 点云分割相较图像分割的优势是啥?
点云分割相较图像分割的优势是啥?

0. 笔者个人体会
近年来,自动驾驶领域的各项下游任务基本上都要求了对场景的语义理解,比如自动驾驶车辆要能够理解哪个是路面、哪个是交通灯、哪个是行人、哪个是树木,因此点云分割的作用就不言而喻。
但随着Transformer模型的大火,用于点云分割的深度神经网络的参数量越来越庞大,动不动就上亿参数。想要训练如此庞大的模型,除了需要足够强的GPU外,还需要大量的标签和数据。数据很容易得到,64线的激光雷达一帧可以打出十几万个点云,现有的雷达数据集也不少了。但标签呢?给点云打过label的人都知道这个过程有多繁琐(haaaaa)。
由此,点云分割模型便出现了各种各样的训练范式,主要包括有监督、弱监督、无监督以及半监督。那么哪种训练方法才是最优的?显然这个问题在不同场景下有不同的答案。本文将带领读者阅读几种主流的顶会框架,探讨不同训练方法的基本原理。当然笔者水平有限,若有理解不当的地方,欢迎大家一起探讨,共同学习!
划重点,本文提到的算法都是开源的!文末附代码链接!各位读者可在现有模型的基础上设计自己的点云分割模型。
1. 点云分割相较图像分割的优势是啥?
自动驾驶领域的下游任务,我认为主要包括目标检测、语义分割、实例分割和全景分割。其中目标检测是指在区域中提取目标的候选框并分类,语义分割是对区域中不同类别的物体进行区域性划分,实例分割是将每个类别进一步细化为单独的实例,全景分割则要求对区域中的每一个像素/点云都进行分类。
因为图像中存在大量且丰富的纹理信息,且相机相较于雷达很便宜,所以对图像进行分割非常容易。近年来也涌现了一大批图像语义分割的深度模型,比如我们所熟知的ViT、TransUNet、YOLOP等等。各自架构层出不穷,不停的在各种排行榜上提点,似乎图像语义分割已经非常完美。
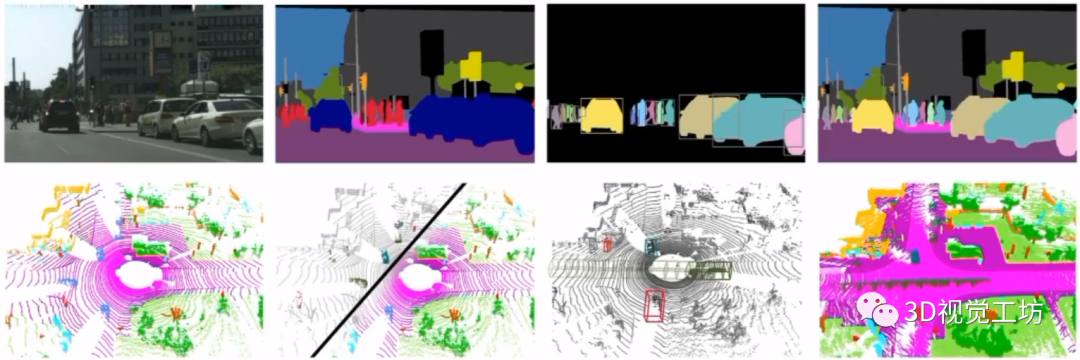
那么为啥还要对雷达点云进行分割呢?
主要有三个原因:
(1) 激光雷达可以获得绝对尺度。
我们知道单目图像是无法获得绝对尺度的,并且自动驾驶汽车在长时间运行过程中也会发生尺度漂移问题。虽然现有的一些方法在尝试从单目图像中恢复出绝对尺度,但基本上也都不太准确。这就导致了单纯从图像中提取出来的语义信息,很难直接应用于轨迹规划、避障、巡航等自动驾驶任务。
(2) 激光雷达对强/弱光线非常鲁棒
视觉语义分割非常受光照和恶劣天气影响,在过强、过弱、模糊等光线条件下,分割结果往往会出现很严重的畸变。但对于自动驾驶任务来说,恶劣天气显然是无法避免的。
(3) 激光雷达可以对环境进行3D感知
我们希望自动驾驶汽车能够对周围的整体环境进行全方位的感知,这对于激光雷达来说很容易。但对于图像来说就很难了,仅仅依靠单目图像很难恢复出完整的环境。依靠环视相机进行BEV感知的话也会带来像素畸变问题。
2. 都用啥数据集?
这里介绍几个主流的点云分割数据集,用于模型的训练和评估。
2.1 nuScenes-Lidarseg数据集
数据集链接:https://www.nuscenes.org/nuscenes#lidarseg(注意总文件有293G)
nuScenes数据集是由Motional公司在2019年3月发布的用于自动驾驶的共有大型数据集。数据集来源于波士顿和新加坡采集的1000个驾驶场景,每个场景选取了20秒长的视频,共计大约15小时的驾驶数据。场景选取时充分考虑多样化的驾驶操作、交通情况和意外情况等,例如不同地点、天气条件、车辆类型、植被、道路标和驾驶规则等。
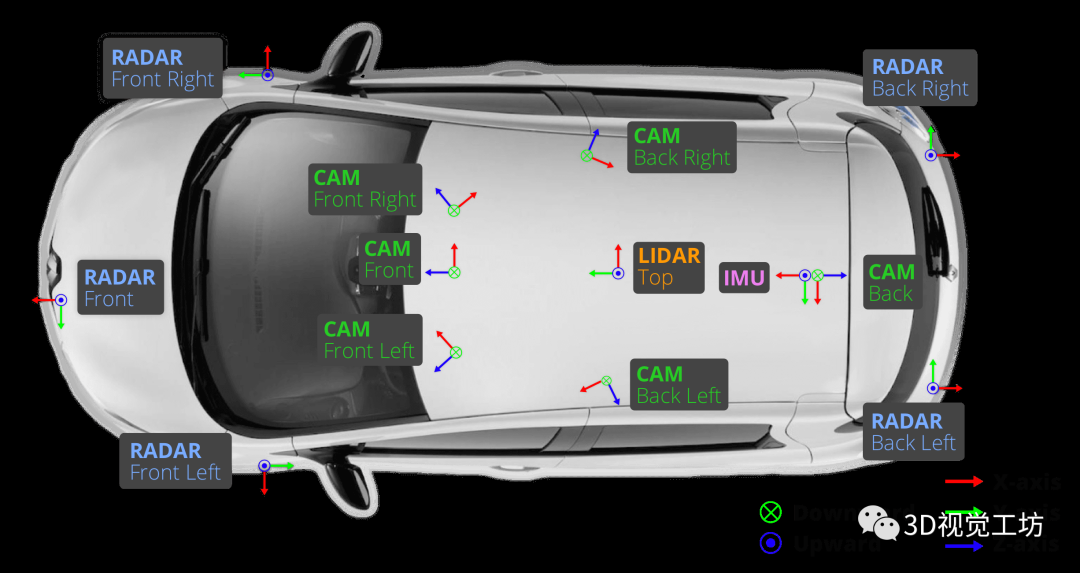
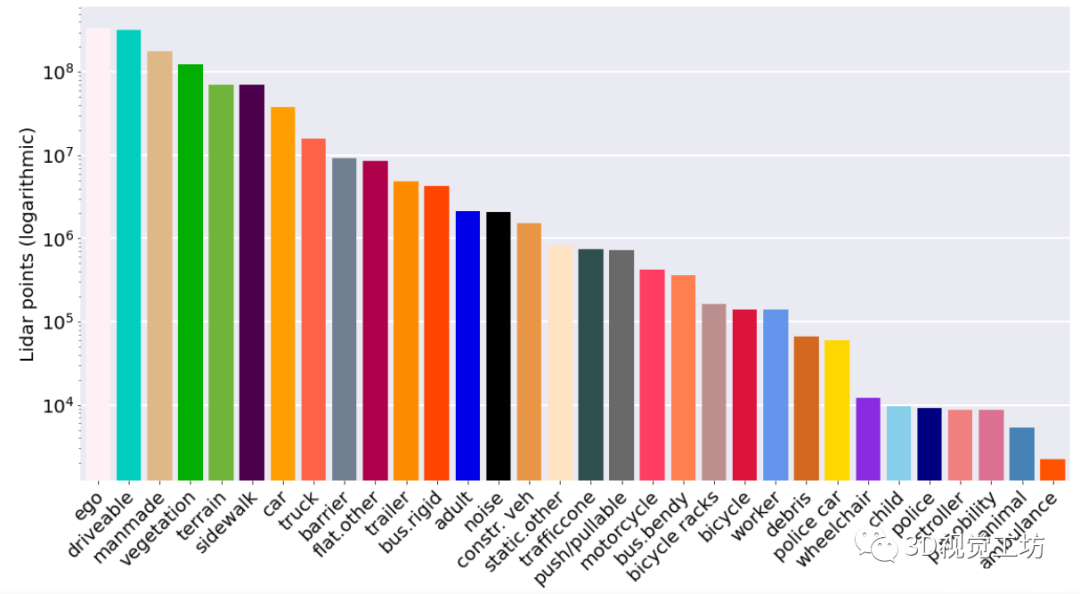
完整的nuScenes数据集包括大约140万个图像、40万个激光雷达点云、140万个雷达扫描和4万个关键帧中的140万个对象边界框。其传感器包括6个摄像头、1个32线激光雷达、5个毫米波雷达、GPS和IMU,如下图所示。2020年7月发布的nuScenes-lidarseg数据集,增加了激光雷达点云的语义分割标注,涵盖了23个前景类和9个背景类。nuScenes-lidarseg在40万个点云和1000个场景(850个用于训练和验证的场景,150个用于测试的场景)中包含14亿个注释点。
2.2 SemanticKITTI数据集
数据集地址:http://www.semantic-kitti.org/index.html
SemanticKITTI数据集是一个基于KITTI Vision Benchmark里程计数据集的大型户外点云数据集,显示了市中心的交通、住宅区,以及德国卡尔斯鲁厄周围的高速公路场景和乡村道路。原始里程计数据集由22个序列组成,作者将序列00到10拆分为训练集,将11到21拆分为测试集,并且为了与原始基准保持一致,作者对训练和测试集采用相同的划分,采用和KITTI数据集相同的标定方法,这使得该数据集和KITTI数据集等数据集可以通用。
SemanticKITTI数据集作者提供了精确的序列扫描注释,并且在点注释中显示了前所未有的细节,包含28个类。

2.3 ScribbleKITTI数据集
这个数据集很新,是CVPR2022 Oral的成果。
论文链接:https://arxiv.org/abs/2203.08537
数据集链接:http://github.com/ouenal/scribblekitti
ScribbleKITTI数据集希望通过利用弱监督(weak supervision)来实现3D语义分割方法,首次提出了使用涂鸦(scribbles)对雷达点云进行标注。但这也导致那些包含边缘信息的未标注点并未被使用,且由于缺乏大量标注点(该方法只使用8%的标注点)的数据,影响了具有长尾分布的类置信度,最终使得模型性能有所下降。
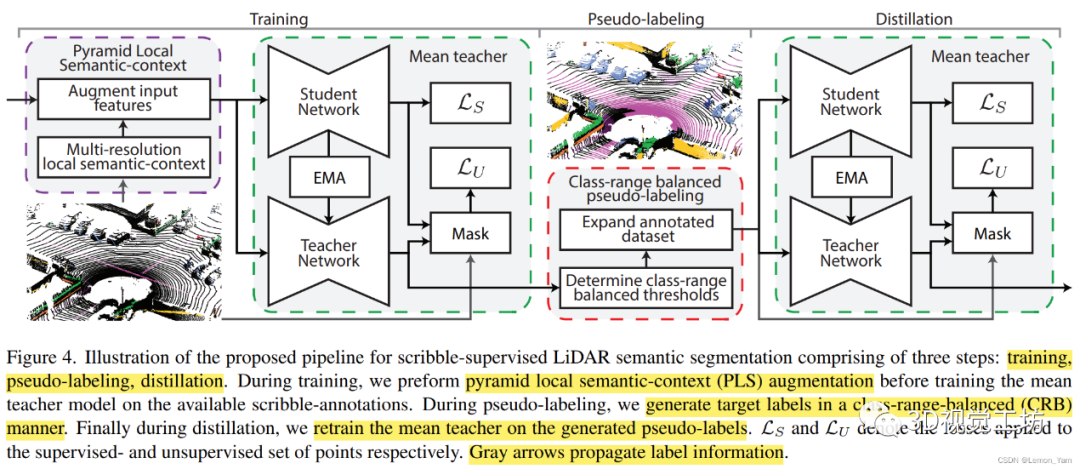
因此,ScribbleKITTI还提出了一个额外的pipeline,用以减少这种性能差距。该pipeline由三个独立的部分组成,可以与任何LiDAR语义分割模型相结合。论文代码采用Cylinder3D模型,在只使用8%标注的情况下,可达到95.7%的全监督性能。

论文提出的pipeline可分为训练、伪标签和蒸馏这三个阶段:在训练期间,首先通过PLS来对数据进行增强,再训练mean teacher,这有利于后面生成更高质量的伪标签。在伪标签阶段,通过CRB来产生目标标签,降低由于点云自身属性降低生成伪标签的质量。在蒸馏阶段,通过前面生成的伪标签再对mean teacher进行训练。
3. 雷达点云表征
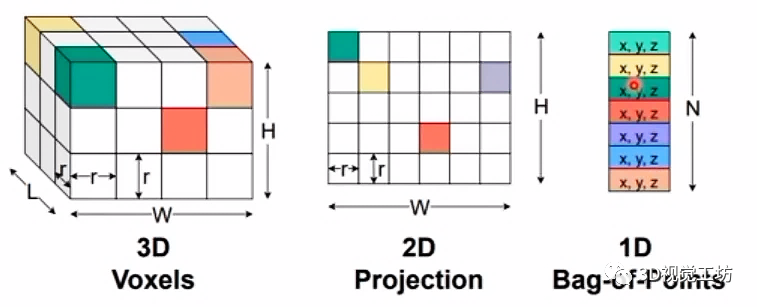
深度学习模型都需要一个规范化的数据表征,才能进行合理的特征提取和融合。对于图像来说,是一个非常规整的2D表征,即每个像素位置都是固定的,这有利于模型训练和测试。但对于3D点云来说,每帧点云有十几万个点,杂乱无章的点云必然不利于模型训练。因此需要对雷达点云进行合理表征。
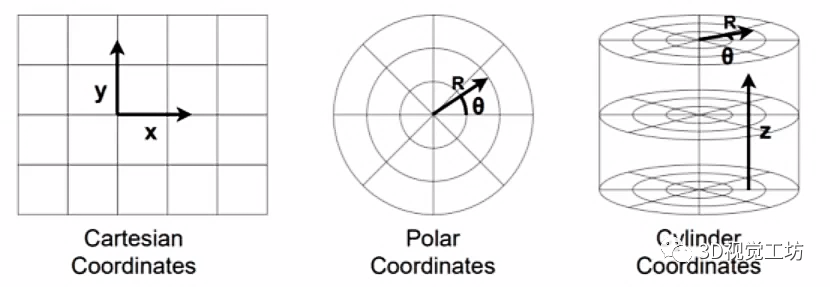
雷达点云主要的表征模式有四种:
(1) 2D Range View表征
非常接近图像,将点云投影到平面,直接进行2D表征,得到x、y坐标。有时投影过程中还会考虑点云强度、深度以及每个方格是否有点云。网络输入也就是2D Range View,首先提取特征,然后进行特征融合,最后根据不同的分割头进行语义训练。
(2) 2D BEV表征
对于很多自动驾驶场景,往往是x和y坐标范围有几十米上百米,但z方向的坐标只有几米。因此有些表征就直接省略掉z方向的表达,通过俯视图得到极坐标表征。
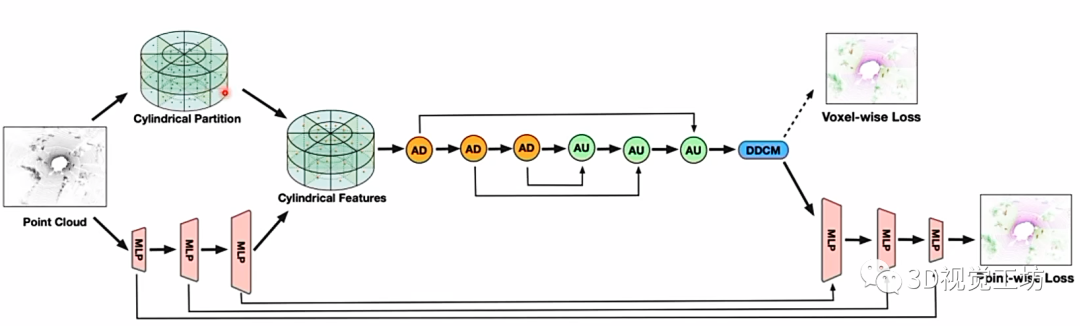
(3) 3D Cylinder Voxel表征
在点云z方向进行Cylinder的划分,是一种3D描述,典型代表就是Cylinder3D。注意为什么要用Cylinder来表征而不是其他正方体呢?这是因为点云分布的密度是不一样的,在自车周围的点云密度很大,在周围的点云密度很小。通过这种不规则的划分就更有利于特征提取。
(4) 混合表征
显然每种表征方法都有各自的特点和优劣,那么有些文章就将不同的表征模式进行混合,进而得到更强的表征。具体执行过程中会先通过不同的支路单独进行特征提取,之后进行特征融合并输出头。
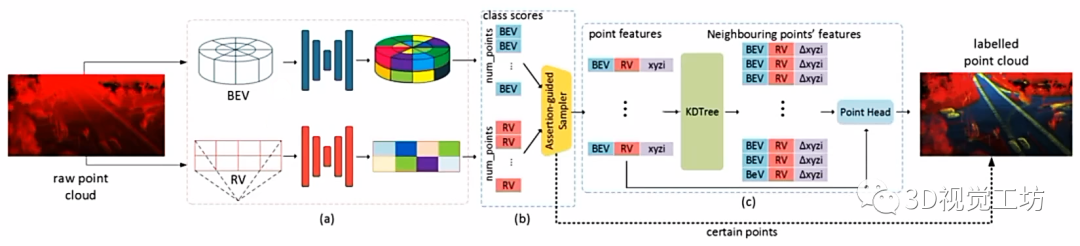
而针对不同的表征,也有不同的操作。对于3D表征来说,主要是Conv3d和SparseConv,对于2D表征来说,主要是Conv2d和线性Linear。对于直接将点作为输入的一维表征,使用Conv1d和线性Linear。
4. 全监督算法
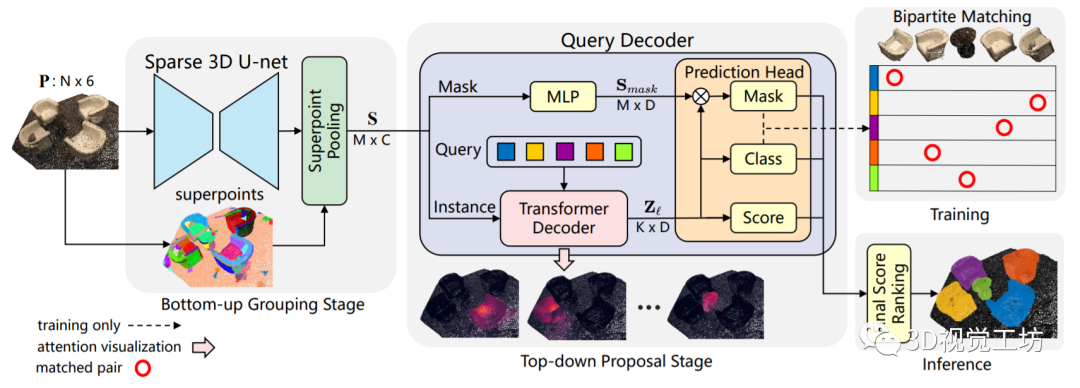
华南理工大学今年11月在arXiv上传了论文“Superpoint Transformer for 3D Scene Instance Segmentation”,基于Transformer构建了一个新的点云分割框架,名为SPFormer。具体来说,作者提出一种基于Superpoint Transformer的新型端到端三维实例分割方法,它将点云中的隐特征分组为超点,并通过查询向量直接预测实例,而不依赖目标检测或语义分割的结果。
SPFormer其实针对的不是自动驾驶场景,它主要是在ScanNet和S3DIS这两个室内数据集上进行训练和评估。感觉最近很少有自动驾驶场景的全监督算法了,主要还是因为对数据量和标注要求太大。
这个框架的关键步骤是一个带有Transformer的新型查询解码器,它可以通过超点交叉关注机制捕捉实例信息并生成实例的超点掩码。通过基于超点掩码的双点匹配,SPFormer可以实现网络训练,而不需要中间的聚合步骤,这就加速了网络的发展。
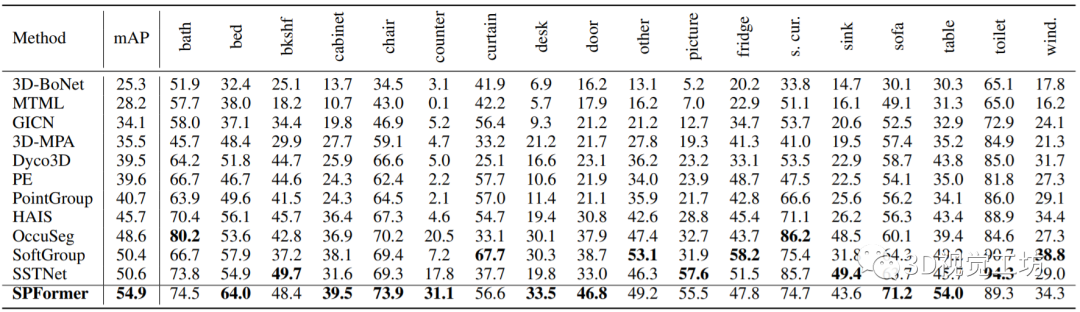
SPFormer的结果也很漂亮,在ScanNetv2 hidden上的mAP达到了54.9%,比之前最好的结果高出4.3%。对于具体的18个类别,SPFormer在其中的8个类别上取得了最高的AP得分。特别是在counter类别中,SPFormer超过了之前最好的AP分数10%以上。
总结一下,全监督算法的精度应该是最高的,因为接受了完全的标签训练,但是对数据量和标注的要求越来越大。
5. 弱监督算法
感觉ScribbleKITTI中提出的弱监督Pipeline非常妙了,可以与任何LiDAR语义分割模型相结合,这里再回顾一下。
这里再介绍一个基于雷达引导的图像弱监督分割算法,感觉很有意思:
是由北京理工大学和上海AI Lab联合提出的LWSIS,今年12月7日上传到arXiv,录用到了2023 AAAI,可以说非常新!论文题目是“LWSIS: LiDAR-guidedWeakly Supervised Instance Segmentation for Autonomous Driving”。
LWSIS利用现有的点云和3D框,作为训练2D图像实例分割模型的自然弱监督。LWSIS不仅在训练过程中利用了多模态数据中的互补信息,而且显著降低了稠密二维掩膜的标注成本。具体来说,LWSIS包括两个关键模块:点标签分配(PLA)和基于图的一致性正则化(GCR)。前者旨在将三维点云自动分配为二维逐点标签,而后者通过增强多模态数据的几何和外观一致性来进一步优化预测。此外,作者对nuScenes进行了二次实例分割标注,命名为nuInsSeg,以鼓励多模态感知任务的进一步研究。
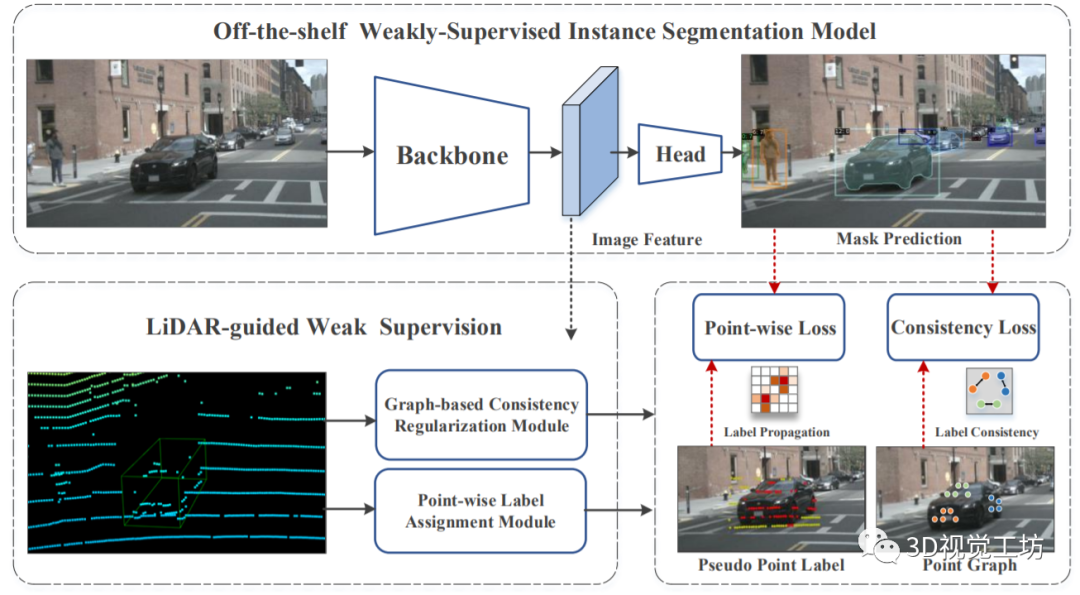
在nuInsSeg和大规模Waymo上的大量实验表明,LWSIS在训练过程中只涉及三维数据,可以显著改进现有的弱监督分割模型。此外,LWSIS还可以与Point Painting等3D目标检测器结合,提升3D检测性能。

总结一下,感觉弱监督算法是现在的一个主流发展趋势。也就是说,放弃标注复杂的目标,转而去用一些容易得到的表情来引导训练。感觉这种思想非常巧妙!当然用来引导的标签不一定要是涂鸦或者点云,也可以是其他形式,读者可以由此设计自己的弱监督分割网络。
6. 无监督算法
点云分割算法是否可以完全不依赖标签?
这似乎是个很难回答的问题,没有标签,也就完全无法知道物体的类别先验,就更加无法进行训练。
但香港理工大学的2022 NeurIPS论文“OGC: Unsupervised 3D Object Segmentation from Rigid Dynamics of Point Clouds”似乎回答了这个问题。作者的思路也很巧妙:一辆汽车上的所有点一起向前运动,而场景中其他的点则保持静止。那么理论上,我们可以基于每个点的运动,将场景中属于汽车的点和其他点分割开,实现右图中的效果。
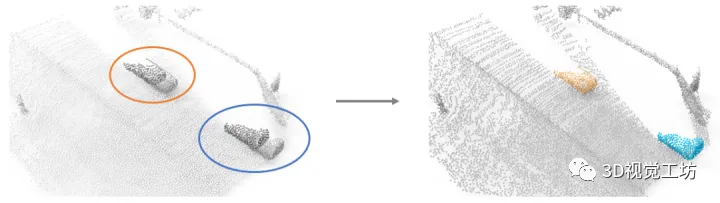
OGC是一种通用的、能分割多个物体的无监督3D物体分割方法,这种方法在完全无标注的点云序列上进行训练,从运动信息中学习3D物体分割。经过训练后,能够直接在单帧点云上进行物体分割。OGC框架的核心是:以物体在运动中保持几何形状一致作为约束条件,设计一组损失函数,能够有效地利用运动信息为物体分割提供监督信号。
OGC以单点云作为输入,并直接在一次向前传递中估计多个对象遮罩。OGC利用连续点云的潜在动态作为监督信号。具体架构由三个主要组件组成: (1)目标分割网络提取每一点的特征,并从单一点云估计所有对象掩模如橙色块所示;(2)辅助自监督网络来估计来自一对点云的每点运动矢量;3)一系列损失函数充分利用运动动态来监控目标分割骨干。对于前两个组件,实际上可以灵活地采用现有的提取器和自监督运动估计器。


总结一下,无监督算法现在应该还比较少。OGC是利用了运动约束,可以很巧妙得训练点云分割网络。但是静止的物体呢?比如树木、交通灯、建筑。未来应该还会有很多大神提出更多巧妙的思路,让我们拭目以待。
7. 半监督算法
全监督和弱监督都要求对每帧点云都进行标注,只是弱监督标注的少,无监督不需要标注。那么半监督呢?这里半监督指的是,一部分的点云需要进行标注,另外一部分不需要任何标注。即,在充分利用到现有的已标注数据的基础上,结合便于收集的大量无标注数据,训练泛化能力优异的模型。
本文介绍的算法是新加坡国立大学今年6月提出的LaserMix for Semi-Supervised LiDAR Semantic Segmentation。
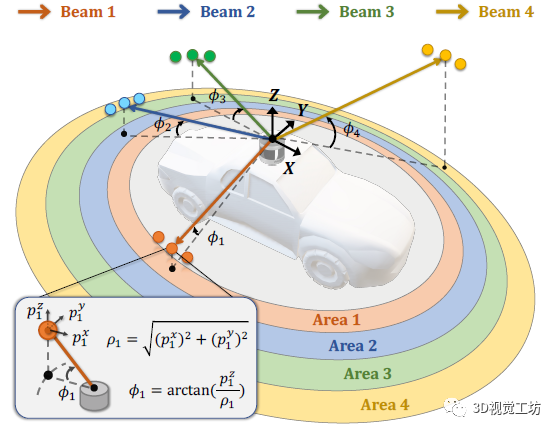
这项工作的思路非常巧妙!作者发现,无论是静态背景还是动态前景对象,都在LiDAR点云场景中表现出很强的结构先验,而这种先验可以很好地由LiDAR的激光束所表征。以最常见的旋转型LiDAR传感器为例,其以自车为中心向周围各向同性地发射具有固定倾角的激光射线,由于不同类别本身具有特殊的分布,由激光射线探测并返回的点便能够较为精准地捕捉到这些不同类别所蕴藏的结构化信息。
例如,road类在靠近自车周围的区域中大量分布,主要由位于下部的射线所收集;vegetation类分布在远离自车的区域,主要由位于上部的具有较大正向倾角(inclination)的射线所收集;而car类主要分布在LiDAR点云场景的中部区域,主要由中间的射线所收集。
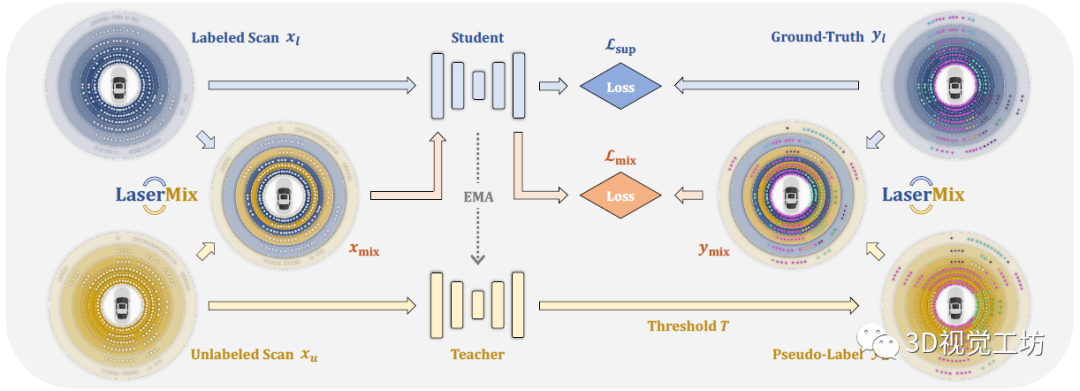
LaserMix管道有两个分支,一个有标注的学生分支和没有标注的教师分支。在训练过程中,一个batch由一半有标签数据和一半无标签数据组成。LaserMix收集来自学生和教师的预测,并使用预定义的置信度阈值从教师网络的预测中生成伪标签。对于有标记数据,LaserMix计算学生网络的预测和真实值之间的交叉熵损失。对于无标签数据,LaserMix将每次扫描与随机标记扫描混合在一起,加上伪标记或真值。然后,令学生对混合数据进行预测,计算交叉熵损失。
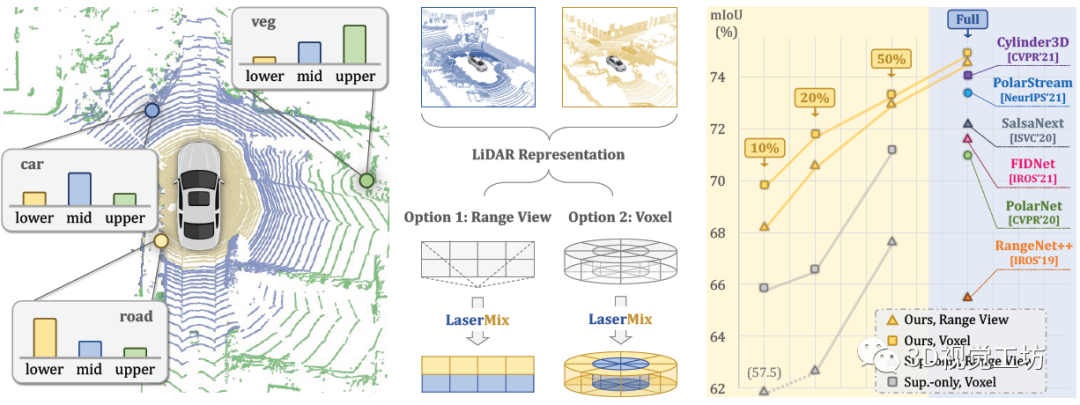
LaserMix在Range View和Voxel这两种点云表征上都进行了验证,体现出该方法的普适性和适配性。此外,作者将nuScenes、SemanticKITTI、ScribbleKITTI三个数据集按照1%,10%,20%和50%的有标注数据比例进行了划分,并认为其余数据均为未标注数据。结果显示,LaserMix极大地提升了半监督条件下的LiDAR分割结果。无论是在不同的数据集还是不同的LiDAR点云表征下,LaserMix的分割结果都明显地超过了Sup.-only和SOTA的半监督学习方法。其中Sup.-only代表仅使用有标注数据进行训练后的结果,可以理解为该任务的下界(lower bound)。
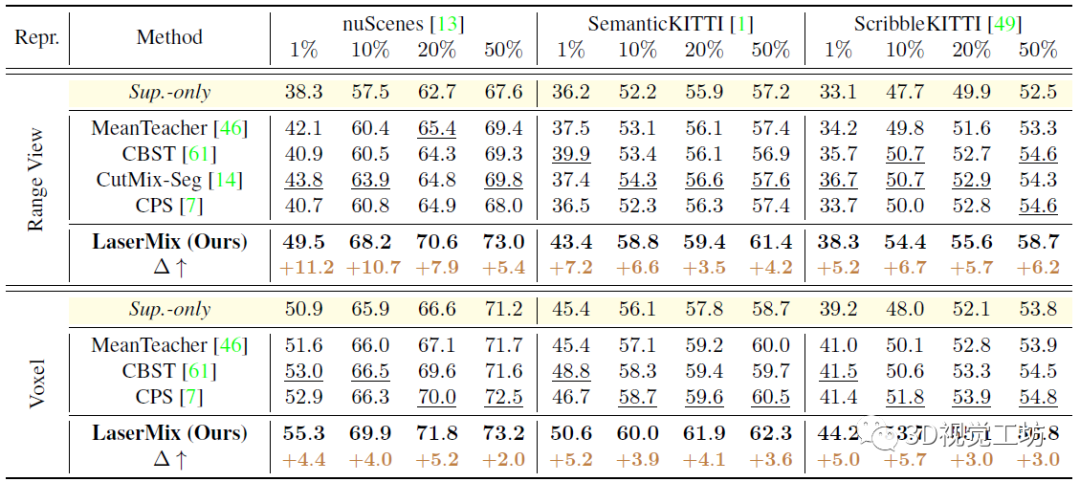
总结一下,半监督算法其实同时结合了弱监督和监督的优点。弱监督虽然标注的简单了,但本质上还是需要对每帧数据都进行标注,这个工程量也非常大。但是半监督居然可以在仅有1%标签数据的情况下进行训练,训练效果还超过了很多同类型的算法,所以我感觉半监督在未来也会成为主流发展趋势,
8. 结论
本文首先介绍了点云分割相较于图像分割的优势,然后阐述了一些点云分割必备的基础知识,最后分别探讨了全监督、弱监督、无监督、半监督点云分割算法的网络架构和基本原理。其中,全监督算法精度最高,但要求的数据量和标签也很大。无监督往往是依靠环境中的某种特殊假设进行训练,在特殊场景下会非常高效。弱监督和半监督在很少的数据标注条件下,达到了和全监督几乎相当的精度。笔者认为,在未来,弱监督和半监督是点云分割领域的重要发展趋势。
审核编辑 :李倩
-
图像
+关注
关注
2文章
1097浏览量
42473 -
数据集
+关注
关注
4文章
1242浏览量
26284 -
点云
+关注
关注
0文章
59浏览量
4099
原文标题:点云分割训练哪家强?监督,弱监督,无监督还是半监督?
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于 MOS 管的步进驱动板 PCB 阻抗匹配与地平面分割
全面掌握ComfyUI系统教程|94节从入门到进阶实战清单
SAM(通用图像分割基础模型)丨基于BM1684X模型部署指南
【NPU实战】在迅为RK3588上玩转YOLOv8:目标检测与语义分割一站式部署指南

自动驾驶模型是如何“看”懂点云信息的?
传音TEX AI团队斩获ICCV 2025大型视频目标分割挑战赛双料亚军
手机板 layout 走线跨分割问题
基于黄金分割搜索法的IPMSM最大转矩电流比控制
北京迅为itop-3588开发板NPU例程测试deeplabv3 语义分割

三维扫描效率革命:自由维度(手持 / 机械臂)相较固定式方案的 N 倍产能提升


如何将32个步进伺服驱动器塞进小型板材分割机中?

【正点原子STM32MP257开发板试用】基于 DeepLab 模型的图像分割
凡亿Allegro Skill布线功能-检查跨分割



评论