 如何利用StarRocks特性开启数据湖的极速分析体验
如何利用StarRocks特性开启数据湖的极速分析体验
随着开源数据湖技术的快速发展以及湖仓一体全新架构的提出,传统数据湖在事务处理、流式计算以及数据科学场景的限制逐渐得以优化解决。 为了满足用户对数据湖探索分析的需求,StarRocks 在 2.5 版本开始发布了诸多数据湖相关的重磅特性,为用户提供更加开箱即用的极速湖分析体验。
本文为您揭秘如何利用 StarRocks 特性开启数据湖的极速分析体验,同时展示用户真实场景中的落地案例以及性能测试结果,最后对 StarRocks DLA (Data Lake Analytics)未来的产品规划做一些分享。
#01
站在Warehouse的当下,思考Lakehouse的未来
—
整个大数据架构逐步经历了这么几个典型的发展阶段:
Schema-on-Write 架构:通过严格的建模范式约束,来支撑 BI 场景下的查询负载,但在以存算一体为主流系统架构的历史背景下,数据量膨胀带给用户高昂维护成本,同时对异构数据缺乏维护能力。
Scheme-on-Read 架构:以 HDFS 为统一存储层,并提供基础的文件 API 来与查询层进行交互。这种架构模式虽然一定程度上保证了 TCO 和文件格式开放性,但由于应用读时才能感知数据质量,也将数据治理问题带来的成本转嫁给了下游应用。
云上数据湖架构:云上对象存储逐步代替 HDFS,并逐步演化成:以对象存储作为统一离线存储, 以 Warehouse 作查询加速双层架构。虽然这种双层架构同时保障了冷数据的存储成本和热数据的查询性能,但伴随而来的是多轮跨系统 ETL,也就引入了 Pipeline 构建时的工程复杂度。
伴随数据湖架构的现代化革新,用户除了维护一个 Apache Iceberg(以下简称 Iceberg)/Apache Hudi(以下简称 Hudi)湖存储,更亟需一款高性能的查询组件来满足业务团队的分析需求,快速从数据中获得“见解”驱动业务增长。传统的查询引擎,例如 Apache Spark(以下简称 Spark)/Presto/Apache Impala(以下简称 Impala)等组件能够支撑的数据湖上查询负载性能有限。部分高并发低延时的在线分析场景依旧需要用户维护一套 MPP 架构的数仓组件,多套组件伴随而来的自然是系统复杂度和高昂的运维代价。所以我们一直在畅想:有没有可能使用 StarRocks 来帮助用户搞定所有的分析场景?以“帮助用户屏蔽复杂度,把简单留给用户”为愿景,那我们可以做些什么?
其实 StarRocks 早在 2.2 版本起,就引入了 Apache Hive(以下简称 Hive)/Iceberg/Hudi 外部表等特性,并在离线报表、即席查询等场景积累了成熟的用户案例。从一条 SQL 的生命周期来说,StarRocks 除了在查询规划阶段 FE 节点对 Hive metastore 发起元数据请求,以及执行查询计划时 BE 扫描对象存储以外,其他阶段可以实现高度的复用。这意味,一方面,得益于 CBO 和向量化执行引擎带来的特性,StarRocks 数据湖分析在内存计算阶段有明显的优势;另一方面,我们也意识到,元数据服务请求和 DFS/对象存储之上 Scan 等环节,在整个 SQL 生命周期里可能会成为影响用户查询体验的关键。
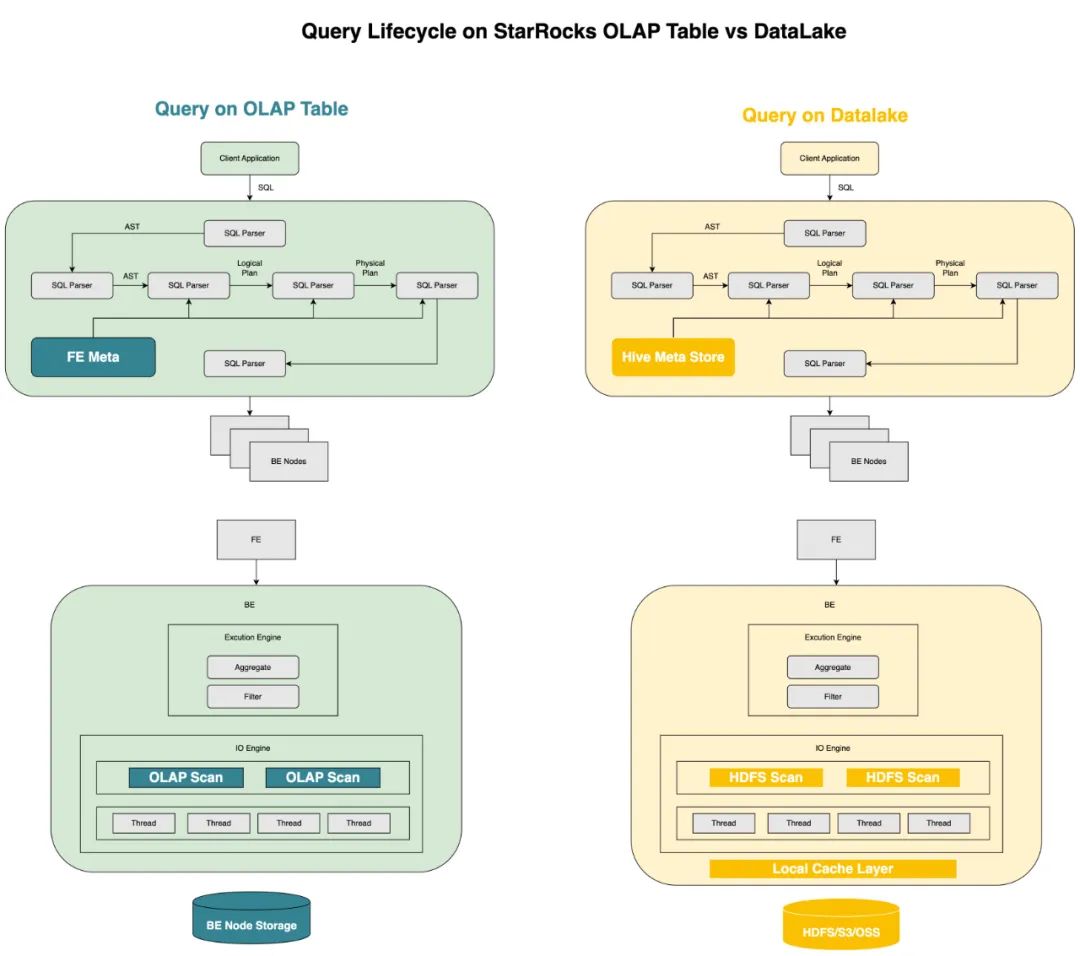
从工程效率来说,数据湖分析的前置工作,本质是便捷高效地完成元数据服务和存储的访问接入和同步工作。在这一场景里,2.2 版本之前的外部表要求用户逐个手动完成表结构的配置,和 Presto/Trino 等产品相比,在易用性上还有一定差距。 从数据治理的角度来说,构架分析链路的关键环节之一就是,让查询层在接入时能够遵循企业的数据安全规范,无论是元数据可见性还是表文件可访问性。如何构建可信的数据安全屏障,打消架构师在技术选型时的顾虑,也是 StarRocks 在大规模生产用例中进行落地应用的基础前提。 将当下面临的问题抽丝剥茧之后,StarRocks 数据湖分析便有了更加清晰的产品目标:
Extreme performance:用极致查询性能赋能数据驱动的业务团队,让用户快速获得对数据的见解
Out-of-box:需要提供更加开箱即用的数据接入体验,以及更加安全合规的数据接入模式
Cost effective:为用户提供具有性价比的资源持有方案,成为 Price-performance 维度的技术选型最优解
Uniformed platform:StarRocks 是带有自管数据的现代架构 MPP 数据库。当用户分析内部数据和外部数据时,如何带来一致的数据管理体验,也是致力于现代湖仓架构的 StarRocks 面临的核心挑战之一。
#02全新的场景与挑战—1查询性能的挑战
我们第一阶段目标是对标主流的查询引擎产品(例如 Presto/Trino),为数据湖上的查询负载带来 3-5 倍的性能提升。在团队向这一目标推进过程中,我们的产品也遭遇了场景差异性带来的挑战。不同于查询内表场景,对元数据服务以及分布式文件存储的响应波动的鲁棒性直接决定了用户侧的查询体验是否平稳。
在这里,我们以一条 Query on Hive 的生命周期来举例,说明不同阶段我们遇到的问题:
查询规划阶段:若用户查询历史明细数据,单条 Query 可能会同步触发大量 Table Partition 的元数据请求,Metastore 的抖动又会导致 CBO 等待超时,最终引发查询失败。这是一个 Adhoc 场景中最典型的案例。在查询规划阶段,如何在元信息拉取的全面性和时效性上做出体验最好的权衡?
资源调度阶段:Adhoc 场景下的系统负载有明显的峰谷差异,从资源成本角度出发,弹性扩缩容自然是一个查询组件在公有云场景需要具备的基础特性。而在 StarRocks 存算一体的架构里,BE 节点扩缩容过程伴随着数据重分布的代价。因此,如何才能为用户提供容器化部署以及水平伸缩的可能性?另一方面,在大规模用例里经常会出现多业务部门共享集群的场景,如何为运行在数据湖上的查询负载提供很好的隔离性,降低业务之间的影响?
查询计划生成阶段:查询数据湖时,目标数据的文件分布决定了 Scan 过程的 IO 开销,而文件分布一般又取决于上游写入习惯与文件合并策略。对于上游 CDC 入湖过程中里的大量小文件,如何设计灵活 Scan Policy 才能缓解 IO 带来的查询性能瓶颈?
查询执行阶段:我们都知道在生产环境中,HDFS 本身由于抖动带来访问延迟是很常见的现象,而这类抖动就直接给查询速度造成波动,很影响业务用户的分析体感。同时,Adhoc 场景本身的查询习惯(例如针对全量历史数据的一次聚合计算)决定了瓶颈并不在内存计算而是在 IO 上。如何让 Query 再快一点?想在外部存储上直接优化 IO 的问题,最直接的想法就是针对局部性较强的查询场景,提供针对远端存储的数据文件 Cache 能力。
2数据管理的挑战 借助 StarRocks 已有的全面向量化执行引擎、全新的 CBO 优化器等,这些能力能够极大地提升我们在单表以及多表层面的性能表现。在这个基础之上,针对数据湖分析的场景,我们也增加了新的优化规则。
相信关注 StarRocks 的读者中很大一部分是基础架构领域的从业人员。但凡和业务团队打过交道,都会感同身受:推动业务部门升级基础技术组件,成本非常的高。对公司 IT 治理来说,在每一次技术选型里,能否全面 cover 旧方案的基础用例、把控业务迁移里的 bad case 同样会影响选型成败。此时 StarRocks 就更需要站在工程师朋友的视角上,全面审视湖分析场景中“水桶的短板”到底在哪里。
数据安全:数据湖作为维护企业核心数据资产的基础设施,一般在企业内都会为其维护成熟的访问控制策略,例如,在传统 Hadoop 生态中基于 Kerberos 来定制统一认证,用 Ranger 做统一 ACL 管理;或者是接入云厂商托管的 IAM 服务。这些不同场景下数据治理的事实标准,均是考量数据湖分析产品成熟度的重要参考。
业务迁移:在尝试用 StarRocks 来帮助用户替换存量的 Presto/SparkSQL 查询负载的过程中,用户需要同步迁移原有的业务 SQL,甚至是 UDF。系统之间的语法糖差异越大,用户在迁移过程里进行 SQL 重写的成本就越高昂。面对引擎之间的语法差异,如何尽可能给用户带来平滑的迁移体感?
元数据管理:StarRocks 作为具有自管数据的 OLAP 系统,如果同时接入外部湖上的数据,意味着需要统筹管理系统内部/外部的元数据,并通过 StarRocks 展示统一视图。系统外部元数据同步的数据一致性和开箱即用如何权衡?
3社区协作的挑战 Eric S. Raymond 在《大教堂和集市》中说,一个项目若想成功,“要将用户当做合作者”。开源产品的成功,从来不止步于完成一个特性的开发这么简单。
历史上,Hive 在大数据生态中并不是产品力最出众的,正是其对计算引擎的包容普适性逐步造就了其不可替代的位置。StarRocks 站在 OLAP 查询层的角度也希望为社区用户构建一种普适性:于湖分析场景来说,任意数据源的接入需求,社区开发者都能够快速流畅地完成接入开发。优雅高度抽象的代码框架,理想中可以带来一种双赢的协作模式:用户的需求能够以社区互助的方式得到敏捷响应,产品能力也可以像滚雪球一样愈加丰满,伴随社区生态不断成长。
在这个愿景下,如何在起步阶段定义出一个好的代码框架,让后续各类数据源对接的开发工作对社区的工程师同学尽可能友好,又能平滑兼容各类外部数据系统的差异性,则是数据湖研发团队一个重点需要思考的问题。
#03
思考和关键行动
—
1数据湖生态全面完善
支持 Hudi 的 MOR 表(2.5.0 发布)
StarRocks 在 2.4 版本就通过 Catalog 提供了 Hudi 数据的接入能力。在即将发布的 2.5.0 版本,StarRocks 将会支持以 Snapshot query 和 Read optimized query 两种查询模式来支持 Hudi 的 MOR 表。
借助该特性,在数据实时入湖场景(例如上游 Flink CDC 到 Hudi),StarRocks 就可以更好支持用户对实时落盘数据的分析需求。
支持 Delta Lake Catalog(2.5.0 发布)
在 2.5.0 版本中,StarRocks 将正式通过 Catalog 支持分析 Delta lake。目前支持以 Hive metastore 作为元数据服务,即将支持 AWS Glue。未来还将计划逐步对接 Databricks 原生的元数据存储。
通过这种方式,在 Spark 生态里批处理完成的数据,用户就可以无需重复拷贝,直接在 StarRock 进行交互式分析。
支持 Iceberg V2 表(在 2.5.X 即将发布)
StarRocks 在 2.4 版本就通过 Catalog 提供了 Iceberg V1 数据的接入能力。在未来的 2.5 小版本中,我们即将正式支持对接 Iceberg V2 格式,全面打通 Iceberg 与 StarRocks 的数据生态。
支持 Parquet/ORC 文件外表
在部分场景下,用户的数据文件直接由 Spark Job 或者其他方式写入 DFS 生成,并不具备一个存储在 Metastore 中的完整 Schema 信息。用户如果希望直接分析这些文件,按照以往只能全量导入 StarRocks 后再进行分析。在一些临时的数据分析场景下,这种全量导入的模式操作代价比较昂贵。
从 2.5.0 版本起,StarRocks 提供了文件外表的功能,用户无需借助 Metastore 也可以直接对 DFS/对象存储的文件直接进行分析,更可以借助 INSERT INTO 能力对目标文件进行导入前的结构变换和预处理。对于上游以原始文件作为数据源的分析场景,这种模式更灵活友好。2开箱即用的元数据接入方案
Multi-catalog (2.3.0已发布)
StarRocks 在 2.3 版本中发布了 Catalog 特性,同时提供了 Internal Catalog 和 External Catalog 来对 StarRocks 内部自有格式的数据以及外部数据湖中的数据进行统一管理。
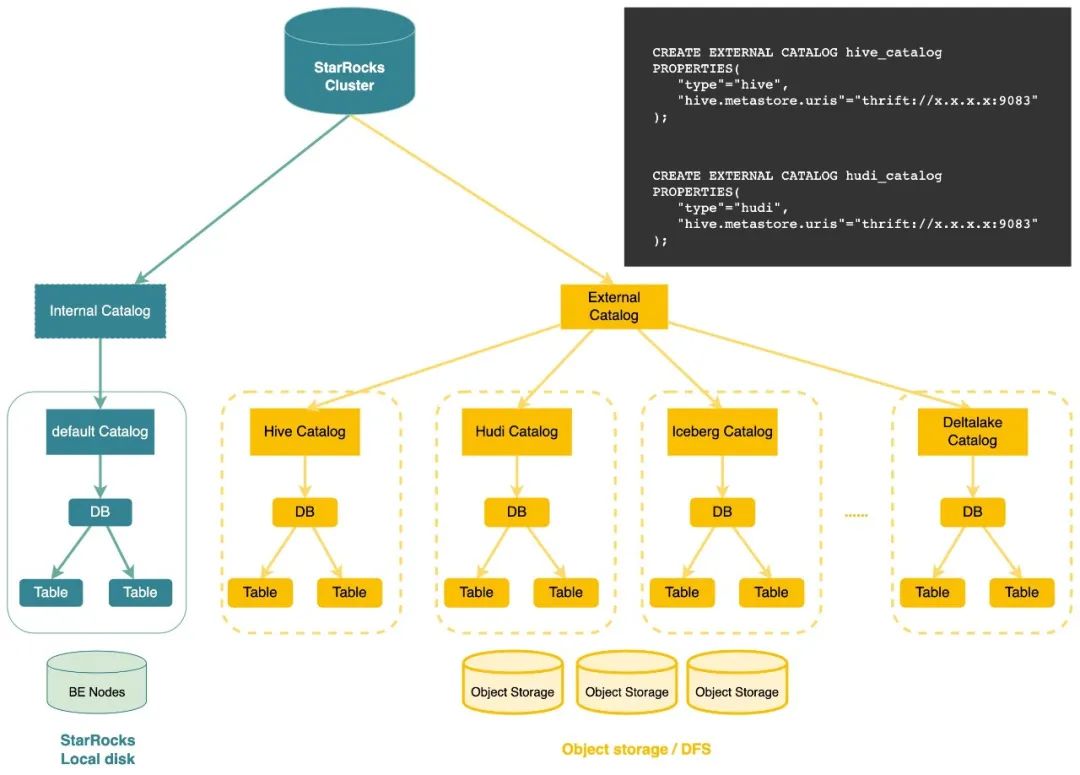
借助 External Catalog,用户无需创建外部表即可对湖中的数据进行分析,维护 StarRocks 的平台团队也无需维护两个系统之间的元数据一致性。
开箱即用的 Meta Cache policy(2.5.0发布)在 2.5 之前版本的 Hive catalog 里,元数据同步存在较多问题。一旦 Hive 表发生了分区的新增或是分区内数据发生了修改,往往需要用户找到指定分区,并在 StarRocks 里手动执行 REFRESH PARTITION 才行。这对业务侧的用户带来了较大困扰,因为业务分析师团队往往无法感知具体哪个分区发生了数据变更。 在 2.5 版本,我们优化了这个系统行为,对于 Hive 追加分区,StarRocks 会在查询时感知最新分区状态;对于 Hive 分区中的数据更新,我们提供了REFRESH EXTERNAL TABLE 的方式来刷新最新的元数据状态。 通过这种方式,Adhoc 场景里的业务团队无需关心具体的分区数据更新,也可以在 StarRocks 访问到具有正确性保证的数据结果。3完备的分析用例支持湖分析支持 Map&Struct(2.5.0发布)完整支持分析 Parquet/ORC 文件格式中的 Map 和 Struct 数据类型:

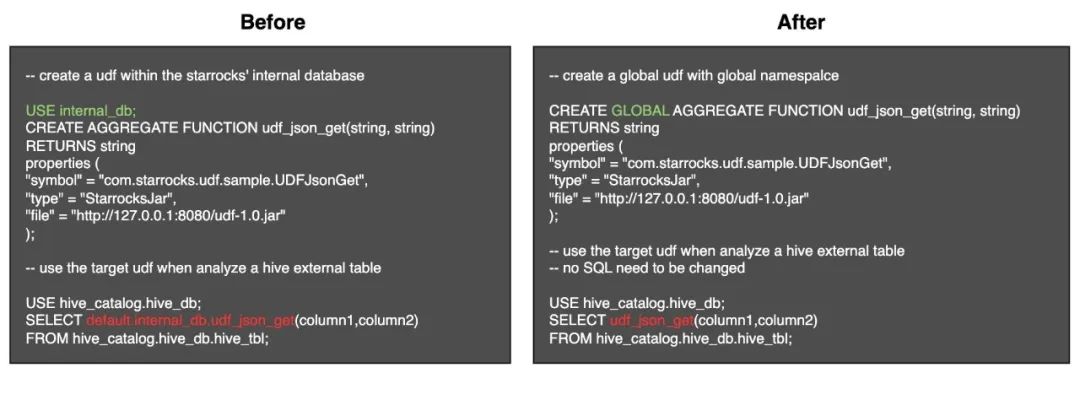
Global namespace 的 UDF(2.5.x 即将发布)在之前的 OLAP 场景中,StarRocks 的 UDF 是挂载在某个 database 下进行管理,Namespace 是 Database-level。这种模式在湖分析场景给用户带来一定的困扰,因为用户无法直接通过 Function_name 来引用目标函数,而是通过
4极致性能体验Blockcache(2.5.0发布)
为了优化重 IO 场景下的查询场景,一方面降低热数据查询场景下,相同原始数据反复读取的 IO 代价,另一方面缓解 DFS 本身波动对查询性能带来的波动,StarRocks 在 2.5.0 即将正式发布 Block cache 特性。
在 StarRocks 里,Block 是对 DFS/对象存储中原始文件按照一定策略切分后的数据对象,也是 StarRocks 对原始数据文件进行缓存时的最小数据单元。当查询命中 DFS/对象存储中文件后,StarRocks 会对命中的 Block 进行本地缓存,支持内存+本地磁盘的混合存储介质方式,并分别配置 Cache 对内存和本地磁盘的占用空间上限。基于 LRU 策略对远端对象存储上的 Block 进行载入和淘汰。
通过这种方式,大幅度优化了 HDFS 本身抖动的问题,无需频繁访问 HDFS;同时对于热点数据上的交互式探查场景,大大提升了远端对象存储的数据拉取效率,用户分析体验得到极大提升。更重要的是,整个缓存机制没有引入任何的外部依赖,通过配置文件即可开启。
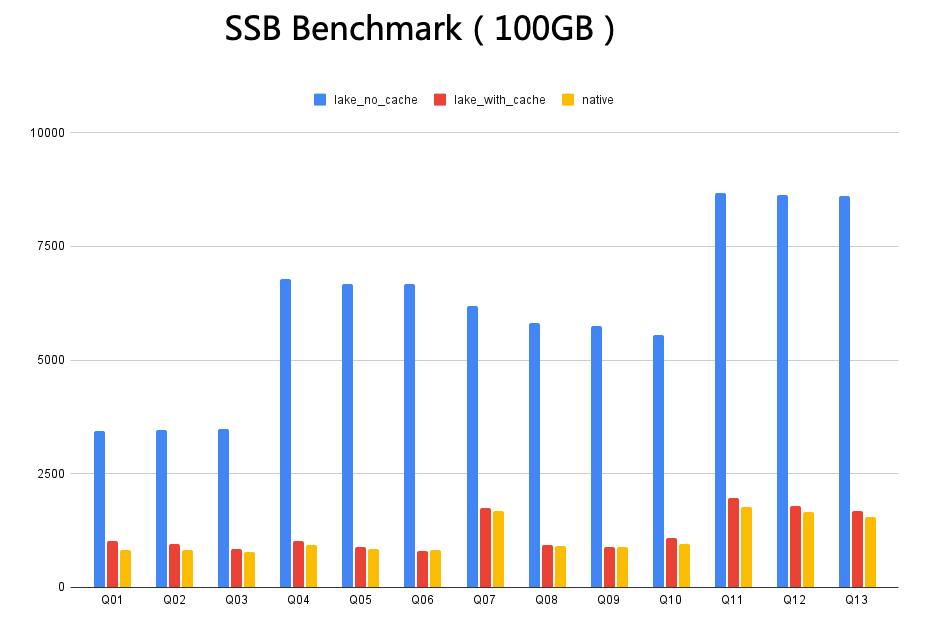
如下图所示,以 100GB 的 SSB Benchmark 为例,实验中以使用纯内存作为缓存介质,以阿里云 OSS 作为对象存储。其中 lake_with_cache 是缓存命中率 100% 情况下的查询性能,Native 是指数据导入 StarRocks 后的查询性能,lake_with_cache 是无缓存直接访问 OSS 的查询性能。从图中可以观测到:在缓存完全命中的前提下,cache 后的数据查询性能基本追平将数据导入 StarRocks 的性能。这意味着在部分简单场景下,借助 Blockcache 的能力,StarRocks 在已经能够支撑部分延迟要求更加苛刻的 SQL 负载。
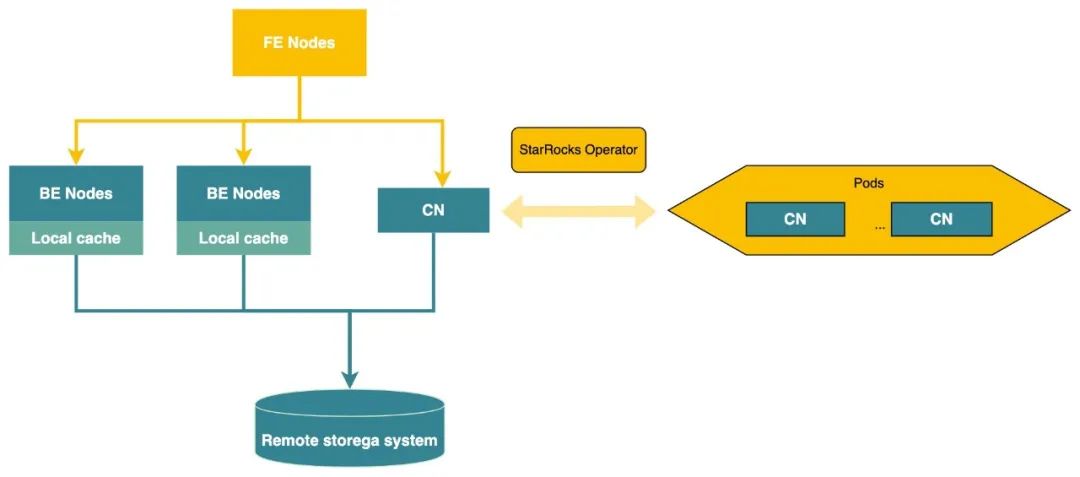
5更加灵活的资源管理模式StarRocksonK8S(2.5.0即将发布)在 StarRocks 存算一体的背景下,为了加节点提升集群整体查询负载的同时又不带来数据重分布代价,社区开发者们经过长达 3 个月的研发为社区贡献了基于 K8S 的存算分离能力。具体来说,从 2.4.0 版本起,通过在 BE 节点的基础之上,就已经重新抽象了一种无状态的计算节点(Compute Node,简称CN)。 在数据湖分析场景,CN 可以承担从 Scan 到 Shuffle 到聚合全生命周期的计算流程。CN 除了支持用户进行免数据迁移的在线增减节点以外,还能够通过容器化来进行部署。在此基础上,社区官方还提供了全新的 StarRocks Operator,能够在实际业务场景中后端流量&日志量激增时,实时感知分析平台的负载激增,并快速地自动创建 Compute Node。同时,通过 Kubernetes 的 HPA 功能完成 Compute Node 的弹性扩缩容(该特性已经在 2.4 版本发布)。内核级别的灵活弹性,一方面,大大优化了数据湖场景下用户维护 StarRocks 的 TCO,另一方面也给基于 StarRocks 构建 Serverless 形态的湖分析产品提供了无限想象空间。
从 2.5.0 版本起,StarRocks 的 FE/BE 也基本完成了容器化部署的兼容。不久,社区官方 Operator 也即将发布,届时将会大大提升运维效率和生产力。
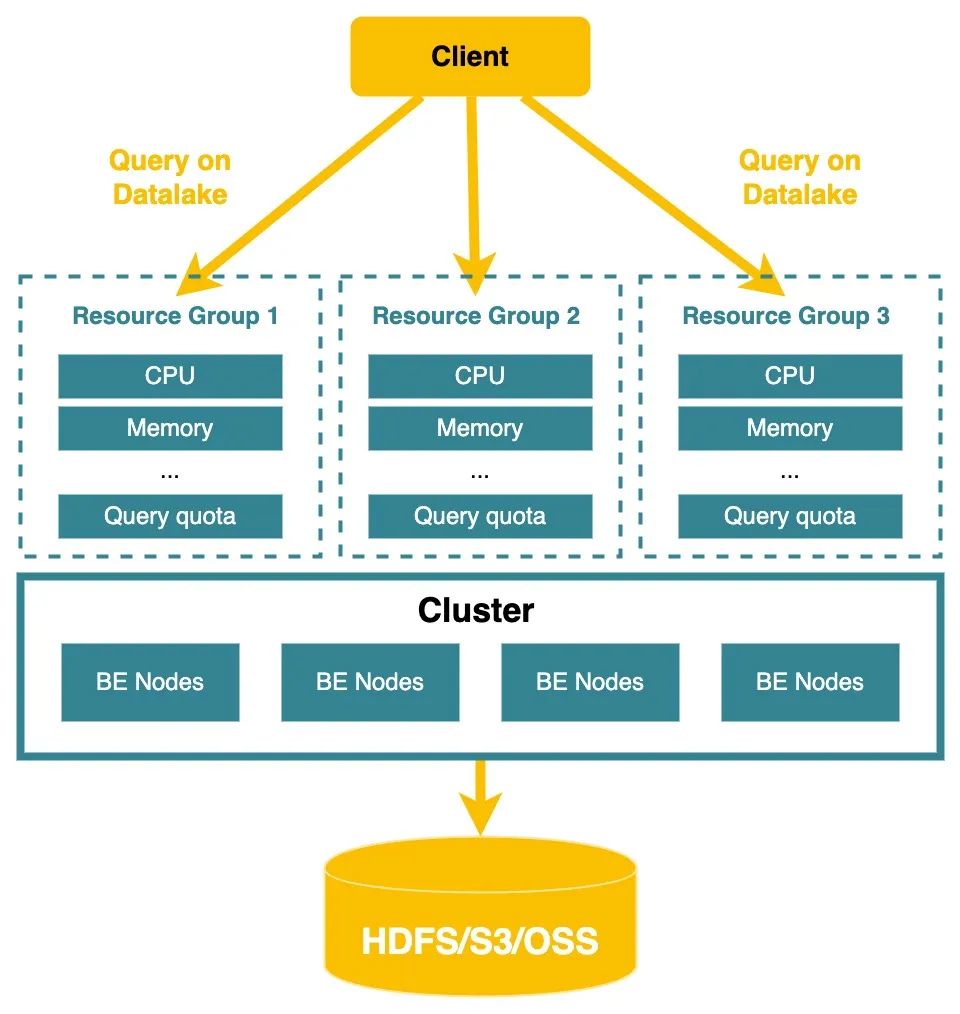
利用Resource group对湖上的分析负载进行软隔离(2.3.0已发布)
StarRocks 在 2.2 版本发布了资源隔离能力。在 2.3 版本支持了通过资源组来对数据湖上的查询负载进行隔离。通过这种软隔离的资源划分机制,能够让这些 Adhoc query 运行时在特定的 CPU 核数/内存范围之下,用户的大规模集群在同时支持多个部门的固定报表分析业务和 Adhoc 业务时,能够具有更好的隔离性,湖上的大查询相互之间可以优先保障稳定。
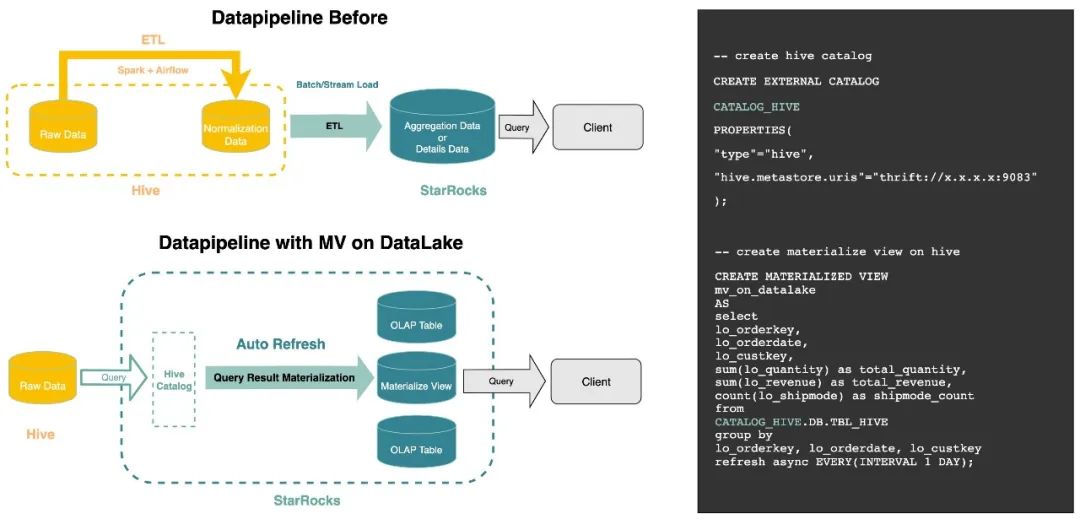
6湖仓深度融合支持在数据湖上构建自动刷新的物化视图(2.5.0发布)物化视图是数据库技术中的一种经典查询加速手段,主要给用户带来两大价值点:查询加速和数据建模。在 2.4 版本中,我们发布了全新的物化视图,该物化视图在语义上是一张用户可感知并独立查询的表,具备将复杂查询结果进行物化并自动刷新的能力。 从 2.5 版本开始,StarRocks 支持直接在数据湖上构建物化视图,用户只需要在创建物化视图时,基于 INSERT INTO SELECT 定义好数据加工处理的逻辑以及自动刷新的时间周期(例如 1 天),物化视图便会自动将湖上数据进行处理,并把结果落盘在 StarRocks 的本地存储上。同时考虑到 ODS 层全表扫描的代价比较重,例行执行这类查询会给内存带来大量不必要开销。对于 Hive 分区表场景,V2.5.0 的物化视图还支持在创建时扫描最近 K 个分区数量,从而搭配分区裁剪来控制例行扫描的数据量。 参考下图,我们可以看到前后对比:对于一些常见的 ETL 任务及其调度场景,我们无需再依赖外部系统,跨系统间的 ETL 链路也得到了缩短。对于平台团队来说,大大节约了运维成本。 在 V2.5.X 的后续小版本,我们还即将针对数据湖上的查询提供自动路由能力。通过后台查询改写技术(Query rewrite),当用户的 SQL 查询 Hive 时,系统会基于匹配程度将 Query 自动路由到物化视图上,直接返回提前聚合处理好的数据结果。对于物化视图和源表数据存在不一致的场景,系统也会提供默认兜底策略来优先保证查询结果的正确性。真正意义上实现统一一份元数据的前提下,尽可能给数据湖上的查询负载带来 MPP 数据仓库的查询并发和分析体验。
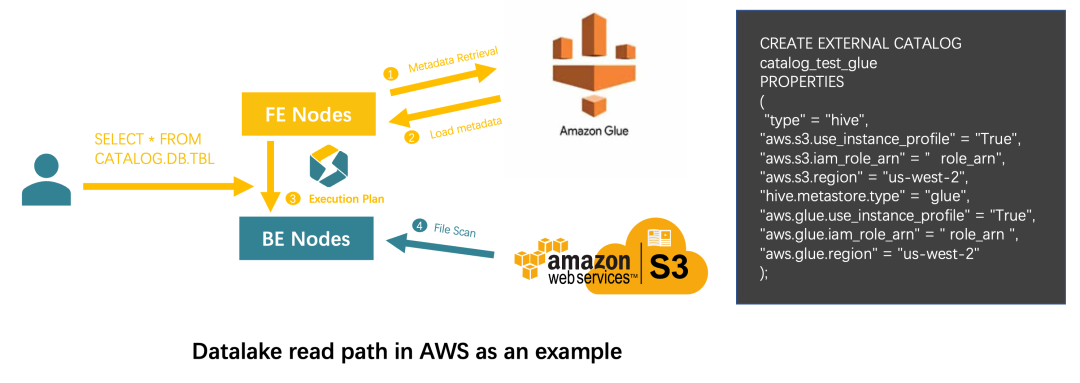
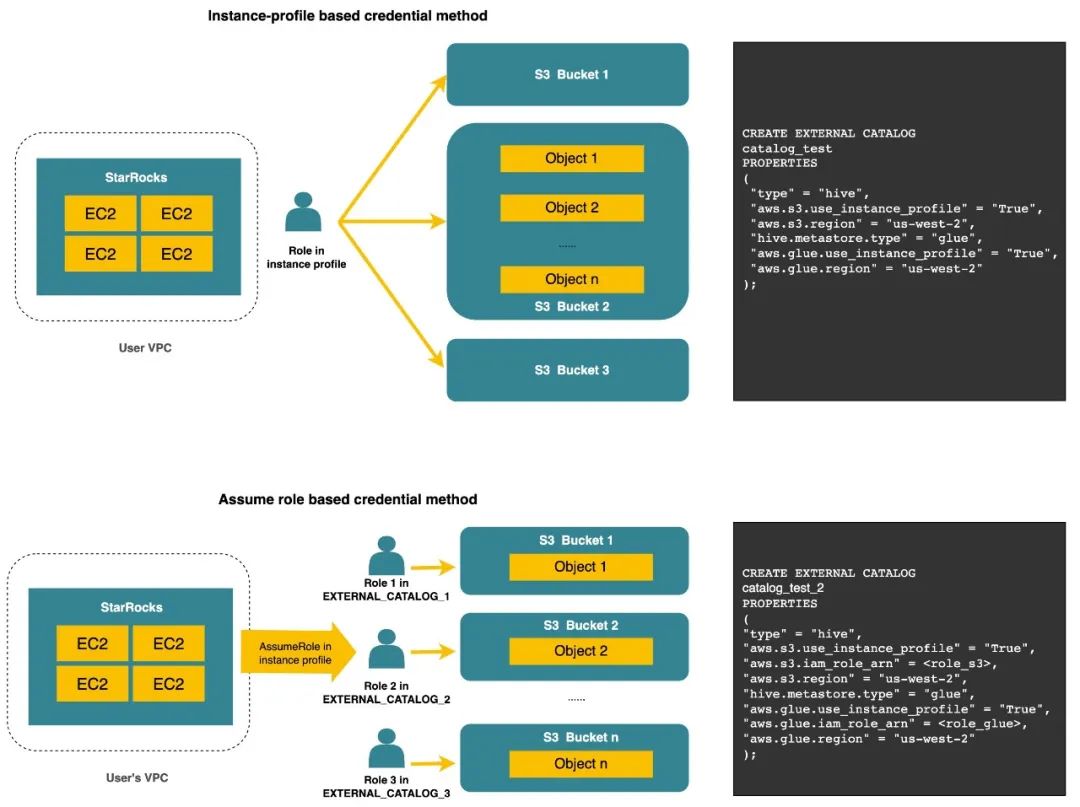
7公有云生态打通集成AWS Glue作为湖分析的Metastore,对云上数据资产进行统一分析(2.5.0发布)根据 AWS 官方文档介绍,AWS Glue 作为完全兼容 Hive metastore 的统一目录服务,为用户 Region 内的数据资产提供了统一视图,并能够在 EMR 中作为云原生的 Metastore 一键开启。这给公有云用户在 EMR 上提供了开箱即用的数据管理体验。同时,其内置的 Crawlers 功能还可以轻松的帮助 S3 文件批量生成表 Schema,赋予其 Hive table 的语义,从而对各类查询引擎的分析负载将会更加灵活友好。 StarRocks 为了给公有云用户带来更加云原生和一体化的数据分析体验,早在 2.3 版本就支持了阿里云的 Datalake formation 的集成,从 2.5.0 版本开始正式支持以 AWS Glue 作为湖分析时的 Metastore。 借助这一特性,AWS 上的 StarRocks 用户可以在 AWS Glue 里控制元数据的访问权限;也可以通过 StarRocks 湖分析能力,借助更高效的查询性能,使用 SQL 按需分析对象存储文件,同时保证了安全和数据分析效率。
深度集成AWS IAM,支持Secret key&IAM Role等多种认证方式(在2.5.X即将发布)除了性能维度,数据安全从来都是数据湖分析场景里做技术选型的重中之重。在过往积累的海内外用户案例里,我们注意到云厂商给对象存储等云资源提供了完整的认证和访问管理机制(IAM),而我们的用户也会根据不同云厂商的 IAM 产品逻辑来定义符合企业安全需求的数据访问规范。以 Amazon Cloud Service 为例,这些用户常用的云资源访问管理策略包括但不限于:
通过统一的 Access key/Secret key 来进行用户身份进行认证和鉴权
通过 IAM Role 搭配角色代理的机制,来实现不同角色身份的动态切换
借助 AWS EC2 的 Instance profile 中自带的身份信息进行认证
在未来的 V2.5.X 小版本里,StarRocks 数据湖分析将会对上述几种公有云场景用户常用的认证方式进行完备的兼容。未来 StarRocks 在公有云上的数据访问管理将会更加省心省力,数据安全不再成为企业云上 OLAP 技术选型的顾虑。
#04
Benchmark验证
—1StarRocks vs Presto(Trino)
SSB Flat on Hive
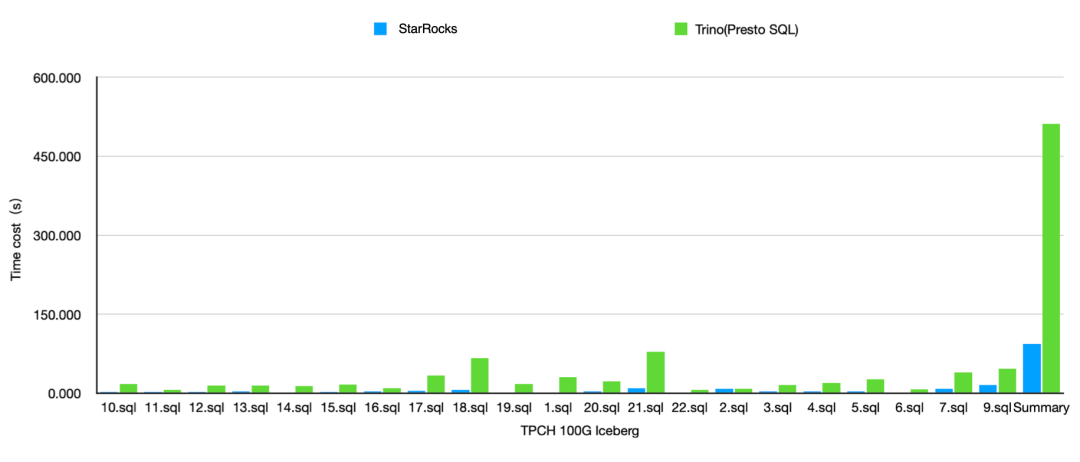
以 2.5 最新版本为基准,StarRocks 和业界最主流的湖分析引擎 Trino 367 在 100GB 的 SSBFlat 测试集(HDFS)上分别进行了查询 Hive 的性能测试对比。并行度均为 8,Cache 均未开启。
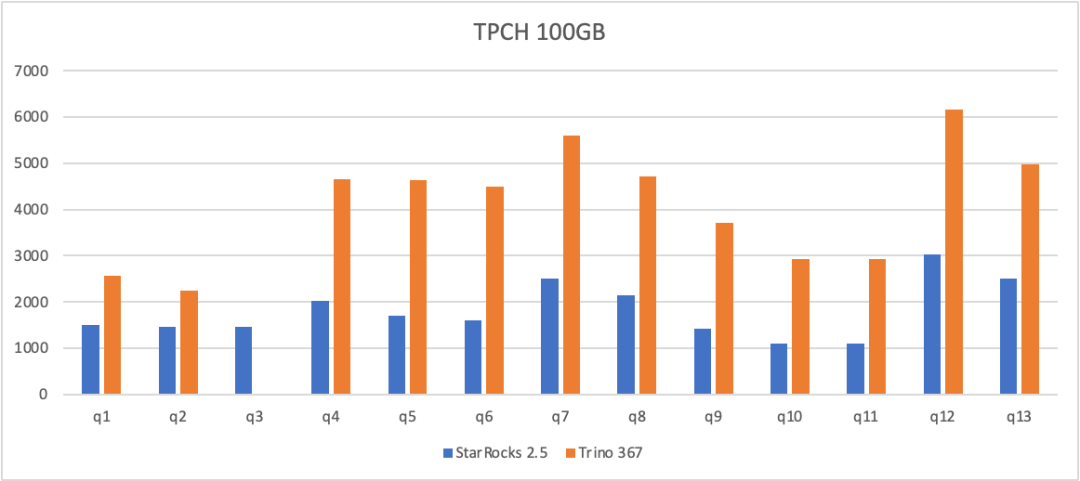
在大宽表场景下,相比 Trino,StarRocks 在 Hive 上有 2-3 倍的性能提升。
TPCH on Hudi
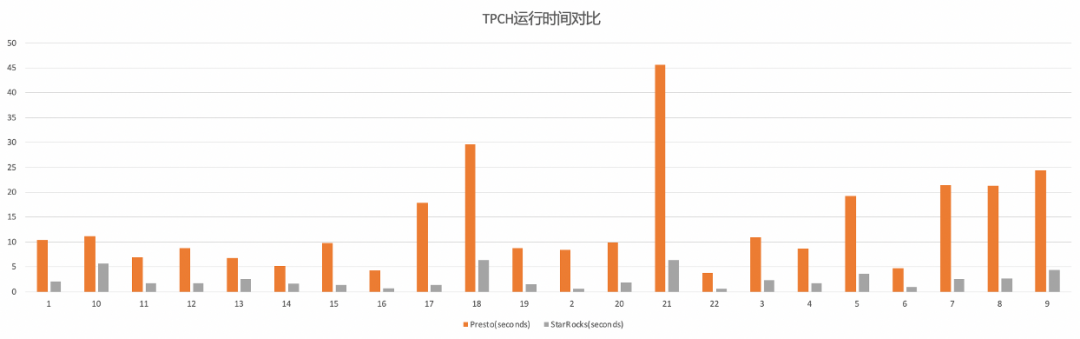
在 100GB 的 TPCH 场景下,我们还和 Presto 对比了在 COW 表上的查询性能。从图中可以看见,在 COW 表上,相比 Presto,StarRocks 的查询性能有 3-5 倍不等的稳定性能提升。
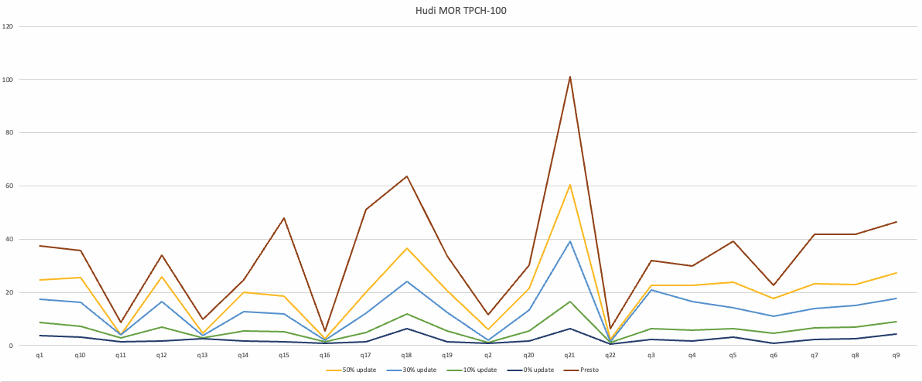
另外,我们还针对了 MOR 存在的更新场景,和 Presto 进行了一个对比实验。下图中,Presto 的场景最简单,无数据更新;而 StarRocks 查询 MOR 时候分别对比了无更新和有数据更新的场景(查询模式均为 Snapshot query)。可以观察到,面对无更新的 MOR 表,StarRocks(下图深蓝线) 整体性能能够稳定的提升 3-5 倍。在数据更新占比分别为 10%(下图绿色线)、30%(下图浅蓝线)、50%(下图黄色线)的场景中,StarRocks 在承担文件读时合并开销的前提下,查询性能依旧大幅超越 Presto(下图深红线)。
TPCH on Iceberg
在 100GB 的 TPCH 场景下,我们也和 Presto 在 Iceberg v1 format 上做了性能对比。可以观测到,平均性能整体上有 3-5 倍不等的提升。
除了在标准测试集进行的验证,StarRocks 的湖分析特性也在各类企业用户的生产环境中得到了大规模验证,帮助用户在分析效能和数据加工成本上获得了提升:
华米科技基于 StarRocks 构建了 Hive 分析平台,对接了企业内的 Superset 等 BI 工具。并维护专用 StarRocks 集群用来承接 Hive 上的查询负载,相比于原 SparkSQL,给业务分析团队极大的提升了取数分析的效率。后续关于 GlobalUDF 等特性也将助力更多的业务 SQL 平滑迁移到 StarRocks 上面来。
在汽车之家的自助分析平台场景,内部的多引擎融合分析平台选择集成了 StarRocks 来作为 Hive 的统一查询层。用真实线上业务 SQL 测试后对比 Presto 集群,根据观测结果显示,80% 的真实业务 SQL 负载有了 3 倍不等的性能提升。后续伴随关于 Map&Struct 数据类型的新特性上线,也将进一步提升 StarRocks 对业务 SQL 查询负载支持的完备程度。
腾讯游戏基于 StarRocks 在 Iceberg 数据湖上构建了存算分离的 Serverless 数据分析架构,支撑了单表 TB 级别的湖分析场景,并落地了性能和成本均衡的云原生架构方案。
理想汽车基于 StarRocks 的 Hive 外表替换了 Impala。一方面通过外表 Join 等特性缩短了数据加工的链路,同时也缓解了原 Hadoop 集群的运维压力。
#05
未来规划
—
1Table Sink in Datalake 从 2.5 版本开始,我们就会陆续强化 StarRocks 针对 Iceberg/Hudi 等主流数据湖的 Table sink 能力。借助这一能力,对于用户通过 StarRocks 探查分析得到的结果集,随时都可以通过 CREATE TABLE AS SELECT ... 的方式回写到数据湖当中,使得这些数据资产能够基于数据湖本身的 Open table format 在不同的引擎/服务之间实现自由共享,告别反复的迁移复制。2跨引擎语法兼容
不同查询引擎之间有各自的语法糖。一旦业务团队的分析行为依赖这些语法糖,那么使用 StarRocks 对 Presto/Trino 等存量系统的替换过程就变得更加繁琐。因为这涉及到业务 SQL 改写,给用户也带来了额外的困扰和成本。
为了帮助用户更加省心地实现统一湖仓分析,StarRocks 计划在系统内分阶段提供针对多种查询引擎的 Parser 插件,并帮助用户自动跨引擎的语法树自动转换。借助这个能力,用户通过 Client 连接 StarRocks 时,只需要手动指定当前会话生效的 Parser 类型,即可将其他引擎的原生 SQL 直接运行在 StarRocks 的 MPP 架构之上。既避免了 SQL 迁移改写,又可以直接享受到 StarRocks 的极速分析性能。3Azure/Google Cloud Platform集成 StarRocks 这两年产品力的进步有目共睹,国内各大云厂商也陆陆续续在 EMR 上为用户提供了 StarRocks 的托管式服务,这正是社区用户广泛呼声的最强论证。作为一个无国界、开放包容的开源社区,StarRocks 也有计划在全球公有云的复杂场景中继续深度打磨和成长。目前,StarRocks 已经和 Amazon Web Service 完成了主要的生态组件集成,并陆陆续续开始承载全球公有云用户的一些核心分析业务。未来还计划全面支持 Google Cloud Platform 和 Azure Cloud。4在物化视图上拓展增量查询语义,构建增量数据Pipeline
物化视图是连接数据湖和数据仓库的一个天然枢纽。在 Hadoop 时代,MapReduce 计算框架和 Hive format 还没有能力去识别和处理增量数据,因此整个 ETL Pipeline 还是在分区级别Scan的查询语义上构建的,这带来了时效性和计算效率低下的瓶颈。
在基于 StarRocks 构建湖仓一体架构的时候,我们就在思考:既然主流的数据湖 Table format 均能够支持访问增量数据,而物化视图又能够自动完成湖仓之间的 ETL,为什么我们不直接让整个 Pipeline 基于增量的查询语义来构建?对于增量实时入湖的场景,增量 Pipeline 既能够节约重复扫描历史数据的开销。借助增量微批的计算模型把每次计算的代价降低,从而使湖仓之间的同步和建模计算可以更加频繁,获得更高的时效性。
因此,在数据湖上拓展增量查询的语义,未来也会是物化视图支撑湖仓一体化融合的一个重要思路。5批处理能力强化 批处理能力是建模场景的基础能力,而这也正是 StarRocks 需要持续强化的地方。之前用户倾向于将数据建模好后导入 StarRocks 承接查询负载。在数据湖场景里,我们需要支撑用户能够将 ODS 层的明细数据按需进行灵活加工和处理,并写入 StarRocks 或者直接将查询结果处理后回写到湖中,批处理能力是对 MPP 架构的一个重大挑战,也是未来我们重点强化的场景之一。6外部数据细粒度权限管理 目前我们对外部数据的权限管理还停留在 Catalog 级别,这种看似简单的数据访问方式也带来了数据权限放大的隐患。在 3.0 版本后,我们将会给用户提供全新的 RBAC 权限管理模型,其中也会提供帮助用户实现 Database 和 External table 级别访问管理的全新能力。
#06
写在最后
—
自 Databricks 的论文面世,Lakehouse 成了大数据从业者津津乐道的行业蓝图。但这套架构是否能替代 Warehouse 支持当下的所有主流场景用例,显然现在下结论也许为时过早,每一个新技术在上升期过后也多多少少都会面临“跨越鸿沟”的挑战。成为一款最适合湖分析场景的产品,也远远不是做好一个 feature 这么简单。
顺着 Lakehouse 这个方向望向前方,依旧有很多的全新的挑战在等待 StarRocks。实时数仓与流式引擎的关系,表格式读取接口的开放与封闭,元数据如何实现更灵活的访问共享,这些都是我们未来需要思考和解决的问题。
从 2.1 版本开始,StarRocks 花费了大量精力来思考和探索:在数据湖时代我们能给用户带来的价值在哪里?企业工程师和社区开发者需要理解一个逻辑:采用新式数据湖架构,并不意味着我们需要彻底抛弃 MPP 数仓架构的诸多特性。如何利用 StarRocks 在优化器/计算引擎/存储引擎等诸多能力优势,帮助用户进一步释放湖上数据分析的无限想象空间,正是 StarRocks DLA 这个项目的核心价值所在。
StarRock V2.5 对 DLA 来说是一个重要转折点,我们在湖分析场景里的思路也愈加清晰。如何利用 StarRocks 更好地支持湖分析场景,助力用户完成 OLAP 层统一?敬请关注我们的社区动态和 Release Plan。
审核编辑 :李倩
-
数据
+关注
关注
8文章
7030浏览量
89034 -
API
+关注
关注
2文章
1501浏览量
62017 -
SQL
+关注
关注
1文章
764浏览量
44130
原文标题:当打造一款极速湖分析产品时,我们在想些什么
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

吉时利2450数字源表如何分析信号的频谱特性

StarRocks 与 AWS 合作持续深入,为全球245个国家企业用户提供轻量化云服务
STM32F407读取挂在FSMC上的外部ADC数据,开启DMA的Mem to Mem模式时只能读取一次FSMC数据,为什么?
阻抗分析仪的原理与特性
什么是数据湖?数据湖和数据仓库有什么区别?
巡湖护河联合执法 解决通信是关键

rc电路移相特性的观察与分析
华为推出全新数据湖解决方案及全闪存新品
工业物联网系统推动持续复苏河湖生态环境
揭秘湖仓一体:大数据演进的未来趋势与影响






 工商网监
工商网监
评论