 世界杯融入词库的位置编码方法介绍
世界杯融入词库的位置编码方法介绍

本文的开头还是从最近爆火的世界杯开始说起,以当下最火的“世界杯阿根廷战胜墨西哥”来说。如果我们一个字符一个字符的获取到embedding,势必NER的效果会很差,但是如果我们能够让模型知道,世界杯、阿根廷、墨西哥分别是三个实体的名字,尤其是在位置编码中“暗示”给模型,会有很好的效果。
上次的分享,主要集中在词语的Embedding方式,这种方式在工业界非常的好用,简单而且有效果。实际上对于算法工程师来说,处理好数据、特征,往往也是对自己能力的重大考验。接下来我们分析一下子NER知识融合的另一种方式,在模型中嵌入知识的表达:
FLAT: Chinese NER Using Flat-Lattice Transformer | 复旦大学| ACL 2020
介绍
近年来,汉字“格”结构被证明是一种有效的中文命名实体识别方法,格子结构被证明对利用词信息和避免分词的错误传播有很大的好处。那么接下来的问题是,什么是汉字格子?Lattice这个单词正是格子的意思,NER任务尝试引入这种类似“格子”的数据来增加NER词汇的容量。
实际上在NER任务中,格是一个有向无环图,其中每个节点都是一个字符或一个潜在的字,可以参考图1a。格子包括句子中的一系列字符和可能的单词。它们不是按顺序排列的,单词的第一个字符和最后一个字符决定了它的位置。汉字格中的一些词可能对NER很重要。举例来说,第一个格子就是“重庆”,也即是从“重”到“庆”。写到这里,读者可能会问,为什么不直接弄成格子呢?例如一个n*n的矩阵?可以是可以的,但是势必会增加内存开销,这点在GPU上的体现很明显。
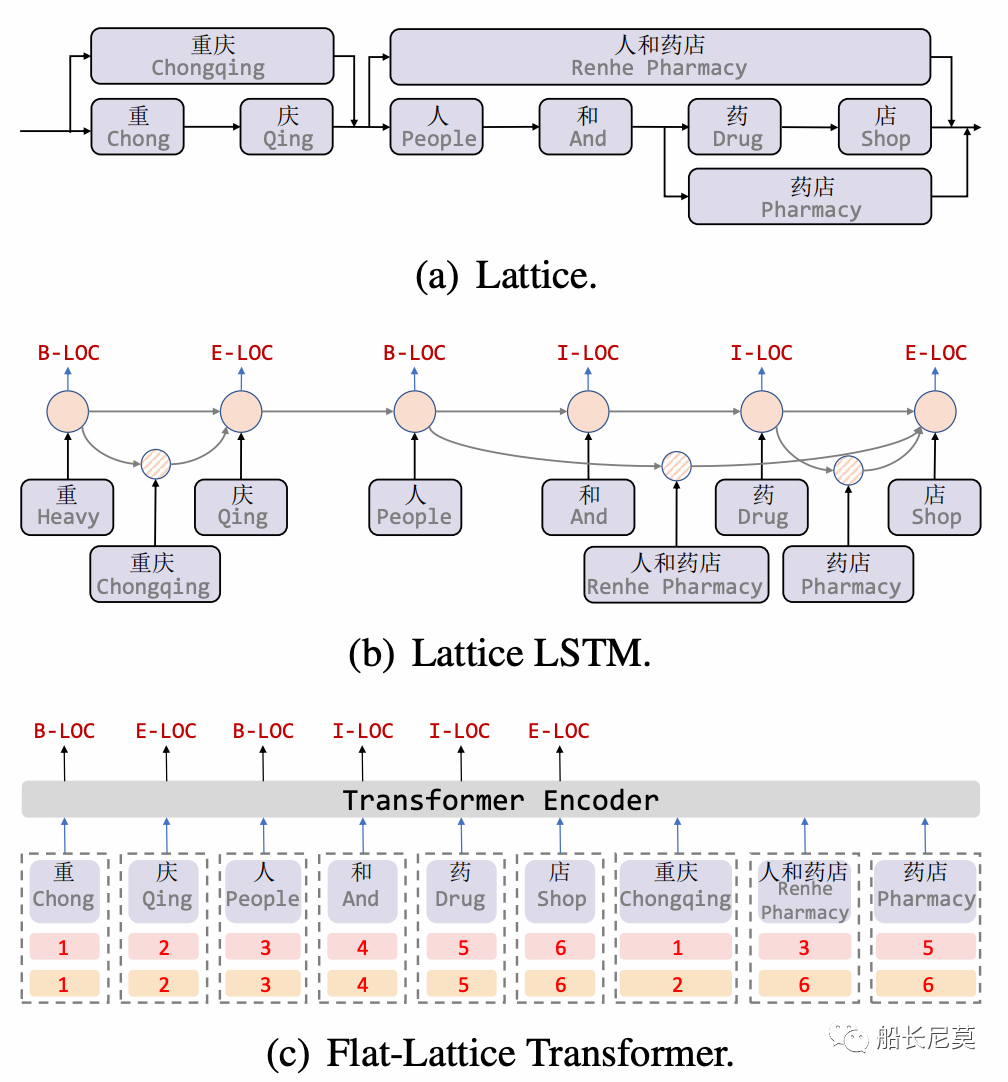
图1:a 为格子的概念图,b为模型Lattice LSTM的结构图,c为本文的模型图
之前的论文,为了适应格子结构,提出了Lattice LSTM,这种方式无疑会增加计算开销,模型图在图1b。在本文中,我们提出了FLAT:用于中文的 Transformer。具体来讲,本文只是将格子结构变成了头部位置和尾部位置两种索引的方式。如图1c,可以看出有数字的地方,就代表了字符的位置,那么词语“重庆”下面跟着的就是1,2,意思是从第一个字符,到第二个字符,是第一个词语“重庆”。同理还有后面的词语“人和药店”,和“药店”。
有意思的地方在于,本文也是引入了多种实体匹配的情况,“药店”这个实体就匹配到了“人和药店”和“药店”,这点在工业界很实用,因为一句话中很可能包含了很多很多的词语,充分的利用到这部分信息,是我们需要做的事情。
模型部分
总的来说,本文的贡献都集中于位置编码的部分,所以我们着重看下位置编码。在图2的模型架构图中,我们看到位置编码作为底层结构,输入给Transformer,最终进行输出。那么位置编码是如何计算的呢?创新性又在哪里?我们继续介绍。
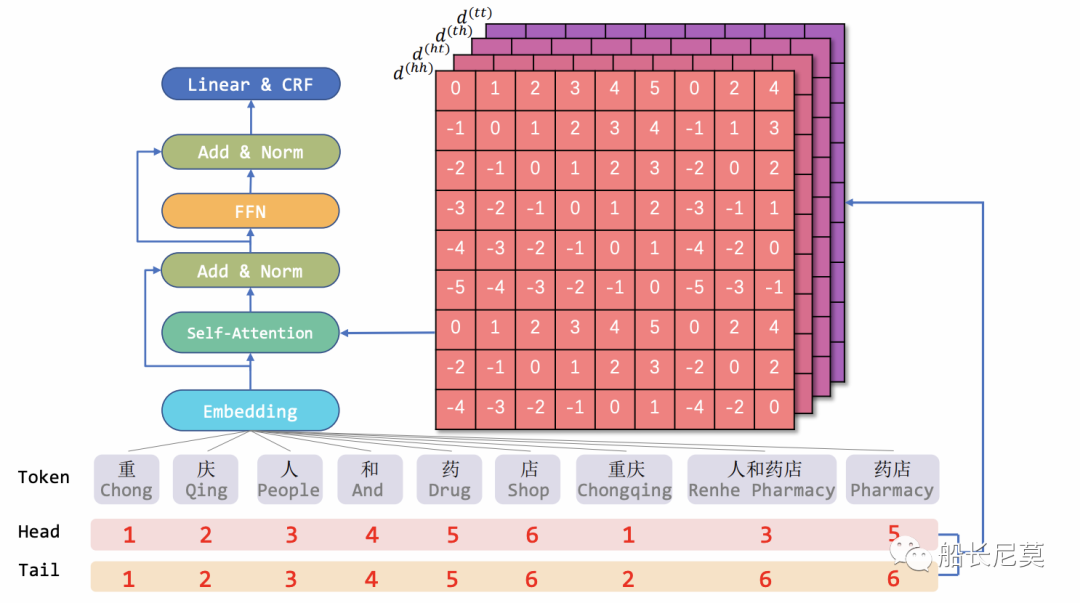
图2:模型架构图
将“格子”转化为扁平的方式
我们只需要知道这串序列的头和尾,就可以复原这个词语,例如“重庆”是由“重”到“庆”组成的。这一步是不需要考虑梯度回传的,为什么呢?因为这在数据处理层面,处理好之后才拿去给模型训练的。
相对位置编码
平面网格结构由不同长度的跨度组成。为了对区间之间的相互作用进行编码,本文提出了区间的相对位置编码。现在我们假设有两条序列,分别是xi 和 xj,具体来说,是图1中的“药店”和“人和药店”,这个例子,和明显xi xj是相交的关系。可以参考图2的模型图。
对于格子中的两个跨 xi 和 xj ,它们之间有三种关系:相交、包含和分离,由它们的首尾决定。接着就是来计算相对距离,那么相对距离有几种呢?答案是四种,为什么会这样?实际上是很简单的排列组合,2*2=4,2代表了开头或者结尾。使用 head[i] 和 tail[i] 表示跨度 xi 的头和尾的位置。四种相对距离可以用来表示 xi 和 xj 之间的关系。它们可以被计算为:
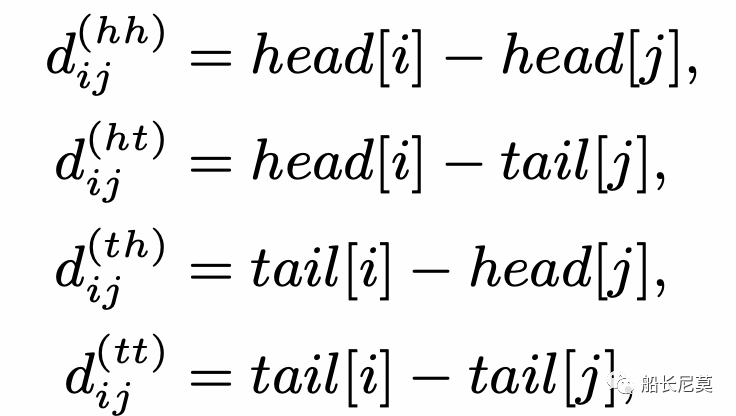
跨度的最终相对位置编码是四个距离的一个简单的非线性变换,见下面的公式。那么问题来了,为什么是四个距离一起计算,而不是只计算一个呢?是因为四个能够完整的还原出原来的状态,而一个不可以。举例来说,如果只有d(hh),代表了从字符串xi的开头,到字符串xj开头的距离,只有这一段距离,是无法复现出原本的xi xj相对位置。
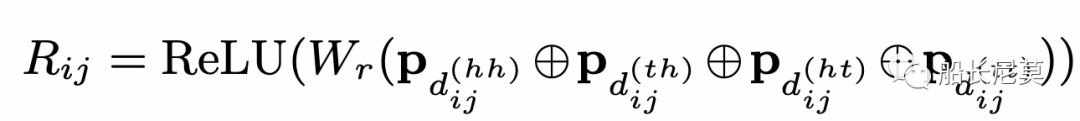
公式也是很好理解的,ReLU为激活函数,Wr是可学习的参数矩阵,四种距离,经过P运算之后叠加在一起作为输入。那么P是什么运算呢?作者在这里沿用了Transformer原本的距离编码。这个公式很神奇,因为很少有公式会把很大的数字,一万放进去,P的运算在奇数位和偶数位的方式不同,2k代表偶数位,2k+1代表奇数位。在知乎上有很多对这种位置编码的讲解,感兴趣的朋友可以自行浏览。
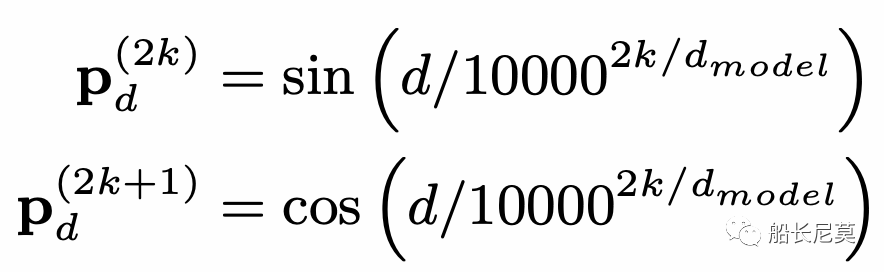
然后使用self-attention的一个变体来利用相对跨度位置编码如下:

其中Rij是从上面的公式而来,E是取Embedding,而W都代表了线性变化的矩阵。紧接着就是用这个A*替换掉原本的A,在Transformer内部进行attention运算的时候,如下的公式所示。之后的步骤就是沿着Transformer的内部进行计算即可。整个模型架构我们介绍完毕了,本文的贡献主要集中在位置编码部分。
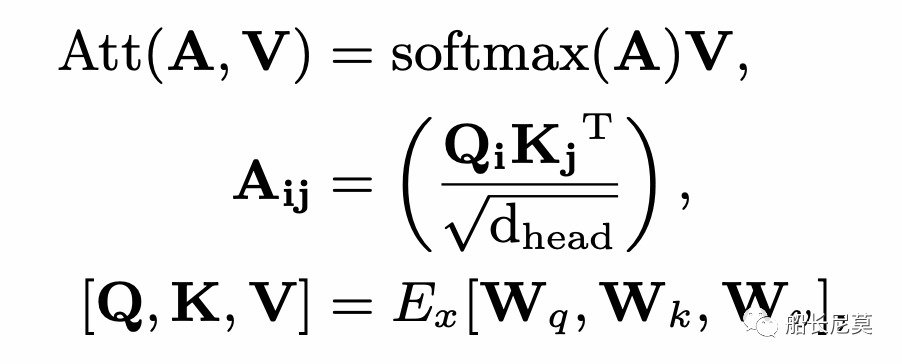
数据集介绍
数据集的详细情况和之前船长对于NER的分享很类似,都是用了差不多的数据集。不进行过多介绍了。
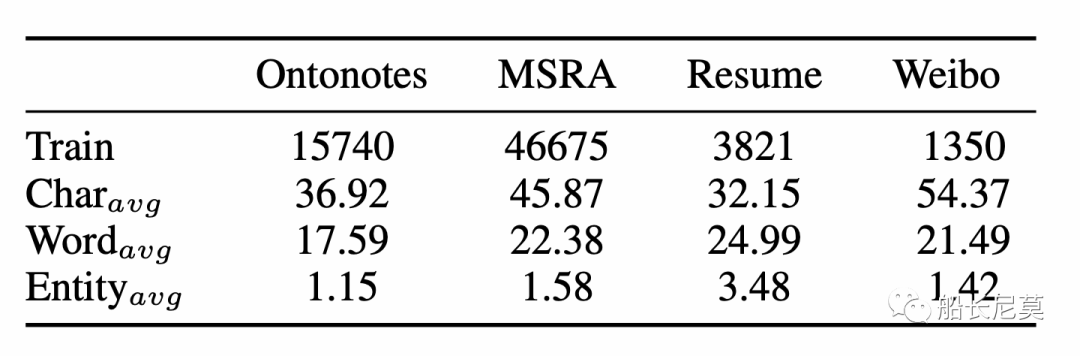
图3:数据集介绍
结果
Flat的方式,相比于之前的方法,有着1~3个点的提升,不同的数据集提升效果不同。
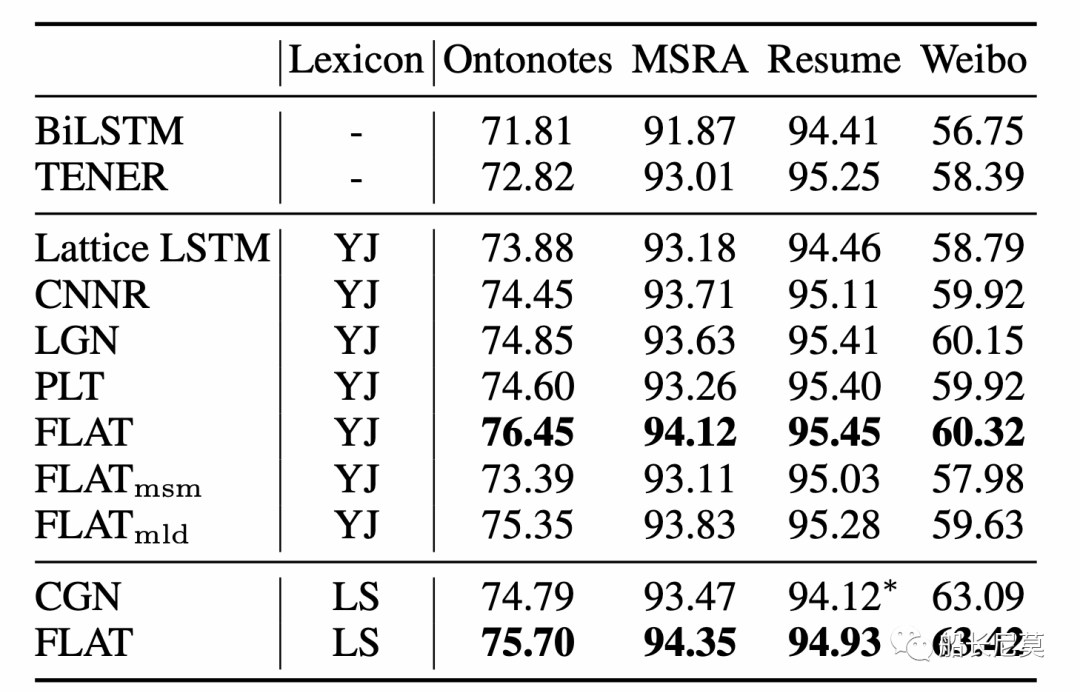
图4:结果介绍
全连通结构的优点
与lattice LSTM相比,注意机制有两个优点:
所有字符都可以直接与它的自匹配词进行交互。
远程依赖关系可以完全建模。这点根本上是缘由于Transformer的attention机制,注意力的机制能够让远距离的文本不再变得遥远。
FLAT的计算效率
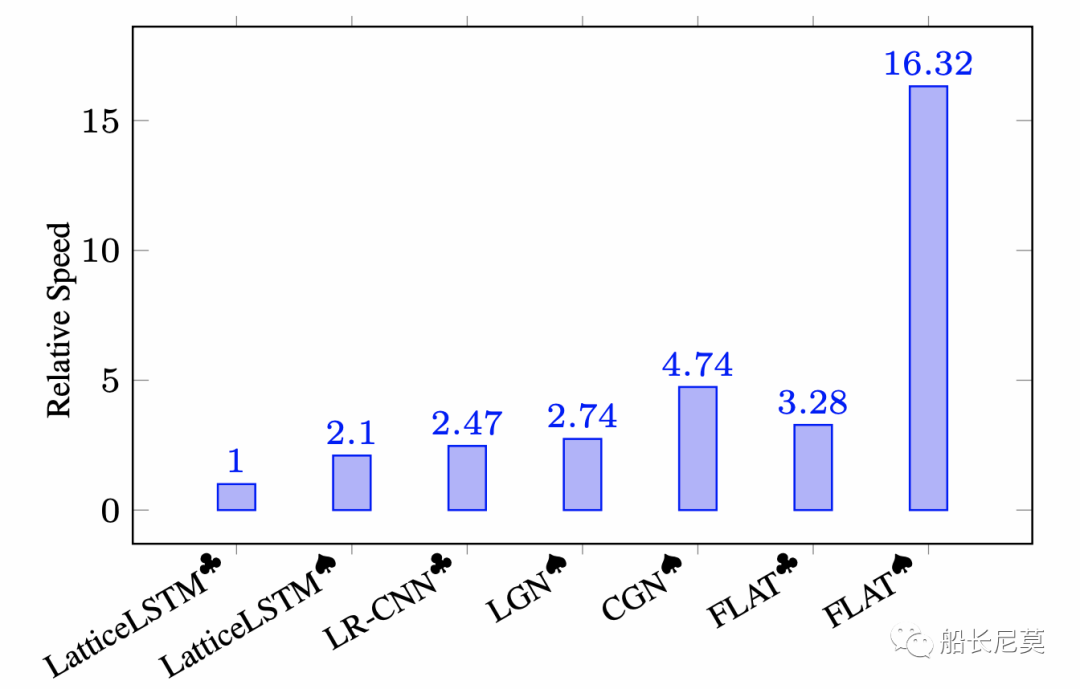
图5:推理速度效果
不难看出,推理速度方面,FLAT完胜了之前的 LatticeLSTM方式,大概提升有8倍之多,其中黑桃、梅花代表实验是否训练以batch-parallel 的机制。
兼容BERT
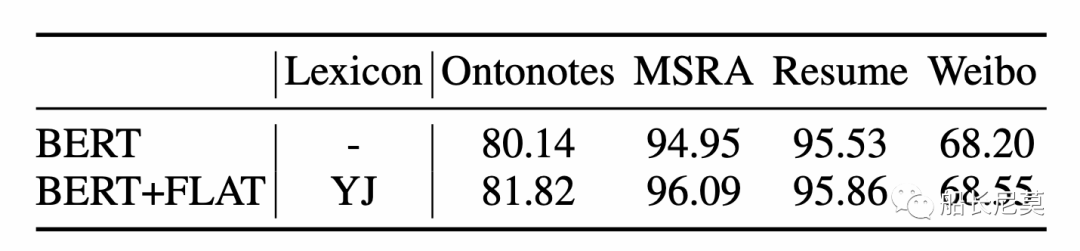
图6:兼容了BERT之后的结果,BERT是指BERT+MLP+CRF架构,BERT+FLAT是指使用BERT嵌入的FLAT
将FLAT机制引入到BERT之后,提升相对很大,因为对预训练模型的提升本身就很难。但是此处直接和BERT进行对比并不合适,因为BERT并没有引入词语的建模。但是能够方便的嵌入到BERT中,无疑会更利用在工业界的利用。
写在最后
本文介绍了一种FLAT的位置编码方式,可以应用在Transformer模型上面,并且很容易结合BERT等预训练模型。实验结果很优秀,关键是推理速度很快,这点也让方法很容易部署在线上,带来很好的效果。
编辑:黄飞
-
NER
+关注
关注
0文章
7浏览量
6477 -
位置编码器
+关注
关注
1文章
22浏览量
5833
原文标题:NER无法识别“世界杯”怎么办?融入词库的位置编码方法介绍
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论