 人工智能中训练和推理的区别是什么,需要关注哪些要点
人工智能中训练和推理的区别是什么,需要关注哪些要点
我们在学习人工智能时常会遇到训练(Training)和推理(Inference)两个概念,这是人工智能实现的两个环节。今天我们一起讨论一下以下两个问题。
训练和推理的区别是什么?
1、训练和推理的区别是什么?
训练过程:又称学习过程,是指通过大数据训练出一个复杂的神经网络模型,通过大量数据的训练确定网络中权重和偏置的值,使其能够适应特定的功能。在训练中需要调整神经网络权重以使损失函数最小,通过反向传播来执行训练以更新每层中的权重。训练过程需要较高的计算性能、需要海量的数据、训练出的网络具有一定通用性。
推理过程:又称判断过程,是指利用训练好的模型,使用新数据推理出各种结论。推理是预测或推断的过程,借助在训练中已确定参数的神经网络模型进行运算,利用输入的新数据来一次性进行分类或输出预测结果。
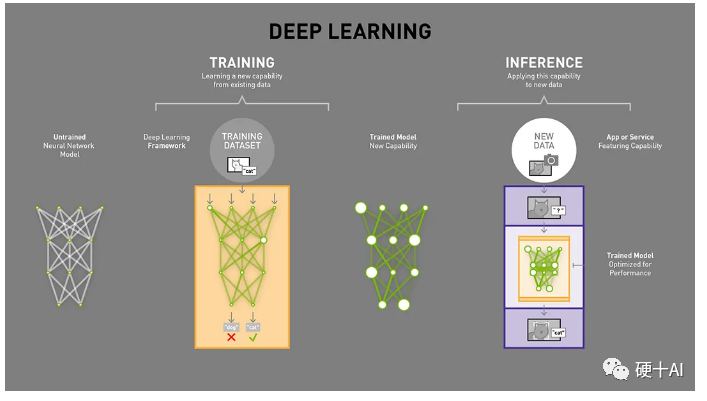
我们可以类比我们自己进行学习,并用自己学到的知识进行判断的过程。学习的过程(训练)是这样的,当我们在学校开始学习一门新学科,为了掌握大量的知识,我们必须读大量的书、专心听老师讲解,课后我们还要做大量的习题巩固自己对知识的理解,并通过考试来验证学习的结果,当我们考试通过后我们才算是完成了整个学习过程。每次考试,有的同学考分高,有的同学考分低,这个就是学习效果的差别了。当然,如果你不幸考试没有通过,还要继续重新学习,不断提升你对知识的掌握程度,直到最终通过考试为止。而判断的过程(推理)如下,我们应用所学的知识进行判断,比如你从医学专业毕业,开始了你治病救人的工作,这时候你对病人病因的判断就是你在做“推理”的工作,你诊断100个病人,其中99个你都能准确的判断出病因,大家都夸你是一个好医生,学有所成、判断准确。
综上,人工智能的这种训练过程和推理过程,和人类大脑学习过程和判断的过程非常相似。通常需要花很长时间来学习(即训练),而学会之后进行判断(即推理)的时间只需要一刹那就行了。
2、区分人工智能训练和推理芯片/产品需要关注哪些要点? 根据承担任务的不同,AI芯片/产品可以分为两类,分别是训练AI芯片和推理AI芯片,他们的主要区别是以下几点。
(1)部署的位置不一样
大量的训练芯片都在云端,即部署于数据中心内,利用海量的数据和庞大而复杂的神经网络进行模型训练,这类芯片都很复杂。目前,除了英伟达、超威、英特尔等芯片公司,谷歌等这些互联网公司都有云端训练芯片,国内华为、寒武纪还有好多初创公司也在做云端训练芯片。
很多的推理芯片也会放置在云端,数据中心中很多服务器都会配置推理用的PCIE插卡,还有大量的推理芯片用在边缘侧(各种数据中心外的设备),如自动驾驶汽车、机器人、智能手机、无人机或物联网设备,它们都是用训练好的模型进行推理。布局云端推理芯片和边缘侧推理芯片的公司更多,产品种类丰富,定制化程度也会高很多。
(2)性能要求不一样
准确度/精度要求不一样
我们从性能角度评价一个人工智能系统的效果,可以通过准确度/精度这样的指标,比如在100个样本中,能预测了 85 个样本,准确率为 85%,人工智能 算法是基于概率论和统计学的,不可能达到 100% 的预测准确率,并且实现越高的准确度需要付出越大的努力和代价越大。我们经常提到的数据精度,也会直接影响系统准确性,我们可以把数据的精度类比为照片中的像素数,像素越多则分辨率越高,同样,精度越高,表征事物越准确。提高精度也是有代价的,它需要系统提供更多的内存,并要耗费更长的处理时间,比如有数据证明采用int4精度与int8相比具有59%的加速。
实际应用中,并不是准确度越高越好或支持的数据精度越高越好,不同的应用场景对于性能指标的要求也是不一样的。以图像识别应用为例,在零售店人员跟踪中,识别经过某个过道的顾客,这种应用5% ~10%的误差是可以接受的;但是在医疗诊断或汽车视觉的等应用中,准确度的要求就要高很多,准确度低了就无法应用。总之,不同应用对于准确度和精度的容忍度是不一样的,需要我们进行权衡。
回到推理和训练产品,选择时就有很大区别,比如在边缘侧的推理产品中,由于它对准确度的要求不高,我们可能只要支持int8甚至更低的精度就可以了。但是训练产品,比如用于高性能计算(HPC)场景中,必须有能力实现高的准确度,支持的数据精度范围也需要更加丰富,比如需要支持FP32、FP64这样精度的数据。10月7日美国对我国新一期的芯片限制法案中,就有一条是对我们支持FP64计算类芯片的研发和生产进行限制。
计算量要求不一样
训练需要密集的计算,通过神经网络算出结果后,如果发现错误或未达到预期,这时这个错误会通过网络层反向传播回来(参考 机器学习中的函数(3) - “梯度下降”走捷径,“BP算法”提效率 ),该网络需要尝试做出新的推测,在每一次尝试中,它都要调整大量的参数,还必须兼顾其它属性。再次做出推测后再次校验,通过一次又一次循环往返,直到其得到“最优”的权重配置,达成预期的正确答案。如今,神经网络复杂度越来越高,一个网络的参数可以达到百万级以上,因此每一次调整都需要进行大量的计算。曾在斯坦福大学做过研究,在谷歌和百度都任职过的吴恩达这样举例“训练一个百度的汉语语音识别模型不仅需要4TB的训练数据,而且在整个训练周期中还需要20 exaflops(百亿亿次浮点运算)的算力”,训练是一个消耗巨量算力的怪兽。 推理是利用训练好的模型,使用新数据推理出各种结论,它是借助神经网络模型进行运算,利用输入的新数据“一次性”获得正确结论的过程,他不需要和训练一样需要循环往复的调整参数,因此对算力的需求也会低很多。
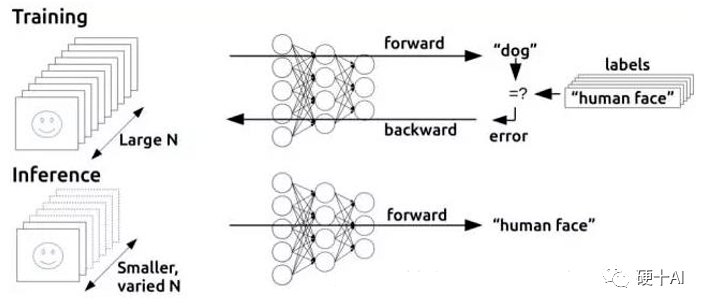
存储要求不一样
训练的时候反向调整会应用到前馈网络计算的中间结果,所以需要很大的显存,训练的芯片存储的设计和使用的方案是复杂的。训练好的模型,需要使用大量数据,大量数据要读入显存,显存带宽要足够大、时延要足够低。同时,我们在神经网络的训练中使用梯度下降算法,显存中除了加载模型参数,还需要保存梯度信息的中间状态,因此训练相比于推理,显存需求大大增加,显存足够大才能运转起来。
综上,训练和推理的芯片/产品部署的位置不一样,对于性能准确度和精度的要求不一样,对于算力能力和存储大小的要求也不一样,除了这些关键指标差异外。用于训练场景的芯片高精度、高吞吐量,因此单芯片功耗大(甚至可以达到300W),这种芯片成本也很高;用于云端推理的芯片,更加关注算力、时延等的平衡,对功耗成本也非常敏感。参考英伟达的产品,它每一代产品并没有开发专门的推理卡,其使用的是训练卡的低配版本来做推理的。但边缘测应用推理芯片,就一定要结合应用场景,做到低功耗、低成本。
3、我们如何去学习理解人工智能里的训练和推理?
要学习理解人工智能,训练和推理相关的知识是必须都要掌握的,如果你只学习了“训练”中如何搭建网络,参数调整等,那么你就无法了解结合实际应用“推理”是如何发挥作用的,接不了地气;同样,如果你只做过“推理”的操作,那么你也不能理解在实现推理判断之前,需要做哪些准备工作,进行大量的计算,才能训练出一个可用的、好的神经网络。 审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4771浏览量
100714 -
人工智能
+关注
关注
1791文章
47183浏览量
238253
原文标题:人工智能中训练和推理的区别是什么?
文章出处:【微信号:Hardware_10W,微信公众号:硬件十万个为什么】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
《AI for Science:人工智能驱动科学创新》第6章人AI与能源科学读后感
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
risc-v在人工智能图像处理应用前景分析
名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新
FPGA在人工智能中的应用有哪些?
人工智能与大模型的关系与区别
5G智能物联网课程之Aidlux下人工智能开发(SC171开发套件V2)
AI训练,为什么需要GPU?






 工商网监
工商网监
评论