 复旦&微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型
复旦&微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型
引言
基础模型 (Foundation model) 指的是在大量数据上训练出来的、可以适应一系列下游任务的模型[1],它被看作是迈向通用人工智能的重要一步。近些年来,随着CLIP的横空出世,视觉-文本预训练 (Vision-Language Pretraining) 及其在各类任务的迁移学习成为了备受关注的研究方向,并被认为是建立视觉基础模型的一个颇具前景的方向。
根据输入数据和目标下游任务的不同,现有的VLP方法可以大致分为两类:图像-文本预训练和视频-文本预训练。前者从图像-文本对中学习视觉和语言表征的联合分布,后者则从视频-文本对中建立视频帧和文本之间的语义关联。然而,当前尚无工作探索将二者统一起来,这篇文章认为这主要因为现有的训练方式无法发挥图像-文本预训练和视频-文本预训练之间的互补性,但单纯地实现统一而在两类下游任务上折损性能将是没有意义的。尽管困难重重,对于基础模型的追求使得这一问题依旧难以回避。
这促使这篇工作思考并最终提出了一个真正统一的视觉-语言基础模型OmniVL以同时支持图像-文本和视频-文本的预训练以及相应的下游任务,包括视觉任务(如图像分类、视频动作识别)、跨模态对齐任务(如图像/视频-文本检索)以及多模态理解和生成任务(如图像/视频问答、字幕自动生成等)。OmniVL第一次探索出了图像和视频任务双向互助的训练范式,而不是以往的单一方向,即用图像(图像-语言)来帮助视频(视频-语言)。
方法
OmniVL实现了模态、功能和训练数据三个维度的统一,本篇对方法的介绍也将围绕着三个统一进行展开。
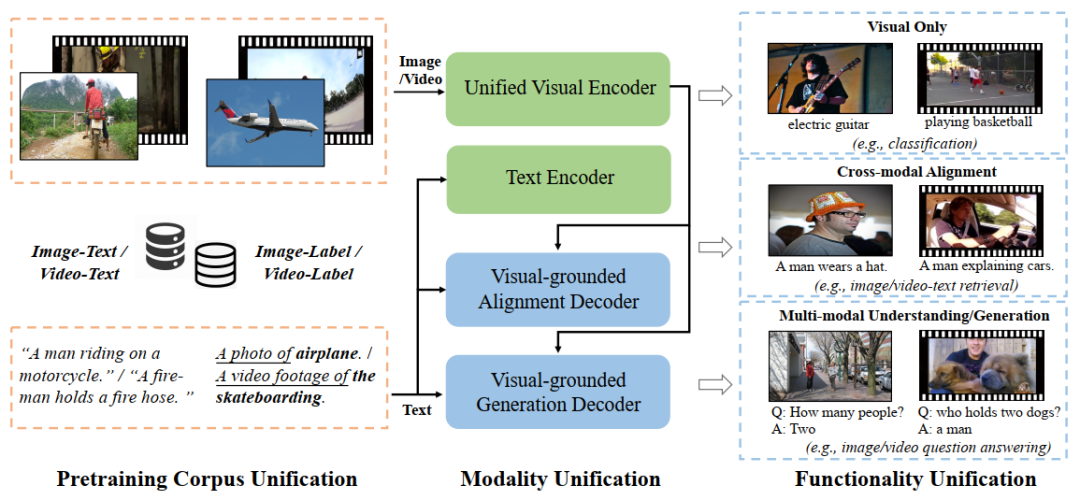
统一的模态.OmniVL采用了一个统一的基于Transformer的视觉编码器来提取视觉表征,其中视频与图像输入共享大部分网络结构,对于视频而言,OmniVL采用了3D patching embedding和时间注意力块[4]。此外,OmniVL额外利用一个文本编码器来提取语言表征。
统一的功能.OmniVL采用了编码器-解码器的结构,并具有两个视觉引导的解码器:跨模态对齐解码器和文本生成解码器,前者通过视觉-文本匹配(的二分类)损失进行监督以学习视觉和文本模态之间的对齐,后者则通过语言建模(的生成式回归)损失进行监督以学习从视觉特征中生成文本的能力。这两个解码器与上述的两个编码器相互配合,赋予了OmniVL“理解“和“生成”的能力。
统一的数据.受到Florence[5]中使用的统一对比学习[6]的启发,OmniVL统一了图像-文本和图像-标签数据作为预训练语料库、并将其进一步扩展到视频-文本和视频-标签数据上。这基于两个方面的考虑:1)利用尽可能多的有监督(或无监督)的数据来丰富语料库;2)人工标注的视觉-标签数据(如ImageNet和Kinetics-400)可以帮助模型学习出更具辨别性的表征,这有助于分类相关的迁移学习任务,而从网络爬取的视觉-语言数据 (如CC12M和WebVid) 涵盖更广泛的视觉概念,这有助于跨模态任务。这种简单的扩展可以帮助OmniVL同时享有两种优势。
最后回到了上面提到的最重要的问题:如何实现图像-文本和视频-文本学习的相互促进。前文提到,现有工作往往只是单独利用图像-文本或者视频-文本进行预训练(如下图2-3行),因此在另一类任务上的表现往往差强人意(多数情况被直接忽略)。尤其是如果只在视频-文本上预训练的话,受限于有限的数据规模、以及视频数据本身的复杂性,在对应的视频任务上表现也很糟糕。为了解决这一问题,一些工作如FiT[7]提出了将图像看作单帧视频、从而利用其和视频数据进行联合训练(如下图第4行),这一做法相较单纯地利用视频数据有显著提升,但是直接从零学习图像和视频的表征以及跨模态的对齐显然颇具挑战性,这为网络的学习和收敛增加了困难。Pretrain-then-finetuning是视觉领域一个常用的做法,它指的是首先在标准的图像数据集上训练骨干网络如ResNet,然后将其在下游任务包括视频动作识别上进行微调,这一方法在各类任务上都取得了显著的成功。借鉴于此,一种简单的做法是首先在图像-文本上进行第一阶段的预训练、然后在视频-文本上进行第二阶段的预训练(如下图第5行)。这一做法是很有竞争力的一个baseline,但是在一方面在图像任务上的性能有所下降、另一方面在视频任务上的表现还不够惊艳。
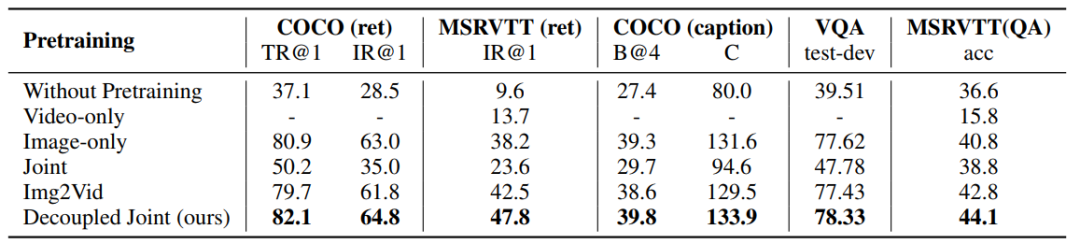
为了更加充分地利用图像-文本和视频-文本数据的互补性、进一步提升在不同下游任务上的表现,OmniVL提出了一个解藕的联合训练方式,即首先在图像-文本上进行预训练、然后结合视频-文本进行联合预训练(如上图第6行),这不仅可以防止对图像表征的遗忘、甚至可以在二者对应的任务上继续提高性能。这篇工作认为这是由于第一阶段网络可以专注在学习空间表征和其与文本模态的对齐上、第二阶段则可以增益性地学习运动表征和跨模态的关系建模,这不仅使学习从空间维度到时间维度更加高效,而且还能使不同源的数据之间形成互补。
实验
视觉任务
文章首先采用经典的图像分类 (linear probing) 和视频动作识别任务 (finetuning) 作为基准评估了视觉编码器在视觉任务上的表现。
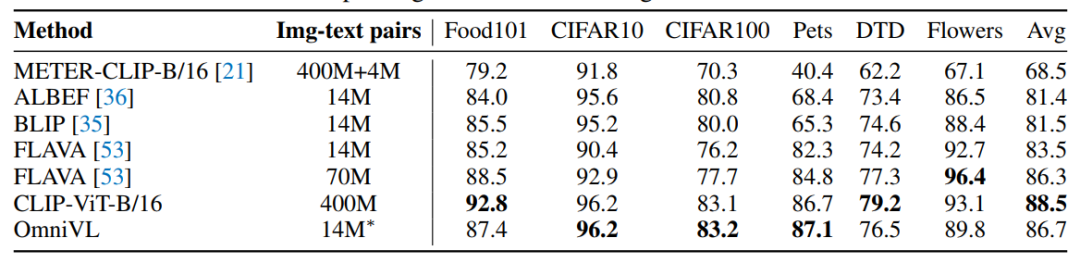

遵从CLIP的实现,OmniVL冻结了视觉编码器的参数并对新附加的线性层进行微调。在6个图像分类数据集上,OmniVL相比于大多数baseline取得了一致更好的结果。与CLIP和FLAVA (70M) 相比,虽然使用明显更少预训练数据,OmniVL仍然取得了总体上有竞争力的结果。
对于视频动作识别,文章在两个规模较小的数据集UCF101和HMDB51上评估了linear probing的结果,并在两个规模较大的数据集Kinetics-400和Something-something V2上评估了微调的结果,实验表明OmniVL都显著地超越了baseline。
跨模态对齐任务
接下来文章探究了OmniVL在图像-文本检索和文本到视频检索任务上的表现。值得一提的是,为了平衡推理效率和多模态信息的深度融合,OmniVL首先根据单模态编码器得到视觉和文本embedding的相似度得分选择Top-K(默认为K=128)候选者,然后利用跨模态对齐解码器计算其成对的匹配得分对候选者重新排序,这种双阶段匹配的方式进一步体现了该架构的优越性。
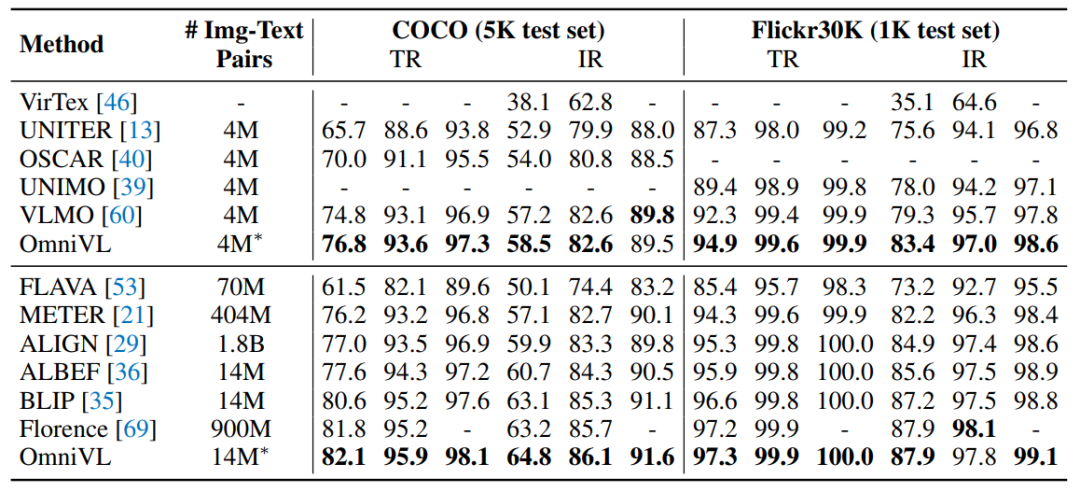
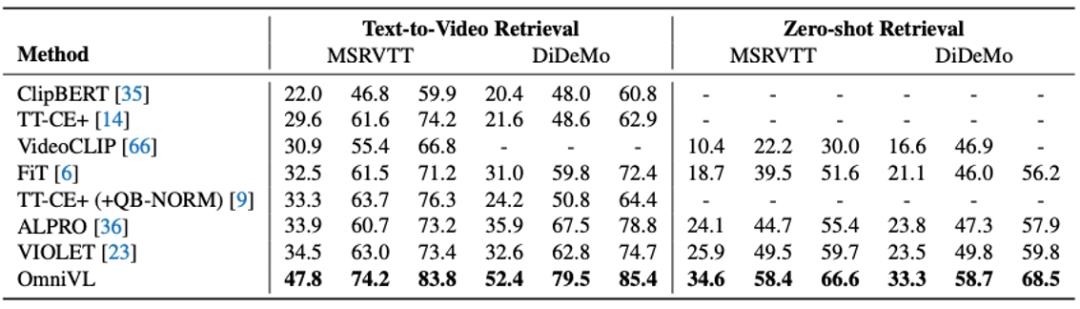
从上图可以看出,无论是在图像-文本检索还是文本到视频检索上,OmniVL都在不同数据集上取得了目前最佳的性能。尤其是在文本到视频检索任务上,得益于所提出的解藕联合预训练方法,OmniVL显著地超越了现有方法。
多模态理解和生成任务
以视觉为基础的跨模态对齐解码器和文本生成解码器使OmniVL具备了多模态理解和生成的能力,在这一部分中,文章评估了它在字幕生成和图像/视频问题回答上的表现。
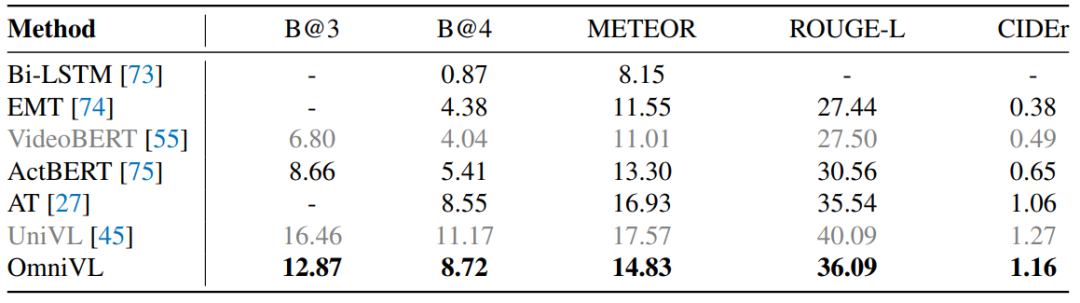

在这类任务上,OmniVL同样取得了最好的结果。
总结和未来工作
这篇工作提出了OmniVL,一个全新的视觉-语言基础模型,它将图像-语言和视频-语言统一起来,并同时支持视觉任务、跨模态对齐任务以及多模态的理解和生成任务。OmniVL采用了统一的视觉-语言对比损失,这让其能够同时利用图像-文本、图像-标签、视频-文本和视频-标签数据进行预训练。另外,文章中提出了一个解耦地联合训练范式,将视觉-语言建模解耦为空间和时间两个维度,从而同时提高了在图像和视频任务的性能。
在这篇工作仅仅在CC12M和WebVid-2.5M这类相对小规模的数据上进行预训练,随着LAION、WebVid-10M的问世,可以在更大规模的数据上训练更大的模型,以探索具有更强零样本、小样本能力的模型。另外一个值得探索的方向是结合更丰富的有标签数据和更优的监督目标,使得模型可以支持细粒度的任务如物体检测、追踪等,从而朝着通用的统一模型更上一层台阶。
审核编辑 :李倩
-
图像
+关注
关注
2文章
1084浏览量
40461 -
图像分类
+关注
关注
0文章
90浏览量
11917
原文标题:NeurIPS 2022 | 复旦&微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KerasHub统一、全面的预训练模型库
北美运营商AT&T认证中的VoLTE测试项


AI大模型的训练数据来源分析
直播预约 |数据智能系列讲座第4期:预训练的基础模型下的持续学习

onsemi LV/MV MOSFET 产品介绍 &amp;amp; 行业应用






 工商网监
工商网监
评论