 基于OpenVINO™ 2022.2与oneAPI构建GPU视频分析服务流水线
基于OpenVINO™ 2022.2与oneAPI构建GPU视频分析服务流水线
科学与技术
实时 AI 视频分析是一种基于人工智能的技术,可分析视频流以检测特定行为和事件。这种类型的系统通过人工智能机器学习引擎检查来自监控摄像头的视频流来进行相关工作。该引擎使用一系列深度学习算法和程序来理解数据,并将数据转换为可理解的、有意义的信息。
以车辆检测这是任务为例,我们可以把 AI 视频分析分为以下几个通用步骤:
1.视频流拉流
2.媒体解码
3.图像前处理缩放
4.深度学习推理,识别车辆
5.后处理画框
6.媒体编码传输
7.分析结果可视化呈现
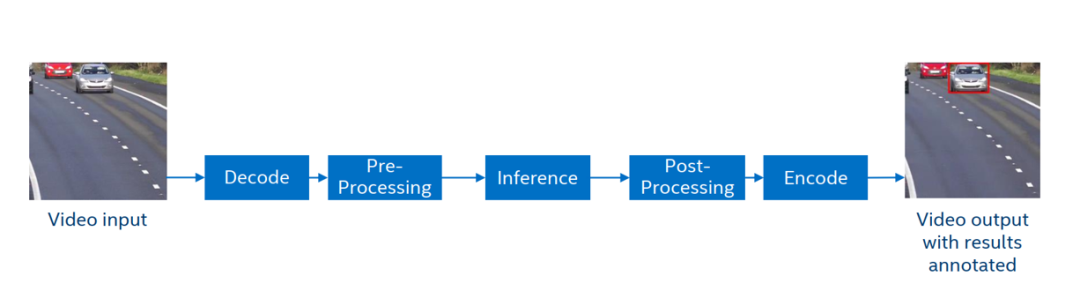
图:通用 AI 视频分析流程
随着边缘计算技术的日渐成熟,我们逐步将 AI 算力与分析服务下沉到边缘设备侧,以获取更好的实时性,并减少视频流传输对于带宽资源的占用。此时,AI Box 边缘计算设备将作为媒体数据分析的核心节点,直接接入并读取 IP 摄像头编码后的视频流数据,进行实时的解码和推理工作,并将结果数据推送至后端机房。后续配合视频监控服务机完成对推理结果的后处理分析与告警,以及将编码后的事件关键帧留存,以供人工追溯。
鉴于边缘测的算力资源有限,大家不难发现这个流程中性能的瓶颈往往会发生在 AI Box 的视频解码或者是推理任务中。同时出于方案成本的考虑,我们也希望可以用相同的硬件资源,接入更多路的视频流分析业务,因此如何进一步优化这部分的工作流程,便成为了本示例希望分享的核心重点。
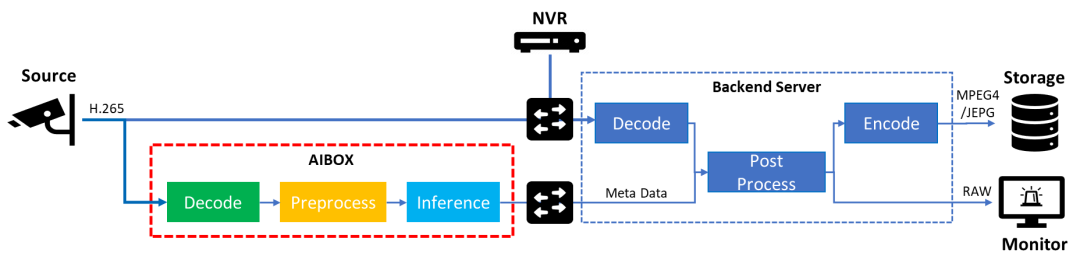
图:边缘 AI 视频分析架构
1.OpenVINO工具套件简介
用于高性能深度学习的英特尔发行版 OpenVINO工具套件基于 oneAPI 而开发,以期在从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO工具套件可赋能开发者在现实世界中部署高性能应用程序和算法。
在推理后端,得益于 OpenVINO 工具套件提供的“一次编写,随处部署”特性,转换后的模型能够在不同的英特尔硬件平台上运行,无需重新构建,有效简化了构建与迁移过程。此外,为了支持更多的异构加速单元,OpenVINO 工具套件的 runtime api 底层采用了插件式的开发架构,基于 oneAPI 中的 MKL-DNN、oneDNN 等函数计算加速库,针对通用指令集进行优化,为不同的硬件执行单元分别实现了一套完整的高性能算子库,提升模型在推理运行时的整体性能表现。
这里值得提一句的是,目前 OpenVINO 2022.2版本可以直接支持英特尔最新的独立显卡产品(dGPU)执行推理任务。
可以参考文章:
官宣:支持英特尔独立显卡的OpenVINO 2022.2新版本来啦
2. 英特尔 oneAPI 简介
英特尔 oneAPI 是一项行业倡议,旨在创建一个开放、基于标准的跨架构编程模型,在面对大量跨各种架构(CPU、GPU、FPGA 和其他加速器)的工作负载时简化开发工作。它包括跨架构语言 Data Parallel C ++(基于 ISO C ++ 和 Khronos Group 的 SYCL)、高级库和社区扩展。许多公司、研究机构和大学均支持 oneAPI。
作为 oneAPI 中最重要的高级库组件之一,oneVPL (Intel oneAPI Video Processing Library)可以在英特尔的 CPU、GPU 等硬件平台上实现对视频数据的解码,编码与处理功能,支持 AVI,H.256 (HEVC),H.264 (AVC),MPEG-2,VP9 等多种媒体标准的硬件解码能力。目前 oneVPL 已经适配以下型号的 GPU 硬件:
11thgeneration Intel Core processors with XeArchitecture GPUs
Intel Iris XeMAX
Intel Arc A-series graphics
Intel Data Center GPU Flex Series
Upcoming GPU platforms
更多关于英特尔硬件编解码格式的支持可以参考
任务开发流程
该方案将依托于英特尔的 GPU 设备执行视频分析业务,主要有以下几个原因:
通常情况下,在性能和功耗等方面,相较 CPU 的软解码,GPU 中专用编解码器往往可以提供更强大的硬件解码能力,输入视频的分辨率越高,这里的性能差异也越明显。
此外鉴于 GPU 设备在并行能力上的优势,OpenVINO在调用英特尔最新的集成显卡 iGPU 和独立显卡 dGPU 推理时,也能发挥出比较优异的吞吐量表现。
最后调用 GPU 推理也能最大化提升英特尔架构的资源利用率,在边缘计算的任务架构中,系统不需要 GPU 来处理图像的渲染业务,而 CPU 往往需要承担更多资源调度方面的工作,通过将视频分析任务搬运到 CPU 自带的集成显卡中,不光能充分利用这部分闲置的资源,并且可以减轻 CPU 上的工作负载,进一步优化方案成本。
因此我们要确保在整个视频流分析链路中,中间数据可以被“保留”在 GPU 的内存中,避免与 host 之间额外的传输开销,同时也减少在同一设备中的数据搬运,也就是所谓的“零拷贝”,从而实现 GPU 处理性能的最大化。
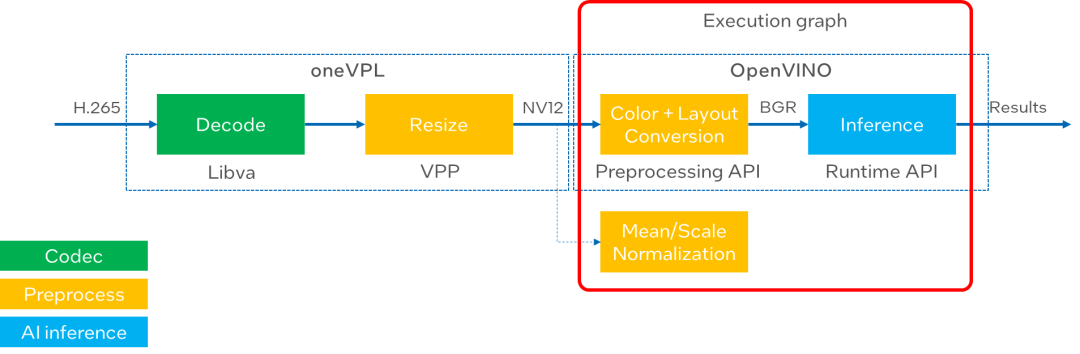
图:GPU 视频分析流水线
接下来我们就通过一个简单的单通道示例,还看下如何优化 GPU 上的视频分析服务。在这个示例中,输入数据是一段 H.265 的视频文件,我们可以把整个流水线分成以下4个部分,分别对应 oneVPL 和 OpenVINO工具套件中不同的组件接口。
1.视频解码 (Libva)
oneVPL依赖于Libva库,通过对VA-API (Video Acceleration API)接口的上层封装,实现了 GPU 硬件编解码能力。在这个示例中关于解码部分可以有以下几个步骤被抽象出来:
利用 MFXVideoDECODE_Init 接口,通过 oneVPL session 初始化解码模块:
sts = MFXVideoDECODE_Init(session, &mfxDecParams);
向右滑动查看完整代码
读取视频流,并封装到 bitstream buffer 中:
sts = ReadEncodedStream(bitstream, source);
向右滑动查看完整代码
调用 MFXVideoDECODE_DecodeFrameAsync 接口执行解码任务,将解码后的数据写入 pmfxDecOutSurfac 地址
sts=MFXVideoDECODE_DecodeFrameAsync(session, (isDrainingDec)?NULL:&bitstream, NULL, &pmfxDecOutSurface, &syncp);
向右滑动查看完整代码
2.图像缩放(VPP):
接下来使用 oneVPL 中的 VPP(Video processing functions)模块来实现对于图像的缩放处理,首先我们需要定义一些关键参数,例如输出图像的色彩通道与缩放后的图像尺寸,这里为了能实现编码输出与推理输入的零拷贝共享,我们需要将输出的色彩格式设置为 NV12:
mfxVPPParams.vpp.Out.FourCC = MFX_FOURCC_NV12; mfxVPPParams.vpp.Out.ChromaFormat=MFX_CHROMAFORMAT_YUV420; mfxVPPParams.vpp.Out.Width=ALIGN16(vppOutImgWidth); mfxVPPParams.vpp.Out.Height=ALIGN16(vppOutImgHeight);
向右滑动查看完整代码
利用 MFXVideoVPP_Init 接口,初始化 VPP 模块:
sts = MFXVideoVPP_Init(session, &mfxVPPParams);
向右滑动查看完整代码
将解码后的输出数据地址送入 MFXVideoVPP_ProcessFrameAsync 接口,进行图像缩放处理,并以指定的色彩通道输出:
MFXVideoVPP_ProcessFrameAsync(session, pmfxDecOutSurface, &pmfxVPPSurfacesOut);
向右滑动查看完整代码
3.色彩空间与数据排布转换(OpenVINO Preprocessing API):
Preprocessing API 是OpenVINO 2022.1版本中新增加的一个功能,可以实现将一些常规的前处理操作以 node 节点的形式集成到OpenVINO模型的 runtime 执行图中,从而实现将这部分计算过程加载到指定的硬件平台进行执行,同时利用 OpenVINO 强大的模型加速能力,提升前处理任务性能,这里可以被支持的前处理任务包含:
精度转换:U8 buffer to FP32
Layout转换:Transform to planar format: from {1, 480, 640, 3} to {1, 3, 480, 640}
Resize :640x480 to 224x224
色彩空间转换:BGR->RGB
Normalization:mean/scale
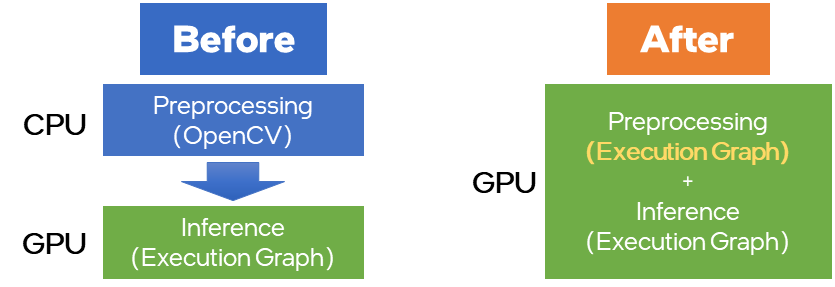
图:Preprocessing API 功能示意
这里我们将部分 VPP 不支持的前处理算子,通过 Preprocessing API 的方式将他们放到 GPU 上去执行,一方面可以减少 CPU 上任务的负载,一方面可以避免额外的 Device to Host 内存拷贝。查询 Open Model Zoo 的预训练模型说明可知,本示例用到车辆检测模型的输入数据通道要求为 BGR,数据排布为 NCHW,因此在调用 Preprocessing API 时,我们需要实现这两种格式的转换:

图:vehicle-detection-0200 模型输入要求说明
回到代码部分,我们调用 pre_post_process 头文件中的相应函数实现对 VPP 输出数据的色彩空间转换(YUV->BGR)和排布转换(NHWC->NCHW),并且最终通过 build 方法,将这部分前处理任务集成到原始模型的执行图中,生成新的 model 对象:
autop=PrePostProcessor(model); p.input().tensor().set_element_type(ov::u8) //YUVimagescanbesplitintoseparateplanes .set_color_format(ov::NV12_TWO_PLANES,{"y","uv"}) .set_memory_type(ov::surface); //Changecolorformat p.input().preprocess().convert_color(ov::BGR);//Changelayout p.input().model().set_layout("NCHW"); model=p.build();
向右滑动查看完整代码
此处,NV12 会被拆分为 Y 和 UV 两个分量,如果不执行 NCHW 的转换,运行时会由于通道维度不匹配而报错。
4. 模型推理(OpenVINO runtime):
为了实现零拷贝的诉求,该示例中用到的 OpenVINO的“Remote Tensor API of GPU Plugin”相关接口,以实现与 VA-API 组件对于 GPU 内存中视频数据的共享。具体步骤如下:
创建 GPU 中共享内存的上下文:
auto shared_va_context = ov::VAContext(core, lvaDisplay);
向右滑动查看完整代码
获取VPP输出结果的句柄,并通过 create_tensor_nv12 接口将 VA-API surface 转化并封装成 OpenVINO的 tensor 内存对象:
lvaSurfaceID=*(VASurfaceID*)lresource; //WrapVPPoutputintoremoteblobsandsetitasinferenceinput autonv12_blob=shared_va_context.create_tensor_nv12(height,width,lvaSurfaceID);
向右滑动查看完整代码
在推理请求中载入该内存对象,并执行推理:
infer_request.set_tensor(new_input0->get_friendly_name(),nv12_blob.first); infer_request.set_tensor(new_input1->get_friendly_name(),nv12_blob.second); //startinferenceonGPU infer_request.start_async(); infer_request.wait();
向右滑动查看完整代码
可以发现,不同于原始模型,这里输入数据变成两份,原因是在上一步调用 Preprocessing API 的过程中,我们将 NV12 还原到 Y 和 UV 两个分量,所以原始模型的输入数据数也要做相应调整。
参考示例使用方法
本示例已在 Ubuntu20.04 及第十一代英特尔酷睿 iGPU 及A RCA380dGPU 环境下进行了验证。
1.下载示例 
2.安装相应组件和依赖
可以参考该示例仓库中的README文档进行环境安装:
https://github.com/OpenVINO-dev-contest/decode-infer-on-GPU
3.下载预训练模型
这个示例中我们用到了 Open Model Zoo 的 vehicle-detection-0200 模型用于对视频流中的车辆进行检测,具体下载命令如下:
 4.编译并执行推理任务
4.编译并执行推理任务

5.运行输出
最终效果如下:
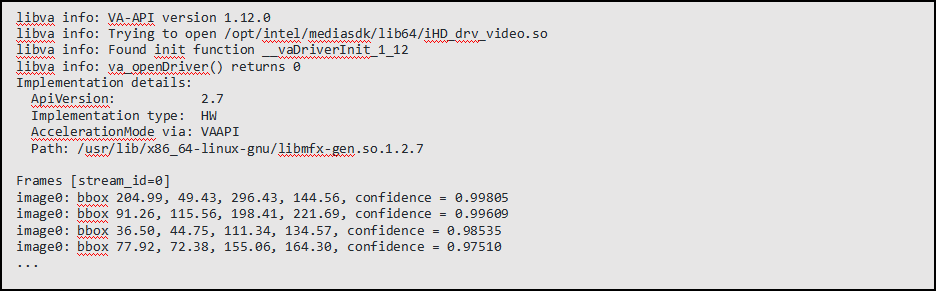
该示例会输出每一帧画面中被检测到车辆的置信度,以及在画面中的坐标信息等。
结论
利用 oneAPI 的 oneVPL 组件,以及 OpenVINO的 Preprocessing API 和 remote tensor 接口,我们可以在英特尔 GPU 硬件单元上构建从解码,前处理,推理的视频分析全流程应用,且没有额外的内存拷贝,大大提升对 GPU 资源的利用率。随着越来越多的英特尔独立显卡系列产品的推出,相信这样一套参考设计帮助开发者在 GPU 平台上实现更出色的性能表现。
审核编辑:汤梓红
-
英特尔
+关注
关注
61文章
10070浏览量
172832 -
gpu
+关注
关注
28文章
4828浏览量
129744 -
AI
+关注
关注
87文章
32369浏览量
271473 -
人工智能
+关注
关注
1799文章
48061浏览量
241999 -
视频分析
+关注
关注
0文章
30浏览量
10895
原文标题:基于OpenVINO™ 2022.2与oneAPI构建GPU视频分析服务流水线
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
利用OpenVINO和LlamaIndex工具构建多模态RAG应用

为什么无法在RedHat中构建OpenVINO™ 2022.2?
周期精确的流水线仿真模型
浅谈GPU的渲染流水线实现
FPGA之流水线练习(3):设计思路
FPGA之为什么要进行流水线的设计
各种流水线特点及常见流水线设计方式
如何选择合适的LED生产流水线输送方式
嵌入式_流水线






 工商网监
工商网监
评论