 云计算数据压缩方案
云计算数据压缩方案

文章转发自51CTO【ELT.ZIP】OpenHarmony啃论文俱乐部——《云计算数据压缩方案》
1.技术DNA
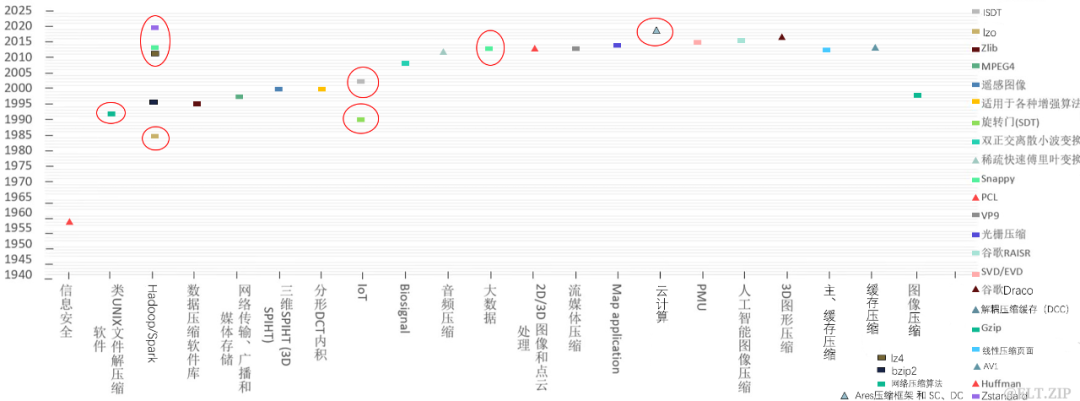
2. 智慧场景
3.前言概览
近年来,相机、卫星、地震监测等传感设备产生了大量的流数据。云计算技术使这些流数据的存储、访问和管理变得更加容易,也降低了成本。其中,云存储系统成为在各种云服务器上存储数据块的一种有前途的技术,其主要机制之一是数据复制。数据复制的目标是解决云存储的可用性、可靠性、安全性、带宽和数据访问的响应时间,从而使数据密集型项目能够实现更优越的性能。然而,既然复制,就免不了会产生过多的重复副本造成资源浪费。因此,便产生了一种通过移除重复副本来减小云存储系统中数据占用的大小,实现数据压缩、避免资源浪费的重复数据删除技术。
以一种典型的传统分类方式来看,可以将此重复数据删除技术分为delta-based和hash-based两类。本着相同的目标,前者基于相似性的消除,后者基于加密函数而发挥作用。
而在另一种分类方式中,可以将此重复数据删除技术分为基于服务器和基于客户端两类。前者中,消除冗余数据的操作是在服务器接收到数据后完成的,而后者则在发送数据之前就先在客户端检查数据的重复性。
后文将对以上内容一一解析,不过开始之前,我们还是先了解一些云计算的周边内容。
4.云计算
4.1 云计算产生背景
云存储数字数据量的不断增加 ,需要更多的存储空间,高效的技术 ,处理这些数据。
那么何为云计算?是如上图一般把网线接到云彩上进行计算吗?当然不是,这是一种形象的比喻,云计算提供了一种新的互联网技术方式,利用互联网和中央远程服务器管理资源和应用程序。许多最终用户以最低的成本使用这一创新,并且无需安装就可以访问应用程序。
4.2 公有云和私有云
云计算可以是公共云或是私有云。公共云平台(例如AWS和Microsoft Azure)将资源集中在分布在全球各地的数据中心,用户可以通过公共互联网访问它们。这些资源通过计量服务提供给客户,云计算供应商负责不同程度的后端维护。
私有云被托管在企业数据中心或托管数据中心设施中。虽然其功能不如大规模的公共云。但它们确实有一定的弹性,企业的开发人员和管理人员仍然可以使用自助服务门户访问资源。从理论上来说,私有云提供了更好的控制和安全性,但这需要企业的IT团队的努力。
云计算部署模型包括私有云、公共云、两者的混合,以及多个云平台的组合。也可以将公共云和私有云链接以创建混合云,或者可以将两个或多个公共云连接以创建多云架构。
4.3 云计算主要优点
4.4云计算存在问题
云服务中最重要、最典型的是信息存储服务。数据的安全性、个人数据的隐私性保护、数据访问的权限管理、数据的容灾备份、数据拜访的实时性会受网络稳定性影响。以及如何降低冗余数据、减少存储成本。
4.5常见的云存储供应商
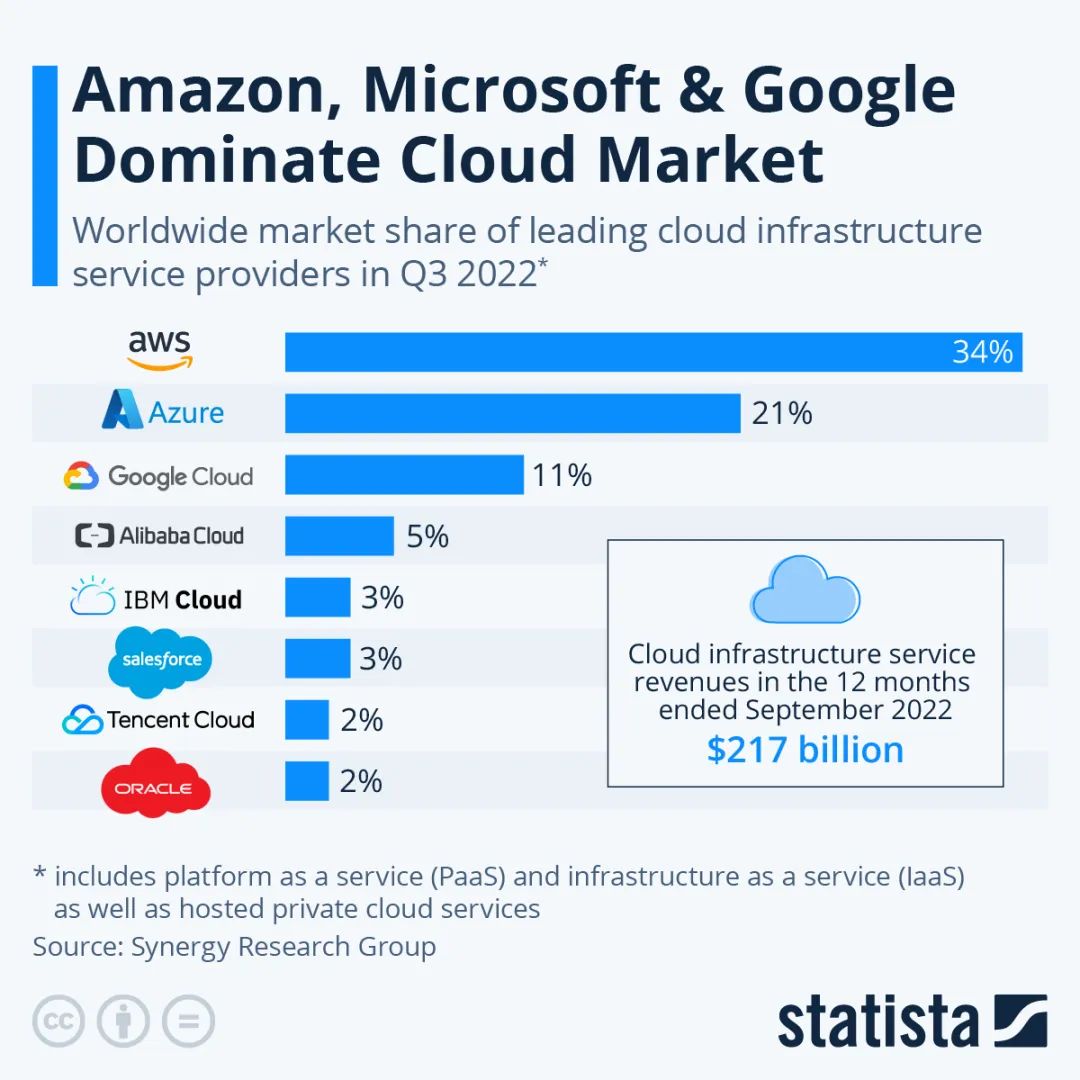
亚马逊、微软、谷歌和阿里巴巴四大云服务厂商,占据了全球七成以上市场份额。紧随四大市场领导者后面的有IBM、Salesforce、腾讯、Oracle和一大批市场份额较小的公司。而亚马逊在全球公有云服务市场中的领导地位主要是由于其市场份额第一缘故。
4.6云计算与大数据
云计算和大数据是近六七年来大热的两个概念,很多时候,二者都是被绑定在一起谈论的。
大数据就是通过搜集海量的数据对其进行分析和处理,发现隐藏在这些数据背后的潜在联系,洞察内在过程,进而使这些数据转化或推导出具有更多价值的信息,最终为用户的决策提供帮助。放到日常工作生活中的典型表现就是“喜欢看什么,就会推什么”:当我们刷一些娱乐类或者新闻类的app时,看到感兴趣的内容就免不了会驻足多停留一段时间,可能还会直接去搜相关的话题,这时大数据就已经完成了标记、为你的ID打上了相应的标签。基于内容相关性的频次或后台的定位信息等,标签也会不尽相同。尽管觉得自己净如白纸,但在平台的全闭环下,大数据总是能精确地捕捉并震撼到我们。
4.7云计算的技术
云计算本质上是分布式计算的一种,通过对任务的分发,实现多端并行计算,最终再进行计算结果的合并。它提供了计算资源的虚拟化池,存储、应用、内存、处理能力和服务都是在用户需要时可以用来请求这些资源的实例。其中,云服务通常分为平台即服务(PaaS)、软件即服务(SaaS)和基础设施即服务(IaaS)三种模式,三者的主要区别就是提供服务的方式不同,需要用户根据实际需要进行选择匹配。此外,基于云计算的思路,还衍生出了雾计算、边缘计算、移动边缘计算(MEC)和移动云计算(MCC)。
5.云存储
云存储是一种有用的移动边缘计算(M E C)设备,其特点是存储空间有限。这些数据或日志数据可以在需要时被存储和访问到云存储服务中。为了提高M E C设备上的云存储服务体验,可以将多个云存储服务合并成一个统一的云存储在云存储中,在处理大量数据时,无法避免重复。尽管云存储空间巨大,这种复制极大地浪费了网络资源,消耗了大量电能,并使数据管理变得复杂。重复数据删除可以节省大量空间和成本,备份应用可以减少高达 90-95%的存储需求,标准文件系统可以减少高达 68%的存储需求。数据重复删除和数据压缩是在云中优化存储的可用技术中使用的最突出的技术。
5.1 重复数据删除技术
随机复制作为一种流行的复制方案,已广泛用于云存储系统,如Hadoop分布式文件系统(HDFS)、RAMCloud、Google文件系统(GFS)和微软Azure等,使用随机复制从不同机房随机选择的三台服务器中复制数据,从而防止单个集群中的数据丢失。然而,三方随机复制不能很好地应对机器故障,若三个节点的随机组合同时出现错误,就会造成数据丢失。
为了解决以上问题,便提出了Copyset复制和分层复制两种方案。但又出现了新的问题:它们都没有试图降低由于复制而造成的存储成本和带宽成本。尽管后续又提出了更多相关的复制方案,但仍然存在着同样的问题。
于是,有学者设计了一种叫做流行感知的多故障弹性和经济有效的复制方案(PMCR)的方案。它比之前的复制方案都有优势,且同时具有以下特点:
-
可以处理相关或不相关的机器故障
-
压缩那些很少使用的冷门数据的副本
-
降低了存储和带宽成本
-
不会显著影响数据持久性、数据可用性和数据请求的延迟
5.1.1 SC、DC压缩
由于PMCR方案的操作是一整套流程,我们在此只关注其中压缩数据降低冗余度的部分。
SC全称Similarity Compression,是依据数据相似性压缩的一种方法;DC全称Delta Compression,意即增量压缩。PMCR使用SC压缩读密集型数据,使用DC压缩写密集型数据。SC删除文件或文件中相似的块,文件请求用户在接收到压缩文件后,可再恢复已删除的数据块;DC存储文件的副本和与此文件相似的其他文件的不同部分,以上将会被传输给文件请求用户。而当文件更新时,只需将更新后的部分同步到副本节点即可。
5.1.1.1相似性压缩(SC)
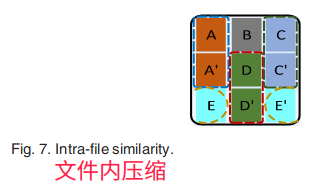
进行SC时,相似的块被分组在一起,一定数量相似的小块形成一个大块。然后,删除重复的块或接近重复的块到一个块。在PMCR中,当压缩读密集型数据时,对于每一组相似的块,只需存储第一个块即可,剩下的冗余块可删除;对于不同数据对象之间的冗余块,也可消除,方式大体分为文件内压缩和文件间压缩:
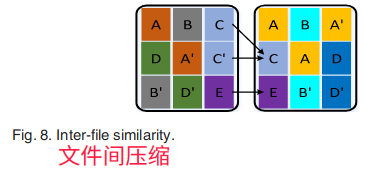
5.1.1.2增量压缩(DC)
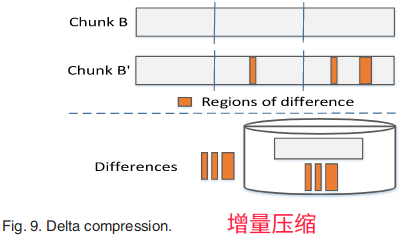
如图,B块和B’块都是相似的块,它们之间的差异用橙色标记出,此时,便可用DC存储橙色区域。当块B或块B’被更新时,只需将更新的部分而非整个块发送到复制服务器即可,然后,副本服务器再更新相应的部分。要将数据发送给用户,只需传输存储的不同部分和B块的完整部分。
5.1.2DSHA算法
现有系统使用(任何类型的)加密散列算法(如 MD5 或 Secure 散列算法),生成散列值,重复数据删除这些算法产生固定长度的 128 位或 160 位分别作为输出以识别复制的存在。同时用一个额外的内存空间存储哈希值。
本文提出了一种高效的分布式存储哈希算法(Distributed Storage Hash Algorithm, DSHA),以减少用于识别和丢弃冗余数据的哈希值所占用的内存空间。
结论:实验分析表明,该策略降低了哈希值的内存利用率,提高了数据读写性能。
5.2SDM技术
SDM是一种针对移动设备的智能重复数据删除系统,提高了云存储作为移动设备上的存储解决方案的可行性。SDM旨在利用多核技术 在现代移动处理器上的架构。为了减少重复数据删除过程的时间,针对每种文件类型的最佳重复数据删除方法,而不依赖于针对每种文件类型的任何配置。由于其设计,学习系统不存在散列不兼容性。
5.2.1移动设备和云存储服务的固有限制
-
移动设备的性能限制 移动设备的处理功率和电源受到限制。
-
有限的存储容量 由于其外形因素,也很难在移动设备中安装高容量的存储空间。云存储供应商提供的免费存储容量 往往很小,升级需支付额外费用。
-
网络带宽 网络带宽对于访问云存储至关重要。遗憾的是,网络带宽通常被限制在免费存储上,云存储服务的带宽是在活动用户的数量之间划分的,会导致更长的访问时间,在大多数在某些情况下,这将导致云存储服务的性能低于客户的网络性能。
-
价格昂贵的无线网络收费
-
有限网络覆盖范围 网络覆盖对移动用户来说可能是一个问题。当用户超出网络覆盖范围时,所有的网络活动都将是已停止,这意味着没有云存储服务。
5.2.2系统架构
我们建议使用智能重复数据删除技术进行移动云存储(SDM)。SDM在文件级和块级使用多级重复数据删除方法,这些方法由学习系统集成(学习系统选择最佳的重复数据消除 方法来实现最佳的数据减少和能量消耗。此外,我们还使用哈希表和一个bloom过滤器来进行本地搜索并添加并行化来提高应用程序的性能。整个系统如图所示。整个过程是可逆的,因为重复数据删除是一个无损压缩的操作。
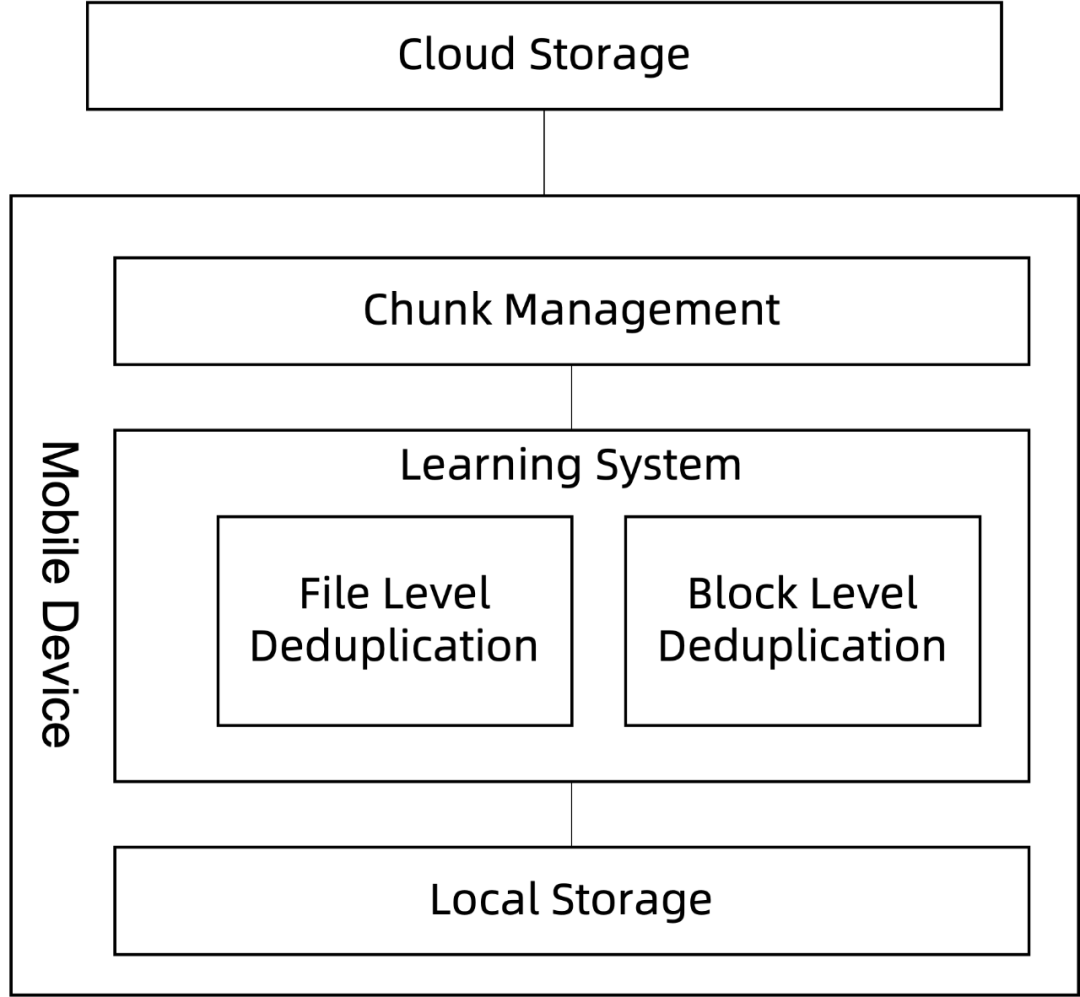
文件级重复数据删除 在文件级别上,重复数据删除可以通过比较整个文件来进行操作。由于它只将一个哈希值与另一个文件哈希值进行比较,因此该进程比其他方法更快。但是,当文件的一部分发生更改时,整个哈希值也会发生更改。这就降低了文件级重复数据删除的性能。
块级重复数据删除 当在块级别执行重复数据删除时,处理的文件被分割为多个块。每个块的处理与文件级重复数据删除中的文件相同。块的大小可以是固定大小的或可变大小的。
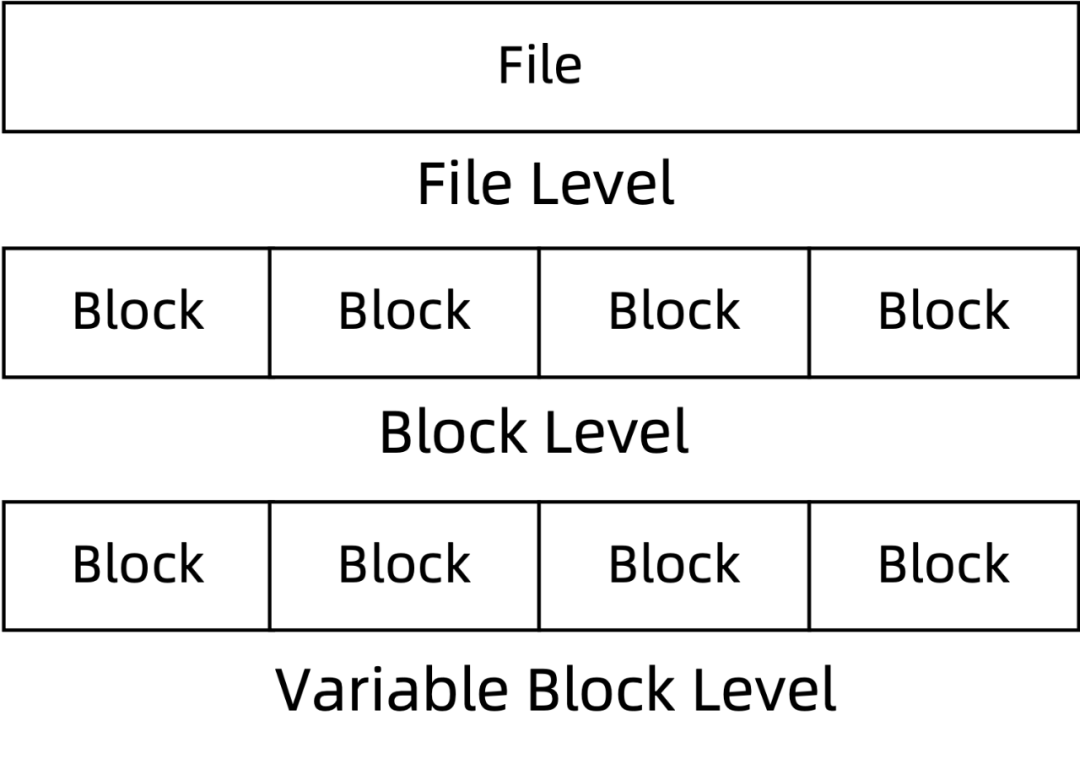
块级变化不会影响其他块的哈希值,但是,在一个块部分字节变化上就会改变多个块的哈希值。可变大小的块或内容定义的分块通过使用固定的分块偏移量来分割一个文件来解决这个问题。固定的分块偏移量可以通过使用Rabin滚动散列找到。Rabin滚动散列使用多项式和一个滑动窗口来进行散列。为了找到分块偏移量,我们滑动和散列窗口,直到哈希匹配一个预定义的值。
5.2.3应用场景
客户端API 该方案提供了客户端与存储服务器之间良好的接口。通过选择合适的存储节点, 可以降低 CPU 负载。
System.out.println();
jLabel3.setText(digits+outputString1);
Class.forname("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc//localhost:3306/javamysql", "root", "root");
String HashValue = digits + outputString1;
String status = null;
int result, tab = 0;5.2.4性能测试数据
安卓的一个原型实现上的实现:
-
仅限文件级重复数据删除的系统(FDS)
-
仅限块级重复数据删除的系统(BDS)
-
针对移动设备或SDM的智能重复数据删除
- 预配置的重复数据删除系统(PCDS)
| 文件类型 | 分配重复数据删除方法 |
|
mp3 |
文件级 |
| jpg | 文件级 |
| 块级 | |
| obb | 块级 |
|
未知的 |
块级 |
-
旋转重复数据删除系统(RADS)
| 文件类型 | 已分配的重复数据删除方法 | 目标重复数据消除率(%) |
|
mp3 |
5文件级 | 5 |
| jpg | 文件级 | 5 |
| 块级 | 5 | |
| obb | 块级 | 25 |
|
未知的 |
块级 | 10 |
5.2.5测试结果
演示不同的重复数据删除系统在处理未知文件类型时的性能:
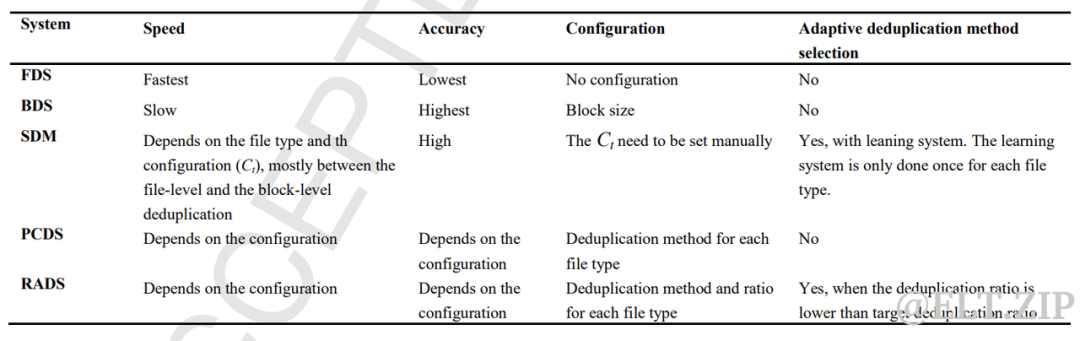
总的来说,SDM比其他系统表现得更好,特别是在未知的文件类型上,因为我们的系统不需要对不同的文件类型进行任 何特定的配置。对于大多数情况下文件和块级之间的重复数据删除吞吐量,以及接近块级重复数据删除精度的重复数据删 除精度,与其他系统相比,我们的系统可以使云存储作为移动设备的存储解决方案更加可行。
6.Ares数据压缩框架
6.1介绍
现代应用中的数据爆炸现象给存储系统带来了巨大的压力,因此开发者使用数据压缩技术来解决这个问题。但是,在考虑输入数据类型和格式时,每个压缩库都表现出不同的优势和劣势。所以有相关学者提出了Ares,一个智能、自适应和灵活的模块化压缩框架,可以根据工作负载的类型为给定的输入数据动态选择压缩库,并为用户提供适当的基础设施来微调所选的库。Ares是一个模块化框架,它统一了多个压缩库,同时允许用户添加更多压缩库。同时,Ares也是一个统一的压缩引擎,它抽象了每个工作负载使用不同压缩库的复杂性。
在科学和云计算领域的实际运用中,Ares的执行速度相比其他解决方案快了 2-6 倍,而且附加数据分析的成本较低。与完全没有压缩的基线相比,速度快了 10 倍。
6.2面临的问题
我们知道,无损压缩算法分为两类:通用算法和专用算法。像Bzip、Zlib、7z这些就是属于通用压缩库,事实上,它们的性能的确很好,但不足是不会利用数据表示之间的细微差别。所以又有了一些更专门的算法,比如Snappy、SPDP、LZO等,这一类算法通过最小化数据占用空间来提高应用程序的整体性能,因而有着广泛的前景。
尽管有以上这些特定领域的压缩库的良好发展,但是仍然面临几个比较现实的问题:
-
数据依赖:由于每个库对某种数据类型的专一化,致使对于其他情况来说,它通常不够一般化。即使选择了库,大多数应用程序由于使用很多不同类型的数据,因此仅使用一个库也不会产生最佳性能。
-
库的选择:不同的库有着不同的优点和缺点,通常为一个用例选择合适的库是困难的。即使在同一个应用程序中,其不同部分也会有着不同的压缩需求。比如档案的存储需要高的压缩比,而进程间的数据共享需要高的压/解压缩速度。
-
API和可用性:每个压缩库都有自己的一组参数和API,通常很难过渡到或采用新的库,没有哪种压缩算法可为所有类型的数据、文件格式或应用程序需求提供最佳性能。我们希望可以有一个智能的框架,能够无缝统一多个库,并根据特定场景动态选择“最佳”压缩算法。
6.3基准测试
既然要统一不同算法,那首先就要确切地掌握它们的实际表现。因此,学者对广泛选择的压缩库通过全面的基准测试进行了性能评估:
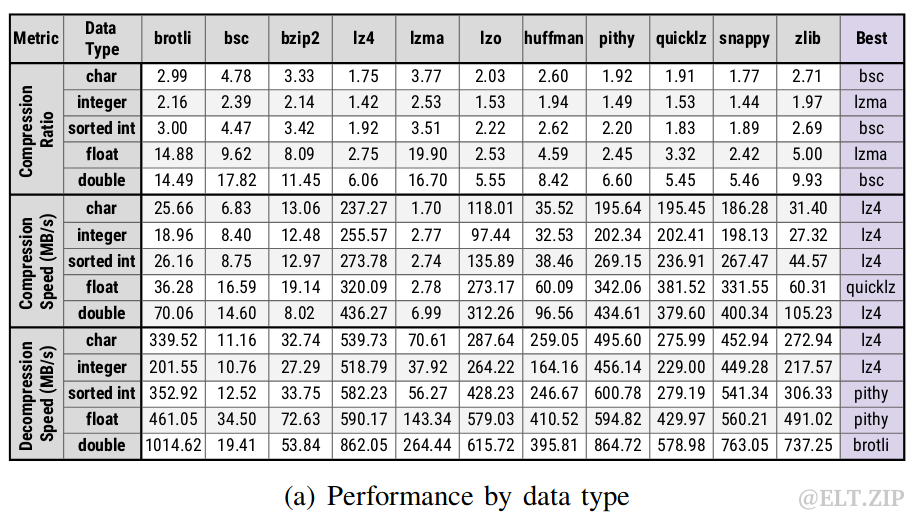
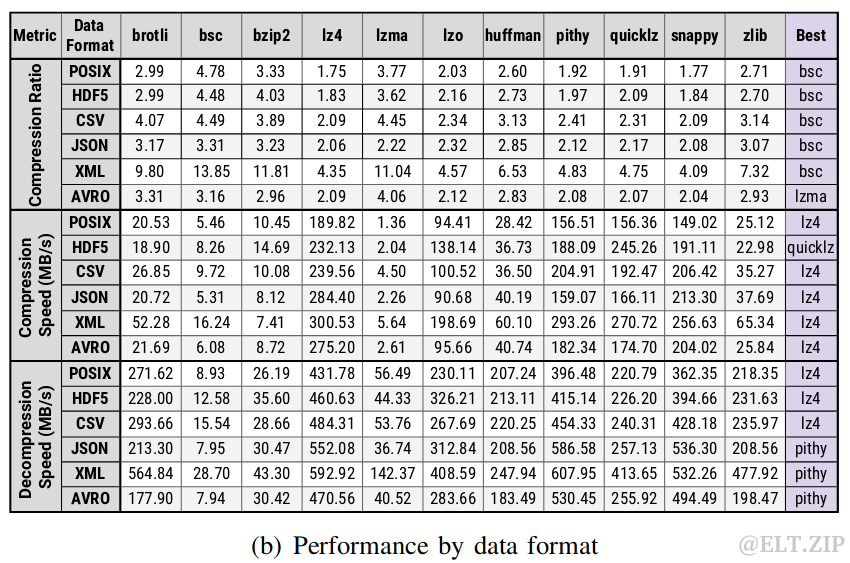
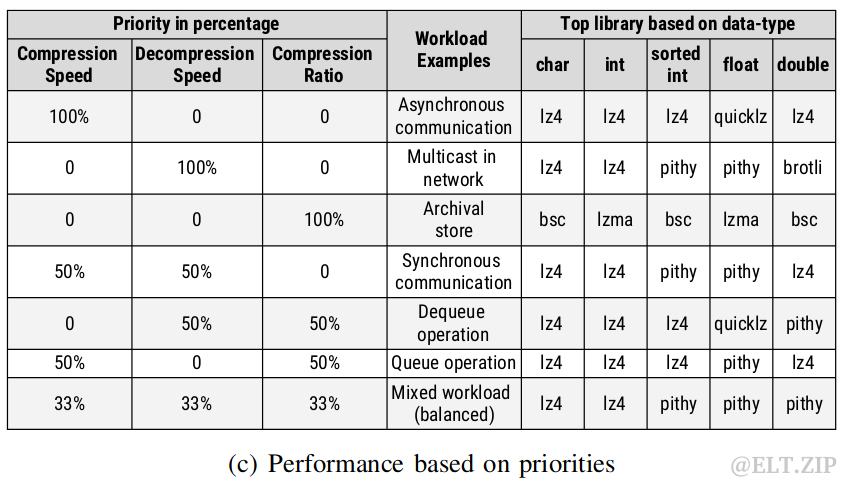
从数据类型、数据格式和工作负载优先级三个维度进行了测试,篇幅有限,细节分析部分这里不再具体展开。简单总结为:通过观察各个库之间的性能变化,可以发现每个工作负载都可以从智能的动态压缩框架中受益。
6.4Ares的体系架构
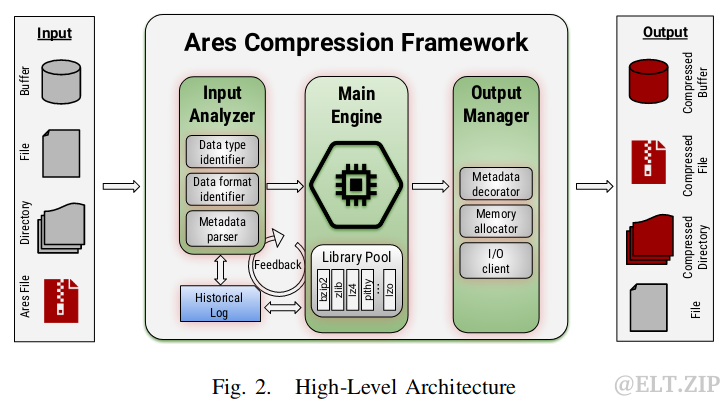
Ares架构的核心是即插即用,框架是一个中间件库,它封装了多个压缩库,从用户侧抽象出它们的复杂性。应用程序可以使用Ares作为工具(CLI)或作为一个库(API)。在这两种情况下,Ares内部的数据流是相同的。首先,Ares分析输入数据,以识别所涉及的数据类型和格式。其输入可以是一个文件、一个目录或一个以前压缩过的文件(file.ares)。然后,将分析结果传递给主引擎,由主引擎决定哪个压缩库最适合给定的情况。根据决策,Ares利用一个库池,其中包括预编译的压缩库(目前的原型中已存在11个),再执行压/解压缩操作。最后,Ares用其元数据修饰压缩数据,并输出.ares文件到磁盘。
6.5要点评估
6.5.1开销和资源利用率
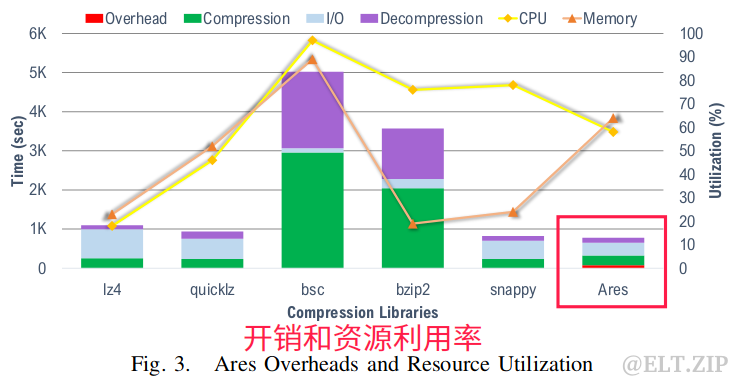
如上图,我们可以观察到,每个被测试的库都展现了不同的开销。例如,lz4、quicklz和snappy在CT、I/O和DT上都实现了类似的时间,但系统利用率不同(如snappy是CPU密集型、内存占用低)。相比之下,bsc提供了最高8.6x的CR,但也是最慢的库,它的CPU和内存占用率高达90%以上。bzip2的内存占用较低,但在CR为6.2x时仍保持较高的CPU占用率。另一方面,Ares通过分析输入数据来平衡CT、DT和CR,而这个额外的开销只占总时间的10%。Ares用了74秒进行数据类型和格式的检测,即便有这些额外的开销,Ares执行所有操作的速度仍然比所有库的速度快,并取得了最佳的总体时间。
具体来说,Ares比bsc快6.5倍,比bzip2快4.6倍,比lz4、quicklz快5-40%,而且在达到58%的CPU和64%的内存占用率情况下仍然非常快。
6.5.2压/解压智能度
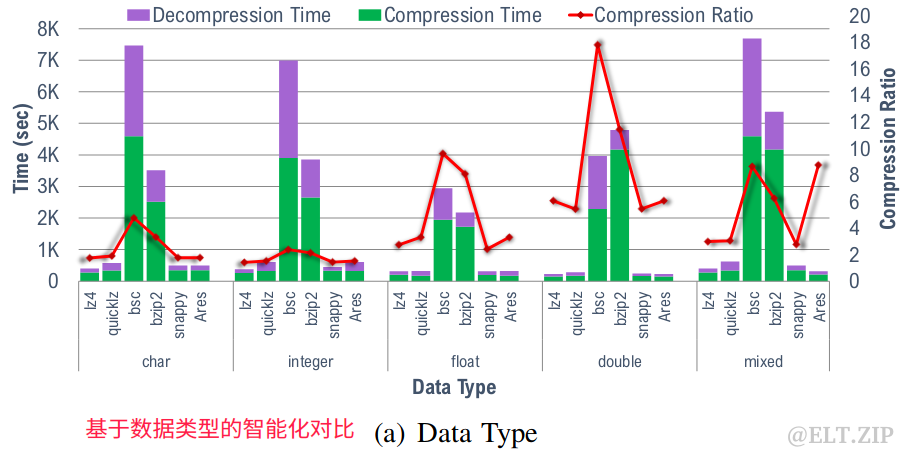

从结果可以看出,使用CR为1.75倍的lz4可以更快地压缩二进制数据。对于较复杂的压缩,bsc实现了大于5倍的CR,但CT和DT明显减慢。
6.5.3压/解压适应度
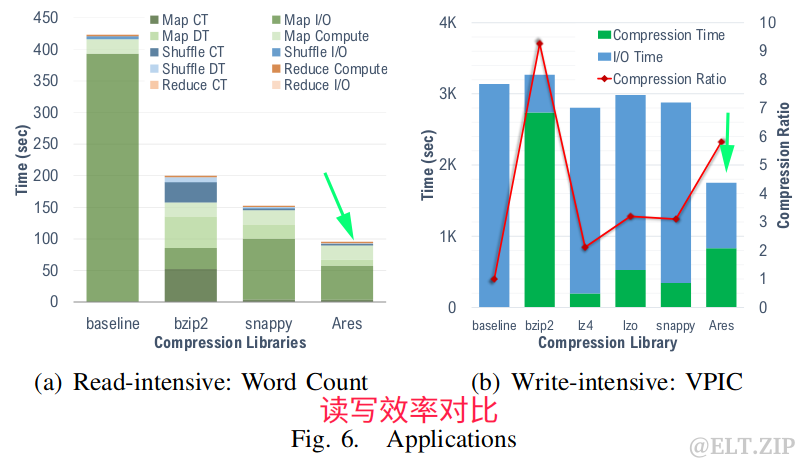
6.5.4压/解压灵活度
Ares的优势在于它能够根据输入的数据类型和格式进行压缩。此外,Ares提供了在给定工作负载的情况下对某些压缩特性进行优先级排序的基础设施。Ares的目标是通过C/C++和Java绑定支持科学和云工作负载。此外,Ares抽象了它的引擎中包含的每个压缩库的细节,这使得它更易于使用,并且在需要时可以灵活地扩展到更多的压缩库。下面用了四个不同的科学应用(VPIC和HACC)和云工作负载(单词计数和整数排序)测试了Ares的性能,研究了三种类型的工作负载:
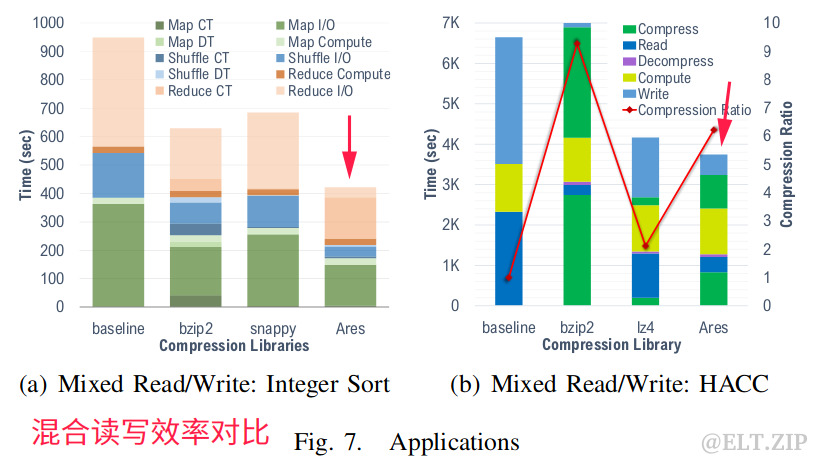
6.6总结
与传统的压缩库相比,Ares可以提高性能。具体来说,在科学和云计算领域的实际应用中,Ares的执行速度比同类解决方案快了2-6倍,并为用户提供了一个灵活的基础设施,可根据手头的任务确定压缩特点。
<本文完>
参考文献
[1] Shakarami A, Ghobaei-Arani M, Shahidinejad A, et al. Data replication schemes in cloud computing: a survey[J]. Cluster Computing, 2021, 24(3): 2545-2579.
https://www.researchgate.net/publication/350921010_Data_replication_schemes_in_cloud_computing_a_survey
[2] Widodo R N S, Lim H, Atiquzzaman M. SDM: Smart deduplication for mobile cloud storage[J]. Future Generation Computer Systems, 2017, 70: 64-73.
https://www.researchgate.net/publication/304906996_SDM_Smart_deduplication_for_mobile_cloud_storage
[3] Rani, I.S., Venkateswarlu, B.: A systematic review of different data compression technique of cloud big sensing data. In: International conference on computer networks and inventive communication technologies (pp. 222–228). Springer, Cham (2019)
https://link.springer.com/content/pdf/bfm:978-3-030-37051-0/1.pdf
[4] Hema, S., Kangaiammal, A. (2019) Distributed storage hash algorithm (DSHA) for file-based deduplication in cloud computing. In: International conference on computer networks and inventive communication technologies (pp. 572–581). Springer, Cham (2019)
https://dl.acm.org/doi/abs/10.1016/j.jksuci.2021.04.005
[5] Liu J, Shen H, Narman H S. Popularity-aware multi-failure resilient and cost-effective replication for high data durability in cloud storage[J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 30(10): 2355-2369.
https://ieeexplore.ieee.org/document/8478382/
[6] Devarajan H, Kougkas A, Sun X H. An intelligent, adaptive, and flexible data compression framework[C]//2019 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID). IEEE, 2019: 82-91.
https://ieeexplore.ieee.org/document/8752926
[7]Top 10 benefits of cloud computing - Information Age
https://www.information-age.com/top-10-benefits-cloud-computing-7248/
ELT.ZIP是谁?
ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
成员:
上海工程技术大学大二在校生闫旭
合肥师范学院大二在校生楚一凡
清华大学大二在校生赵宏博
成都信息工程大学大一在校生高云帆
黑龙江大学大一在校生高鸿萱
山东大学大三在校生张智腾

ELT.ZIP是来自6个地方的同学,在OpenHarmony成长计划啃论文俱乐部里,与来自华为、软通动力、润和软件、拓维信息、深开鸿等公司的高手一起,学习、研究、切磋操作系统技术...
写在最后
OpenHarmony 成长计划—“啃论文俱乐部”(以下简称“啃论文俱乐部”)是在 2022年 1 月 11 日的一次日常活动中诞生的。截至 3 月 31 日,啃论文俱乐部已有 87 名师生和企业导师参与,目前共有十二个技术方向并行探索,每个方向都有专业的技术老师带领同学们通过啃综述论文制定技术地图,按“降龙十八掌”的学习方法编排技术开发内容,并通过专业推广培养高校开发者成为软件技术学术级人才。
啃论文俱乐部的宗旨是希望同学们在开源活动中得到软件技术能力提升、得到技术写作能力提升、得到讲解技术能力提升。大学一年级新生〇门槛参与,已有俱乐部来自多所高校的大一同学写出高居榜首的技术文章。
如今,搜索“啃论文”,人们不禁想到、而且看到的都是我们——OpenHarmony 成长计划—“啃论文俱乐部”的产出。
OpenHarmony开源与开发者成长计划—“啃论文俱乐部”学习资料合集
1)入门资料:啃论文可以有怎样的体验
https://docs.qq.com/slide/DY0RXWElBTVlHaXhi?u=4e311e072cbf4f93968e09c44294987d
2)操作办法:怎么从啃论文到开源提交以及深度技术文章输出https://docs.qq.com/slide/DY05kbGtsYVFmcUhU
3)企业/学校/老师/学生为什么要参与 & 啃论文俱乐部的运营办法https://docs.qq.com/slide/DY2JkS2ZEb2FWckhq
4)往期啃论文俱乐部同学分享会精彩回顾:
同学分享会No1.成长计划啃论文分享会纪要(2022/02/18)https://docs.qq.com/doc/DY2RZZmVNU2hTQlFY
同学分享会No.2 成长计划啃论文分享会纪要(2022/03/11)https://docs.qq.com/doc/DUkJ5c2NRd2FRZkhF
同学们分享会No.3 成长计划啃论文分享会纪要(2022/03/25)
https://docs.qq.com/doc/DUm5pUEF3ck1VcG92?u=4e311e072cbf4f93968e09c44294987d
现在,你是不是也热血沸腾,摩拳擦掌地准备加入这个俱乐部呢?当然欢迎啦!啃论文俱乐部向任何对开源技术感兴趣的大学生开发者敞开大门。

扫码添加 OpenHarmony 高校小助手,加入“啃论文俱乐部”微信群
后续,我们会在服务中心公众号陆续分享一些 OpenHarmony 开源与开发者成长计划—“啃论文俱乐部”学习心得体会和总结资料。记得呼朋引伴来看哦。
原文标题:云计算数据压缩方案
文章出处:【微信公众号:开源技术服务中心】欢迎添加关注!文章转载请注明出处。
-
开源技术
+关注
关注
0文章
389浏览量
8011 -
OpenHarmony
+关注
关注
25文章
3760浏览量
16876
原文标题:云计算数据压缩方案
文章出处:【微信号:开源技术服务中心,微信公众号:共熵服务中心】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
租用国外云服务器算数据跨境吗?
LZO Data Compression,高性能LZO无损数据压缩加速器介绍,FPGA&ASIC
LZO Data Compression,高性能LZO无损数据压缩加速器介绍,FPGA&ASIC
云计算与边缘计算的结合
数据轻松上云——明达Mbox边缘计算网关

plc边缘计算数据采集网关是什么


华为云GaussDB数据库基础版发布:旗舰性能、价格下降超60%
基于门控线性网络(GLN)的高压缩比无损医学图像压缩算法





 工商网监
工商网监
评论