 7个强大实用的Python机器学习库!
7个强大实用的Python机器学习库!
我们总说“不要重复发明轮子”,python 中的第 3 方工具库就是最好的例子。借助它们,我们可以用简单的方式编写复杂且耗时的代码。在本篇内容中给大家整理了 7 个有用的 Python 库,如果大家从事机器学习工作,一定要来一起了解一下。1.Prophet
Prophet是 Facebook 开源的时间序列预测工具库,基于 Stan 框架,可以自动检测时间序列中的趋势、周期性和节假日效应,并根据这些信息进行预测。这个库在 GitHub 上有超过 15k 星。
 Prophet 通常用于预测未来几个月、几年或几十年的时间序列数据,例如销售额、市场份额等。它提供了 Python 和 R 两个版本,可以跨平台使用,支持 CPU 和 GPU 的并行运算。Prophet 的输入数据格式要求是一个包含时间戳和目标值的数据框,并支持给定时间范围、预测期限和宽限期等参数进行预测。Prophet 对缺失数据和趋势变化很稳健,通常可以很好地处理异常值。
Prophet 通常用于预测未来几个月、几年或几十年的时间序列数据,例如销售额、市场份额等。它提供了 Python 和 R 两个版本,可以跨平台使用,支持 CPU 和 GPU 的并行运算。Prophet 的输入数据格式要求是一个包含时间戳和目标值的数据框,并支持给定时间范围、预测期限和宽限期等参数进行预测。Prophet 对缺失数据和趋势变化很稳健,通常可以很好地处理异常值。
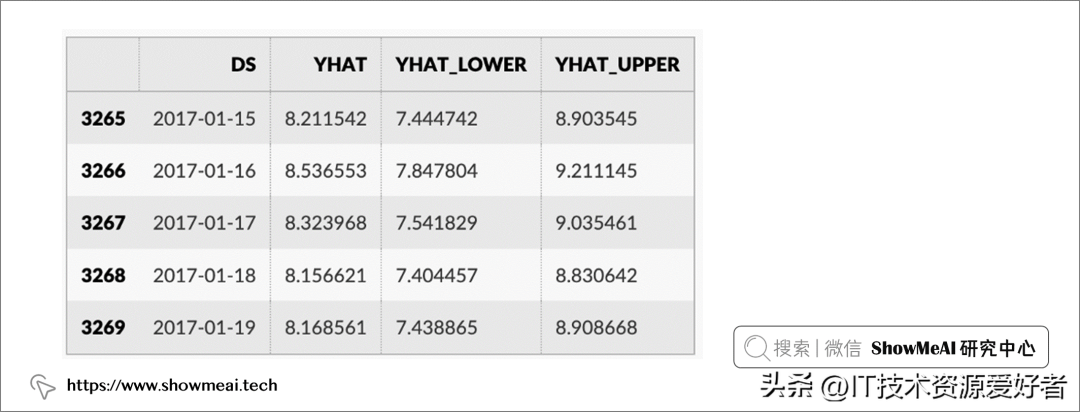
# Pythonforecast = m.predict(future)forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
2.Deep Lake
Deep Lake是一种数据集格式,提供简单的 API 以用于创建、存储和协作处理任何规模的 AI 数据集。这个库在 GitHub 上有超过 5k 星。 Deep Lake 的数据布局可以在大规模训练模型的同时,实现数据的快速转换和流式传输。谷歌、Waymo、红十字会、牛津大学等都在使用 Deep Lake。
Deep Lake 的数据布局可以在大规模训练模型的同时,实现数据的快速转换和流式传输。谷歌、Waymo、红十字会、牛津大学等都在使用 Deep Lake。
for epoch in range(2): running_loss = 0.0 for i, data in enumerate(deeplake_loader): images, labels = data['images'], data['labels'] # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(images) loss = criterion(outputs, labels.reshape(-1)) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 100 == 99: #print every 100 mini-batches print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100)) running_loss = 0.0
3.Optuna
Optuna 是一个自动机器学习超参数调优工具,可以帮助用户通过使用各种规则自动调整机器学习模型的超参数,以提高模型的性能。这个库在 GitHub 上拥有超过 7k 颗星。

import ... # Define an objective function to be minimized.def objective(trial): # Invoke suggest methods of a Trial object to generate hyperparameters regressor_name = trial.suggest_categorical('regressor',['SVR', 'RandomForest']) if regressor_name = 'SVR': svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True) regressor_obj = sklearn.svm.SVR(C=svr_c) else: rf_max_depth = trial.suggest_int('rf_max_depth', 2, 332) regressor_obj = sklearn.ensemble.RandomForestRegressor(max_depth=rf_max_depth) X, y = sklearn.datasets.fetch_california_housing(return_X_y=True) X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X, y, random_state=0) regressor_obj.fit(X_train, y_train) y_pred = regressor_obj.predict(X_val) error = sklearn.metrics.mean_squared_error(y_val, y_pred) return error # An objective value linked with the Trial object. study = optuna.create_study() # Create a neW studystudy.optimize(objective, n_trials=100) # Invoke opotimization of the objective function
4.pycm
pycm是一个用于计算二分类和多分类指标的 Python 库。这个库在 GitHub 上有超过 1k 星。

它可以计算多种常用的指标,包括准确率、召回率、F1值、混淆矩阵等。此外,pycm 还提供了一些额外的功能,例如可视化混淆矩阵、评估模型性能的指标来源差异等。pycm是一个非常实用的库,可以帮助快速评估模型的性能。
from pycm import *y_actu = [2, 0, 2, 2, 0, 1, 1, 2, 2, 0, 1, 2] y_pred = [0, 0, 2, 1, 0, 2, 1, 0, 2, 2, 2, 2] cm = ConfusionMatrix(actual_vector=y_actu, predict_vector=y_pred) cm.classes cm.print_matrix() cm.print_normalized_matrix()
5.NannyML
NannyML是一个开源的 Python 库,允许估算部署后的模型性能(而无需访问目标),检测数据漂移,并智能地将数据漂移警报链接回模型性能的变化。这个库在 GitHub 上有超过 1k 星。

为数据科学家设计的 NannyML 具有易于使用的交互式可视化界面,目前支持所有表格式的用例(tabular use cases)、分类(classification)和回归(regression)。NannyML 的核心贡献者研发了多种用于估算模型性能的新算法:基于信心的性能估算(CBPE)与直接损失估算(DLE)等。NannyML 通过构建“性能监控+部署后数据科学”的闭环,使数据科学家能够快速理解并自动检测静默模型故障。通过使用 NannyML,数据科学家最终可以保持对他们部署的机器学习模型的完全可见性和信任。
import nannyml as nmlfrom IPython.display import display # Load synthetic data reference, analysis, analysis_target = nml.load_synthnetic_binary_classification_dataset()display(reference.head())display(analysis.head()) # Choose a chunker or set a chunk sizechunk size = 5000 # initialize, specify required data columns,, fit estimator and estimateestimator = nml.CBPE( y_pred_proba='y_pred_proba', y_pred='y_pred', y_true='work_home_actual', metrics=['roc_auc'], chunk_size=chunk_size, problem_type='classification_binary',)estimator = estimator.fit(reference)estimated_performance = estimator.estimate(analysis) # Show resultsfigure = estimated_performance.plot(kind='performance', metric='roc_auc', plot_reference=True)figure.show()
6.ColossalAI
ColossalAI是一个开源机器学习工具库,用于构建和部署高质量的深度学习模型。这个库在 GitHub 上有超过 6.5k 星。

ColossalAI 提供了一系列预定义的模型和模型基础架构,可用于快速构建和训练模型。它还提供了一系列工具,用于模型评估,调优和可视化,以确保模型的高质量和准确性。此外,ColossalAI 还支持部署模型,使其能够通过各种不同的接口与其他系统集成。ColossalAI 的优势在于它易于使用,可以为数据科学家和机器学习工程师提供快速和有效的方法来构建和部署高质量的大型模型。
from colossalai.logging import get_dist_loggerfrom colossalai.trainer import Trainer, hooks # build components and initialize with colossaalai.initialize... # create a logger so that trainer can log on thhe consolelogger = get_dist_logger() # create a trainer objecttrainer = Trainer( engine=engine, logger=logger)
7.emcee
emcee是一个开源的 Python 库,用于使用 Markov chain Monte Carlo(MCMC)方法进行模型拟合和参数估计。这个库在 GitHub 上有超过 1k 星。
import numpy as npimport emcee def log_prob(x, ivar): return -0.5 * np.sum(ivar * x ** 2) ndim, nwalkers = 5, 100 ivar = 1./np.random.rand(ndim)p0 = np.random.randn(nwalkers, ndim) sampler = emcee.EnsembleSampler(nwalkers, ndim, log_prob, args=[ivar])sampler.run_mcmc(p0, 10000)
总结
以上就是给大家做的工具库介绍,这7个工具库都是非常有用的,对于机器学习工作者来说,它们可以大大提高工作效率,让你能够在简单的方式下编写复杂的代码。所以,如果你还没有了解这些工具库的话,不妨花一点时间来了解一下。
-
机器学习
+关注
关注
66文章
8461浏览量
133438 -
python
+关注
关注
56文章
4813浏览量
85318 -
GitHub
+关注
关注
3文章
477浏览量
16881
原文标题:【推荐】7个强大实用的Python机器学习库!
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
传统机器学习方法和应用指导

一个月速成python+OpenCV图像处理






 工商网监
工商网监
评论