 芯片设计挑战:SRAM缩放速度变慢
芯片设计挑战:SRAM缩放速度变慢
几乎所有处理器都依赖某种形式的 SRAM 缓存。缓存作为一种高速存储解决方案,由于其紧邻处理核心的战略位置,访问时间非常快。拥有快速且可访问的存储可以显着提高处理性能,并减少核心工作所浪费的时间。 在第 68 届年度 IEEE 国际 EDM 会议上,台积电揭示了 SRAM 缩放方面的巨大问题。该公司正在为 2023 年开发的下一个节点 N3B 将包括与其前身 N5 相同的 SRAM 晶体管密度,后者用于 AMD 的Ryzen 7000 系列等 CPU 。 目前正在为 2024 年开发的另一个节点 N3E 并没有好多少,其 SRAM 晶体管尺寸仅减少了 5%。
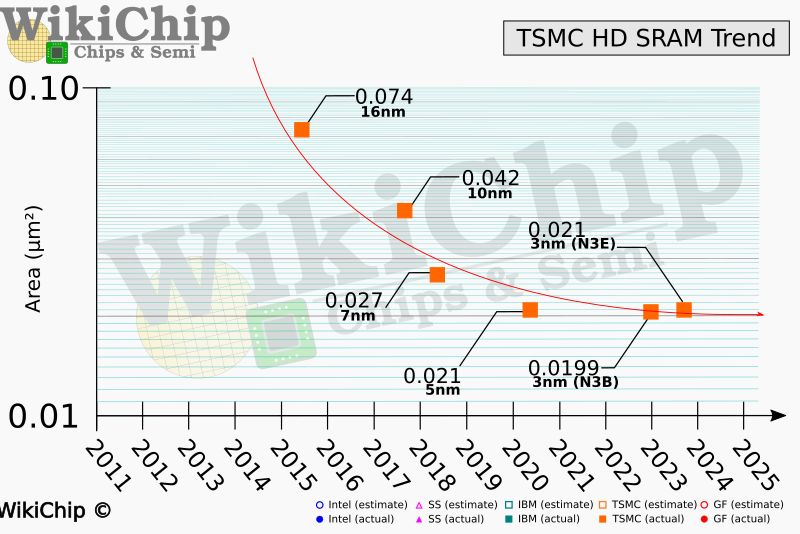
根据 WikiChip 的一份报告,讨论了半导体行业中 SRAM 收缩问题的严重性。台积电的 SRAM Scaling 已经大幅放缓。台积电报告说,尽管逻辑晶体管密度继续缩小,但其 SRAM 晶体管的缩放比例已经完全趋于平稳,以至于 SRAM 缓存在多个节点上保持相同的大小。它会迫使处理器 SRAM 缓存在微芯片芯片上占用更多空间。这反过来可能会增加芯片的制造成本,并阻止某些微芯片架构变得尽可能小。 对于未来的 CPU、GPU 和 SoC 来说,这是一个主要问题,由于 SRAM 单元面积缩放缓慢,它们可能会变得更加昂贵。
SRAM 缩放速度变慢
台积电在今年早些时候正式推出其 N3 制造技术时表示,与其 N5(5 纳米级)工艺相比,新节点的逻辑密度将提高 1.6 倍和 1.7 倍。它没有透露的是,与 N5 相比,新技术的 SRAM 单元几乎无法缩放。根据 WikiChip,它从台积电在国际电子设备会议 (IEDM) 上发表的一篇论文中获得信息TSMC 的 N3 具有 0.0199µm² 的 SRAM 位单元尺寸,与 N5 的 0.021µm²SRAM 位单元相比仅小约 5%。改进后的 N3E 变得更糟,因为它配备了 0.021 µm² SRAM 位单元(大致相当于 31.8 Mib/mm²),这意味着与 N5 相比根本没有缩放。 同时,英特尔的 Intel 4(最初称为 7nm EUV)将 SRAM 位单元大小从 0.0312µm² 减少到 0.024µm²,对于 Intel 7(以前称为 10nm Enhanced SuperFin),我们仍在谈论 27.8 Mib/mm ²,这有点落后于 TSMC 的 HD SRAM 密度。 此外, WikiChip 回忆起 Imec 的演示文稿,该演示文稿显示在带有分支晶体管的“超过 2nm 节点”上的 SRAM 密度约为 60 Mib/mm²。这种工艺技术还需要数年时间,从现在到那时,芯片设计人员将不得不开发具有英特尔和台积电宣传的 SRAM 密度的处理器。
现代芯片中的 SRAM 负载
现代 CPU、GPU 和 SoC 在处理大量数据时将大量 SRAM 用于各种缓存,从内存中获取数据效率极低,尤其是对于各种人工智能 (AI) 和机器学习 (ML) 工作负载。但是现在即使是智能手机的通用处理器、图形芯片和应用处理器也带有巨大的缓存:AMD 的 Ryzen 9 7950X 总共带有 81MB 的缓存,而 Nvidia 的 AD102 使用至少 123MB 的 SRAM 用于 Nvidia 公开披露的各种缓存。 展望未来,对缓存和 SRAM 的需求只会增加,但对于 N3(将仅用于少数产品)和 N3E,将无法减少 SRAM 占用的裸片面积并降低新的更高成本节点与 N5 相比。从本质上讲,这意味着高性能处理器的裸片尺寸将会增加,它们的成本也会增加。同时,就像逻辑单元一样,SRAM 单元也容易出现缺陷。在某种程度上,芯片设计人员将能够通过 N3 的 FinFlex 创新(在一个块中混合和匹配不同种类的 FinFET 以优化其性能、功率或面积)来减轻更大的 SRAM 单元。 台积电计划推出其密度优化的 N3S 工艺技术,与 N5 相比,该技术有望缩小 SRAM 位单元的尺寸,但这将在 2024 年左右发生,我们想知道这是否会为 AMD、Apple 设计的芯片提供足够的逻辑性能,英伟达和高通。
缓解措施
在成本方面缓解 SRAM 区域扩展放缓的方法之一是采用多小芯片设计,并将较大的缓存分解为在更便宜的节点上制造的单独裸片。这是 AMD 对其 3D V-Cache 所做的事情,尽管原因略有不同。另一种方法是使用替代内存技术,如 eDRAM 或 FeRAM 用于缓存,尽管后者有其自身的特点。 无论如何,在未来几年,基于 FinFET 节点的 3nm 及更高节点的 SRAM 缩放速度放缓似乎是芯片设计人员面临的主要挑战。
编辑:黄飞
-
台积电
+关注
关注
44文章
5710浏览量
167119 -
cpu
+关注
关注
68文章
10926浏览量
213347 -
gpu
+关注
关注
28文章
4799浏览量
129526 -
sram
+关注
关注
6文章
769浏览量
114963
原文标题:停止SRAM微缩,意味着更昂贵的CPU和GPU
文章出处:【微信号:ICViews,微信公众号:半导体产业纵横】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
开源芯片系列讲座第24期:基于SRAM存算的高效计算架构

CV3600数字+模拟转数字+模拟带帧率和分辨率缩放的音视频转换芯片

电机速度变慢跟什么有关联
stm8s003/stm8s005单片机控制的电机,当电机转起来时,用手一捏住光感线,电机速度就变慢了或是停下,为什么?
STM32L492 DMA多通道复用后速度变慢是什么原因导致的?
STM32F103定时器变慢的原因?怎么解决?
Microchip推出容量更大、速度更快的串行SRAM产品线

STM32上电启动后,会有几率出现程序运行速度变慢的现象,是为什么?
Microchip推出容量更大、速度更快的串行 SRAM产品线
芯片新战场,EDA如何拥抱新挑战?

SRAM CLA和SRAM有什么区别





 工商网监
工商网监
评论