 高工年会演讲回顾:超级算力,赋能整车中央计算
高工年会演讲回顾:超级算力,赋能整车中央计算
当下的智能电动汽车时代,已经进入智能网联决胜的下半场,高算力芯片成为衡量汽车企业产品水平高低的重要指标之一,算力配置也成为了车企在车型规划中的关键要素。此外,随着芯片算力的提升,以及汽车应用复杂化,各功能域互相渗透,域集中式的控制架构成为一个演进趋势。
在上周举行的 2022(第六届)高工智能汽车年会暨年度金球奖评选颁奖典礼上,NVIDIA 中国区软件解决方案总监卓睿分享了以“超级算力,赋能整车中央计算”为题的演讲,介绍 NVIDIA 在这个背景下如何布局并做出了哪些探索。以下为内容概要。

智驾和智舱融合趋势突显
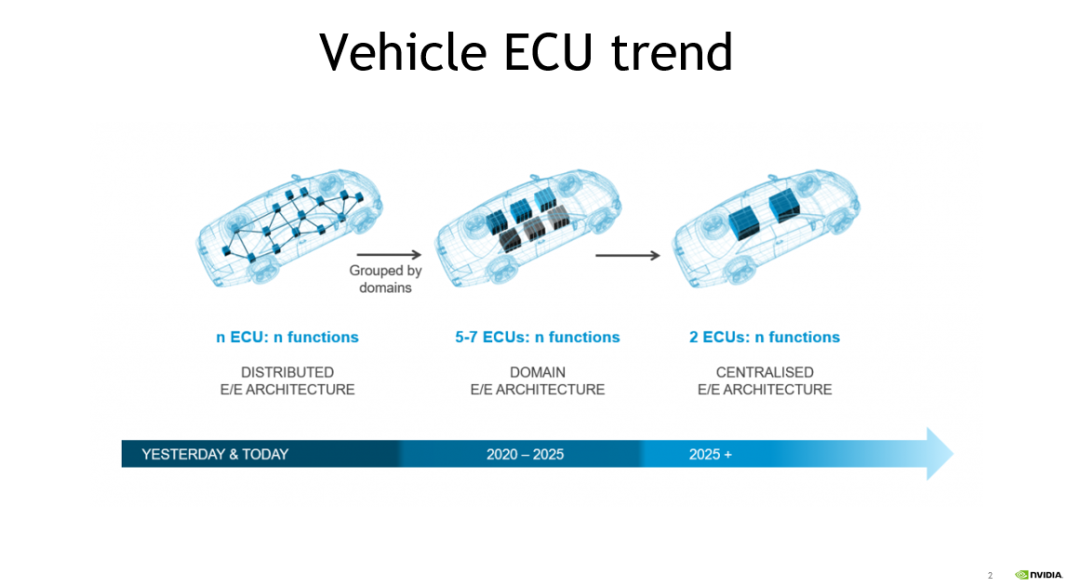
近年来,随着汽车电子电气架构由传统的分布式架构向中央集成式架构演进,车内电子控制单元(ECU)数量逐渐减少。随着芯片算力的不断提升,自动泊车以及高级驾驶辅助系统(ADAS)等功能得以整合。
当前,汽车制造商和一级供应商希望能够将智驾和智舱功能进行进一步融合。目前已经有客户将基于 DRIVE Orin 的智驾芯片与相关厂商的座舱芯片集成至一块 PCB 中或同一 ECU 中的不同 PCB 上。这种不同的技术趋势的出现,意味着在不远的将来,汽车内部与智能功能相关的域控制器数量将会进一步减少,芯片将大放异彩。
DRIVE Orin 踏浪争先
强劲赋能自动驾驶
从去年开始,很多中国车企都采用了NVIDIA DRIVE Orin SoC。DRIVE Orin Soc 的算力达到 254 TOPS,内存带宽被设定在 205GB/s,可以支持各种传感器和 4 个 10G bps 的网络接口,以及 H.265/HEVC/VP9 格式的 4K@60Hz 视频编码或者 8K@30Hz 视频解码。
DRIVE Orin 集成了新一代 GPU 体系架构,GPU 凭借其灵活性,可支持无人驾驶领域的算法团队开发新的算法。另外,GPU 虽然非常灵活,但本身从能耗比来说表现还不是最好,所以 NVIDIA 又加入了 DLA(Deep Learning Accelerator,深度学习加速器)。NVIDIA 将 GPU 与 DLA 相结合,帮助客户能够更加灵活地将不同算法部署在不同引擎上,以达到更好的功耗比和性能表现。
除 AI 计算能力之外,对芯片而言,CPU 也至关重要。目前,NVIDIA 软件团队正在持续优化 CPU 算力,将需要并行的算力从 CPU 迁移到 GPU 和 DLA。此外,DRIVE Orin 芯片属于异构的计算架构,配置了许多性能卓越的加速引擎,如适用于传统的 CV 算法的 PVA 引擎,可用于深度学习的前处理和后处理的加速。
此外,DRIVE Orin 的带宽也值得一提,其高达 254 TOPS 的算力都需要通过内存加载,如果带宽速度相对较慢,就意味着带宽才是真正的算法瓶颈。DRIVE Orin 可支持 205 GB/s 的带宽,可避免由于带宽不足造成的瓶颈。
现阶段,通过单个或两个 DRIVE Orin,不仅可以将标准的 ADAS 功能提升,应用于高速公路或城市道路等场景,还可以将 360 度环视、编码、自动驾驶监测以及泊车功能集成至 DRIVE Orin 中,而这个集成的实现得益于算力的提升和芯片功能的逐步强大。
DRIVE Thor 蓄势待发
推动实现舱驾一体融合
DRIVE Orin 是 NVIDIA 推出的第三代无人驾驶车载芯片。NVIDIA 发布的第一代 Parker 更多是基于 Linux 打通数据链路,例如摄像头获取数据后的前处理和推理等,但欠缺真正的功能安全。因而虽然被大量厂商作为开发板,但 Parker 并没有在无人驾驶领域实现量产。NVIDIA 在 Parker 之后带来了下一代产品—DRIVE Xavier,该产品在国内已有量产。DRIVE Xavier 有超过 90 亿个晶体管,是全球第一个达到 ISO 26262 安全认证的复杂 SoC。DRIVE Orin 相比于第二代产品 DRIVE Xavier,算力水平有了进一步提升,同时架构和软件也拥有延续性,在国内自动驾驶行业占据主流。
今年 GTC 秋季大会上发布的可实现 2000 TFLOPS 浮点算力的 DRIVE Thor,相比前三代产品而言变化较大。前三代产品主要用于解决智能驾驶的应用场景,而 DRIVE Thor 在此基础上,还将推动实现智能座舱。在硬件层面,DRIVE Thor 利用 MIG 技术,实现 GPU 硬件在智驾域和智舱域的隔离;在软件层面,DRIVE Thor 通过虚拟化的技术,保证渲染与 AI 功能在智舱域的并行,“软硬共进”,实现舱驾一体融合。

DRIVE Thor 内含 780 亿个晶体管,主要有三项优势(如上图)。
FP8 的支持
DRIVE Thor 的优势之一是具有 8 位浮点(FP8)精度。FP8 是 NVIDIA 积极推动的一种新型的数据处理方式,其目的在于贯通软件和硬件提供一个通用、可维持准确性的交换格式,以加速 AI 的训练、推理。传统意义上讲,开发人员在从 32 位浮点转换成 8 位整数(8-int)的数据格式时,往往会损失神经网络的准确性。DRIVE Thor 在 FP8 精度下 2000 TFLOPS 的浮点算力,让开发人员在不牺牲精度和准确性的情况下进行数据传输。事实上,FP8 的主要目的是支持推理 Transformer 引擎的自动驾驶汽车平台,该引擎是 NVIDIA GPU 中 Tensor Core 的新组件。借助该引擎,DRIVE Thor 可将 Transformer 深度神经网络的推理性能提升高达 9 倍,这对于支持与自动驾驶相关的、庞大且复杂的 AI 工作负载至关重要。
多域计算
DRIVE Thor 支持多域计算,可隔离用于自动驾驶和车载信息娱乐的功能。车辆中通常会分布数十个 ECU 来为各个功能提供支持,借助 DRIVE Thor,汽车制造商可以在单个系统级芯片(SoC)上高效整合多种功能,可满足智能座舱和智能驾驶对 GPU 不同的安全性和稳定性的需求,能够缓解算力供应紧张并简化车辆设计开发,从而进一步显著降低运行能耗、减轻重量并减少布线。
NVLink-C2C 芯片互联技术
DRIVE Thor 还采用了最新的 NVLink-C2C 芯片互联技术,可同时运行多个操作系统。用户可以单独使用 DRIVE Thor 芯片,也可以通过最新的 NVLink-C2C 芯片互连技术同时连接两个 Thor 芯片,使两个芯片作为单一操作系统的统一平台。
NVLink-C2C 的优势在于它能够以最小的开销在超高速数据传输链路中共享、调度和分发任务。在软件定义汽车的发展趋势下,这为汽车制造商带来足够大的算力冗余和灵活性,支持软件定义车辆的开发,这些车辆可通过安全的 OTA 更新持续升级。
软件赋能“行稳致远”
那么如何让中央域控制的芯片更富竞争力呢?除了硬件的支持外,软件赋能也必不可少。无论是 DRIVE Orin 还是 DRIVE Thor,都是 SOA 架构,该架构拥有很强的延续性。该部分着重介绍以下几点:
-
DRIVE Orin 和 DRIVE Thor 的 API,也就是所谓的中间件,以及底层的大部分架构非常相似,可支持有 DRIVE Orin 开发经验的开发人员,将其开发的代码轻松迁移至 DRIVE Thor。
-
基于 NVIDIA DRIVE OS 的经验。DRIVE Orin 和 DRIVE Thor 均支持基于 Hypervisor 的 Guest OS 架构。客户可根据场景的需要,灵活地配置一个或者多个 Guest OS 作为操作系统。
-
安全标准受重视程度逐渐提高,厂商也更加关注安全需求。NVIDIA 在软硬件方面都进行了功能安全性的提升。
-
随着芯片逐渐开始支持多域计算,虚拟化的重要程度也不断提升。当前,NVIDIA 可利用自有的 Hypervisor 实现虚拟化,避免不同模块之间产生干扰,实现资源隔离。
DRIVE Orin 是利用了相同的 Hypervisor,其 ADAS 功能可根据客户需求选择 Linux 或 QNX 作为操作系统。当前国内主流选择是 QNX 系统,但仍有不少数客户选择使用 Linux。NVIDIA 与黑莓(BlackBerry)进行了深度合作,通过 QOS 版本满足 ASIL-D 级别的功能安全。
在 DRIVE Thor 中,用户可整合仪表盘、车载信息娱乐(IVI)等功能。因此,可以支持三个 Guest OS 来满足不同域的需求。
NVIDIA 对于深度学习领域关注的不仅仅是 TOPS 算力本身。如图所示是 NVIDIA 每一代芯片产品最高可达的算力水平,在此基础上还需考虑带宽以及可编程性等。对于可编程性而言,NVIDIA CUDA 架构可支持业界流行的 TensorFlow、PythonTorch 等典型训练框架,拥有良好的可编程性。
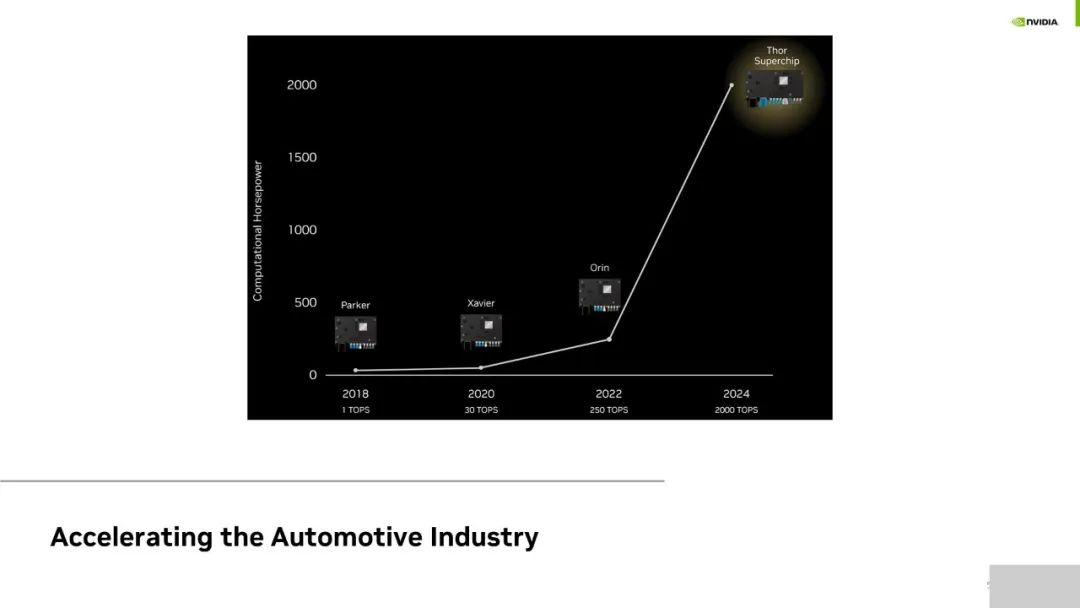
而编译器实际上是一个推理架构,能够优化以 Python 或 Tensorflow 输入的网络架构,包括对 Layer 的融合,精度的优化等,能够在保证准确性的同时大幅提升性能。NVIDIA 支持不同的网络,包括检测、分类、Transformer 和对话式 AI 等。因为目前智能座舱的对话式 AI 部署很多是基于云上进行的,希望未来客户能够借助 NVIDIA 提供的算力支持,将他们部署在云端的算法部署在 DRIVE Thor 中。
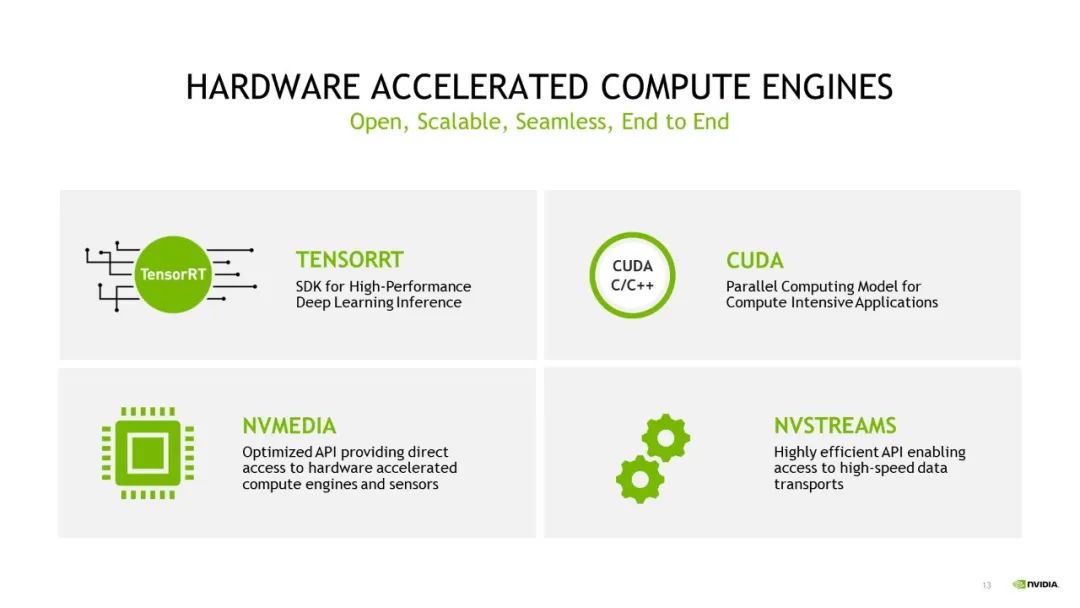
除上文提到的 DRIVE OS 以外,NVIDIA 还将在 DRIVE Orin 和 DRIVE Thor 等产品中延续使用 NVIDIA DRIVE SDK 和 CUDA 架构。SDK 的延续,可赋能应用迁移,如将基于 DRIVE Orin 开发的应用轻松迁移至 DRIVE Thor 平台。如 NvMedia 可用于收集传感器数据并无缝传输至 GPU 引擎和 DLA 引擎中,而 NvStreams 则相当于一个用于内存管理和传输的 SDK,可以实现不同应用场景之间的数据传输,包括跨线程、跨进程和跨 VM 之间的传输。
原文标题:高工年会演讲回顾:超级算力,赋能整车中央计算
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3858浏览量
92164
原文标题:高工年会演讲回顾:超级算力,赋能整车中央计算
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

算智算中心的算力如何衡量?

算家计算 开启贵州人工智能算力服务新篇章

燧原科技入选先进计算赋能新质生产力典型应用案例
亿纬锂能受邀出席2024高工锂电年会
本源“量超融合先进计算平台”入选2024算力中国·年度重大成果

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
稳定、高效、低成本,储能与算力正在相互赋能
算力的分类与现代生活
算能亮相第七届数字中国建设峰会,以算力赋能千行百业

马斯克欲建xAI超级算力工厂
中科创达全球首发面向中央计算的AI原生整车操作系统—滴水OS
DPU技术赋能下一代AI算力基础设施
中国移动发布基于飞腾CPU自主研发的赋能AI算力时代的新产品






 工商网监
工商网监
评论