
知存科技启动首届存内计算创新大赛
存内计算作为一项打破“内存墙”“功耗墙”的颠覆性技术,消除了存与算的界限,相比CPU或GPU能够实现更高计算并行度、更大专用算力,达成数量级
d锁存器解决了sr锁存器的什么问题
D锁存器(Data Latch)和SR锁存器(Set-Reset Latch)是数字电路中常见的两种存储元件。它们在数字系统中扮演着重要的角色,用于存储和传递信息。然而,这两种锁存器在设计和应用上
知存科技推动新一代存内计算芯片产品产业化进程
6月3日,知存科技总部启航仪式在杭州临平算力小镇正式举行,标志着公司在存内计算芯片领域开启技术研发、人才战略、产业升级的新征程。临平区委书记陈如根,区委常委、组织部长杨霞,区委常委
存内计算——助力实现28nm等效7nm功效
当的性能。存算一体尝试通过集成存储和计算在一个芯片甚至一个容器内,来突破访存限制,发挥芯片的最大算力。下面我们将重点介绍存算一体技术。

论基于电压域的SRAM存内计算技术的崭新前景
这篇文章总结了冯·诺伊曼架构及其在处理数据密集型应用中所面临的性能和能耗问题。为了应对这一挑战,文章介绍了存内计算技术,其中重点讨论了基于电压域的SRAM存
浅谈存内计算生态环境搭建以及软件开发
应用架构,提高开发效率。
此外,在搭建存内计算环境时,关键的硬件和软件是不可或缺的。硬件方面,需要足够的RAM来存储数据集和支持计算过程。软件方面,则涉及
发表于 05-16 16:40
知存科技助力AI应用落地:WTMDK2101-ZT1评估板实地评测与性能揭秘
算一体领域,全球参与者可分为国际巨头和新兴企业两大阵营。国际巨头如英特尔、IBM、特斯拉等早已布局存算技术,并推出代表未来趋势的产品。而新兴企业则更灵活选择存内
发表于 05-16 16:38
存内计算WTM2101编译工具链 资料
存内计算是突破物理极限的下一代算力技术- AIGC等人工智能新兴产业的快速发展离不开算力,算力的基础是人工智能芯片。
当前CPU/GPU在执行计算密集型任务时需要将海量参数(ωij)
发表于 05-16 16:33
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究
本文深入探讨了基于SRAM和MRAM的存算一体技术在计算领域的应用和发展。首先,介绍了基于SRAM的存内逻辑计算技术,包括其原理、优势以及在

存内计算芯片研究进展及应用
在NOR Flash存内计算芯片当中,向量-矩阵乘法运算基于电流/电压的跨导与基尔霍夫定律进行物理实现,如图7(a)所示。因此,其核心是设计NOR Flash单元阵列以满足大规模高能效向量-矩阵乘法
浅谈存内计算生态环境搭建以及软件开发
在当今数据驱动的商业世界中,能够快速处理和分析大量数据的能力变得越来越重要。而存内计算开发环境在此领域发挥其关键作用。存内





 工商网监
工商网监
评论