 得物云原生全链路追踪Trace2.0-采集篇
得物云原生全链路追踪Trace2.0-采集篇
0
0xcc 开篇
2020 年 3月,得物技术团队在三个月的时间内完成了整个交易体系的重构,交付了五彩石项目,业务系统也进入了微服务时代。系统服务拆分之后,虽然每个服务都会有不同的团队各司其职,但服务之间的依赖也变得复杂,对服务治理等相关的基础建设要求也更高。
对服务进行监控是服务治理、稳定性建设中的一个重要的环节,它能帮助提早发现问题,预估系统水位,以及对故障进行分析等等。从 2019 年末到现在,得物的应用服务监控系统经历了三大演进阶段,如今,整个得物的应用微服务监控体系已经全面融入云原生可观测性技术 OpenTelemetry。

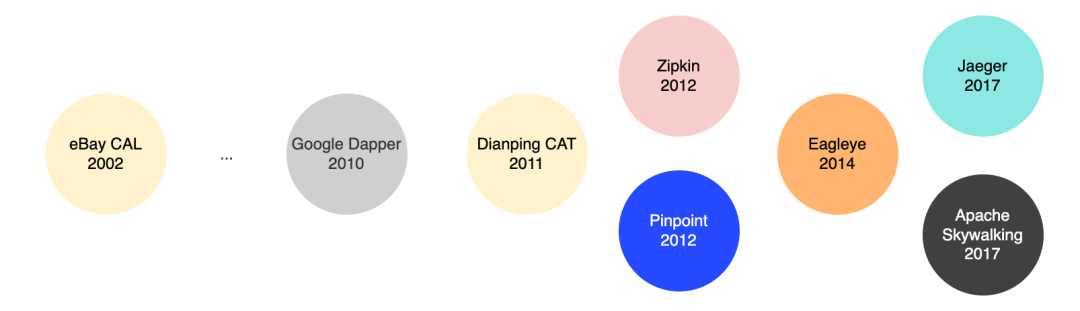
回顾过去十年间,应用服务监控行业的竞争也很激烈,相关产品如雨后春笋般涌现,如推特在 2012 年开源的 Zipkin,韩国最大的搜索引擎和门户网站 Naver 开源的 Pinpoint,近几年 Uber 公司开源的 Jaeger,以及我们国内吴晟开源的 SkyWalking。
有人说,这些其实都归功于 Google 在 2010 年基于其内部大规模分布式链路追踪系统 Dapper 实践而发表的论文,它的设计理念是一切分布式调用链追踪系统的始祖,但其实早在二十年前(2002年),当年世界上最大的电商平台 eBay 就已拥有了调用链追踪系统 CAL(Centralized Application Logging)。2011 年,原eBay的中国研发中心的资深架构师吴其敏跳槽至大众点评,并且深入吸收消化了 CAL 的设计思想,主导研发并开源了CAT(Centralized Application Tracking)。
1
0x01 第一阶段
从0~1基于CAT的实时应用监控
在得物五彩石项目交付之前,系统仅有基础设施层面的监控,CAT 的引入,很好地弥补了应用监控盲区。它支持提供各个维度的性能监控报表,健康状况检测,异常统计,对故障问题排查起到了积极推动的作用,同时也提供简单的实时告警的能力。
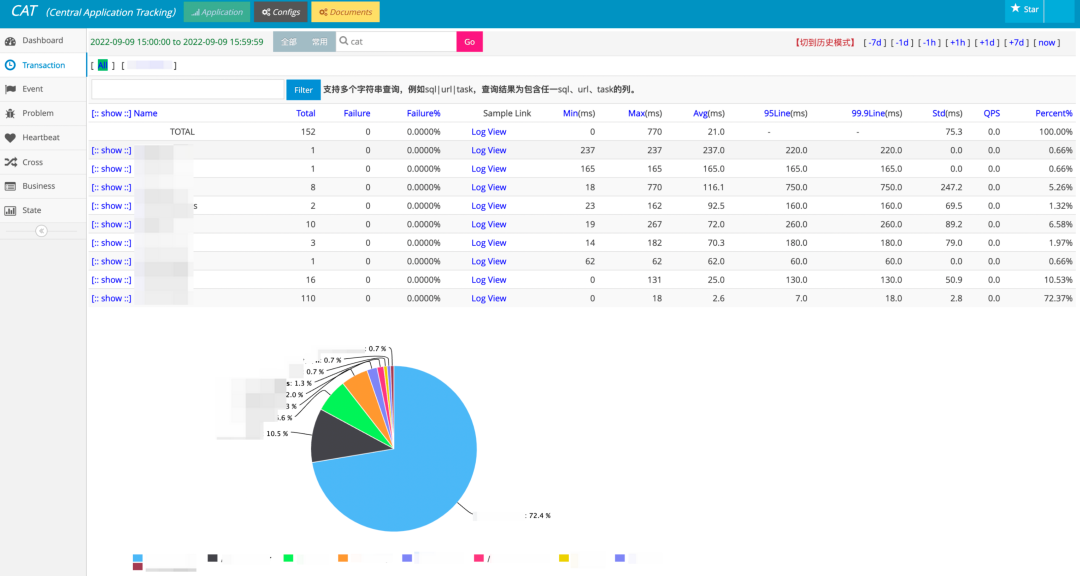
CAT 拥有指标分钟级别的聚合统计的能力,从 UI 上不难看出,它拥有丰富的报表统计能力和问题排障能力。
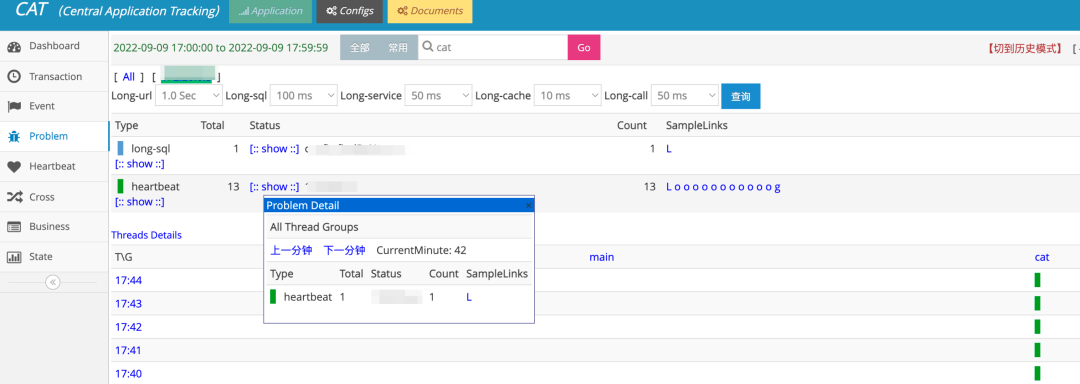
但随着公司业务规模逐步扩大,微服务粒度也不可避免地变小,我们发现,CAT 已经逐步无法满足我们的使用场景了:
-
无法直观呈现全链路视图:
问题排障与日常性能分析的场景也越来越复杂,对于一个核心场景,其内部的调用链路通常复杂多变,站在流量角度上看,需要完整地知道它的来源,上下游链路,异步调用等等,这对于 CAT 来说可能略显超纲。
- 缺少图表定制化能力:
2
0x02 第二阶段
持续创造 基于OpenTracing全链路采样监控
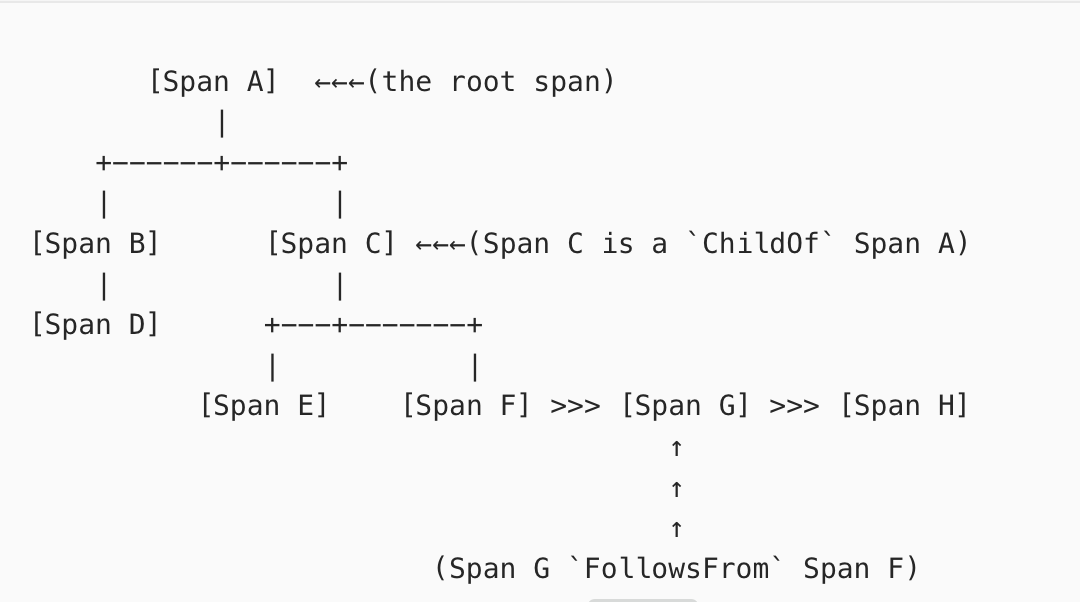
OpenTracing 为全链路追踪 Trace 定制了完整的一套协议标准,本身并不提供实现细节。在 OpenTracing 协议中,Trace 被认为是 Span 的有向无环图(DAG)。官方也例举了以下 8 个 Span 的因果关系和他们组成的单 Trace示例图:
在当时, OpenTracing 相关的开源社区也是异常活跃,它使用 Jaeger 来解决数据的收集,调用链则使用了甘特图展示:
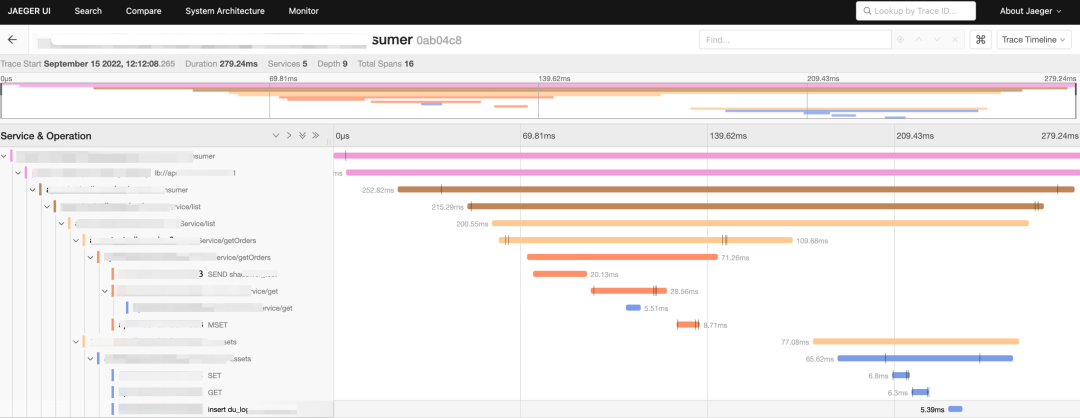
在 OpenTracing 生态中,我们对链路的采样使用头部采样策略, 对于指标 Metrics,OpenTracing 并没有制定它的规范,但在 Google SRE Book 里,关于 Monitoring Distributed System 章节中提到了四类黄金指标:
吞吐量:如每秒请求数,通常的实现方式是,设定一个计数器,每完成一次请求将自增。通过计算时间窗口内的变化率来计算出每秒的吞吐量。
延迟:处理请求的耗时。
错误率/错误数:如 HTTP 500 错误。当然,有些即便是 HTTP 200 状态也需要根据特定业务逻辑来区分当前请求是否属于“错误”请求。
所以,我们决定使用 Micrometer 库来对各个组件进行吞吐量,延迟和错误率的埋点,从而对 DB 类,RPC类的组件做性能监控。因此也可以说,我们第二阶段的监控是以指标监控为主,调用链监控为辅的应用性能监控。2.1 使用 Endpoint 贯穿指标埋点帮助性能分析在指标埋点过程中,我们在所有的指标中引入了“流量入口(Endpoint)”标签。这个标签的引入,实现了根据不同流量入口来区分关联 DB,缓存,消息队列,远程调用类的行为。通过流量入口,贯穿了一个实例的所有组件指标,基本满足了以下场景的监控:
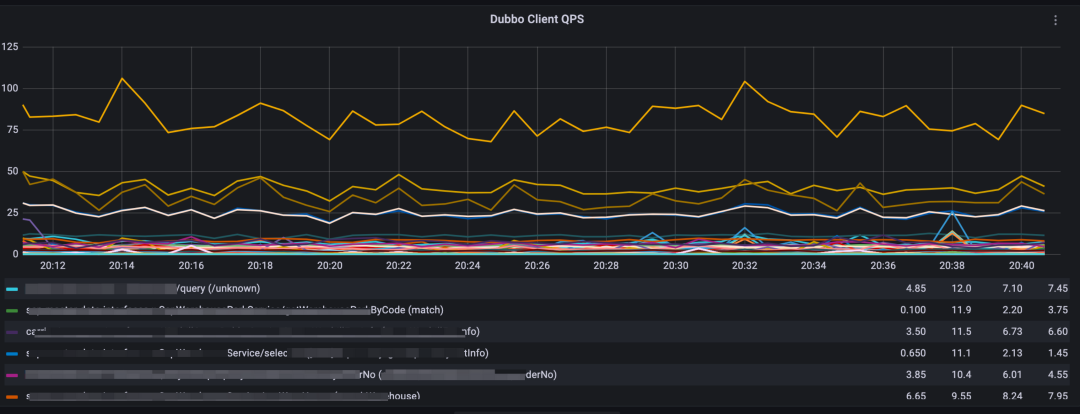
-
接口高耗时分析,根据指标,可还原出单位时间窗口的耗时分解图快速查看耗时组件。

2.2 关于选型的疑问
你可能会问,链路监控领域在业内有现成的 APM 产品,比如 Zipkin, Pinpoint, SkyWalking 等,为什么当时会选择 OpenTracing + Prometheus 自行埋点?主要有两大因素:
第一,在当时,CAT 无法满足全链路监控和一些定制化的报表分析,而得物交易链路五彩石项目交付也趋于尾声,贸然去集成外部一款庞大的 APM 产品在没有充分的验证下,会给服务带来稳定性风险,在极其有限的时间周期内不是个理智的选择。
第二,监控组件是随着统一的基础框架来发布,同时,由另一团队牵头开发的全链路影子库路由组件借助了 OpenTracing 随行数据透传机制,且与监控组件是强耦合关系,而基础框架将统筹监控,压测和其他模块,借助Spring Boot Starter 机制,一定程度上做到了功能的开箱即用,无缝集成。而使用字节码增强方式的 Pinpoint, SkyWalking,无法很好地做到与基础框架集成,若并行开发,也会多出基础框架与 Java Agent 两边的管理和维护成本,减缓迭代速度。
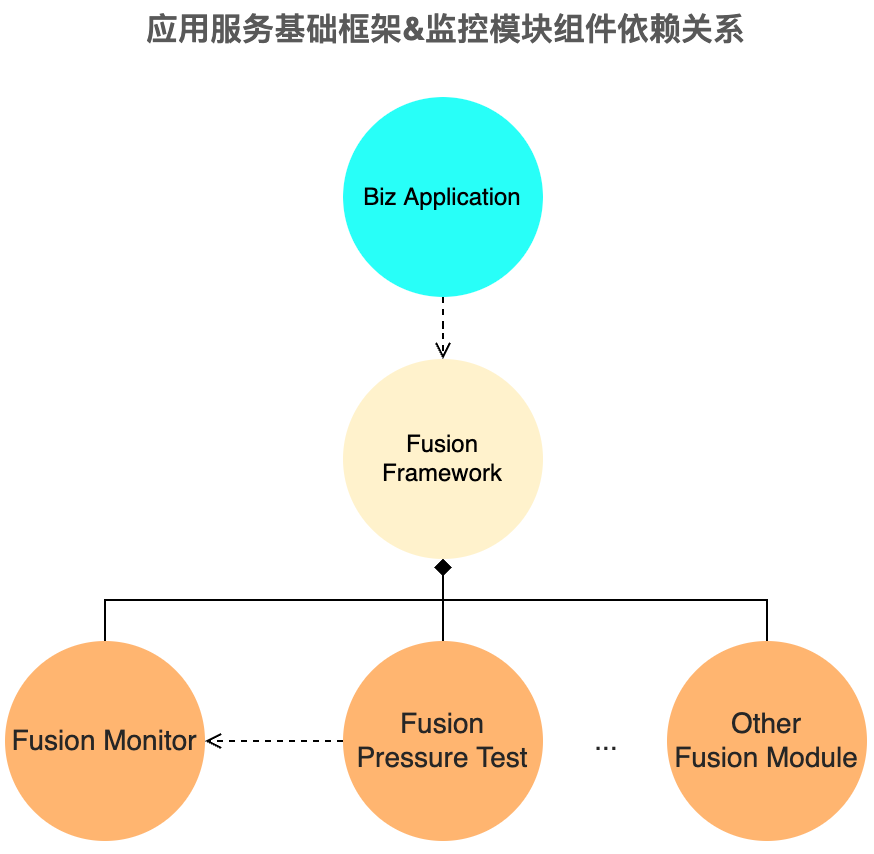
在之后将近两年的时间里,应用服务监控覆盖了得物技术部使用的将近 70% 的组件,为得物App在 2021 年实现全年 99.97% 的 SLA 提供了强有力的支持。现在看来,基于 OpenTracing + Prometheus 生态,很好地解决了分布式系统的调用链监控,借助 Grafana 图表工具,做到了灵活的指标监控,融合基础框架,让业务方开箱即用…然而,我们说第二阶段是基于 OpenTracing 全链路采样监控,随着业务的高速发展,这套架构的不足点也逐渐显露出来。
2.3 架构特点
- 体验层面
-
-
指标:覆盖面广,维度细,能清晰地根据各模块各维度来统计分析,基本做到了监控灵活的图表配置需求。但不可否认它是一种时序聚合数据,无法细化为个体。假如在某个时间点发生过几次高耗时操作,当吞吐量达到一定时,平均耗时指标曲线仍然趋于平稳,没有明显的突出点,导致问题发现能力降低。
-
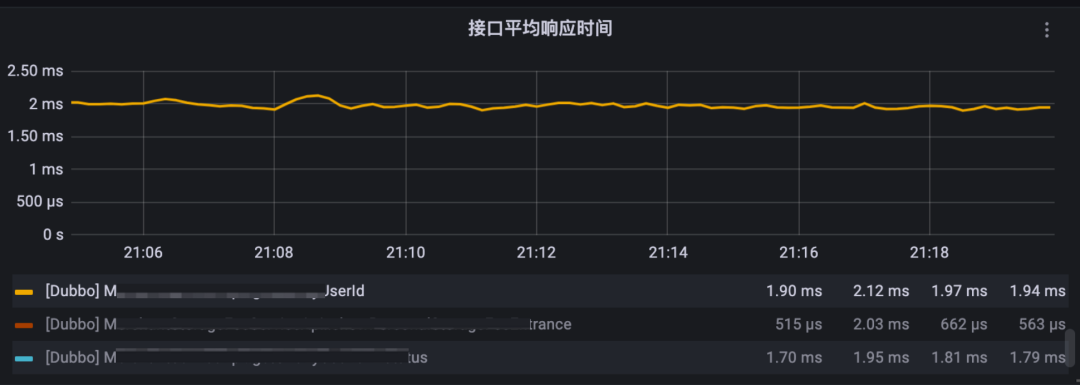
-
-
链路:1%的采样率使得业务服务基本不会因调用链发送量大而导致性能问题,但同时也往往无法从错误,高耗时的场景中找到正好采样的链路。期间,我们曾经考虑将头部采样策略改为尾部采样,但面临着非常高昂的 SDK 改造成本和复杂调用情况下(如异步)采样策略的回溯,且无法保证发生每个高耗时,错误操作时能还原整个完整的调用链路。
-
集成方式:业务和基础框架均采用 Maven 来构建项目,使用 Spring Boot Starter "all in one"开箱即用方式集成,极大降低了集成成本的同时,也给依赖冲突问题埋下了隐患。
-
- 项目迭代层面
迭代周期分化矛盾,与基础框架的集成是当时快速推广落地全链路监控的不二选择,通过这种方式,Java 服务的接入率曾一度接近100%,但在业务高速发展的背景下,基础框架的迭代速度已经远远跟不上业务迭代速度了,这也间接制约了整个监控系统的迭代。
- 数据治理层面
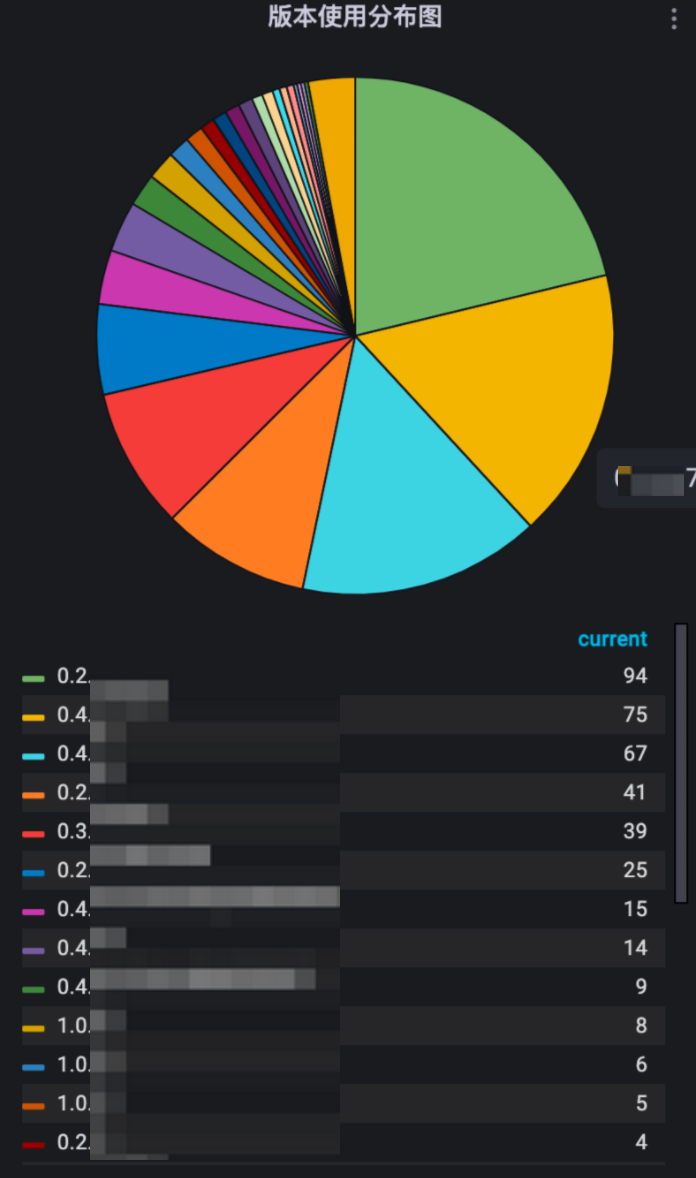
尽管监控系统在每一次迭代时都会尽可能保证最大的向后兼容,但将近两年的迭代周期里,不同版本造成的数据差异也极大制约了监控门户系统天眼的迭代,开发人员长时间奔波于数据上的妥协,在很多功能的实现上曲线救国。
- 稳定性层面
相关预案依托于 Spring 框架 Bean 的自动装配逻辑,业务方理解成本低,便于变更,但缺少细粒度的预案,比如运行时期间特定逻辑降级等等。
-
-
2021 年下半年开始,为了充分平衡以上的收益与风险,我们决定将监控采集端与基础框架解耦,独立迭代。在此之前,在 CNCF(云原生计算基金会)的推动下,OpenTracing 也与 OpenCensus 合并成为了一个新项目 OpenTelemetry。
-

3
0x03 第三阶段
向前一步 基于OpenTelemetry全链路应用性能监控
OpenTelemetry 的定位在于可观测性领域中对遥测数据采集和语义规范的统一,有 CNCF (云原生计算基金会)的加持,近两年里随着越来越多的人关注和参与,整个体系也越发成熟稳定。
其实,我们在2020年底就已开始关注 OpenTelemetry 项目,只不过当时该项目仍处于萌芽阶段, Trace, Metrics API 还在 Alpha 阶段,有很多不稳定因素,考虑到需尽快投入生产使用,笔者曾在 2021 年中到年末期间也或多或少参与了 OpenTelemetry 社区相关 issue 的讨论,遥测模块的开发,底层数据协议的一致和一些 BUG 的修复。在这半年期间,相关 API 和 SDK 随着越来越多的人参与也逐步趋于稳定。
OpenTelemetry架构(图源自 opentelemetry.io)
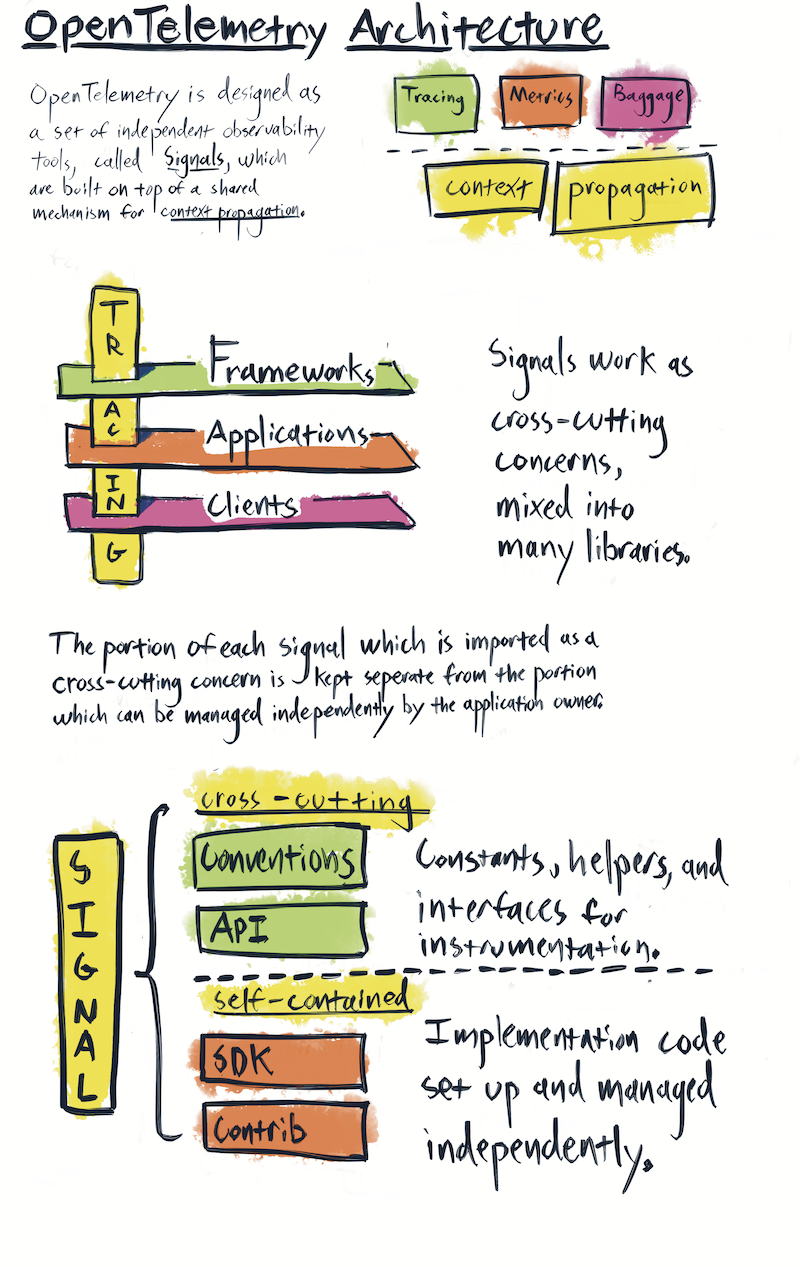
3.1 迈入 Trace2.0 时代
OpenTelemetry 的定位致力于将可观测性三大要素 Metrics,Trace,Log 进行统一,在遥测 API 制定上,提供了统一的上下文以便 SDK 实现层去关联。如 Metrics 与 Trace 的关联,笔者认为体现在 OpenTelemetry 在 Metrics 的实现上包含了对 OpenMetrics 标准协议的支持,其中 Exemplar 格式的数据打通了 Trace 与 Metrics 的桥梁:
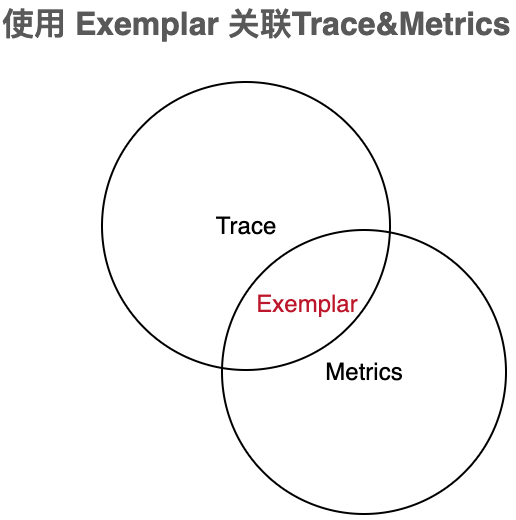
OpenMetrics 是建立在 Prometheus 格式之上的规范,做了更细粒度的调整,且基本向后兼容 Prometheus 格式。
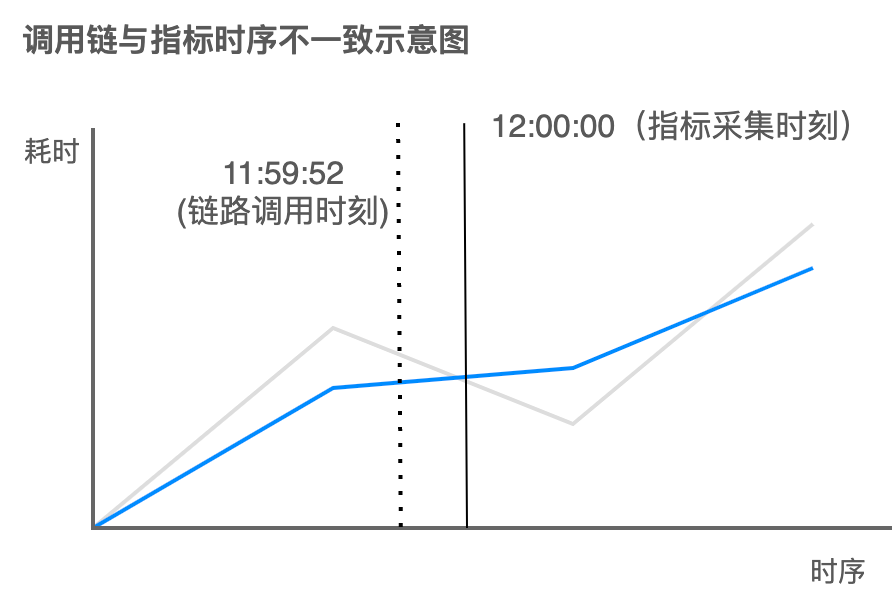
在这之前,Metrics 指标类型的数据无法精确关联到具体某个或某些 Trace 链路,只能根据时间戳粗略关联特定范围内的链路。这个方案的缺陷源自指标采集器 vmagent 每隔 10s~30s 的 Pull 模式中,指标的时间戳取决于采集时刻,与 Trace 调用时间并不匹配。
shadower_virtual_field_map_operation_seconds_bucket{holder="Filter:Factory",key="WebMvcMetricsFilter",operation="get",tcl="AppClassLoader",value="Servlet3FilterMappingResolverFactory",le="0.2"} 3949.0 1654575981.216 # {span_id="48f29964fceff582",trace_id="c0a80355629ed36bcd8fb1c6c89dedfe"} 1.0 1654575979.751
为了采集 Exemplar 格式指标,同时又需防止分桶标签“le”产生的高基数问题,我们二次开发了指标采集 vmagent,额外过滤携带 Exemplar 数据的指标,并将这类数据异步批量发送到了 Kafka,经过 Flink 消费后落入 Clickhouse 后,由天眼监控门户系统提供查询接口和UI。
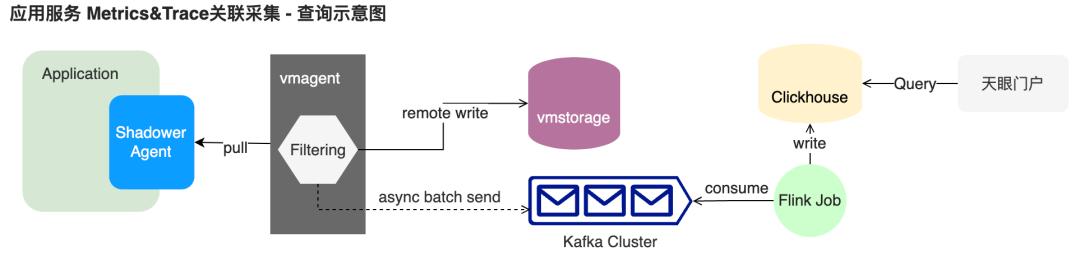
分位线统计与Exemplar 数据关联UI示意图
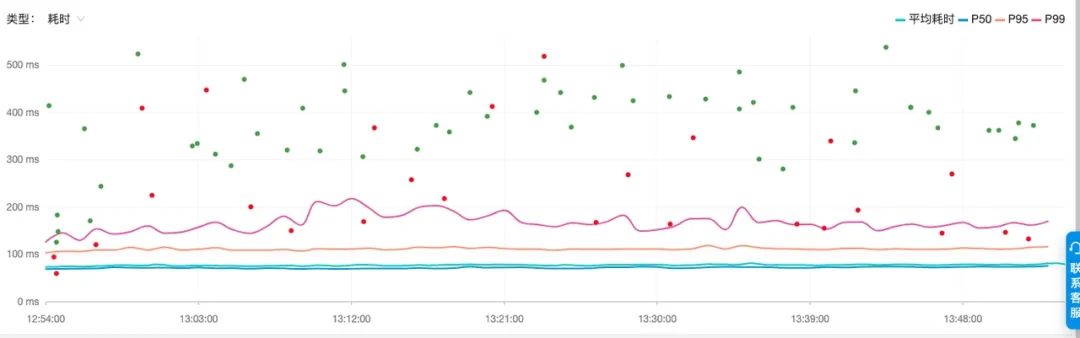
在数据上报层,OpenTelemetry Java SDK 使用了比 JDK 原生的阻塞队列性能更好的 Mpsc (多生产单消费)队列,它使用大量的 long 类型字段来做内存区域填充,用空间换时间解决了伪共享问题,减少了并发情况下的写竞争来提高性能。
在流量高峰时期,链路数据的发送队列这一块的性能从火焰图上看 CPU 占比平均小于2%,日常服务CPU整体水位与0采样相比几乎没有明显差距,因此我们经过多方面压测对比后,决定在生产环境客户端侧开放链路数据的全量上报,实现了在得物技术史上的全链路 100% 采样,终结了一直以来因为低采样率导致问题排查困难的问题,至此,在第三阶段,得物的全链路追踪技术正式迈入 Trace2.0 时代。
得益于 OpenTelemetry 整体的可插拔式 API 设计,我们二次开发了 OpenTelemetry Java Instrumentation 项目 Shadower Java,扩展了诸多功能特性:
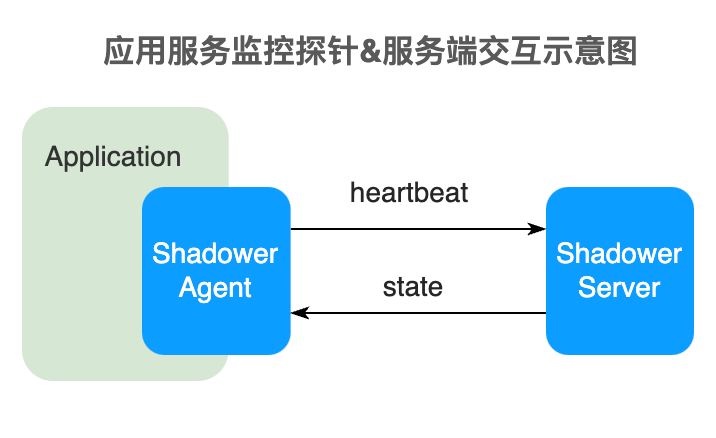
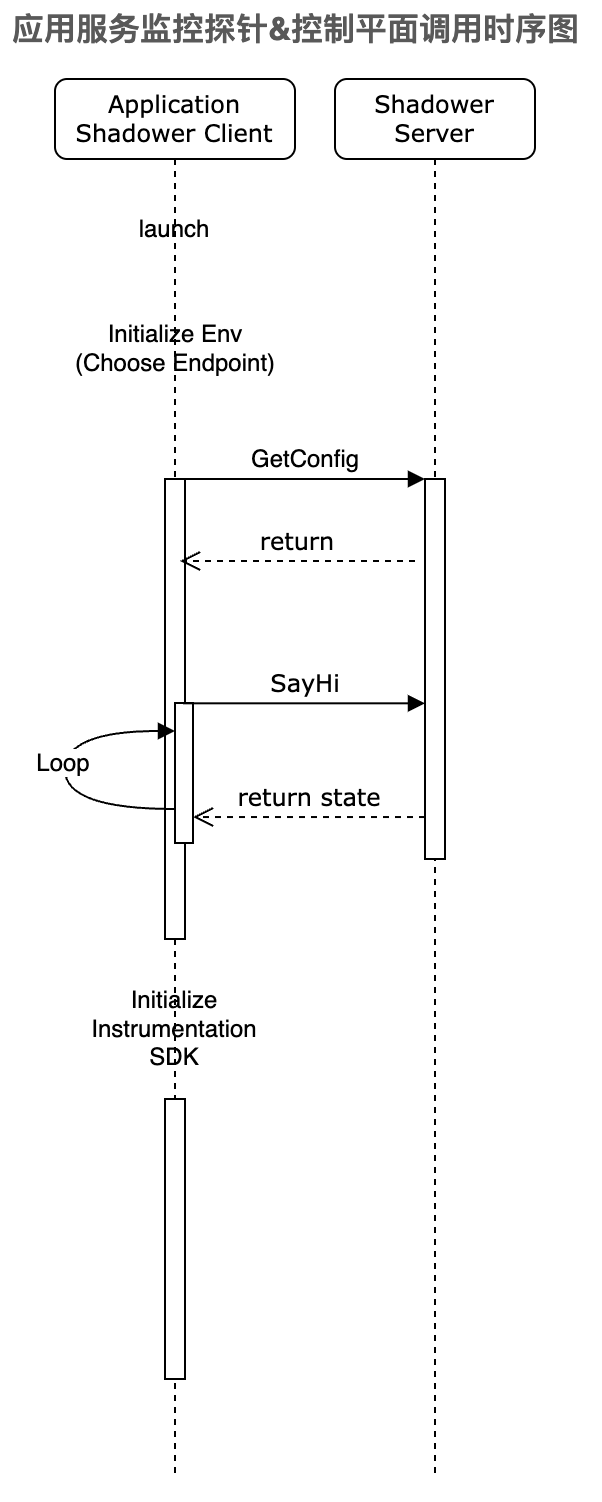
3.2 引入控制平面管理客户端采集行
使用控制平面,通过客户端监听机制来确保配置项的下发动作,包括:
- 实时动态采样控制
- 诊断工具 Arthas 行为控制
- 实时全局降级预案
- 遥测组件运行时开关
- 实时 RPC 组件出入参收集开关
- 实时高基数指标标签的降级控制
- 按探针版本的预案管理
- 基于授权数的灰度接入策略。
- ... ...
控制平面的引入,弥补了无降级预案的空白,也提供了更加灵活的配置,支持了不同流量场景下快速变更数据采集方案:
3.3 独立的启动模块
为了解决业务方因集成基础框架而长期面临的依赖冲突问题,以及多版本共存引起的数据格式分散与兼容问题,我们自研了无极探针工具箱 Promise, 它是个通用的 javaagent launcher, 结合远端存储,支持可配置化任意 javaagent 的下载,更新,安装和启动:
[plugins]
enables = shadower,arthas,pyroscope,chaos-agent
[shadower]
artifact_key = /javaagent/shadower-%s-final.jar
boot_class = com.shizhuang.apm.javaagent.bootstrap.AgentBootStrap
classloader = system
default_version = 115.16
[arthas]
artifact_key = /tools/arthas-bin.zip
;boot_class = com.taobao.arthas.agent334.AgentBootstrap
boot_artifact = arthas-agent.jar
premain_args = .attachments/arthas/arthas-core.jar;;ip=127.0.0.1
[pyroscope]
artifact_key = /tools/pyroscope.jar
[chaos-agent]
artifact_key = /javaagent/chaos-agent.jar
boot_class = com.chaos.platform.agent.DewuChaosAgentBootstrap
classloader = system
apply_envs = dev,test,local,pre,xdw

3.4 基于 Otel API 的扩展
3.4.1 丰富的组件度量
在第二阶段 OpenTracing 时期,我们使用 Endpoint 贯穿了多个组件的指标埋点,这个优秀的特性也延续至第三阶段,我们基于底层 Prometheus SDK 设计了一套完善的指标埋点 SDK,并且借助字节码插桩的便捷,优化并丰富了更多了组件库。(在此阶段,OpenTelemetry SDK 主版本是 1.3.x ,相关 Metrics SDK 还处于Alpha 阶段)
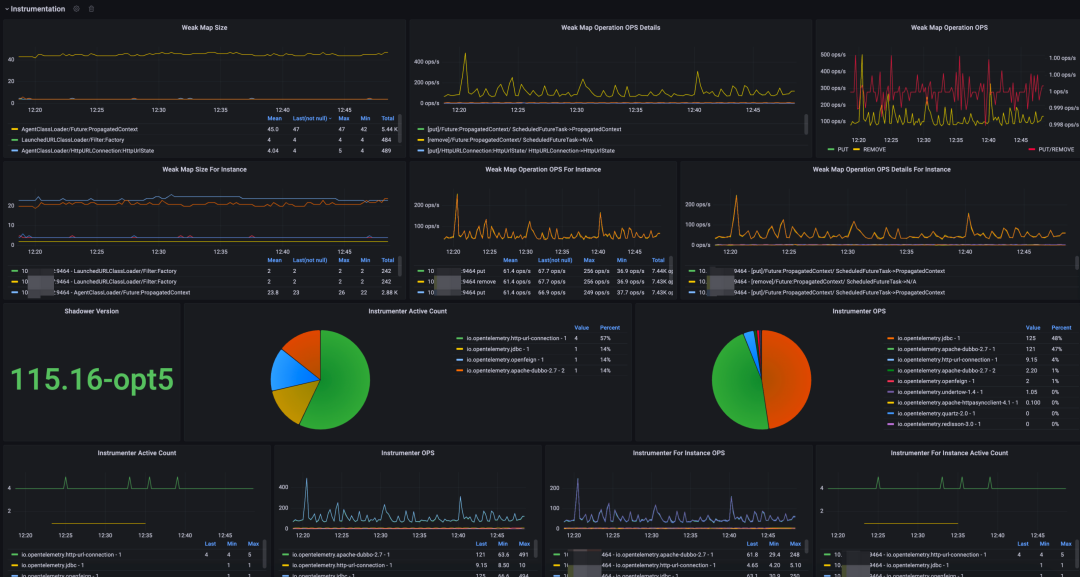
Otel 的 Java Instrumnetation 主要使用 WeakConcurrentMap 来做异步链路上下文数据传递和同线程上下文关联的容器,由于 Otel 对许多流行组件库做了增强,因此 WeakConcurrentMap 的使用频率也是非常高的,针对这个对象的 size 做监控,有助于排查因探针导致的内存泄露问题,且它的增长率一旦达到我们设定的阈值便会告警,提早进行人工干预,执行相关预案,防止线上故障发生。
部分自监控面板
3.4.2扩展链路透传协
1) 引入RPC ID
为了更好地关联上下游应用,让每个流量都有“身份”,我们扩展了 TextMapPropagator 接口,让每个流量在链路上都知道请求的来源,这对跨区域,环境调用排障场景起到关键性作用。
此外,对于跨端场景,我们参考了阿里鹰眼调用链RPCID模型,增加了RpcID字段,这个字段在每次发生跨端调用时末尾数值会自增,而对于下游应用,字段本身的层级自增:
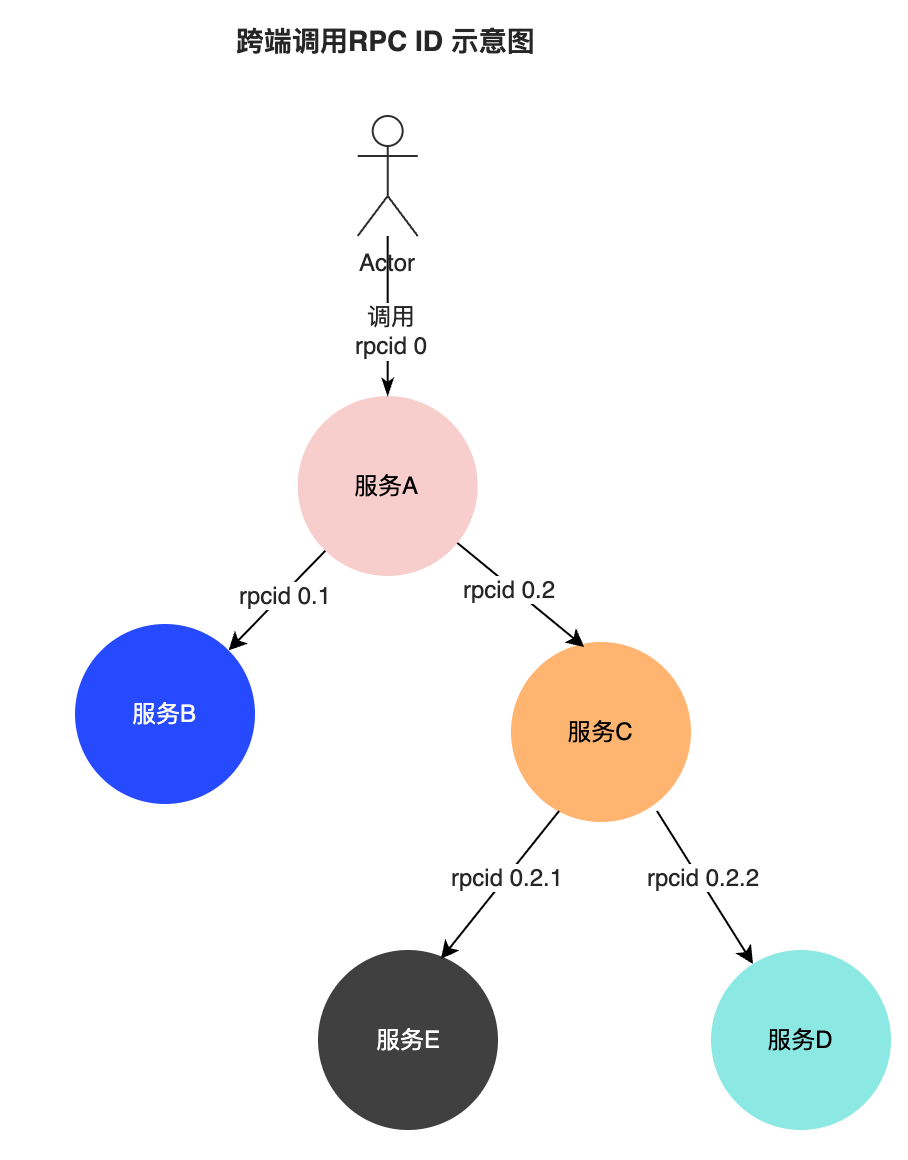
该字段拥有以下作用:
支持提供精简化的调用链路视图,查询臃肿链路(如那些涉及缓存,DB调用大于 2000 Span的链路)时只提供 RPC 调用节点和调用层次关系。
链路保真,客户端链路数据上报队列并不是个无界限队列,当客户端自身调用频繁时,若上报队列堆积达到阈值即会丢弃,这会造成整个链路的不完整,当然这是预期内的现象,但若没有RpcID字段,链路视图将无法关联丢失的节点,从而导致整个链路层级混乱失真。
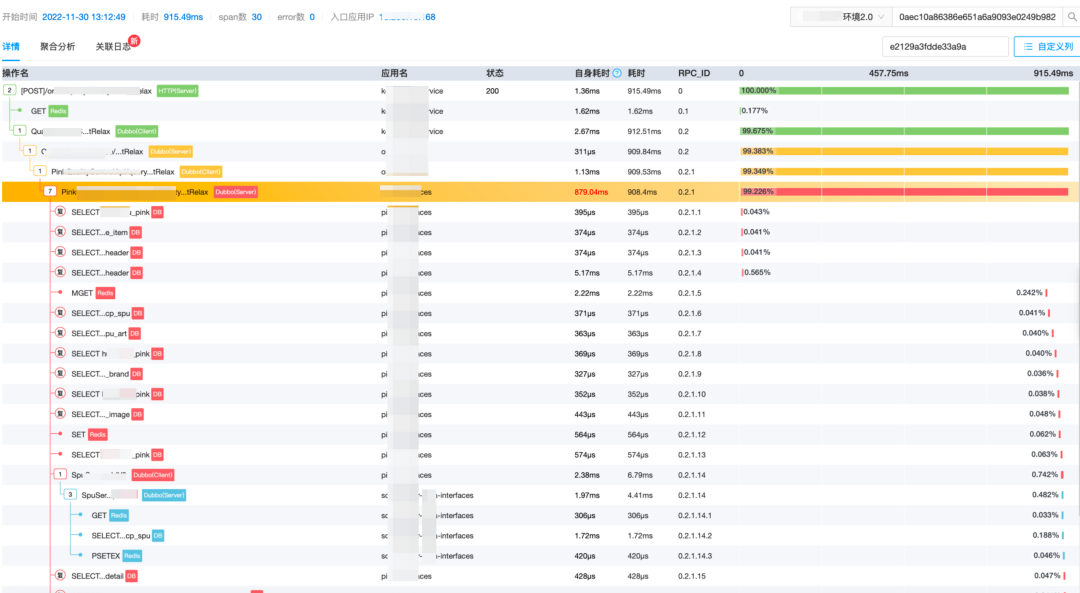
2) 自定义 Trace ID
为了实现链路详情页高效的检索效率,我们扩展 TraceID 生成逻辑,ID的前8位使用实例IP,中8位使用当前时间戳,后16位采用随机数生成。
32位自定义traceId:c0a8006b62583a724327993efd1865d8
c0a8006b 62583a72 4327993efd1865d8
| | |
高8位(IP) 中8位(Timestmap) 低16位(Random)
这样的好处有两点:
通过 TraceID 反向解析时间戳,锁定时间范围,有助于提高存储库 Clickhouse 的检索效率,此外也能帮助决定当前的 Trace 应该查询热库还是冷库。
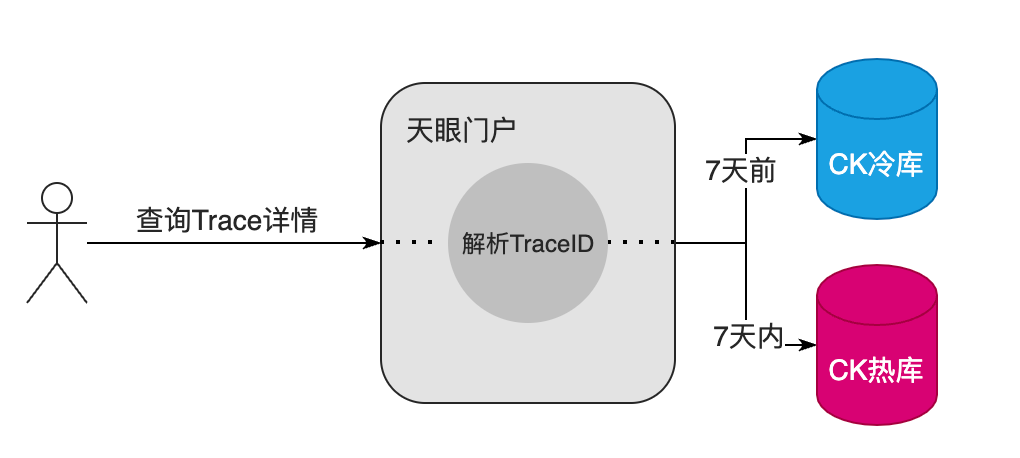
绑定实例 IP,有助于关联当前 Trace 流量入口所属的实例,在某些极端场景,当链路上的节点检索不到时,也能通过实例和时间两个要素来做溯源。
3) 异步调用识别
业务系统为了提高服务吞吐量,充分运用硬件资源,异步调用场景可谓无处不在。我们基于Otel实现的异步链路上下文传递的基础上,额外扩充了"async_flag"字段来标识当前节点相对于父节点的调用关系,从而在展示层上能迅速找出发生异步调用的场景
3.4.3 更清晰的调用链结构
在 Otel 支持的部分组件中,有些操作不涉及到网络调用,或者具有非常频繁的操作,如 MVC 过程,数据库连接获取等,通常来说这类节点在链路详情主视图中的意义不大,因此我们对这类节点的产生逻辑进行了优化调整,使得整个链路主体结构聚焦于“跨端”,同时,对部分核心组件关键内部方法细节做了增强,以“事件”的形式挂载于它们的父节点上,便于更细粒度的排查:
RPC 调用关键内部事件
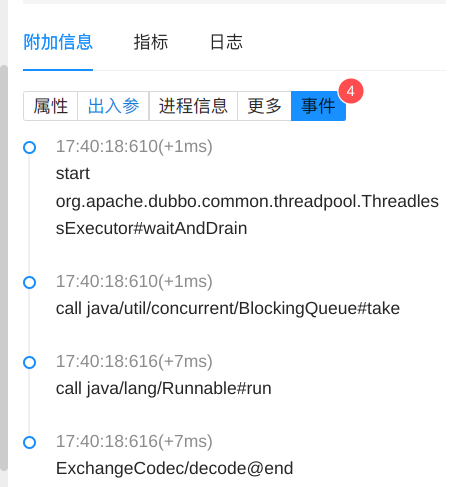
DB 调用连接获取事件
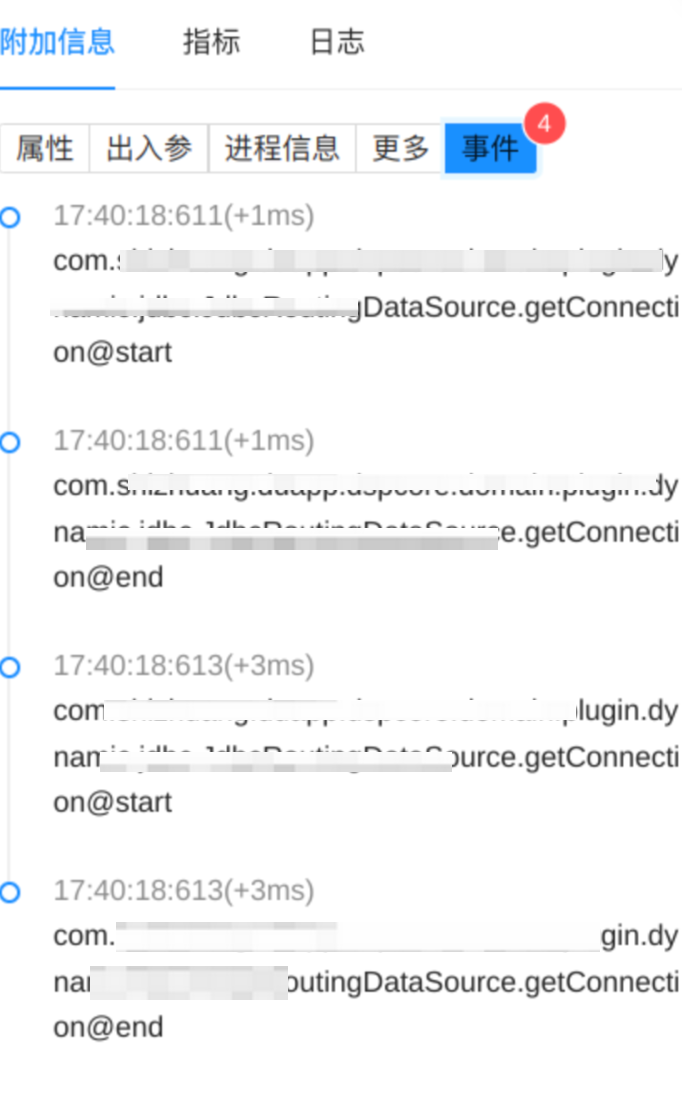
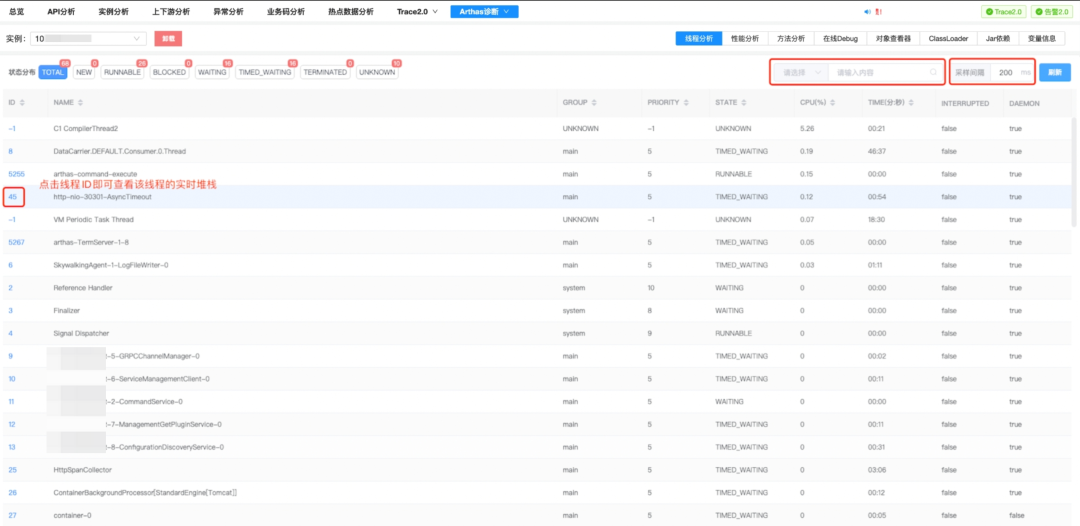
3.4.4 profiling 的支持
1)线程栈分析的集成。通过集成 Arthas 这类工具,可以很方便地查看某个实例线程的实时堆栈信息,同时对采样间隔做控制,避免频繁抓取影响业务自身性能。
2)通过集成 pyroscope,打通高延迟性能排查最后一公里。Pyroscope 对 async profiler 做了二次开发,同时也支持 Otel 去集成,但截至目前,官方并没有实现完整的 Profiling 行为的生命周期,而 Profiling 行为一定程度上会影响性能,于是我们对官方 Pyroscope 的生命周期做了扩展,实现“停止”行为的同时,采用时间轮算法来检测特定操作的耗时,当达到期望的阈值将触发开启 profiling, 待操作结束或超过最大阈值则停止。

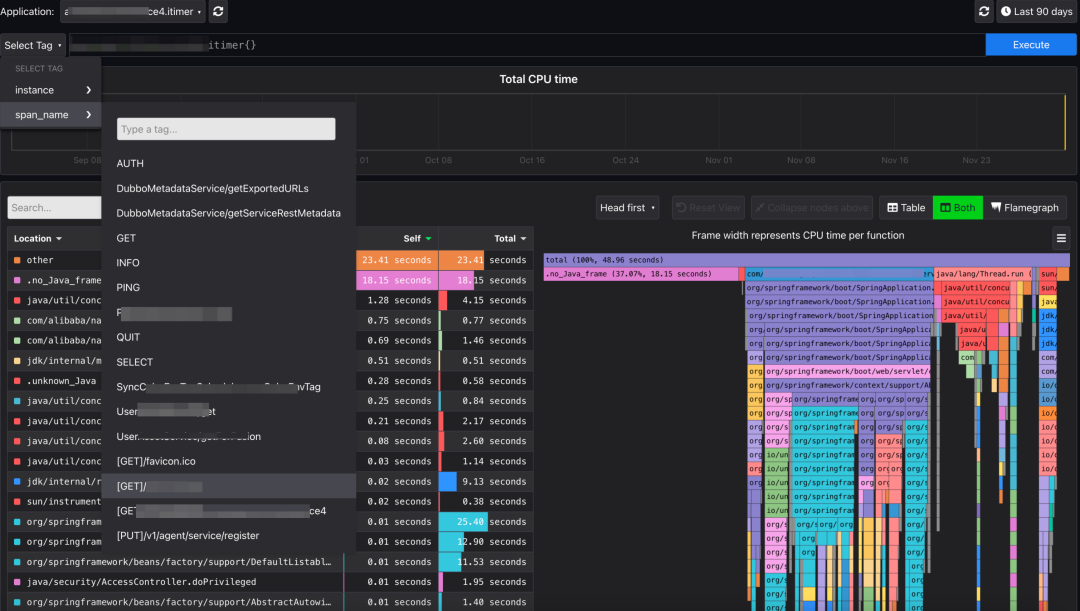
关于性能诊断相关的运用,请期待后续诊断专题。
4
0xff 结语
纵观得物在应用监控采集领域的三大里程碑迭代,第一阶段的 CAT 则是 0~1 的过程,它提供了应用服务对自身观测的途径,让业务方第一次真实地了解了服务运行状况,而第二阶段开始,随着业务发展的飞速提升,业务方对监控系统的要求就不仅只是从无到有了,而是要精细,准确。
因此,快速迭代的背景下,功能与架构演进层面的矛盾,加上外部云原生大背景下可观测领域的发展因素,促使我们进行了基于 OpenTelemetry 体系的第三阶段的演进。功能,产品层面均取得了优异的结果。如今,我们即将进行下一阶段的演进,深度结合调用链与相关诊断工具,以第三阶段为基础,让得物全链路追踪技术正式迈入性能分析诊断时代。
审核编辑 :李倩
-
监控系统
+关注
关注
21文章
3915浏览量
174788 -
cat
+关注
关注
1文章
75浏览量
21284 -
微服务
+关注
关注
0文章
137浏览量
7352
原文标题:得物云原生全链路追踪Trace2.0-采集篇
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何选择云原生机器学习平台
什么是云原生MLOps平台
梯度科技入选2024云原生企业TOP50榜单
软通动力荣登2024云原生企业TOP50榜单
云原生和数据库哪个好一些?
k8s微服务架构就是云原生吗?两者是什么关系
云原生和非云原生哪个好?六大区别详细对比
京东云原生安全产品重磅发布
从积木式到装配式云原生安全
基于DPU与SmartNic的云原生SDN解决方案
云原生转型中从理念到实践的探索与挑战

米哈游大数据云原生实践






 工商网监
工商网监
评论