 对比NEON汇编与NEON Intrinsics编程的优缺点
对比NEON汇编与NEON Intrinsics编程的优缺点
本文选自极术专栏《Infrastructure开源软件 on Arm》的Arm NEON学习系列。前面我们学习了如何快速上手开始NEON编程以及ArmNEON优化技术,本篇我们将对比NEON汇编与NEON Intrinsics编程的优缺点。
1.简介
ARMNEON编程主要有两种最常用的方式手写汇编和Intrinsics。本文将对比NEON汇编与NEON Intrinsics编程的优缺点。
2.NEON汇编与Intrinsics
NEON汇编与Intrinsics各有优缺点:

NEON汇编与Intrinsics各有优缺点:但实际情况远远比这些复杂很多,特别是涉及到ARM v7-A/v8-A跨平台的时候。下面我们结合实例做一些更深入的分析。
2.1 编程
对于初学者来说,Intrinsics比较易学易用。但是对于有汇编经验的开发者来说,可能更熟悉NEON汇编编程,切换到Intrinsics反倒需要有个适应过程。下文列出了实际开发中的一些问题。
2.1.1 指令灵活性
从指令使用角度来说,汇编指令比Intrinsics指令更灵活,主要体现在数据加载/存储上,比如下例:
-
Intrinsics指令
-
加载数据到一个64位寄存器 vld1_s8/u8/s16/u16/s32…etc
-
加载数据到一个128位寄存器vld1q_s8/u8/s16/u16/s32…etc
-
-
ARM v7-A汇编
VLD1 { Dd}, [Rn]
VLD1 { Dd, D(d+1) }, [Rn]
VLD1 { Dd, D(d+1), D(d+2)}, [Rn]
VLD1 { Dd, D(d+1), D(d+2), D(d+3) }, [Rn]
-
ARM v8-A汇编
LD1 { .]
LD1 { ., .}, []
LD1 { ., ., . }, []
LD1 { ., ., ., . }, []
这个问题主要针对现在,相信随着编译器的升级这些问题会逐渐解决的。
在一些情况下,有的编译器已经能把两条指令解析成一条汇编指令,比如: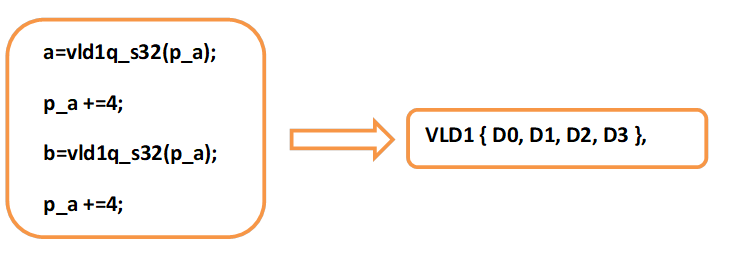
因此,我们有理由由相信,随着ARM v8-A编译器的不断升级,intrinsics指令会完善到跟汇编指令一样灵活的。
2.1.2 寄存器分配
NEON汇编编程时,需要自己分配寄存器,用户必须清楚寄存器的使用情况。而Intrinsics编程的一个好处就是,用户只需要定义变量即可,编译器会自动分配寄存器。这是优点,但有时也会变成弱点。实践证明,因为ARMv7-A只有16个128位NEON寄存器,在Intrinsics编程时,如果用户同时使用过多的NEON寄存器,会导致gcc编译器的寄存器分配问题。主要表现是编译器会把很多数据存储到堆栈中,这样会极大的影响程序性能。因此用户在使用Intrinsics编程时要注意这个问题。在性能出现异常时(比如C程序的性能比NEON程序的性能要好),检查反汇编,看是否有寄存器分配的问题出现。在ARM64中,有32个128位NEON寄存器,这个问题的影响大大减弱。
2.2 性能与编译器
在同一平台下,NEON汇编的性能与编译器无关,只由NEON的实现方式决定。好处是用户在调整代码时,用户可以预测、控制自己程序的性能,但没有惊喜。
NEON Intrinsics 的性能则极大的依赖于编译器,不同的编译器,性能可能有极大的差别。一般来说,越老版本的编译器,性能越差。如果用户需要保留对老版本编译器兼容性时,需要慎重考虑使用Intrinsics。此外,当用户优化代码细节的时候,编译器的介入,使用户很难预测程序性能的变化,但有时候会有惊喜,有时Intrinsics的性能会比汇编的性能要好。尽管很少见,但确实存在。
编译器主要对优化NEON程序造成影响。下图是NEON实现及优化的一般流程:
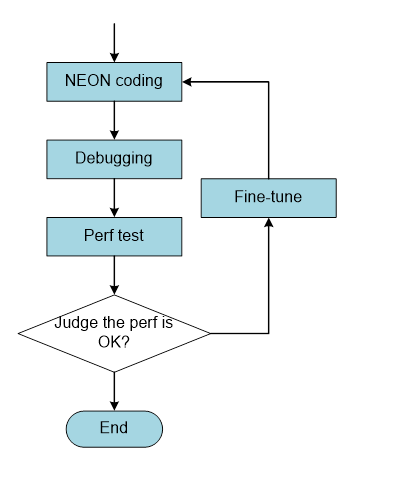
对于NEON汇编或是Intrinsics来讲,实现流程是一样的,编程——调试——测试。但是调优的步骤是不一样的。
NEON汇编的调优方式主要有:
• 改变实现方式,比如改变所用指令,调整并行方式。
• 调整指令顺序,以降低数据依赖性
• 上文第二章所介绍的方式都可以尝试
在汇编调优时,最精细方式是:
• 确定汇编指令数目和指令的时序
• 使用PMU (Performance Monitoring Unit)测量程序执行的周期数
• 根据使用指令的时序,调整程序,尽量减少指令延时
这种方式的缺点是,针对指定微架构的调整,换到另外的平台性能不一定会好。经常花费很大的工作量而只能取得很小的性能提升。
NEON intrinsics的调优则比较困难,
• 尝试NEON汇编所用的调优方式,然后
• 观察反汇编,看看数据依赖性、寄存器使用等情况
• 判断优化效果是否达到预期, 如果符合预期则工作结束。此时,需要测试多种编译器,检查性能的异同。
在使用intrinsics转换ARMv7-A的汇编时,优化效果判断比较简单,只要Intrinsics性能接近汇编性能即可。但是,在使用Intrinsics优化ARM v8-A的代码时,我们没有性能参考的对象,较难判断代码是否调整到最优状态了。可能会有疑问,会不会汇编实现的性能会更好?但随着整个ARM v8-A环境的成熟,这个问题带来的影响会越来越小。另外,如果更看重Intrinsics的其它优点,对性能也不是锱铢必较的话,这个问题的影响也不大。
2.3 跨平台与可移植性
现在,现有的大部分NEON汇编代码只能运行在ARM v7-A或是ARM v8-A AArch32模式的平台上。想要运行在ARM v8-A AArch64模式的平台,我们必须重写代码,这带来了很大的工作量。这时,NEON Intrinsics代码的好处就体现出来了,在ARM v8-A AArch64模式下,我们可以直接运行这些代码,减少了重写代码的工作量。同时,我们可以只维护一套代码,这样也减少了维护的工作量。
然而,由于ARMv7-A/ARMv8-A的硬件资源不同,即使用Intrinsics,有时我们也需要两套代码。Ne10中FFT实现就是一个例子:
// radix 4 butterfly with twiddles
scratch[0].r = scratch_in[0].r;
scratch[0].i = scratch_in[0].i;
scratch[1].r = scratch_in[1].r * scratch_tw[0].r - scratch_in[1].i * scratch_tw[0].i;
scratch[1].i = scratch_in[1].i * scratch_tw[0].r + scratch_in[1].r * scratch_tw[0].i;
scratch[2].r = scratch_in[2].r * scratch_tw[1].r - scratch_in[2].i * scratch_tw[1].i;
scratch[2].i = scratch_in[2].i * scratch_tw[1].r + scratch_in[2].r * scratch_tw[1].i;
scratch[3].r = scratch_in[3].r * scratch_tw[2].r - scratch_in[3].i * scratch_tw[2].i;
scratch[3].i = scratch_in[3].i * scratch_tw[2].r + scratch_in[3].r * scratch_tw[2].i;
上述代码描述了32位浮点复数FFT算法的基本元——基4蝶形运算。从代码中我们可以看出:
• 如果在一次循环中,两个基4蝶形运算并行,需要20个 64位寄存器。
• 如果在一次循环中,四个基4蝶形运算并行,需要20个 128位寄存器。
由于ARM v7-A只有16个128位寄存器,因此,该平台的FFT实现仅能一次循环两个基4蝶形运算并行。而ARM v8-A有32个128位寄存器,该平台的FFT实现能一次循环四个基4蝶形运算并行。因此,即使用Intrinsics,我们也需要两套代码。
上例可以说明,在实现一套代码跨ARM v7-A/v8-A平台时,我们需要注意一些类似的特例。
2.4 将来
上面已经分析了NEON汇编与Intrinsics的很多问题,但是这些问题都是暂时的。长远来看,使用intrinsics还是更好。Intrinsics能带来硬件以及编译器发展的好处。经典算法只要实现一次即可,不用随着硬件的升级而重新编程,大大减少了工作量。
2.5 总结
结合实例,上文对NEON汇编和Intrinsics做了一些分析。总体来说,使用intrinsics利大于弊。特别是与汇编相比,Intrinsics更容易编程,且能够更好地兼容ARMv7-A/ARMv8-A。
下面再总结一下NEON Intrinsics使用时的一些注意事项:
• 使用的寄存器数量
• 编译器选择
• 查看反汇编
3.总结
本文通过实际程序分析了NEON汇编与Intrinsics的优缺点。希望能对用户在NEON实际开发中有些借鉴意义。
审核编辑 :李倩
-
寄存器
+关注
关注
31文章
5343浏览量
120365 -
编程
+关注
关注
88文章
3616浏览量
93734
原文标题:Arm NEON学习(三)NEON 汇编与Intrinsics编程
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论